Docker网络原理
前言
Docker有4种网络通信模型,分别是:bridge、host、none、container,默认使用的网络模型是bridge,本文中用到的也是bridge网络模型
本文分享Docker网络原理,主要包含两部分内容:
- 容器之间通信
- 容器访问外网
1、前置网络知识
1)、veth pair
veth是虚拟以太网卡(Virtual Ethernet)的缩写。veth设备总是成对的,因此称之为veth pair。veth pair一端发送的数据会在另外一端接收。根据这一特性,veth pair常被用于跨network namespace之间的通信,即分别将veth pair的两端放在不同的namespace里,如下图所示:
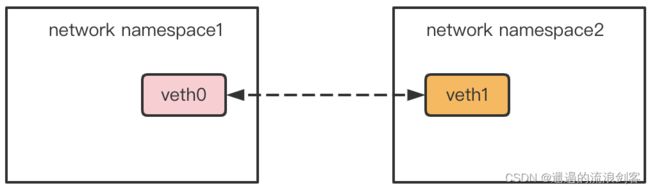
案例:使用veth pair实现跨network namespace之间的通信
# 创建一个名为netns1的network namespace
[root@aliyun ~]# ip netns add netns1
# 使用ip netns exec命令进入,查询网络配置
[root@aliyun ~]# ip netns exec netns1 ip link list
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
netns1这个network namespace目前没有任何配置,因此只有一块系统默认的本地回环设备lo
# 创建veth pair,名字分别是veth0和veth1
[root@aliyun ~]# ip link add veth0 type veth peer name veth1
# 创建的veth pair在主机上表现为两块网卡,设备初始状态是DOWN
[root@aliyun ~]# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:16:3e:2d:4e:bc brd ff:ff:ff:ff:ff:ff
3: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether ee:2b:7c:7d:a4:a2 brd ff:ff:ff:ff:ff:ff
4: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 7e:67:0c:b3:d7:cd brd ff:ff:ff:ff:ff:ff
# 把veth pair的一端放到netns1 network namespace
[root@aliyun ~]# ip link set veth1 netns netns1
# netns1 network namespace能看到veth1网卡,而主机根network namespace看不到该网卡
[root@aliyun ~]# ip netns exec netns1 ip link list
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
3: veth1@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether ee:2b:7c:7d:a4:a2 brd ff:ff:ff:ff:ff:ff link-netnsid 0
[root@aliyun ~]# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:16:3e:2d:4e:bc brd ff:ff:ff:ff:ff:ff
4: veth0@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 7e:67:0c:b3:d7:cd brd ff:ff:ff:ff:ff:ff link-netnsid 0
这两块网卡创建出来还都是DOWN状态,需要手动把状态设置成UP,同时绑定IP地址
[root@aliyun ~]# ip netns exec netns1 ifconfig veth1 10.1.1.1/24 up
[root@aliyun ~]# ifconfig veth0 10.1.1.2/24 up
上面两条命令首先进入netns1这个network namespace,为veth1绑定IP地址10.1.1.1/24,并把网卡的状态设置为UP,而仍在主机根network namespace中的网卡veth0被绑定了IP地址10.1.1.2/24。这样一来,就可以ping通veth pair的任意一头了
# 在主机上ping netns1 network namespace里的网卡
[root@aliyun ~]# ping 10.1.1.1
PING 10.1.1.1 (10.1.1.1) 56(84) bytes of data.
64 bytes from 10.1.1.1: icmp_seq=1 ttl=64 time=0.034 ms
64 bytes from 10.1.1.1: icmp_seq=2 ttl=64 time=0.040 ms
# 进入netns1 network namespace里去ping主机上的虚拟网卡
[root@aliyun ~]# ip netns exec netns1 ping 10.1.1.2
PING 10.1.1.2 (10.1.1.2) 56(84) bytes of data.
