Redis实现分布式锁方案
一、并发安全问题
先来引入一个问题,复习复习以前多线程和数据库的知识。
如下所示,有一个Product表,带有库存:

在这里提供一个简单的扣减库存的接口:
@Override
@Transactional
public boolean buy(Integer id) {
boolean b = false;
//1)从数据库获取库存
int stock = mapper.getStock(id);
//2)判断库存是否充足
if (stock > 0) {
System.out.println("库存为:" + stock);
//3)扣减库存
b = mapper.updateStock(id, stock - 1);
}
return b;
}
使用jmeter测试,开启n多个线程同时去扣减id为1的数据的库存(每次减一):
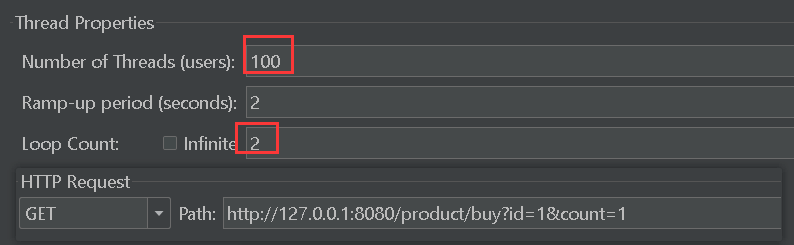
最终的结果显示库存为负数,明显超卖了(有可能是正数),这是在单线程下的并发安全问题。问题的原因是多个线程同时查询,都查询到库存充足,进入if块了,但库存被扣完了,此时就会超卖。
解决这种并发问题有多种:
①在应用层面加锁,也就是加synchronized同步代码块:
public boolean director(Integer id) {
synchronized (this) {
return ((ProductService)AopContext.currentProxy()).buy(id);
}
}
@Override
@Transactional(isolation = Isolation.REPEATABLE_READ, propagation = Propagation.REQUIRED)
public boolean buy(Integer id) {
boolean b = false;
int stock = mapper.getStock(id);
if (stock > 0) {
System.out.println("库存为:" + stock);
b = mapper.updateStock(id, stock - 1);
}
return b;
}为什么这么写?是因为直接加锁有一点问题——>传送门。
②在数据库层面加悲观锁:在第一条查询语句时就加上排他锁,保证了只有一个线程能够同时查询和更新
③数据库层面加乐观锁。但乐观锁在高并发场景下失败率会急剧增加,严重影响效率
update product set stock=#{count},version=version+1 where id=#{id} and version=#{version}
集群服务的情况:
上面的问题解决方案是在单机服务的基础上,如果我们的服务是分布式的,用户访问的是集群系统中的多个节点,此时加synchronized的方式就不行了,但是在数据库层面加锁还可以解决的。
因为synchronized的锁由本地jvm管控,它是在一个进程的基础上实现的;而分布式系统它包含多个jvm,也就是多个进程,我们代码中的锁对象在这多个jvm中都是独立的,锁的逻辑也是独立的,允许多个线程在不同的节点中同时进入synchronized代码块。
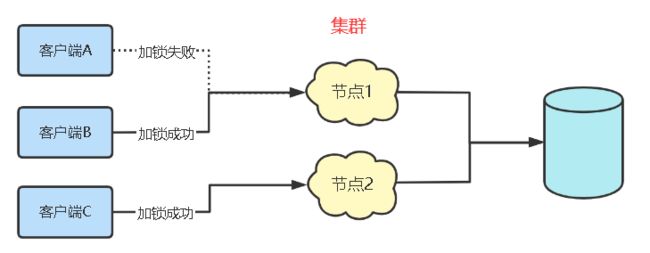
而在数据库层面上锁就不一样了,我们这的数据库是一个全局性的,所有集群中的节点都能感知到它,所以说它可以控制所有节点的加锁情况。但这种锁不是很通用。
二、为什么需要分布式锁?
分布式锁用于在分布式系统中的多个进程之间保证互斥性。单机锁是在一个进程上有用,而分布式系统中一个服务可能是一个集群,分布在多个进程上,此时单机锁就控制不了了,需要使用一个全局的锁,让集群中的所有节点都能感知到它,需要加锁时都去请求该全部锁。
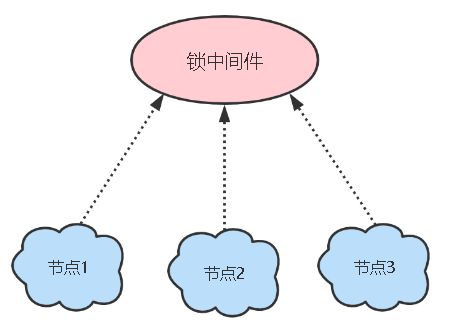
实现分布式锁的方案有哪些?
