MySQL数据库——数据类型和表约束
文章目录
- MySQL——数据类型和表约束
-
- 一、MySQL数据类型
- 二、MySQL定义列数据类型
-
- 1.数字
-
- 1.1整型
- 1.2浮点型
- 1.3定点型
- 2.字符串
-
- 2.1 char和varchar
- 2.2varchar和text
- 2.3二进制数据(Blob)
- 3.日期时间类型
- 4.Mysql数据类型的长度和范围
- 5.Mysql数据类型使用建议
- 6.Mysql选择数据类型的基本原则
- 三、Mysql数据类型约束
-
- 1.非空约束(not null)
- 2.唯一约束(unique [key|index])
- 3.主键约束(primary key)
- 4.自增长约束(auto_increment)
- 5.默认约束(default)
- 6.外键约束(foreign key)
- 四、MySQL索引
-
- 1.Mysql索引的分类
- 2.Mysql不同类型索引用途和区别
- 3.Mysql使用索引
-
- 3.1创建索引
-
- 3.1.1普通索引(index)
- 3.1.2唯一索引(unique)
- 3.1.3主键索引(primary key)
- 3.2删除索引
-
- 3.2.1普通索引(index)
- 3.2.2唯一索引(unique)
- 3.2.3主键索引(primary key)
- 3.3查看索引
- 3.4选择索引的原则
MySQL——数据类型和表约束
一、MySQL数据类型
• 整数类型:BIT、BOOL、TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT
• 浮点数类型:FLOAT、DOUBLE、DECIMAL
• 字符串类型:CHAR、VARCHAR、TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT、TINYBLOB、BLOB、MEDIUMBLOB、LONGBLOB
• 日期类型:Date、DateTime、TimeStamp、Time、Year
• 其他数据类型:BINARY、VARBINARY、ENUM、SET、Geometry、Point、MultiPoint、LineString、MultiLineString、Polygon、GeometryCollection等
二、MySQL定义列数据类型
mysql> create table 表名(
字段名 列类型 unsigned [可选的参数],
字段名 列类型 [可选的参数],
字段名 列类型 [可选的参数],
);
1.数字
1.1整型
| Mysql数据类型 | 字节 | 比特位 | 最小值 | 最大值 |
|---|---|---|---|---|
| tinyint(n) | 1 | 8 | -128 | 127 |
| smallint(n) | 2 | 16 | -32768 | 32767 |
| mediumint(n) | 3 | 24 | -8838608 | 8839627 |
| int(n) | 4 | 32 | -2147483648 | 2147483647(0和31个1) |
| bigint(n) | 8 | 64 | -(1个1和63个0) | (0和63个1) |
当整数值超过int数据类型支持的范围时,就可以采用bigint。
在MySQL中,int数据类型是主要的整数数据类型。