64 bytes from 10.1.1.2: icmp_seq=1 ttl=64 time=0.021 ms
64 bytes from 10.1.1.2: icmp_seq=2 ttl=64 time=0.039 ms
veth pair设备的原理就是向veth pair一端输入数据,数据通过内核协议栈后从veth pair的另一端出来。veth pair的基本工作原理如下图:

2)、Linux bridge
两个network namespace可以通过veth pair连接,但要做到两个以上network namespace相互连接,veth pair就做不到了,而通过Linux bridge就可以实现
网桥是二层网络设备,Linux bridge就是Linux系统中的网桥,但是Linux bridge的行为更像是一台虚拟的网络交换机,任意的真实物理设备(例如eth0)和虚拟设备(例如veth pair)都可以连接到Linux bridge上。需要注意的是,Linux bridge不能跨机连接网络设备
Linux bridge与Linux其他网络设备的区别在于,普通的网络设备只有两端,从一端进来的数据会从另一端出去。例如,物理网卡从外面网络中收到的数据会转发给内核协议栈,而从协议栈过来的数据会转发到外面的物理网络中。Linux bridge则有多个端口,数据可以从任何端口进来,进来之后从哪个口出去取决于目的的MAC地址,原理和物理交换机差不多
案例:使用bridge连接veth pair实现跨network namespace之间的通信
[root@aliyun ~]# yum install -y bridge-utils
# 创建网桥
[root@aliyun ~]# brctl addbr br0
[root@aliyun ~]# brctl show
bridge name bridge id STP enabled interfaces
br0 8000.000000000000 no
# 创建两个network namespace
[root@aliyun ~]# ip netns add netns0
[root@aliyun ~]# ip netns add netns1
[root@aliyun ~]# ip netns list
netns1
netns0
# 创建两对veth pair
[root@aliyun ~]# ip link add veth0 type veth peer name veth0-br
[root@aliyun ~]# ip link add veth1 type veth peer name veth1-br
[root@aliyun ~]# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:16:3e:2d:4e:bc brd ff:ff:ff:ff:ff:ff
3: br0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether f2:74:e6:78:20:b5 brd ff:ff:ff:ff:ff:ff
4: veth0-br@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 7e:c4:ae:9f:b2:a0 brd ff:ff:ff:ff:ff:ff
5: veth0@veth0-br: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether da:ca:2b:e3:f2:3d brd ff:ff:ff:ff:ff:ff
6: veth1-br@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether ee:46:7d:68:19:c1 brd ff:ff:ff:ff:ff:ff
7: veth1@veth1-br: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether be:87:6b:26:49:f8 brd ff:ff:ff:ff:ff:ff
# 两对veth pair的一端分别放到两个network namespace
[root@aliyun ~]# ip link set veth0 netns netns0
[root@aliyun ~]# ip link set veth1 netns netns1
# 两对veth pair的另一端连接到网桥
[root@aliyun ~]# brctl addif br0 veth0-br
[root@aliyun ~]# brctl addif br0 veth1-br
[root@aliyun ~]# brctl show
bridge name bridge id STP enabled interfaces
br0 8000.7ec4ae9fb2a0 no veth0-br
veth1-br
# 给两个network namespace中的veth配置ip并启用
[root@aliyun ~]# ip netns exec netns0 ifconfig veth0 10.1.1.1/24 up
[root@aliyun ~]# ip netns exec netns1 ifconfig veth1 10.1.1.2/24 up
# 主机根network namespace中的veth和网桥状态都设置为启用
[root@aliyun ~]# ifconfig veth0-br up
[root@aliyun ~]# ifconfig veth1-br up
[root@aliyun ~]# ifconfig br0 up
# veth0 ping veth1
[root@aliyun ~]# ip netns exec netns0 ping 10.1.1.2
PING 10.1.1.2 (10.1.1.2) 56(84) bytes of data.
64 bytes from 10.1.1.2: icmp_seq=1 ttl=64 time=0.046 ms
64 bytes from 10.1.1.2: icmp_seq=2 ttl=64 time=0.046 ms
# veth1 ping veth0
[root@aliyun ~]# ip netns exec netns1 ping 10.1.1.1
PING 10.1.1.1 (10.1.1.1) 56(84) bytes of data.
