深度学习面试题——深度学习的技术发展史
深度学习面试题——深度学习的技术发展史
提示:机器学习和深度学习在大厂中可能要考的东西
《百面机器学习和百面深度学习》一书,在面试前好好看!
深度学习的三次浪潮
说说分类网络的发展
为什么要设计残差连接
说说语义分割网络的发展
deeplabV3有什么改进,具体讲一下
vgg16同期还有哪些网络,inception网络有什么特点
什么是感受野?
讲一下 mobileNet系列,ResNet系列
说说目标检测的发展
讲一下目标检测one stage, two stage,讲一下yoloV1
yolo实现,损失函数
Faster R-CNN 的具体流程
Faster R-CNN 训练和测试的流程有什么不一样
YOLOv3和Faster R-CNN 的差异
YOLO系列有几个版本,YOLOv4 用到了哪优化方法
除了聚类,还有哪些anchor的设计
anchor的理解
Anchor-free的优势在哪里
介绍比赛中的有用的trick有哪些
手写nms
文章目录
- 深度学习面试题——深度学习的技术发展史
-
- @[TOC](文章目录)
- 深度学习的三次浪潮
- 说说分类网络的发展,在图像领域,主要是卷积网络大放异彩
- 为什么要设计残差连接
- 说说语义分割网络的发展
- deeplabV3有什么改进,具体讲一下
- vgg16同期还有哪些网络,inception网络有什么特点
- 什么是感受野?
- 讲一下 mobileNet系列,ResNet系列
- 说说目标检测的发展
- 讲一下目标检测one stage, two stage,讲一下yoloV1
- yolo实现,损失函数
- Faster R-CNN 的具体流程
- Faster R-CNN 训练和测试的流程有什么不一样
- YOLOv3和Faster R-CNN 的差异
- YOLO系列有几个版本,YOLOv4 用到了哪优化方法
- 除了聚类,还有哪些anchor的设计
- anchor的理解
- Anchor-free的优势在哪里
- 介绍比赛中的有用的trick有哪些
- 手写nms
- 总结
文章目录
- 深度学习面试题——深度学习的技术发展史
-
- @[TOC](文章目录)
- 深度学习的三次浪潮
- 说说分类网络的发展,在图像领域,主要是卷积网络大放异彩
- 为什么要设计残差连接
- 说说语义分割网络的发展
- deeplabV3有什么改进,具体讲一下
- vgg16同期还有哪些网络,inception网络有什么特点
- 什么是感受野?
- 讲一下 mobileNet系列,ResNet系列
- 说说目标检测的发展
- 讲一下目标检测one stage, two stage,讲一下yoloV1
- yolo实现,损失函数
- Faster R-CNN 的具体流程
- Faster R-CNN 训练和测试的流程有什么不一样
- YOLOv3和Faster R-CNN 的差异
- YOLO系列有几个版本,YOLOv4 用到了哪优化方法
- 除了聚类,还有哪些anchor的设计
- anchor的理解
- Anchor-free的优势在哪里
- 介绍比赛中的有用的trick有哪些
- 手写nms
- 总结
深度学习的三次浪潮
深度学习真正广为人知是2016 年阿尔法狗战胜围棋高手李世石九段。
深度学习其实是由机器学习中的神经网络发展而来,而神经网络早在上世纪50年代就开始发展了,历经三起两落。
提出神经网络的简单模型为第一个高峰。

最开始的神经网络只有单层,并且是线性的,所以表示能力有限,解决不了“异或”问题。神经网络进入第一次低潮。
上世纪80年代,David Rumelhar和Geoffery E.Hinton提出了反向传播(back propagation)算法,解决了两层神经网络的复杂计算问题,因为引入了“隐藏层”,同时克服了“异或”问题。这是第二次高峰。LeCun同期也提出了,但是他没有发表。
但受限于当时的数据获取、计算资源等,神经网络训练极容易过拟合,后来被SVM压住了一头,进入第二次低潮。
难能可贵的是,Hintion、Bengio、LeCun三巨头依然在神经网络领域默默耕耘,Hintion于2006年发明“深度置信网络”,通过逐层预训练解决了网络过拟合问题。随后为了回击质疑,在2012年ImageNet竞赛中以神经网络方法强势夺冠,接下来便是我们所熟知的第三次高峰了。并且这次高峰开始深刻影响到我们生活的方方面面,2016年开始人工智能时代真的来临。
Hintion的精神很值得我们学习,科研不是一味追热点,追来追去成不了大牛,唯有埋头耕耘,才能在一个领域做出真正的有价值的东西。
说说分类网络的发展,在图像领域,主要是卷积网络大放异彩
(1)LeNet-5,
LeNet-5由Yann LeCun等人在1998年提出,LeNet-5是基于梯度学习的卷积神经网络,并成功应用于手写数字字符识别,在那时的技术条件下就取得了低于1%的错误率,因此被用于全美所有的邮政系统。