只有当参数表达式是bigint数据类型时,函数才返回bigint,Mysql不会自动将其他整数数据类型提升为bigint。
int(n)里n是表示select查询结果集中的显示宽度,并不影响实际的取值范围,没有影响到显示的宽度。无论n等于多少,int永远占4字节,不足的用0补足,超过的无视长度而直接显示整个数字,但要整型设置了unsigned zerofill才有效。id int(5) unsigned zerofill效果为:

1.2浮点型
| Mysql浮点型数据类型 | 字节数 | |
|---|---|---|
| float(m,d) | 4 | 单精度浮点型 8位精度,m总个数,d小数位 |
| double(m,d) | 8 | 双精度浮点型 16位精度,m总个数,d小数位 |
设一个字段定义为float(6,3)。如果插入一个数123.45678,实际数据库里存的是123.457,但总个数还以实际为准,即6位数。整数部分最大是3位。
如果插入12.123456,存储的是12.1234,如果插入的是12.12,则存储的是12.1200。
当不指定m、d的时候,会按照实际的精度来处理。
1.3定点型
浮点型在数据库中存放的是近似值,而定点型在数据库中存放的是精确值。
| Mysql浮点型数据类型 | 含义 |
|---|---|
| decimal(m,d) | 总个数m最大为64,小数位最多为29位,d |
decimal无论写入数据中心的数据是多少,都不会存在精度丢失问题,常见于银行系统、互联网金融系统等对小数点后的数字敏感的系统中。
定点型与浮点型的区别:
• float/double在db中存储的是近似值,而decimall则是以字符串形式进行保存的。
• decimal(M,D)的规则和loat/double相同,但区别在float/double在不指定M、D时默认按照实际精度来处理而decimal在不指定M、D时默认为decimal(10,0)
2.字符串
| Mysql数据类型 | 含义 |
|---|---|
| char(m) | 固定长度,最多255个字符 |
| varcahr(m) | 可变长度,最多65535个字符(utf-8下是21844) |
| tinytext | 可变长度,最多255个字符 |
| text | 可变长度,最多65535个字符 |
| mediument | 可变长度,最多2的24次方-1个字符 |
| logtext | 可变长度,最多2的32次方-1个字符 |
2.1 char和varchar
• char表示定长字符串,长度是固定的;如果插入数据的长度小于char的固定长度时,则用空格填充;因为长度固定,所以存取速度要比varchart快很多,甚至能快50%,但正因为其长度固定,所以会占据多余的空间,是空间换时间的做法;对于char来说,最多能存放的字符个数为255,和编码无关。
• varchar表示可变长字符串,长度是可变的;插入的数据是多长,就按照多长来存储;varchar在存取方面与char相反,它存取慢,因为长度不固定,但正因如此,不占据多余的空间,是时间换空间的做法;对于varchar来说,最多能存放的字符个数为65532。
• 结合性能角度(char更快),节省磁盘空间角度(varchar更小),具体情况还需具体来设计数据库才是妥当的做法。
• MySQL处理char类型数据时会将结尾的所有空格处理掉而varchar类型数据则不会。