64 bytes from 10.1.1.1: icmp_seq=1 ttl=64 time=0.029 ms
64 bytes from 10.1.1.1: icmp_seq=2 ttl=64 time=0.055 ms
使用bridge连接veth pair基本工作原理如下图:

3)、iptables
iptables是位于用户空间的一个面向系统管理员的Linux防火墙的管理工具,而iptables的底层实现是Netfilter,Linux内核通过Netfilter实现网络访问控制功能
1)iptables的四表五链
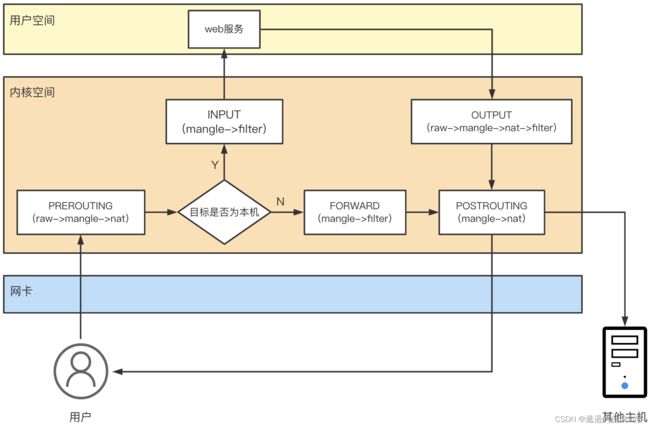
上图中使用箭头展示了用户访问使用了iptables的机器的过程,其中按照箭头的顺序我们就可以将其梳理为一条大的带有分支的链条,在每个需要进行操作的模块处都标有名称和相应的括号,括号内的就是iptables的四表,而每个模块都可以视为一个链
之所以叫作链就是因为在访问该链的时候会按照每个链对应的表依次进行查询匹配执行的操作,如PREROUTING链对应的就是(raw->mangle->nat),每个表按照优先级顺序进行连接,每个表中还可能有多个规则,因此最后看起来就像链一样,因此称为链
注意每一个链对应的表都是不完全一样的,表和链之间是多对多的对应关系。但是不管一个链对应多少个表,它的表都是按照下面的优先顺序来进行查找匹配的
表的处理优先级:raw>mangle>nat>filter
四表:
iptables的四个表iptable_filter、iptable_mangle、iptable_nat、iptable_raw,默认表是filter(没有指定表的时候就是filter表)
filter表:用来对数据包进行过滤,具体的规则要求决定如何处理一个数据包。对应的内核模块为:iptable_filter,其表内包括三个链:input、forward、outputnat表:nat全称是network address translation网络地址转换,主要用来修改数据包的IP地址、端口号信息。对应的内核模块为:iptable_nat,其表内包括三个链:prerouting、postrouting、outputmangle表:主要用来修改数据包的服务类型,生存周期,为数据包设置标记,实现流量整形、策略路由等。对应的内核模块为:iptable_mangle,其表内包括五个链:prerouting、postrouting、input、output、forwardraw表:主要用来决定是否对数据包进行状态跟踪。对应的内核模块为:iptable_raw,其表内包括两个链:output、prerouting
五链:
iptables的五个链PREROUTING、INPUT、FORWARD、OUTPUT、POSTROUTING
input链:当收到访问防火墙本机地址的数据包时,将应用此链中的规则output链:当防火墙本机向外发送数据包时,将应用此链中的规则forward链:当收到需要通过防火中转发给其他地址的数据包时,将应用此链中的规则,注意如果需要实现forward转发需要开启Linux内核中的ip_forward功能prerouting链:在对数据包做路由选择之前,将应用此链中的规则postrouting链:在对数据包做路由选择之后,将应用此链中的规则
2)iptables配置
iptables的基本语法命令格式
iptables [-t 表名] 管理选项 [链名] [匹配条件] [-j 控制类型]
- 表名、链名:指定iptables命令所操作的表和链,未指定表名时将默认使用filter表
- 管理选项:表示iptables规则的操作方式,比如:插入、增加、删除、查看等
- 匹配条件:指定要处理的数据包的特征,不符合指定条件的数据包不处理
- 控制类型:指数据包的处理方式,比如:允许accept、拒绝reject、丢弃drop、日志log等
iptables命令的常用管理选项
-A:在指定链的末尾添加一条新的规则
-D:删除指定链中的某一条规则,可删除指定序号或具体内容
-I:在指定链中插入一条新规则,未指定序号时默认作为第一条规则
-R:修改、替换指定链中的某一条规则,可指定规则序号或具体内容
-L:列出指定链中所有的规则,未指定链名,则列出表中的所有链
-F:清空指定链中所有的规则,未指定链名,则清空表中的所有链
-P:设置指定链的默认策略
-n:使用数字形式显示输出结果
-v:查看规则列表时显示详细的信息
-h:查看命令帮助信息
--line-numbers:查看规则列表时,同时显示规则在链中的顺序号
4)、NAT工作原理
接下来介绍一些NAT(Network Address Translation,网络地址转换)的基本知识,众所周知,IPv4的公网IP地址已经枯竭,但是需要接入互联网的设备还在不断增加,这其中NAT就发挥了很大的作用(此处不讨论IPv6)。NAT服务器提供了一组私有的IP地址池(10.0.0.0/8、172.16.0.0/12、192.168.0.0/16),使得连接该NAT服务器的设备能够获得一个私有的IP地址(也称局域网IP/内网IP),当设备需要连接互联网的时候,NAT服务器将该设备的私有IP转换成可以在互联网上路由的公网IP(全球唯一)。NAT的实现方式有很多种,这里我们主要介绍三种:静态NAT、动态NAT和网络地址端口转换(NAPT)
1)BNAT
