一文看懂推荐系统:排序04:视频播放建模
一文看懂推荐系统:排序04:视频播放建模
提示:最近系统性地学习推荐系统的课程。我们以小红书的场景为例,讲工业界的推荐系统。
我只讲工业界实际有用的技术。说实话,工业界的技术远远领先学术界,在公开渠道看到的书、论文跟工业界的实践有很大的gap,
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
王树森娓娓道来**《小红书的推荐系统》**
GitHub资料连接:http://wangshusen.github.io/
B站视频合集:https://space.bilibili.com/1369507485/channel/seriesdetail?sid=2249610
基础知识:
【1】一文看懂推荐系统:概要01:推荐系统的基本概念
【2】一文看懂推荐系统:概要02:推荐系统的链路,从召回粗排,到精排,到重排,最终推荐展示给用户
【3】一文看懂推荐系统:召回01:基于物品的协同过滤(ItemCF),item-based Collaboration Filter的核心思想与推荐过程
【4】一文看懂推荐系统:召回02:Swing 模型,和itemCF很相似,区别在于计算相似度的方法不一样
【5】一文看懂推荐系统:召回03:基于用户的协同过滤(UserCF),要计算用户之间的相似度
【6】一文看懂推荐系统:召回04:离散特征处理,one-hot编码和embedding特征嵌入
【7】一文看懂推荐系统:召回05:矩阵补充、最近邻查找,工业界基本不用了,但是有助于理解双塔模型
【8】一文看懂推荐系统:召回06:双塔模型——模型结构、训练方法,召回模型是后期融合特征,排序模型是前期融合特征
【9】一文看懂推荐系统:召回07:双塔模型——正负样本的选择,召回的目的是区分感兴趣和不感兴趣的,精排是区分感兴趣和非常感兴趣的
【10】一文看懂推荐系统:召回08:双塔模型——线上服务需要离线存物品向量、模型更新分为全量更新和增量更新
【11】一文看懂推荐系统:召回09:地理位置召回、作者召回、缓存召回
【12】一文看懂推荐系统:排序01:多目标模型
【13】一文看懂推荐系统:排序02:Multi-gate Mixture-of-Experts (MMoE)
【14】一文看懂推荐系统:排序03:预估分数融合
提示:文章目录
文章目录
- 一文看懂推荐系统:排序04:视频播放建模
- 视频播放建模
-
- 播放时长
- 视频完播
- 总结
视频播放建模
上节介绍了预估分数的融合,
这节专门讨论视频播放的建模,讨论播放时长和完播率这两个指标,
播放时长
先来研究视频的播放时长。
图文笔记排序和视频的排序有显著的区别。
对于图文笔记,排序的主要依据是这些指标包括点击、点赞、收藏、转发、评论。
也就是说,用户的点击和交互反映出用户对图文笔记的兴趣,
视频有些区别,视频的排序依据还有播放时长和完播,
尤其是对于一些视频网站,时长和完播是最主要的指标,其次才是点击和交互。
如果用户把一个视频看完,即便没有点赞、收藏、转发,也能说明用户对视频感兴趣。
我们先来讨论播放时长,由于它是一个连续变量,
大家自然而然会想到用回归拟合播放时长,
但直接做回归的效果并不好,实践中对播放时长建模最好的方法是下面这篇Youtube的论文。

