工程(二)——DeeplabV3+语义分割训练自制数据集
目录
1、配置环境
1.1 利用conda新建一个环境并激活
1.2 安装pytorch
1.3 更新bashrc环境
2、安装DeeplabV3
2.1 克隆代码
2.2 下载数据集和预训练模型
3、测试算法
4、制作VOC数据集
4.1 转VOC格式
4.2 项目数据准备
5、训练验证数据集
5.1 visdom可视化
5.2 训练网络
5.3 验证模型
6、cityscapes数据集的训练及制作
6.1 训练cityscapes数据集
6.2 cityscapes数据集的制作
1、配置环境
1.1 利用conda新建一个环境并激活
conda create -n deeplabv3 python=3.8
conda activate deeplabv31.2 安装pytorch
conda install pytorch torchvision cudatoolkit=11.3 -c pytorch
//11.3为电脑cuda的版本,其他版本也可以1.3 更新bashrc环境
alias python='/home/cxl/anaconda3/envs/deeplabv3/bin/python3.8'
source ~/.bashrc2、安装DeeplabV3
2.1 克隆代码
git clone https://github.com/VainF/DeepLabV3Plus-Pytorch.git
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple2.2 下载数据集和预训练模型
数据集:链接: https://pan.baidu.com/s/1eiPyD6Esjihiph9yCTYv0Q 提取码: qrcl
权重:链接: https://pan.baidu.com/s/1-CE9WUVkyhg64YD6IDwL9g 提取码: t4wt
下载到DeepLabV3Plus-Pytorch/datasets/data目录下并解压
解压命令
tar xvf VOCtrainval_06-Nov-2007.tar
tar xvf VOCtest_06-Nov-2007.tar
tar xvf VOCtrainval_11-May-2012.tar
将训练模型放在weight文件夹中3、测试算法
使用deeplabv3plus_mobilenet模型
单张图片
python predict.py --input datasets/data/VOCdevkit/VOC2007/JPEGImages/000001.jpg --dataset voc --model deeplabv3plus_mobilenet --ckpt weights/best_deeplabv3plus_mobilenet_voc_os16.pth --save_val_results_to test_results
文件夹图片
python predict.py --input datasets/data/VOCdevkit/VOC2007/JPEGImages --dataset voc --model deeplabv3plus_mobilenet --ckpt weights/best_deeplabv3plus_mobilenet_voc_os16.pth --save_val_results_to test_results
cityscapes
python predict.py --input datasets/data/JPEGImages --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt weights/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_results 
使用deeplabv3_mobilenet模型
python predict.py --input datasets/data/VOCdevkit/VOC2007/JPEGImages/000001.jpg --dataset voc --model deeplabv3_mobilenet --ckpt weights/best_deeplabv3_mobilenet_voc_os16.pth --save_val_results_to test_results
python predict.py --input datasets/data/VOCdevkit/VOC2007/JPEGImages --dataset voc --model deeplabv3_mobilenet --ckpt weights/best_deeplabv3_mobilenet_voc_os16.pth --save_val_results_to test_results4、制作VOC数据集
4.1 转VOC格式
labelme官方转化代码,roadscene_train为图片和json混合的文件
labelme/examples/semantic_segmentation at main · wkentaro/labelme · GitHub
训练数据集
python labelme2voc.py roadscene_train roadscene_train/data_dataset_voc --labels
labels.txt
验证数据集
python labelme2voc.py roadscene_val roadscene_val/data_dataset_voc --labels
labels.txt其中labels.txt文件是自己定义的类别