静态NAT:LVS的官方文档中也称为(N-to-N mapping) ,前面的N指的是局域网中需要联网的设备数量,后面的N指的是该NAT服务器所拥有的公网IP的数量。既然数量相等,那么就可以实现静态转换,即一个设备对应一个公网IP,这时候的NAT服务器只需要维护一张静态的NAT映射转换表
| 内网IP | 外网IP |
|---|
动态NAT:LVS的官方文档中也称为(M-to-N mapping) ,注意这时候的M>N,也就是说局域网中需要联网的设备数量多于NAT服务器拥有的公网IP数量,这时候就需要由NAT服务器来实现动态的转换,这样每个内网设备访问公网的时候使用的公网IP就不一定是同一个IP
2)NAPT
以上这两种都属于基本网络地址转换(Basic NAT),仅支持地址转换,不支持端口映射,这样就产生资源浪费的问题。我们知道一个IP实际上可以对应多个端口,而我们访问应用实际上是通过IP地址+端口号的形式来访问的,即客户端访问的时候发送请求到服务器应用程序坚挺的端口即可实现访问。那么NAPT就是在基础上的扩展,它在IP地址的基础上加上了端口号,支持了端口映射的功能
NAPT:NAPT实际上还可以分为源地址转换(SNAT)和目的地址转换(DNAT)两种,这个源地址和目的地址是针对NAT服务器而言
SNAT:
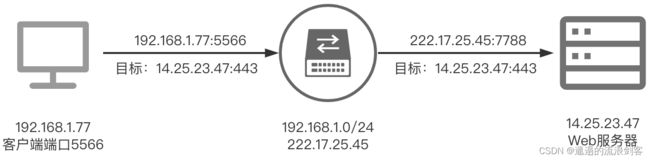
客户端上运行着一个浏览器,假设它使用的是5566端口,需要访问14.25.23.47这个Web服务器的HTTPS服务的443端口,它在访问的时候需要经过局域网出口的这个路由器网关(同时也是NAT服务器),路由器对它进行一个NAPT的源地址转换(SNAT),这时候客户端的请求经过NAT服务器之后变成了222.17.23.45:7788这个IP端口对Web服务器的443端口进行访问。这个过程中,目标服务器(Web服务器)的IP和端口是一直没有改变的
DNAT:
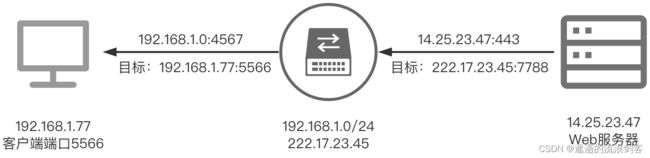
接下来在Web服务器接收到请求之后,需要返回数据给发送请求的设备,注意这时候Web服务器返回数据的指向IP应该是刚刚NAT服务器发送请求的227.17.23.45:7788这个IP端口,这时候路由器网关再进行一次NAPT的目标地址转换(DNAT),目标的IP端口就是最开始发送请求的192.168.1.77:5566这个端口
2、容器之间通信
1)、docker0网桥与veth pair
当我们安装完docker之后,docker会在宿主机上创建一个名叫docker0的网桥,默认IP是172.17.0.1/16
[root@aliyun ~]# ifconfig
docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
inet6 fe80::42:3dff:fe43:6d70 prefixlen 64 scopeid 0x20<link>
ether 02:42:3d:43:6d:70 txqueuelen 0 (Ethernet)
RX packets 4472 bytes 254744 (248.7 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5080 bytes 8741120 (8.3 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.19.216.110 netmask 255.255.240.0 broadcast 172.19.223.255
inet6 fe80::216:3eff:fe2d:4ebc prefixlen 64 scopeid 0x20<link>
ether 00:16:3e:2d:4e:bc txqueuelen 1000 (Ethernet)
RX packets 156055 bytes 223972092 (213.5 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 56749 bytes 5515146 (5.2 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
凡是连接在docker0网桥上的容器就可以通过它来进行通信,而容器则通过veth pair连接到docker0网桥
启动一个叫作nginx-1的容器:
[root@aliyun ~]# docker run --name nginx-1 -d -p 9001:80 nginx:1.17.1
然后进入到这个容器中查看一下它的网络设备:
[root@aliyun ~]# docker exec -it nginx-1 /bin/bash
# 安装net-tools
root@f5e7b5b6b908:/# apt-get update
root@f5e7b5b6b908:/# apt install net-tools
root@f5e7b5b6b908:/# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.2 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:ac:11:00:02 txqueuelen 0 (Ethernet)