接下来我要讲这篇论文的方法,但我讲的跟这篇论文有些区别,
原因是直接用这篇论文的方法会有偏差,

这是排序模型用的特征,其中包含用户特征、视频特征、场景特征、统计特征,
把它输入多层神经网络,这个神经网络叫做share button。
被所有任务共享。
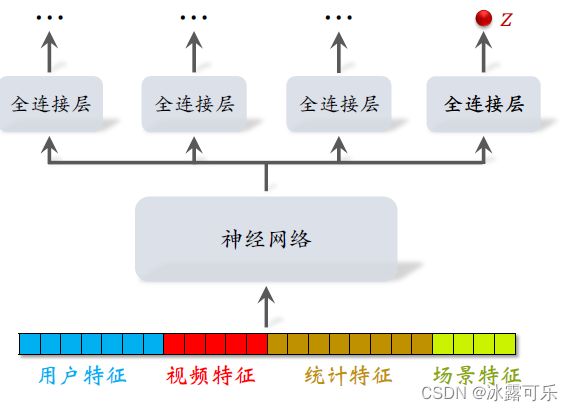
在这个神经网络之上,有很多个全链接阶层,
每个全链接层对应一个目标,比如点击、点赞、收藏、播放时长
这节我们忽略掉点击、点赞、收藏之类的预估目标,
我们只关心对播放时长的预估,
最右边的输出对应播放时长,把全链接层输出的实数记Z,后面要用到它
对Z做sigmoid的变换得到P,
根据sigmoid函数的定义,
P等于Z的指数函数除以一加上Z的指数函数,
我们让P拟合Y,
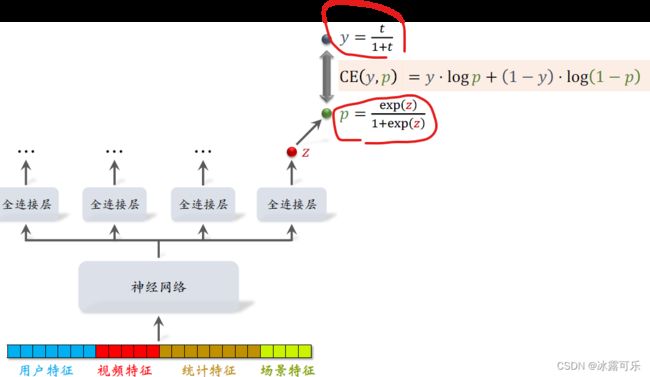
Y是我们自己定义的,它等于T除以一加T
T的意思是用户实际观看视频的时长,T越大则Y也越大。
为了让P拟合Y,我们用Y和P的交叉商作为损失函数,
它等于Y乘以log p加上 一减Y乘以log 1减P。
最小化交叉熵会让P接近Y
大家仔细看一下P和Y
P等于EXP Z除以一加EXP Z,
而Y等于T除以一加T,
很显然,如果P等于Y,那么EXP Z就等于T,
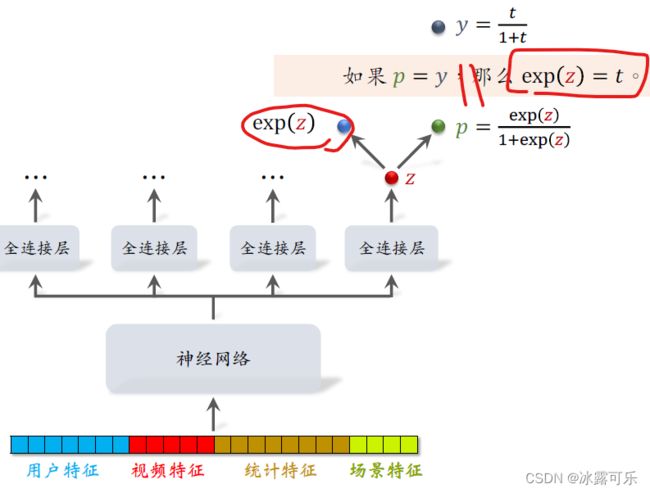
也就是说,我们可以用EXP Z 作为播放时长的预估【预测阶段】,
对Z做指数变换,输出的实数EXPZ就是对播放时长的预估,
总结一下,右边的全连接层输出Z,对Z做sigmoid的变换,得到P
在训练中要用P,用Y与P的交叉商作为损失函数训练模型,
做完训练之后,P就没有用了。
线上做推理的时候,只用Z的指数函数,把它作为对播放时长T的预估,
再重复一遍!!!
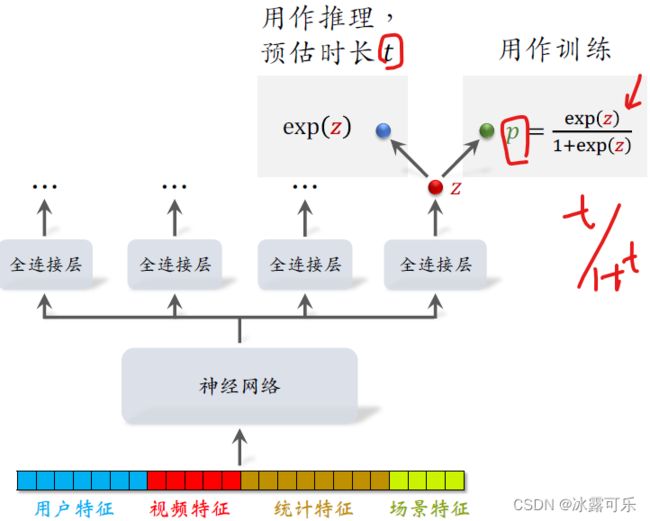
视频的播放时长建模具体这样做,
把最后一个全年阶层的输出记作Z
Z可以是正的也是负的,
在训练的时候要用到P,它等于Z的sigmoid函数,
我们把实际观测到的播放时长叫做T
T被记录在训练数据中,
如果用户没有点击视频,那么T就等于零,做训练的时候要最小化交叉熵做损失函数。
前面我解释过这个交叉的损失函数是怎么来的,