• char(n)若存入字符数小于n,则以空格补于其后,查询之时再将空格去掉。所以char类型存储的字符串末尾不能有空格,varchar不限于此。
• char(n)固定长度,char(4)不管是存入几个字符,都将占用4个字节,varchar是存入的实际字符数+1个字节(n<=255)或2个字节(n>255),所以varchar(4),存入3个字符将占用4个字节。
• MySQL处理char类型数据时会将结尾的所有空格处理掉而varchar类型数据则不会
• char类型的字符串检索速度要比varchar类型的快。
• MysQL要求一个行的定义长度不能超过65535即64K。对于未指定varchar字段not nulle的表,会有1个字节专门表示该字段是否为null varchar(n),当M范围为0<=n<=255时会专门得一个字节记录varchar型字符串长度,当M>255时,会专门有两个字节记录varchar型字符串的长度,把这一点和上一点结合,那么65535个字节实际可用的为65535-3=65532个字节。
• 所有英文无论其编码方式,都占用1个字节,但对于gbk编码,一个汉字占两个字节,因此最大n=65532/2=32766;对于utf8编码,一个汉字占3个字节,因此最大M=65532/3=21844utf8mb4编码方式,1个字符最大可能占4个字节,那么varchar(n),n最大为65532/4=16383。
• varchar(n)n>255时转为tinytext
• varchar(n)n>500时转为text
• varchar(n)n>20000时转为mediumtext
2.2varchar和text
• varchari可指定n,text不能指定,内部存储varchar是存入的实际字符数+1个字节(n<=255)或2个字节(n>255),text是实际字符数+2个字节。
• varchari可直接创建索引,text创建索引要指定前多少个字符。varchari直询速度快于text,在都创建索引的情况下,tet的索引似乎不起作用。
• MySQL单行i最大数据量为64K,当varchar(M)的M大于某些数值时,varchars会自动转为text。
• 过大的内容varchar和text没有区别。
• 单行64K即65535字节的空间,varchar.只能用63352/65533个字节,但是text可以65535个字节全部用起来。
• text可以指定text(n),但是n无论等于多少都没有影响
• text不允许有默认值,varchar允许有默认值
• varchara和text两种数据类型,使用建议是能用varchar就用varchari而不用teXt(存储效率高),varchar(M)的M有长度限制,如果大于限制可以使用mediumtext(16M)或者longtext(4G)。
2.3二进制数据(Blob)
• BLOB和txt存储方式不同,TEXT以文本方式存储,英文存储区分大小写,而B引ob是以二进制方式存储,不分大小写。
• BLOB存储的数据只能整体读出。
• TEXT可以指定字符集,Blob不用指定字符集。
• Blob是用于存储例如图片、音视频这种文件的二进制数据的。
3.日期时间类型
| 数据类型 | 字节数 | 格式 | 备注 |
|---|---|---|---|
| date | 3 | yyyy-MM-dd | 存储日期值 |
| time | 3 | HH:mm:ss | 存储时分秒 |