RX packets 5085 bytes 8741390 (8.3 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 4472 bytes 317352 (309.9 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
root@f5e7b5b6b908:/# route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 172.17.0.1 0.0.0.0 UG 0 0 0 eth0 # 默认路由
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0 # 所有对172.17.0.0/16网段的请求也会被交给eth0来处理
这个容器里有一张叫作eth0的网卡,正是一个veth pair设备在容器里的这一端
通过route命令查看nginx-1容器的路由表,这个eth0网卡是这个容器里的默认路由设备;所有对172.17.0.0/16网段的请求也会被交给eth0来处理
而这个veth pair设备的另一端,则在宿主机上。可以通过查看宿主机的网络设备看到它:
[root@aliyun ~]# ifconfig
docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
inet6 fe80::42:3dff:fe43:6d70 prefixlen 64 scopeid 0x20<link>
ether 02:42:3d:43:6d:70 txqueuelen 0 (Ethernet)
RX packets 4475 bytes 254869 (248.8 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5083 bytes 8741341 (8.3 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.19.216.110 netmask 255.255.240.0 broadcast 172.19.223.255
inet6 fe80::216:3eff:fe2d:4ebc prefixlen 64 scopeid 0x20<link>
ether 00:16:3e:2d:4e:bc txqueuelen 1000 (Ethernet)
RX packets 156294 bytes 224012066 (213.6 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 56959 bytes 5551799 (5.2 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth5eda16a: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::4014:9fff:fea5:b31b prefixlen 64 scopeid 0x20<link>
ether 42:14:9f:a5:b3:1b txqueuelen 0 (Ethernet)
RX packets 4475 bytes 317519 (310.0 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5088 bytes 8741611 (8.3 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@aliyun ~]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.02423d436d70 no veth5eda16a
通过ifconfig命令的输出可以看到,nginx-1容器对应的veth pair设备,在宿主机上是一张虚拟网卡,它的名字叫做veth5eda16a。 并且通过brctl show的输出,可以看到这张网卡插在了docker0上
如何找到docker和宿主机上veth pair设备的关系:
通过查看容器里的eth0网卡的iflink找到对应关系
# 宿主机上
[root@aliyun ~]# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:16:3e:2d:4e:bc brd ff:ff:ff:ff:ff:ff
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:3d:43:6d:70 brd ff:ff:ff:ff:ff:ff
11: veth5eda16a@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether 42:14:9f:a5:b3:1b brd ff:ff:ff:ff:ff:ff link-netnsid 0
# 容器内
[root@aliyun ~]# docker exec -it nginx-1 /bin/bash
root@f5e7b5b6b908:/# cat /sys/class/net/eth0/iflink
11
这样就可以确定container f5e7b5b6b908在宿主机上对应的veth pair是veth5eda16a了
再启动另一个叫作nginx-2的容器:
[root@aliyun ~]# docker run --name nginx-2 -d -p 9002:80 nginx:1.17.1
[root@aliyun ~]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.02423d436d70 no veth5eda16a
veth6b9c3d8
就会发现一个新的、名叫veth6b9c3d8的虚拟网卡也被插在了docker0网桥上
2)、容器之间通信原理
在nginx-1容器里ping一下nginx-2容器的IP地址(172.17.0.3),就会发现同一宿主机上的两个容器默认就是相互连通的
[root@aliyun ~]# docker exec -it nginx-1 /bin/bash
# 安装ping
root@f5e7b5b6b908:/# apt-get install inetutils-ping
root@f5e7b5b6b908:/# ping 172.17.0.3
PING 172.17.0.3 (172.17.0.3): 56 data bytes
64 bytes from 172.17.0.3: icmp_seq=0 ttl=64 time=0.098 ms
64 bytes from 172.17.0.3: icmp_seq=1 ttl=64 time=0.080 ms
当在nginx-1容器里访问nginx-2容器的IP地址(比如ping 172.17.0.3)的时候,这个目的IP地址会匹配到nginx-1容器里的第二条路由规则
root@f5e7b5b6b908:/# route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 172.17.0.1 0.0.0.0 UG 0 0 0 eth0 # 默认路由
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0 # 所有对172.17.0.0/16网段的请求也会被交给eth0来处理
可以看到,这条路由规则的网关(Gateway)是0.0.0.0,这就意味着这是一条直连规则,即:凡是匹配到这条规则的IP包,应该经过本机的eth0网卡,通过二层网络直接发往目的主机
而要通过二层网络设备到达nginx-2容器,就需要有172.17.0.3这个IP地址对应的MAC地址。所以nginx-1容器的网络协议栈,就需要通过eth0网卡发送一个ARP广播,来通过IP地址查找对应的MAC地址
这个eth0网卡是一个veth pair,它的一端在这个nginx-1容器的Network Namespace里,而另一端则位于宿主机上(Host Namespace),并且被插在了宿主机的docker0网桥上。一旦一张虚拟网卡被插在网桥上,它就会变成该网桥的从设备。从设备会被剥夺调用网络协议栈处理数据包的资格,从而降级成为网桥上的一个端口。而这个端口唯一的作用,就是接收流入的数据包,然后把这些数据包的处理(比如转发或者丢弃),全部交给对应的网桥
所以,在收到ARP请求之后,docker0网桥就会扮演二层交换机的角色,把ARP广播转发到其他被插在docker0上的虚拟网卡。这样,同样连接在docker0上的nginx-2容器的网络协议栈就会受到这个ARP请求,从而将172.17.0.3所对应的MAC地址回复给nginx-1容器
有了这个目的的MAC地址,nginx-1容器的eth0网卡就可以将数据包发出去
而根据veth pair设备的原理,这个数据包会立刻出现在宿主机上的veth5eda16a虚拟网卡上。不过,此时这个veth5eda16a网卡的网络协议栈的资格已经被剥夺,所以这个数据包就直接流入到了docker0网桥里
docker0处理转发的过程,则继续扮演二层交换机的角色。此时,docker0网桥根据数据包的目的MAC地址(也就是nginx-2容器的MAC地址),在它的CAM表(即交换机通过MAC地址学习维护的端口和MAC地址的对应表)里查到对应的端口(Port)为:veth6b9c3d8,然后把数据包发往这个端口
而这个端口,正是nginx-2容器插在docker0网桥上的另一块虚拟网卡,当然,它也是一个veth pair设备。这样,数据包就进入到了nginx-2容器的Network Namespace里
所以,nginx-2容器看到的情况是,它自己的eth0网卡上出现了流入的数据包。这样,nginx-2的网络协议栈就会对请求进行处理,最后将响应(Pong)返回到nginx-1

3、容器访问外网
在nginx-1容器中ping www.bing.com是能ping通的,说明容器里是能访问外网的
root@f5e7b5b6b908:/# ping www.bing.com
PING china.bing123.com (202.89.233.101): 56 data bytes
64 bytes from 202.89.233.101: icmp_seq=0 ttl=114 time=28.361 ms
64 bytes from 202.89.233.101: icmp_seq=1 ttl=114 time=28.323 ms
nginx-1位于docker0这个私有bridge网络中(172.17.0.0/16),当nginx-1从容器向外ping时,数据包是怎样到达www.bing.com的呢?