实践中把分母一加T给去掉也没问题,
这就相当于给损失函数做加权权重是播放时长。

线上做推理的时候,把EXP Z作为对播放时长的预估,
最终把EXP Z做一种分公式中的一项,它会影响到视频的排序。
视频完播
前面介绍我对播放时长的预估,这节剩下内容表示对视频完播的预估。
对于视频完播,有两种建模的方法,一种是回归,

举个例子,视频的长度是十分钟,用户实际播放了四分钟就关掉了,
那么实际的播放率是Y等于0.4,
做训练的时候,让模型预估的播放率P,去拟合Y
Y的大小介于零到一之间,用Y和P的交叉熵作为损失函数。
在线上用P作为对完播率的预估,
比方说模型输出P等于0.73,意思是预计播放73%。
这个预估的完播率就像是点赞率、收藏率一样,反映出用户对物品的兴趣,
预估的完播率会作为融分公式中的一项影响视频的排序,
另一种是视频完播的建模方法是:元分类,需要算法工程师自己定义完播指标。

比如完播80%,什么意思?
如果一个视频的长度是十分钟,那么播放超过八分钟就算是正样本,
少于八分钟算是负样本,
这里完播80%只是举个例子,
你也可以把完播定义为播放超过20%,或者播放超过50%,怎么样定义完播都行。
训练要做二元分类播放,超过80%算是正样本,小于80%算是负样本,
做完训练之后,可以用这个二元分类器在线上预估完播率。
举个例子,如果模型输出0.73,意思是视频播放超过80%的概率等于0.73,
预估的播放率会跟点击率等指标一起作为排序的依据。
在实践中,我们不能把预估的完播率直接用到人分公式中,
为什么?从直觉上说,视频越长,完播率就越低。
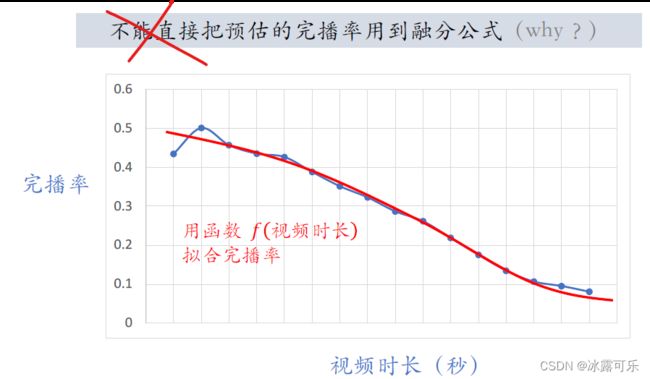
一个15秒的短视频,完播率会很高,
但是15分钟的长视频完播率就会比较低,
如果直接用预估的完播率,
那么会有利于短视频,而对长视频不公平。
看上面那张图,这对视频播放的统计,
横轴是视频时长,就视频的长度有多少秒,
纵轴是视频完播率图中的曲线趋势
很明显,视频越长,完播率就越低,
这跟我们的直觉是符合的,
我们用函数F拟合蓝色的曲线。
函数F的变量是视频长度,
我们要用函数F对预估的完播率做调整,
这样可以公平对待长短视频的完播率。
现场预估完播率之后,可以这样对完播率做调整,
用预估的完播率除以刚才你所说的函数F
F是视频长度的函数,视频越长,函数值F越小,把调整之后的分数记作p finish。

它可以反映出用户对视频的兴趣,而且对长短视频是公平的。
把p finish作为容分公式中的一项,与播放时长、点击率、点赞率等指标一起决定视频的排序。
okay,这节我们讨论了视频的排序视频,有两个独特的指标,
一个是播放时长,
另一个是完播率。
我详细解释了如何对播放时长和完播率做建模
总结
提示:如何系统地学习推荐系统,本系列文章可以帮到你
(1)找工作投简历的话,你要将招聘单位的岗位需求和你的研究方向和工作内容对应起来,这样才能契合公司招聘需求,否则它直接把简历给你挂了
(2)你到底是要进公司做推荐系统方向?还是纯cv方向?还是NLP方向?还是语音方向?还是深度学习机器学习技术中台?还是硬件?还是前端开发?后端开发?测试开发?产品?人力?行政?这些你不可能啥都会,你需要找准一个方向,自己有积累,才能去投递,否则面试官跟你聊什么呢?
(3)今日推荐系统学习经验:我详细解释了如何对播放时长和完播率做建模