LeNet-5包含两层卷积、两层池化、三层全连接。
【杨立昆的最新书籍:科学之路:人,机器与未来】中细细讲解了这段历史,非常精彩
(2)Alex-Net
Alex-Net在2012年ImageNet竞赛中力压群雄,结构与LeNet-5区别不大,但是使用了7x7、11x11的大卷积核增大感受野。使用到的新技术有ReLU Nonlinearity(Rectified Linear Unit)、Local Response Normalization(局部响应归一化)、Overlapping Pooling(覆盖的池化操作)、Dropout

(3)VGG
VGG是Oxford的Visual Geometry Group提出的。该网络主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。
VGG优点: VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。
几个小滤波器(3x3)卷积层的组合比一个大滤波器(5x5或7x7)卷积层好,保持同等感受野的情况下计算量更小:
验证了通过不断加深网络结构可以提升性能。

VGG16包含了16个隐藏层(13个卷积层和3个全连接层),如上图中的D列所示
VGG19包含了19个隐藏层(16个卷积层和3个全连接层),如上图中的E列所示
VGG网络的结构非常一致,从头到尾全部使用的是3x3的卷积和2x2的max pooling。
(4)GoogLeNet
GoogLeNet与VGG不同,该网络主要工作是探索了增加网络的宽度。论文提出了名为Inception 的结构来实现既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。

GoogLeNet优点:提出了Inception 结构
任意nxn的卷积都可以通过1xn卷积后接nx1卷积来替代。实际上,作者发现在网络的前期使用这种分解效果并不好,只有在中度大小的feature map上使用效果才会更好。
探索了网络宽度可以降低网络计算量同时表现优异。GoogLeNet的计算效率明显高于VGGNet,大约只有500万参数,只相当于Alexnet的1/12(GoogLeNet的caffemodel大约50M,VGGNet的caffemodel则要超过600M)。
Average pooling代替全连接层,有效减少参数
探索了1x1卷积的作用,用于升维和降维信息。
(5)ResNet
深度CNN网络达到一定深度后再一味地增加层数并不能带来进一步地分类性能提高,反而会招致网络收敛变得更慢,原因就是网络退化 说白了就是解决梯度消失问题。于是ResNet提出了res-block结构,

原先的网络输入x,希望输出H(x)。现在我们令H(x)=F(x)+x,那么我们的网络就只需要学习输出一个残差F(x)=H(x)-x。当残差为0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能(这句话是理解残差的关键)。
思想其实很朴素,resblock基于一个假设:当把浅层网络特征恒等映射传到深层网络时,深层网络的效果一定会比浅层网络好(至少不会差),所以resblock构造了一个恒等映射,就是增加了一个跳跃结构,让前面的信息直接流入后面的网络层,这样就不怕网络退化了。简化了学习过程,增强了梯度传播。
(6)Xception
Xception 是 Google 继 Inception 后提出的对 Inception-v3 的另一种改进。Xception 的结构基于 ResNet,但是将其中的卷积层换成了Separable Convolution(极致的 Inception模块)。
(7)SENet
ImageNet最后一届竞赛的冠军,提出了SE结构。
对于channel维度的特征融合,卷积操作基本上默认对输入特征图的所有channel进行融合。而MobileNet网络中的组卷积(Group Convolution)和深度可分离卷积(Depthwise Separable Convolution)对channel进行分组也主要是为了使模型更加轻量级,减少计算量。而SENet网络的创新点在于关注channel之间的关系,希望模型可以自动学习到不同channel特征的重要程度。为此,SENet提出了Squeeze-and-Excitation (SE)模块

为什么要设计残差连接
深度CNN网络达到一定深度后再一味地增加层数并不能带来进一步地分类性能提高,反而会招致网络收敛变得更慢,网络太深而梯度消失,导致网络退化。于是ResNet提出了res-block结构,
思想其实很朴素,resblock基于一个假设:当把浅层网络特征恒等映射传到深层网络时,深层网络的效果一定会比浅层网络好(至少不会差),所以resblock构造了一个恒等映射,就是增加了一个跳跃结构,让前面的信息直接流入后面的网络层,这样就不怕网络退化了。简化了学习过程,增强了梯度传播。
说说语义分割网络的发展
语义分割,简单来说就是像素级别的分类任务。

比如上图每一个像素都属于一个类别,比如汽车,行人等,这对自动驾驶场景来说十分有意义。
语义分割网络的基础还是卷积神经网络,不过去掉了全连接层,变成了全卷积网络了。
而且通常采用编码和解码的网络结构。
为什么要采用编码解码的结构呢?
因为前面的分类网络使得图片的分辨率越来越小,这其实是一个编码的过程,而语义分割要得到原图大小的结果图,所以很自然的还需要解码,将特征图还原至原图大小。
语义分割网络的发展过程,主要的改进方向就是想方设法地利用全局上下文信息。这一点大家要牢记。
(1)FCN
Fully Convolution Networks (FCNs) 全卷积网络是第一个端到端的语义分割网络,最大贡献就是成功将卷积网络应用于语义分割上。