| year | 1 | yyyy | 存储年 |
| datetime | 8 | yyyy-MM-dd HH:mm:ss | 存储日期+时间 |
| timestamp | 4 | yyyy-MM-dd HH:mm:ss | 存储日期+时间,可作时间戳 |
• datetime占8个字节,timestamp占4个字节。
• 由于大小的区别,datetime与timestamp能存磺的时间范围也不同,datetime的存储范画为1000-01-01 00:00:00——9999-12-31 23:59:59,timestamp存储的时间范国为19700101080001–20380119111407
• datetime默认值为空,当插入的值为null时,该列的值就是nul;timestamp默认值不为空,当插入的值为null的时候,mysql会取当前时间。
• datetime存储的时间与时区无关,timestamp存储的时间及显示的时间都依赖于当前时区。
• 在实际工作中,一张表往往会有两个默认字段,一个记录创建时间而另一个记录最新一次的更新时间,这种时候可以使用timestamp类型来实现。
4.Mysql数据类型的长度和范围
Mysql个数据类型及字节长度
| 数据类型 | 字节长度 | 范围或用法 |
|---|---|---|
| Bit | 1 | 无符号[0,255],有符号[128,127],BIT和BOOL布尔型都占用1字节 |
| Tinylnt | 1 | 整数[0,255] |
| Smalllnt | 2 | 无符号[0,65535],有符号[-32768,32767] |
| MediumInt | 3 | 无符号[0,224-1],有符号[-223,223-1] |
| Int | 4 | 无符号[0,232-1],有符号[-231,231-1] |
| BigInt | 8 | 无符号[0,264-1],有符号[-263,263-1] |
| Float(M,D) | 4 | 单精度浮点数。这里的D是精度,如果D<=24则为默认的FLOAT,如果D>24则会自动被转换为DOUBLE型。 |
| Double(M,D) | 8 | 双精度浮点 |
| Decimal(M,D) | M+1或M+2 | 未打包的浮点数,用法类似于FLOAT和DOUBLE,如果在ASP中使用到Decimal数据类型,直接从数据库读出来的Decimal可能需要先转换成Float或Double类型后再进行运算 |
| Date | 3 | 以YYYY-MM-DD的格式显示,比如:2009-07-19 |
| Date Time | 8 | 以YYYY-MM-DDHH:MM:SS的格式显示,比如:2009-07-19 11:22:30 |
| TimeStamp | 4 | 以YYYY-MM-DD的格式显示,比如:2009-07-19 |
| Time | 3 | 以HH:MM:SS的格式显示。比如:11:22:30 |
| Year | 1 | 以YYYY的格式显示。比如:2009 |
| Char(M) | M | 定长字符串 |
| VarChar(M) | M | 变长字符串,要求M<=255 |
| Binary(M) | M | 类似Char的二进制存储,特点是插入定长不足补0 |
| VarBinary(M) | M | 类以VarChar的变长二进制存储,特点是定长不补O |