4.2 项目数据准备
在DeepLabV3Plus-Pytorch/datasets/data文件夹下,创建目录结构如下:
└── VOCdevkit
├── VOC2007
├── ImageSets
├── JPEGImages
└── SegmentationClass
其中:
JPEGImages放所有的数据集图片;
SegmentationClass放标注的数据集掩码文件;
ImageSets/Segmentation下存放训练集、验证集、测试集划分文件
train.txt给出了训练集图片文件的列表(不含文件名后缀)
val.txt给出了验证集图片文件的列表
trainval.txt给出了训练集和验证集图片文件的列表
test.txt给出了测试集图片文件的列表
txt文件名可用一下命令获得,随后用gedit的替换排序去掉后缀名
find . -name "*.*" > lists.txt
5、训练验证数据集
5.1 visdom可视化
#install visdom
pip install visdom
anaconda3/envs/deeplabv3/lib/python3.8/site-packages/visdom
注释掉server.py文件中函数download_scripts_and_run()中的一句
#download_scripts()
# Run visdom server
python -m visdom.server5.2 训练网络
使用deeplabv3plus_mobilenet模型
python main.py --model deeplabv3plus_mobilenet --enable_vis --vis_port 8097 --gpu_id 0 --year 2007 --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16 --num_classes 6 --total_itrs 1000 --ckpt weights/best_deeplabv3plus_mobilenet_voc_os16.pth
batch_size根据电脑性能做调整
num_classes 为种类个数+1
--ckpt 为预训练权重文件
visdom可视化

训练好的模型在checkpoints文件夹中
5.3 验证模型
性能指标统计:用的验证数据集
python main.py --model deeplabv3plus_mobilenet --gpu_id 0 --year 2007 --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16 --ckpt checkpoints/best_deeplabv3plus_mobilenet_voc_os16.pth --test_only --save_val_results图片测试
python predict.py --input datasets/data/VOCdevkit/VOC2007/JPEGImages/img001.jpg --dataset voc --model deeplabv3plus_mobilenet--ckpt checkpoints/best_deeplabv3plus_mobilenet_voc_os16.pth --save_val_results_to test_results1 --crop_size 5136、cityscapes数据集的训练及制作
6.1 训练cityscapes数据集
1、下载cityscapes数据集
Cityscapes Dataset – Semantic Understanding of Urban Street Scenes
2、下载官网数据集功能文件cityscapesScripts-master
将文件一定放对目录
cityscapesScripts/cityscapesscripts at master · mcordts/cityscapesScripts · GitHub

3、预处理数据集
- helpers/label.py文件对训练种类标签进行选择
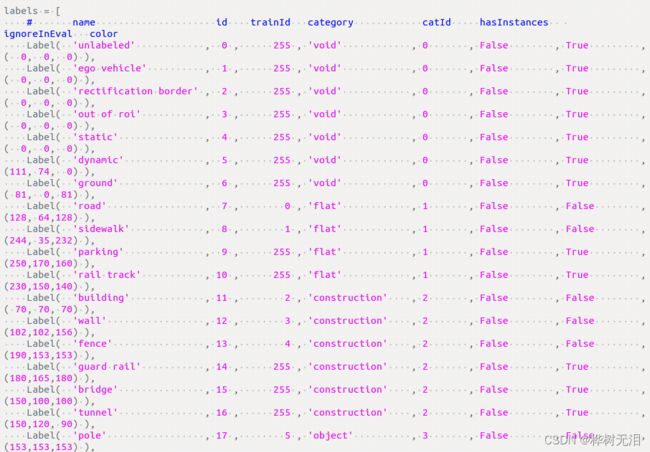
trainID这一列,凡是255的表示均没有加入训练分类。修改trainID和不感兴趣的ignoreInEval改为True
直接运行一下python文件
preparation/createTrainIdLabelImgs.py将多边形格式的注释转换为带有标签ID的png图像,其中像素编码可以在“labels.py”中定义的“训练ID”。preparation/createTrainIdInstanceImgs.py将多边形格式的注释转换为带有实例ID的png图像,其中像素编码由“train ID”组成的实例ID。
4、训练
先打开visdom,不然会报错ConnectionRefusedError: [Errno 111] Connection refused
--vis_port 后面的数字是自己visdom生成的数字

python -m visdom.server
#训练
python main.py --model deeplabv3plus_mobilenet --dataset cityscapes --enable_vis --vis_port 8097 --gpu_id 0 --lr 0.1 --crop_size 321 --batch_size 2 --output_stride 16 --data_root ./datasets/data/cityscapes --ckpt weights/best_deeplabv3plus_mobilenet_cityscapes_os16.pth
#验证
python main.py --model deeplabv3plus_mobilenet --dataset cityscapes --enable_vis --vis_port 8097 --gpu_id 0 --year 2012_aug --crop_val --lr 0.01 --crop_size 513 --batch_size 16 --output_stride 16 --ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth --test_only --save_val_results