在VGG的基础上,将最后一层替换成卷积层,采用线性插值实现上采样,输出原图大小的结果图。
其实原理很简单,不过FCN只有编码结构,最后直接暴力上采样,缺少了解码结构,自然分割效果不会很好。
(2)SegNet
SegNet就是在VGG的基础上,增加了解码的结构,是对FCN的改进,保留了更多语义信息。

SegNet 在解码器中使用反池化对特征图进行上采样,并在分割中保持高频细节的完整性。反池化(up-poolong)我们之前讲过,不再赘述。
(3)U-Net
U-Net 简单地将编码器的特征图拼接至每个阶段解码器的上采样特征图,从而形成一个梯形结构。该网络非常类似于 Ladder Network 类型的架构。
通过跳跃-拼接-连接的架构,在每个阶段都允许解码器学习在编码器池化中丢失的相关特征。
上采样采用转置卷积。
U-Net 比较大的特点就是跳跃结构,充分利用了高低语义信息(上下文信息),实验结果更好。

(4)DeepLab v1
DeepLab v1认为语义分割的全局上下文信息十分重要,越大的感受野越能帮助语义分割的效果提升,基于这一点,
提出 空洞卷积(atrous convolution)(又称扩张卷积(dilated convolution))。我们前面讲过,不再赘述。
使用 CRF(条件随机场) 作为后处理,恢复边界细节,达到准确定位效果。
附加输入图像和前四个最大池化层的每个输出到一个两层卷积,然后拼接到主网络的最后一层,达到 多尺度预测 效果。
(5)DeepLab v2
论文中提出了语义分割中的三个挑战:
由于池化和卷积而减少的特征分辨率。
多尺度目标的存在。
由于 DCNN 不变性而减少的定位准确率。
DeepLab v2最主要的贡献是提出了空洞空间金字塔池化(Atrous Spatial Pyramid Pooling),在不同的分支采用不同的空洞率以获得多尺度图像表征,如下图可以很好的说明。
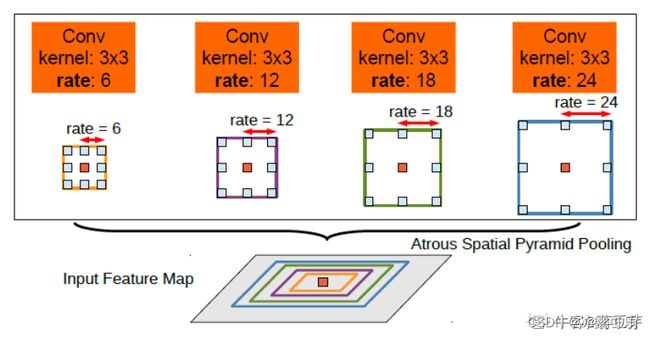
(6)DeepLab v3
DeepLab v3 使用 ResNet 作为主干网络。
在残差块中使用多网格方法(MultiGrid),从而引入不同的空洞率。
deeplabv3 在ASPP模块加入图像级(Image-level)特征,并且使用 BatchNormalization 技巧。

(7)Mask R-CNN
Mask R-CNN 架构相当简单,它是流行的 Faster R-CNN 架构的扩展,在其基础上进行必要的修改,以执行语义分割。
在Faster R-CNN 上添加辅助分支以执行语义分割
对每个实例进行的 RoIPool 操作已经被修改为 RoIAlign ,它避免了特征提取的空间量化,因为在最高分辨率中保持空间特征不变对于语义分割很重要。
Mask R-CNN 与 Feature Pyramid Networks(类似于PSPNet,它对特征使用了金字塔池化)相结合,在 MS COCO 数据集上取得了最优结果。