| Tiny Text | Max:255 | 大小写不敏感 |
| Text | Max:64K | 大小写不敏感 |
| Medium Text | Max:16M | 大小写不敏感 |
| Long Text | Max:4G | 大小写不敏感 |
| TinyBlob | Max:255 | 大小写敏感 |
| Blob | Max:64K | 大小写敏感 |
| MediumBlob | Max:16M | 大小写敏感 |
| LongBlob | Max:4G | 大小写敏感 |
| Enum | 1或2 | 最大可达65535个不同的枚举值 |
| Set | 可达8 | 最大可达64个不同的值 |
5.Mysql数据类型使用建议
• 在指定数据类型的时候一般是采用从小原则,比如能用TINYINT的最好就不用INT,能用FLOAT类型的就不用DOUBLE类型,这样会对MYSQL在运行效率上提高很大,尤其是大数据量测试条件下。
• 不需要把数据表设计的太过复杂,功能模块上区分或许对于后期的维护更为方便,慎重出现大杂烩数据表。
• 数据库的最后设计结果一定是效率和可扩展性的折中,偏向任何一方都是欠妥的。
6.Mysql选择数据类型的基本原则
• 根据选定的存储引擎,确定如何选择合适的数据类型。
• MylSAM数据存储引擎和数据列:MyISAM数据表,最好使用固定长度(CHAR)的数据列代替可变长度VARCHAR)的数据列。
• MEMORY存储引擎和数据列:MEMORY数据表目前都使用固定长度的数据行存储,因此无论使用CHAR或VARCHAR列都没有关系。两者都是作为CHAR类型处理的。
• InnoDB存储引擎和数据列:建议使用VARCHAR类型。对于InnoDB数据表,内部的行存储格式没有区分固定长度和可变长度列(所有数据行都使用指向数据列值的头指针),因此在本质上,使用固定长度的CHAR列不一定比使用可变长度VARCHAR列简单。因而,主要的性能因素是数据行使用的存储总量。由于CHAR平均占用的空间多于VARCHAR,因此使用VARCHAR来最小化需要处理的数据行的存储总量和磁盘I/O是比较好的。
三、Mysql数据类型约束
约束是一种限制,它通过对表的行或者列的数据做出限制,来确保表数据的完整性和唯一性,在mysql当中一般有一下这几种约束:
| Mysql关键字 | 含义 |
|---|---|
| NULL | 数据列可包含NULL值 |
| NOT NULL | 数据列不允许包含NULL值 |
| DEFAULT | 默认值 |
| PRIMARY KEY | 主键 |
| AUTO_INCREMENT | 自动递增1,适用于整数类型 |
| UNSIGNED | 无符号 |
| CHARACTER SET name | 指定一个字符集 |
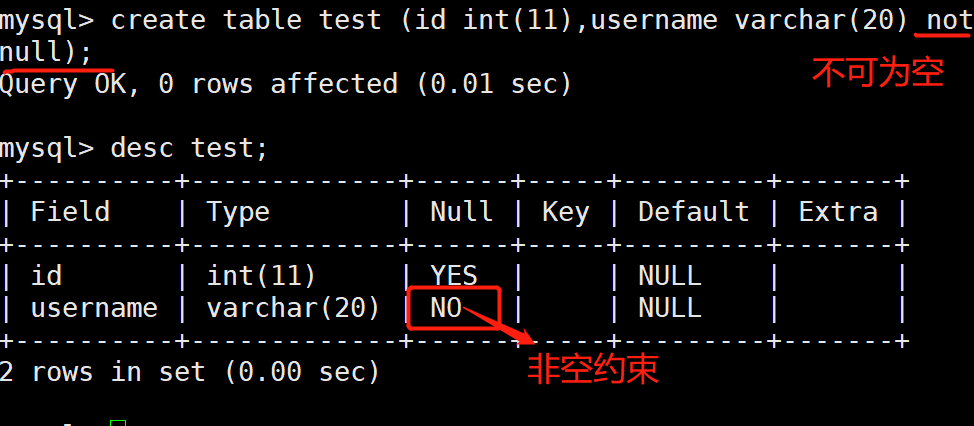
1.非空约束(not null)
就是限制数据库中某个值是否可以为空,null字段值可以为空,not null字段值不能为空。
字段 数据类型 null或not null

ps:如果不生效可以先设置一下sql_mode:
mysql> set session sq1_mode='STRICT_TRANS_TABLES';
2.唯一约束(unique [key|index])
字段添加唯一约束之后,该字段的值不能重复,也就是说在一列当中不能出现一样的值。
#添加唯一约束