这里的关键就是NAT,查看下宿主机上的iptables规则:
[root@aliyun ~]# iptables -t nat -S
-P PREROUTING ACCEPT
-P INPUT ACCEPT
-P OUTPUT ACCEPT
-P POSTROUTING ACCEPT
-N DOCKER
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE # 如果docker0网桥收到来自172.17.0.0/16网段外出包,把它交给MASQUERADE处理
-A POSTROUTING -s 172.17.0.2/32 -d 172.17.0.2/32 -p tcp -m tcp --dport 80 -j MASQUERADE
-A POSTROUTING -s 172.17.0.3/32 -d 172.17.0.3/32 -p tcp -m tcp --dport 80 -j MASQUERADE
-A DOCKER -i docker0 -j RETURN
-A DOCKER ! -i docker0 -p tcp -m tcp --dport 9001 -j DNAT --to-destination 172.17.0.2:80
-A DOCKER ! -i docker0 -p tcp -m tcp --dport 9002 -j DNAT --to-destination 172.17.0.3:80
在NAT表中有这么一条规则:-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
其含义就是:如果docker0网桥收到来自172.17.0.0/16网段外出包,把它交给MASQUERADE处理,而MASQUERADE的处理方式是将包的源地址替换成host的网址发送出去,做了一次源地址转换(SNAT)
下面我们通过tcpdump查看地址是如何转换的。先查看宿主机的路由表
[root@aliyun ~]# route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default gateway 0.0.0.0 UG 0 0 0 eth0
link-local 0.0.0.0 255.255.0.0 U 1002 0 0 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
172.19.208.0 0.0.0.0 255.255.240.0 U 0 0 0 eth0
通过route命令看到默认路由通过eth0发出去,所以我们同时要监控eth0和docker0上的icmp(ping)的数据包
当nginx-1容器中ping www.bing.com时,tcpdump输入如下:
[root@aliyun ~]# tcpdump -i docker0 -n icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on docker0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:50:43.099630 IP 172.17.0.2 > 202.89.233.101: ICMP echo request, id 308, seq 0, length 64
16:50:43.127809 IP 202.89.233.101 > 172.17.0.2: ICMP echo reply, id 308, seq 0, length 64
16:50:44.100511 IP 172.17.0.2 > 202.89.233.101: ICMP echo request, id 308, seq 1, length 64
16:50:44.128641 IP 202.89.233.101 > 172.17.0.2: ICMP echo reply, id 308, seq 1, length 64
docker0收到nginx-1的ping包,源地址为容器的IP:172.17.0.2,交给MASQUERADE处理。这时,在看eth0的变化
[root@aliyun ~]# tcpdump -i eth0 -n icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:50:43.099641 IP 172.19.216.110 > 202.89.233.101: ICMP echo request, id 308, seq 0, length 64
16:50:43.127772 IP 202.89.233.101 > 172.19.216.110: ICMP echo reply, id 308, seq 0, length 64
16:50:44.100536 IP 172.19.216.110 > 202.89.233.101: ICMP echo request, id 308, seq 1, length 64
16:50:44.128607 IP 202.89.233.101 > 172.19.216.110: ICMP echo reply, id 308, seq 1, length 64
ping包的源地址变成eth0的172.19.216.110
这就是iptables的NAT规则的处理结果,从而保证数据包能够到达外网

- nginx-1发送ping包:172.17.0.2 > 202.89.233.101(
www.bing.com对应的IP) - docker0收到包,发现是发送到外网的,交给NAT处理
- NAT将源地址换成eth0的IP:172.19.216.110 > 202.89.233.101
- ping从eth0出去,到达
www.bing.com
参考:
《Kubernetes网络权威指南:基础、原理与实践》
容器网络1.2-docker网桥原理实验
iptables的四表五链与NAT工作原理
浅谈容器网络
Docker容器访问外部世界