(8)PSPNet与RefineNet
PSPNet与RefineNet都是想方设法利用上下文信息,
PSPNet是利用空间金字塔池化聚合全局上下文;
RefineNet则是利用远程残差结构聚合上下文。都取得了很好的效果。
deeplabV3有什么改进,具体讲一下
DeepLab v3 使用 ResNet 作为主干网络。
在残差块中使用多网格方法(MultiGrid),从而引入不同的空洞率。
deeplabv3 在ASPP模块加入图像级(Image-level)特征,并且使用 BatchNormalization 技巧。
vgg16同期还有哪些网络,inception网络有什么特点
GoogLeNet。
Inception 的结构实现既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。
探索了网络宽度可以降低网络计算量同时表现优异。
采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。
nxn卷积核改为1xn和nx1卷积核,节约参数,加速运算,减轻过拟合,增加了一层非线性扩展模型表达能力
去除了最后的全连接层,用全局平均池化层
探索了1x1卷积的作用,用于升维和降维信息。
什么是感受野?
感受野用来表示网络内部的不同神经元对原图像的感受范围的大小。
神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着它可能蕴含更为全局,语义层次更高的特征;
相反,值越小则表示其所包含的特征越趋向局部和细节。
因此感受野的值可以用来大致判断每一层的抽象层次。
两层3x3的卷积核的感受野大小为5x5,
三层3x3的卷积核的感受野大小为7x7
答案解析
讲一下 mobileNet系列,ResNet系列
mobileNet系列
(1)MobileNet V1
是谷歌在2017年提出了,专注于移动端或者嵌入式设备中的轻量级CNN网络。该论文最大的创新点是,提出了深度可分离卷积(depthwise separable convolution)。前面已经讲过,不再赘述
v1中使用了RELU6作为激活函数,这个激活函数在float16/int8的嵌入式设备中效果很好,能较好地保持网络的鲁棒性。
(2)MobileNet V2
时隔一年,谷歌的又一力作。V2在V1的基础上,引入了Inverted Residuals和Linear Bottlenecks。本人水平有限,Inverted Residuals和Linear Bottlenecks暂时扯不清楚。
(3)MobileNet V3
发表于2019年,该v3版本结合了v1的深度可分离卷积、v2的Inverted Residuals和Linear Bottleneck、SE模块,提出了h-switch作为激活函数,利用**NAS(神经结构搜索)**来搜索网络的配置和参数(NAS就是不需要人工调参,自动搜索,要先给出搜索空间和搜索方式)。
(1)ResNet V1
提出了残差模块,不再赘述。
(2)Wider ResNet
Wider ResNet提出,每一个Block中的卷积应该更宽。就是将残差模块的恒等映射分支加宽,网络的深度和宽度都可以使得网络性能变好。
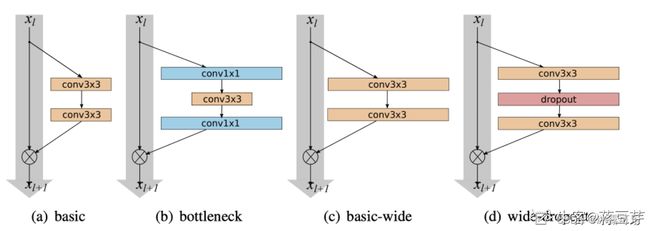
(3)ResNetv2
ResNetv2加入了BN,探索了ReLU和BN放不同的位置对网络性能的影响。
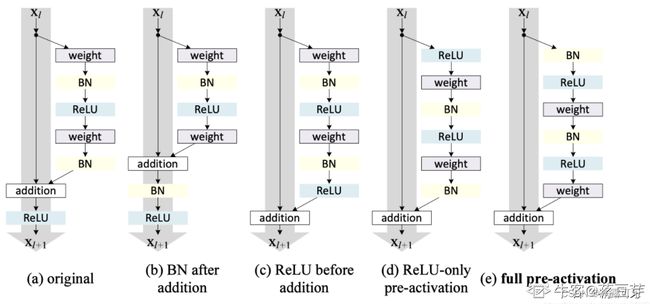
最终选择了(e)。ResNetv2采用pre-activation,先BN再ReLU再权重层。这使得网络更易于训练并且泛化性能也得到提升。
(4)ResNeXt
ResNeXt 同时采用 VGG 堆叠的思想和 Inception 的 split-transform-merge 思想。主要就是单路卷积变成多个支路的多路卷积,不过分组很多,结构一致,进行分组卷积。