alter table 表名 add [constraint[symbol]]
unique [index|key] [index_name] [insex_type] (insex_col_name);
#删除唯一约束
alter table 表名 drop {index|key} index_name;
已经添加的值不能再重复的插入。




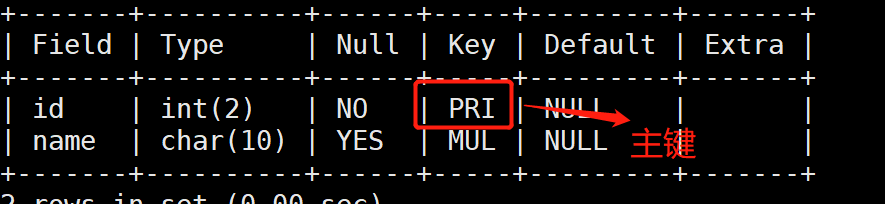
3.主键约束(primary key)
• 主键保证记录的唯一性,主键自动为not null。
• 每张数据表只能存在一个主键not null + unique key,因为一个unique key 又是一个not null的时候,那么它被当做primary key主键。
• 当一张表里没有一个主键的时候,第一个出现的非空且唯一的列被视为有主键。
用法:字段名 primary key
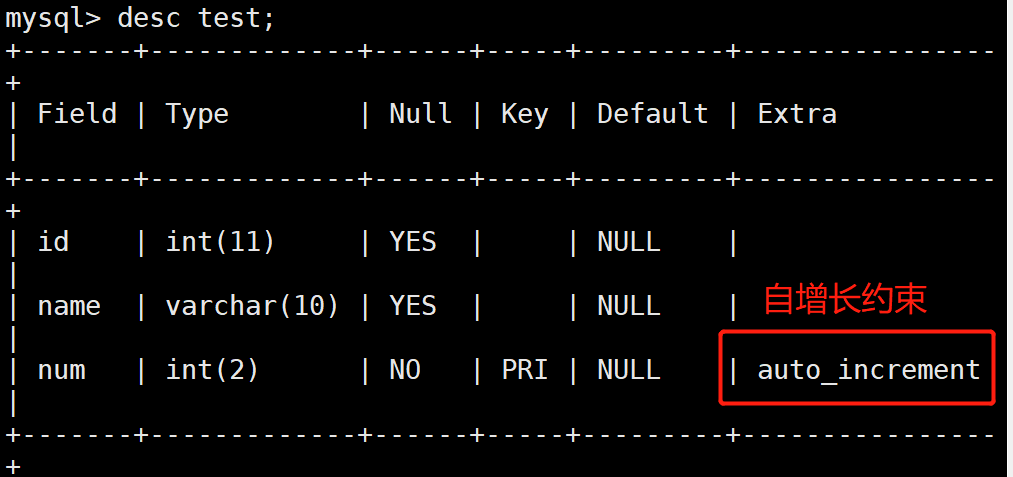
4.自增长约束(auto_increment)
• 自增长AUTO_INCREMENT自动编号,且必须与主键组合使用默认情况下,起始值为1,每次的增量为1。当插入记录时,如果为AUTO_INCREMENT数据列明确指定了一个数值,则会出现两种情况:
①如果插入的值与已有的编号重复,则会出现出错信息,因为AUTO_INCREMENT数据列的值必须是唯一的。
②如果插入的值大于已编号的值,则会把该插入到数据列中,并使在下一个编号将从这个新值开始递增。也就是说,可以跳过一些编号。如果自增序列的最大值被删除了,则在插入新记录时,该值被重用。
#添加表字段语句,必须创建为KEY的字段才能添加自增长
mysql> ALTER TABLE 表名 add(字段 primary key AUTO_INCREMENT);
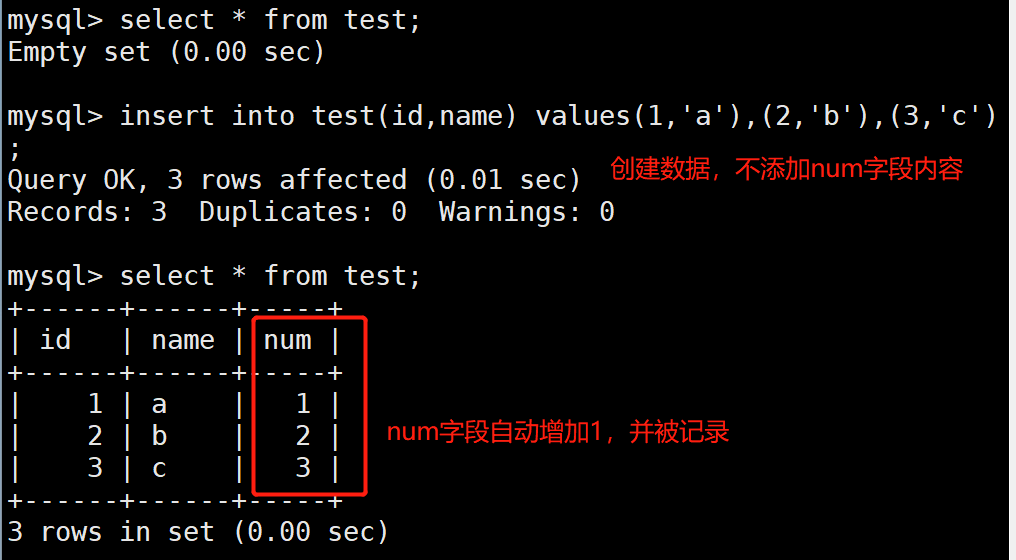
#则插入数据的时候,不输入id的值也会自增长1


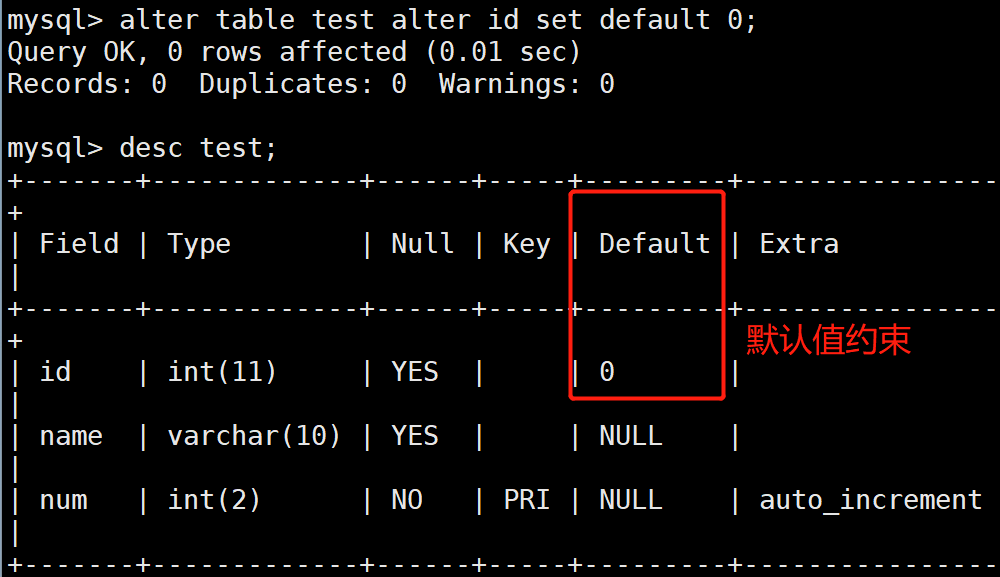
5.默认约束(default)
#添加/删除默认约束
ALTER TABLE tb1_name ALTER [COLUMN] co1_name {SET DEFAULT literal | DROP DEFAULT)
#设置默认值
mysql> ALTER TABLE user ALTER number SET DEFAULT 0;

6.外键约束(foreign key)
• 外键约束要求数据表的存储引擎只能为InnoDB。(查看当前mysql服务器支持的存储引擎命令:show engines)
• 外键的定义:如果同一个属性字段x在表一中是主键,而在表二中不是主键,则字段x称为表二的外键。与外键关联的主表的字段必须设置为主键。要求从表不能是临时表,主表外键字段和从表的字段具备相同的数据类型、字符长度和约束。
外键的实验可参照:https://blog.csdn.net/tu464932199/article/details/126334033?spm=1001.2014.3001.5502最后多表操作一章。
四、MySQL索引
• 索引作为一种数据结构,其用途是用于提升检索数据的效率。例如书的目录。
• 索引是一个排序的列表,在这个列表中存储着索引的值和包含这个值的数据所在行的物理地址。
1.Mysql索引的分类
| 索引名 | 含义 |