(5)DenseNet
DenseNet针对ResNet中的shorcut进行改进。既然shortcut有效,多加点!
DenseNet 的核心思想:对每一层都加一个单独的 shortcut,使得任意两层之间都可以直接相连。
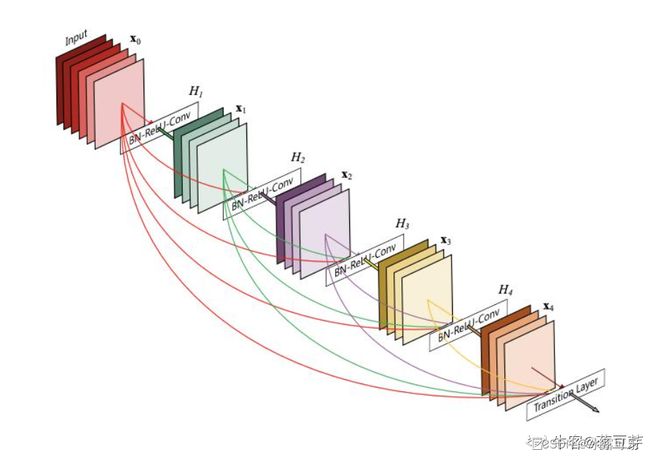
说说目标检测的发展
图像的目标检测任务主要可以分为三大类:
(1)目标分类:识别图片中物体是什么;
(2)目标定位:识别物体的同时,还要定位物体;
(3)多目标检测:多目标的分类与定位。
随着手工特征的性能趋于饱和,目标检测研究在2010年之后达到了一个平稳期,2010-2012年间进展缓慢。2012年,卷积神经网络取得了重大突破(Alex-Net),其作为一个深度神经网络,能够学习一幅图像鲁棒的高级特征表示。
紧接着R. Girshick等人率先提出了具有CNN区域特征(Regions with CNN,RCNN)的方法用于目标检测。从那时起,目标检测开始高速发展。
在深度学习时代,目标检测可以分为两种类型:“两阶段(Two-stage)检测方法”和“单阶段(One-stage)检测方法”,前者将检测定义为“从粗到精”的过程,而后者将检测定义为“一步走”的过程。
许多优秀的基于卷积神经网络的目标检测方法被提出,如基于两阶段的SPPNet、Fast RCNN、Faster RCNN,这些算法首先生成图像中目标物体的建议候选区域,其次再对候选区域做进一步的分类和坐标框回归,得出最后的目标检测结果;
还有基于单阶段的YOLO、SSD和RetinaNet等,这些算法直接通过回归的方式进行图像中目标物体的检测,即分类和回归同时进行。
基于两阶段的CNN检测器
(1)R-CNN
R-CNN 系统分为 3 个阶段,反应到架构上由 3 个模块完成。
生成类别独立的候选区域,这些候选区域其中包含了 R-CNN 最终定位的结果。R-CNN 采用的是 Selective Search 算法生成候选区域。
神经网络去针对每个候选区域提取固定长度的特征向量。R-CNN 采用的是Alexnet
一系列的 SVM 分类器,用于分类特征向量。
R-CNN的方法其实很简单,不再赘述。
测试阶段的目标检测
在测试阶段,R-CNN 在每张图片上抽取近 2000 个候选区域。
然后将每个候选区域进行尺寸的修整变换,送进神经网络以读取特征,然后用 SVM 进行类别的识别,并产生分数。
候选区域有 2000 个,所以很多会进行重叠。针对每个类,通过计算 IoU 指标,采取非极大性抑制,以最高分的区域为基础,剔除掉那些重叠位置的区域。
非极大性抑制
目标检测的过程中在同一目标的位置上会产生大量的候选框,这些候选框相互之间可能会有重叠,此时我们需要利用非极大值抑制找到最佳的目标边界框,消除冗余的边界框。
非极大值抑制的流程如下:
根据置信度得分进行排序
选择置信度最高的边界框添加到最终输出列表中,将其从边界框列表中删除
计算所有边界框的面积
计算置信度最高的边界框与其它候选框的IoU。
删除IoU大于阈值的边界框
重复上述过程,直至边界框列表为空。
R-CNN的缺点第一是太慢,2000多个候选框。第二个缺点不是端到端的方法。第三个缺点是所以特征图固定缩放,影响了精度。
(2)SPPNet
2014年,何凯明等人提出了空间金字塔池化网络(Spatial Pyramid Pooling Networks,SPPNet)。以前的CNN需要固定大小输入,例如AlexNet的输入为224×224,R-CNN也是固定缩放。
SPPNet的主要贡献是引入了空间金字塔池化层,支持CNN生成固定长度表示,而不考虑图像/感兴趣区域的大小,无需重新缩放。
利用SPPNet进行目标检测,可以得到特征图,整个图像只计算一次,避免了重复计算卷积特征。在不牺牲准确率的情况下,比RCNN提升了2倍的速度。
虽然SPPNet有效地提高了检测速度,但它还存在一些弊端:一是它仍然不是一个端对端的方法,二是它只微调了全连接层,而忽略了前面的层。空间金字塔池化层我们前面讲过,不再赘述。
(3)Fast RCNN
2015年,R. Girshick提出了Fast RCNN检测器,这是对RCNN和SPPNet的进一步改进。Fast RCNN使我们能够同时训练检测器和一个边界框(Bounding box)回归器,在相同的网络配置下,在VOC07数据集上,Fast RCNN将mAP从58.5%(RCNN)提升到70.0%,同时检测速度比RCNN快200倍以上。虽然Fast RCNN成功地融合了RCNN和SPPNet的优点,但其检测速度仍然很慢。
Fast RCNN主要有3个改进:
1、卷积不再是对每个region proposal进行,而是直接对整张图像,这样减少了很多重复计算。原来RCNN是对每个region proposal分别做卷积,因为一张图像中有2000左右的region proposal,肯定相互之间的重叠率很高,因此产生重复计算。直接对整张图像卷积后,再使用Selective Search 算法生成候选特征图
2、用ROI pooling进行特征的尺寸变换,因为全连接层的输入要求尺寸大小一样,因此不能直接把region proposal作为输入。
3、将regressor放进网络一起训练,每个类别对应一个regressor,同时用softmax代替原来的SVM分类器。
Fast RCNN将RCNN众多步骤整合在一起,不仅大大提高了检测速度,也提高了检测准确率。当然Fast RCNN的主要缺点在于region proposal的提取使用selective search,目标检测时间大多消耗在这上面(提region proposal 2~3s,而提特征分类只需0.32s),这也是后续Faster RCNN的改进方向之一。
(4)Faster RCNN
2015年,S. Ren等人提出了Faster RCNN检测器。Faster RCNN是第一个端到端的基于深度学习的目标检测方法,同时也是第一个近实时的深度学习探测器。Faster RCNN的主要贡献是引入了区域候选网络(Region Proposal Network ,RPN)。从RCNN到Faster RCNN,对象检测系统中的大多数单个网络块,例如候选检测、特征提取、边界框回归等,已逐渐融入到统一的端到端学习框架。
相比FAST-RCNN,主要两处不同:
(1)使用RPN(Region Proposal Network)代替原来的Selective Search方法产生建议窗口;
(2)产生建议窗口的CNN和目标检测的CNN共享
就是因为优化了Selective Search方法,所以目标Faster RCNN速度很快,接近实时。
基于单阶段的CNN检测器
(1)You Only Look Once(YOLO)
YOLO意思是You Only Look Once,创造性的将候选区和对象识别这两个阶段合二为一,看一眼图片(不用看两眼哦)就能知道有哪些对象以及它们的位置。
YOLO将图片划分为 7x7=49 个网格(grid),每个网格允许预测出2个边框(bounding box,包含某个对象的矩形框),总共 49x2=98 个bounding box。可以理解为98个候选区,它们很粗略的覆盖了图片的整个区域。
去掉候选区这个步骤以后,YOLO的结构非常简单,就是单纯的卷积、池化最后加了两层全连接。单看网络结构的话,和普通的CNN对象分类网络几乎没有本质的区别,最大的差异是最后输出层用线性函数做激活函数,因为需要预测bounding box的位置(数值型),而不仅仅是对象的概率。所以粗略来说,YOLO的整个结构就是输入图片经过神经网络的变换得到一个输出的张量
根据YOLO的设计,输入图像被划分为 7x7 的网格(grid),输出张量中的 7x7 就对应着输入图像的 7x7 网格。或者我们把 7x7x30 的张量看作 7x7=49个30维的向量,也就是输入图像中的每个网格对应输出一个30维的向量。具体来看每个网格对应的30维向量中包含了哪些信息。

20个对象分类的概率:因为YOLO支持识别20种不同的对象(人、鸟、猫、汽车、椅子等),所以这里有20个值表示该网格位置存在任一种对象的概率。
2个bounding box的位置:每个bounding box需要4个数值来表示其位置,(Center_x,Center_y,width,height),即(bounding box的中心点的x坐标,y坐标,bounding box的宽度,高度),2个bounding box共需要8个数值来表示其位置。
2个bounding box的置信度:bounding box的置信度 = 该bounding box内存在对象的概率 x 该bounding box与该对象实际bounding box的IOU
总的来说,30维向量 = 20个对象的概率 + 2个bounding box x 4个坐标 + 2个bounding box的置信度
(2)Single Shot MultiBox Detector(SSD)
SSD由W. Liu等人于2015年提出。这是最重要的第二个单阶段检测器。SSD的主要贡献是引入多分辨率检测技术,这显著提高了检测效率,特别是对于一些小型检测物体,SSD在检测速度和速度上都有优势。
SSD和Yolo一样都是采用一个CNN网络来进行检测,但是却采用了多尺度的特征图,其基本架构如图所示。下面将SSD核心设计理念总结为以下三点:

采用多尺度特征图用于检测
所谓多尺度采用大小不同的特征图,CNN网络一般前面的特征图比较大,后面会逐渐采用stride=2的卷积或者pool来降低特征图大小,这正如上图所示,一个比较大的特征图和一个比较小的特征图,它们都用来做检测。这样做的好处是比较大的特征图来用来检测相对较小的目标,而小的特征图负责检测大目标
采用卷积进行检测
与Yolo最后采用全连接层不同,SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为nxmxp的特征图,只需要采用3x3xp这样比较小的卷积核得到检测值。
设置先验框
在Yolo中,每个单元预测多个边界框,但是其都是相对这个单元本身(正方块),但是真实目标的形状是多变的,Yolo需要在训练过程中自适应目标的形状。而SSD借鉴了Faster R-CNN中anchor的理念,每个单元设置尺度或者长宽比不同的先验框,预测的边界框(bounding boxes)是以这些先验框为基准的,在一定程度上减少训练难度。一般情况下,每个单元会设置多个先验框,其尺度和长宽比存在差异,如图所示,可以看到每个单元使用了4个不同的先验框,图片中猫和狗分别采用最适合它们形状的先验框来进行训练

(3)YOLOv2
YOLOv2相对v1版本,在继续保持处理速度的基础上,从预测更准确(Better),速度更快(Faster),识别对象更多(Stronger)这三个方面进行了改进。其中识别更多对象也就是扩展到能够检测9000种不同对象,称之为YOLO9000。YOLOv2 主要就是加入了很多新技术,不再赘述。最主要的是引入了anchor box