|---|---|
| 普通索引(index) | 索引列值可重复 |
| 唯一索引(unique) | 索引列值必须唯一,可以为NULL |
| 主键索引(primary key) | 索引列值必须唯一,不能为NULL,一个表只能有一个主键索引 |
| 全文索引(full text) | 给每个字段创建索引 |
2.Mysql不同类型索引用途和区别
• 普通索引常用于过滤数据。例如:以商品种类作为索引,检索种类为“手机”的商品。
• 唯一索引主要用于标识一列数据不允许重复的特性,相比主键索引不常用于检索的场景。
• 主键索引是行的唯一标识,因而其主要用途是检索特定数据。
• 全文索引效率低,常用于文本中内容的检索。
3.Mysql使用索引
3.1创建索引
3.1.1普通索引(index)
#在创建表时指定
create table 表名 (字段,index 自定义索引名 (字段(索引长度));
#例:
create table test (id int,index id_index (id(20));
#基于表结构创建
create index 自定义索引名 on 表名(字段(索引长度));
#修改表结构创建
alter table 表名 add index 自定义索引名(字段(索引长度));
3.1.2唯一索引(unique)
#在创建表时指定
create table 表名 (字段,unique 自定义索引名 (字段);
#例:
create table test (id int,unique id_index (id);
#基于表结构创建
create unique 自定义索引名 on 表名(字段);
3.1.3主键索引(primary key)
#在创建表时指定
create table 表名 (字段,primary key (字段);
或create table 表名 (字段 primary key);
#修改表结构创建
alter table 表名 add primary key (字段);
ps:主键索引不能使用基于表结构创建的方式创建。
3.2删除索引
3.2.1普通索引(index)
#直接删除
drop index 索引名 on 表名;
#修改表结构删除
alter table 表名 drop index 索引名;
3.2.2唯一索引(unique)
#直接删除
drop index 索引名 on 表名;
#修改表结构删除
alter table 表名 drop index 索引名;
3.2.3主键索引(primary key)
alter table 表名 drop primary key;
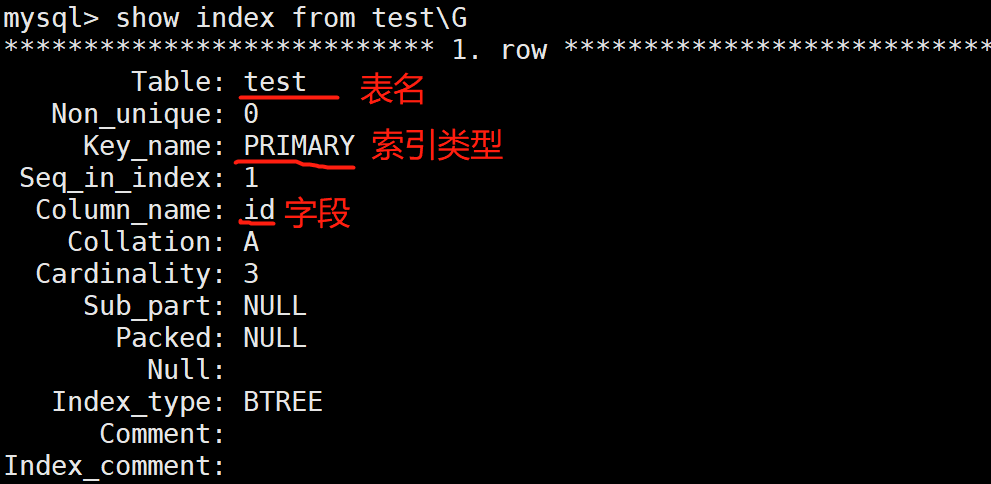
3.3查看索引
show index from 表名\G
3.4选择索引的原则
• 常用于查询条件的字段较适合作为索引,例如where语句和join语句中出现的列。
• 唯一性太差的字段不适合作为索引,例如性别。
• 更新过于频繁(更新频率远高于检索频率)的字段不适合作为索引。
• 使用索引的好处是索引通过一定的算法建立了索引值与列值直接的联系,可以通过索引直接获取对应的行数据,而无需进行全表搜索,因而加快了检索速度。
• 但由于索引也是一种数据结构,它需要占据额外的内存空间,并且读取索引也加会大I/O资源的消耗,因而索引并非越多越好,且对过小的表也没有添加索引的必要,数据量超过300行的表才应该有索引。
• 表的主键、外键必须有索引。
END