(4)YOLOv3
backbone部分由Yolov2时期的Darknet-19进化至Darknet-53,加深了网络层数,引入了Resnet中的跨层加和操作。
Yolov3借鉴了金字塔特征图思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图检测小尺寸物体。
针对anchor box采用聚类的方法获取合适的尺寸。
Yolov3的整个网络,吸取了Resnet、Densenet、FPN的精髓,可以说是融合了目标检测当前业界最有效的全部技巧。
目标检测框架发展太快了,后来还发展出来anchor-free的检测方法,不再一一讲解。
讲一下目标检测one stage, two stage,讲一下yoloV1
目标检测可以分为两种类型:“两阶段(Two-stage)检测方法”和“单阶段(One-stage)检测方法”,前者将检测定义为“从粗到精”的过程,而后者将检测定义为“一步走”的过程。
如基于两阶段的SPPNet、Fast RCNN、Faster RCNN,这些算法首先生成图像中目标物体的建议候选区域,其次再对候选区域做进一步的分类和坐标框回归,得出最后的目标检测结果;
而基于单阶段的YOLO、SSD和RetinaNet等,这些算法直接通过回归的方式进行图像中目标物体的检测,即分类和回归同时进行。
YOLO意思是You Only Look Once,创造性的将候选区和对象识别这两个阶段合二为一,看一眼图片(不用看两眼哦)就能知道有哪些对象以及它们的位置。YOLO将图片划分为 7x7=49 个网格(grid),每个网格允许预测出2个边框(bounding box,包含某个对象的矩形框),总共 49x2=98 个bounding box。可以理解为98个候选区,它们很粗略的覆盖了图片的整个区域。
去掉候选区这个步骤以后,YOLO的结构非常简单,就是单纯的卷积、池化最后加了两层全连接。单看网络结构的话,和普通的CNN对象分类网络几乎没有本质的区别,最大的差异是最后输出层用线性函数做激活函数,因为需要预测bounding box的位置(数值型),而不仅仅是对象的概率。所以粗略来说,YOLO的整个结构就是输入图片经过神经网络的变换得到一个输出的张量
根据YOLO的设计,输入图像被划分为 7x7 的网格(grid),输出张量中的 7x7 就对应着输入图像的 7x7 网格。或者我们把 7x7x30 的张量看作 7x7=49个30维的向量,也就是输入图像中的每个网格对应输出一个30维的向量。分别是20个对象分类的概率、2个bounding box的位置、2个bounding box的置信度
yolo实现,损失函数
损失函数:
Yolo的损失函数由四部分组成:

(1)对预测的中心坐标做损失
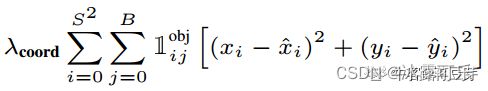
(2)对预测边界框的宽高做损失
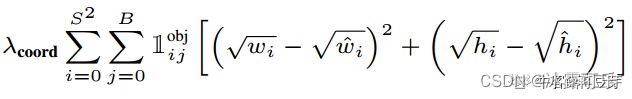
(3)对预测的类别做损失

(4)对预测的置信度做损失
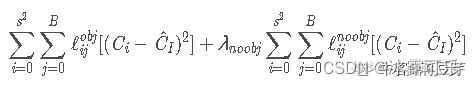
我们发现每一项loss的计算都是L2 loss,即使是分类问题也是。
所以说yolo是把分类问题转为了回归问题。
Faster R-CNN 的具体流程
(1)conv_layer
在输入图像的步骤中,作者把原图都reshape成M×N大小的图片。
一个MxN大小的矩阵经过conv_layers固定变为(M/16)x(N/16)!这样conv_layers生成的feature map中都可以和原图对应起来。最后得到51x39x256
(2)RPN
feature map经过RPN得到候选的anchors,但是这些anchors的框的大小各不相同,需要进行ROIpooling。
(3)ROIpooling
ROI pooling具体操作如下:
1)根据输入image,将ROI映射到feature map对应位置;
2)将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同);
3)对每个sections进行max pooling操作;
(4)分类和bbox回归
classification部分利用已经获得的proposal featuer map,通过full connect层与softmax计算每个proposal具体属于哪个类别(如车,人等),输出cls_prob概率向量;同时再次利用Bounding box regression获得每个proposal的位置偏移量bbox_pred,用于回归更加精确的目标检测框。
Faster R-CNN 训练和测试的流程有什么不一样
交替训练: 利用RPN产生region proposal,将region proposal送入Faster RCNN进行训练。
此时Faster RCNN与RPN还不共享卷积层参数,是两个完全独立的网络。
接着fine-tune RPN,使用Faster RCNN的参数初始化RPN,同时保持RPN与Faster RCNN共享的参数保持不变,仅fine-tune RPN自己的层;接着保持共享的卷积层参数保持不变,仅fine-tune Faster-RCNN自己的层。交替训练整个过程被重复。
测试则是,由RPN产生region proposal,将region proposal送入Faster RCNN进行测试。
YOLOv3和Faster R-CNN 的差异
最大差异是,一个是单阶段,一个是两阶段。(然后详细说说单阶段和两阶段的差异,参考上面回答)
目标检测可以分为两种类型:“两阶段(Two-stage)检测方法”和“单阶段(One-stage)检测方法”,前者将检测定义为“从粗到精”的过程,而后者将检测定义为“一步走”的过程。
如基于两阶段的SPPNet、Fast RCNN、Faster RCNN,这些算法首先生成图像中目标物体的建议候选区域,其次再对候选区域做进一步的分类和坐标框回归,得出最后的目标检测结果;
而基于单阶段的YOLO、SSD和RetinaNet等,这些算法直接通过回归的方式进行图像中目标物体的检测,即分类和回归同时进行。
YOLO系列有几个版本,YOLOv4 用到了哪优化方法
目前有4个版本。(然后展开说一下)
YOLOv4主要的优化是:
使用了新的Backbone: CSDarknet50。
在轻量化的同时保持准确性
降低计算瓶颈
降低内存成本
为了增大感受野,YOLOv4使用了SPP-block(金字塔池化)
改进SAM,改进PAN,和交叉小批量标准化(CmBN),使YOLOv4的设计适合于有效的训练和检测
其他的改进还有加权残差连接、跨阶段部分连接、DropBlock正则化、Mish激活等。
除了聚类,还有哪些anchor的设计
手动设计。
anchor-free
让网络自动学习anchor参数
anchor的理解
anchor通俗来讲就是先验框。
首先预设一组不同尺度不同位置的固定参考框,覆盖几乎所有位置和尺度,每个参考框负责检测与其交并比大于阈值 (训练预设值,常用0.5或0.7) 的目标,
anchor技术将问题转换为"这个固定参考框中有没有认识的目标,目标框偏离参考框多远",不再需要多尺度遍历滑窗,真正实现了又好又快
Anchor-free的优势在哪里
(1)anchor free优点
更大更灵活的解空间、摆脱了使用anchor而带来计算量从而让检测和分割都进一步走向实时高精度
(2)缺点
正负样本极端不平衡
语义模糊性(两个目标中心点重叠)
检测结果不稳定,需要设计更多的方法来进行re-weight
anchor based优点
使用anchor机制产生密集的anchor box,使得网络可直接在此基础上进行目标分类及边界框坐标回归。加入先验,训练稳定
密集的anchor box可有效提高网络目标召回能力,对于小目标检测来说提升非常明显。
缺点
anchor机制中,需要设定的超参:尺度(scale)和长宽比( aspect ratio) 是比较难设计的。这需要较强的先验知识。
冗余框非常之多:一张图像内的目标毕竟是有限的,基于每个anchor设定大量anchor box会产生大量的easy-sample,即完全不包含目标的背景框。这会造成正负样本严重不平衡问题
介绍比赛中的有用的trick有哪些
数据增强
Multi-scale Training/Testing 多尺度训练/测试
Global Context 全局语境
Box Refinement/Voting 预测框微调/投票法
OHEM 在线难例挖掘
Soft NMS 软化非极大抑制
手写nms
def nms(dets, thresh):
x1 = dets[:, 0] #xmin
y1 = dets[:, 1] #ymin
x2 = dets[:, 2] #xmax
y2 = dets[:, 3] #ymax
scores = dets[:, 4] #confidence
areas = (x2 - x1 + 1) * (y2 - y1 + 1) # 每个boundingbox的面积
order = scores.argsort()[::-1] # boundingbox的置信度排序
keep = [] # 用来保存最后留下来的boundingbox
while order.size > 0:
i = order[0] # 置信度最高的boundingbox的index
keep.append(i) # 添加本次置信度最高的boundingbox的index
# 当前bbox和剩下bbox之间的交叉区域
# 选择大于x1,y1和小于x2,y2的区域
xx1 = np.maximum(x1[i], x1[order[1:]]) #交叉区域的左上角的横坐标
yy1 = np.maximum(y1[i], y1[order[1:]]) #交叉区域的左上角的纵坐标
xx2 = np.minimum(x2[i], x2[order[1:]]) #交叉区域右下角的横坐标
yy2 = np.minimum(y2[i], y2[order[1:]]) #交叉区域右下角的纵坐标
# 当前bbox和其他剩下bbox之间交叉区域的面积
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
# 交叉区域面积 / (bbox + 某区域面积 - 交叉区域面积)
ovr = inter / (areas[i] + areas[order[1:]] - inter)
#保留交集小于一定阈值的boundingbox
inds = np.where(ovr <= thresh)[0]
order = order[inds + 1]
return keep
总结
提示:重要经验:
1)这个发展史是非常非常复杂的,重要的是论文的顶会发展史,各种网络层出不穷,各种改进陆陆续续,卷!!
2)没事看看《百面机器学习和百面深度学习》
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。