- 基于数据库的唯一索引。通过insert记录模拟加锁,通过delete删除记录模拟加锁失败,唯一索引保证只能加锁一次,实现简单、性能不高、锁功能少
- 基于ZooKeeper。在/lock目录下创建临时有序节点,判断创建的节点序号是否最小。若是,则表示获取到锁;否则则watch /lock目录下序号比自身小的前一个节点
- 基于redis。通过setnx的结果判断是否加锁成功,性能高,有些地方需配合lua脚本保证命令的原子性
- redisson框架:对redis锁方案的一个封装,简单易用、支持锁重入、支持阻塞等待、Lua脚本原子操作
分布式锁的特性应该是:多进程可见、互斥、高可用、高性能
三、Redis分布式锁方案
前面说的redis通过setnx可以模拟分布式锁这一个过程。如果某线程通过setnx获取到锁,那么后面的线程再执行setnx就会返回0,也就是加锁失败,因为redis单个命令必须是串行执行的,所以可以保证多个线程执行的一致性。
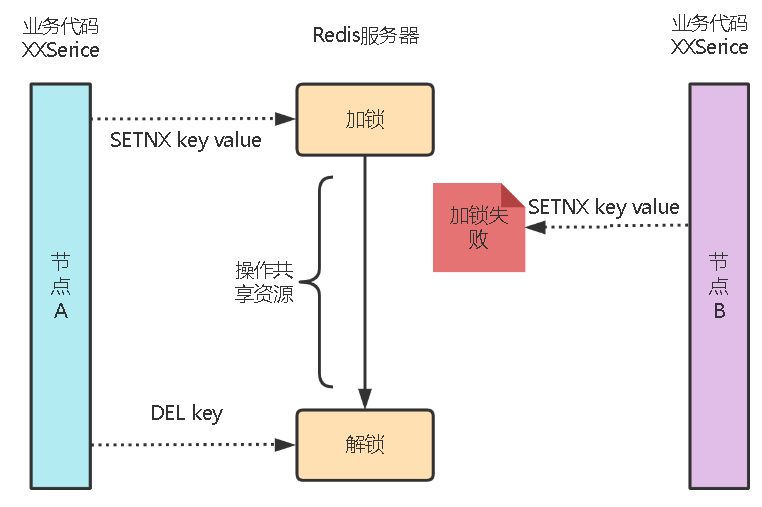
具体实现方式:
private static final String LOCK_NAME = "service:product:lock";
//1.加锁操作
private boolean lock() {
Boolean res = stringRedisTemplate.opsForValue().setIfAbsent(LOCK_NAME, "1");
return res == null ? false : res;
}
//2.解锁操作
private void unlock() {
stringRedisTemplate.delete(LOCK_NAME);
}
public boolean director(Integer id) {
try {
boolean locked = lock();
//如果未获取到锁就等50ms
while (!locked) {
ThreadUtils.sleep(50);
locked = lock();
}
return ((ProductService) AopContext.currentProxy()).buy(id);
} finally {
unlock();
}
}
@Override
@Transactional(isolation = Isolation.REPEATABLE_READ, propagation = Propagation.REQUIRED)
public boolean buy(Integer id) {
boolean b = false;
int stock = mapper.getStock(id);
if (stock > 0) {
System.out.println("库存为:" + stock);
b = mapper.updateStock(id, stock - 1);
}
return b;
}
这是一个简单的redis实现的分布式锁,还比较简陋,存在一些问题:
1.避免死锁
问题:假如节点A获取到锁,如果节点A突然宕机了,此时锁还没有被释放(DEL key操作),所以会出现类似死锁的现象,导致其它节点永远获取不到锁。
解决方案:在申请锁时设定一个过期时间,超过该时间锁自动释放。假设操作共享资源的时间不超过5s,那么过期时间设置为5s即可:
SETNX lock 1 //添加锁
EXPIRE lock 5 //5s自动过期但是还有个问题:这是两条语句,存在并发问题,如果某个客户都执行了第一条语句获取到了锁,但是还没来得及设置过期时间就宕机了,那么死锁还是会出现。
还好在Redis 2.6.12之后,Redis 扩展了SET命令的参数,将SETNX和EXPIRE融合为一个命令:
SET lock 1 EX 5 NX命令解释:EX表示设置过期时间,设置为5s,最后的NX表示SETNX中的NX,不存在key才能设置成功。
另外,过期时间设的不好也会出现问题:
- 不能太长,否则持有锁的节点过期,会让其他节点等待太久,没有必要。
- 不能太短,至少要高于业务的执行时间,如果业务还没完就自动释放锁了,其他线程就会过来占用锁,此时互斥资源就会出错,且还会出现客户端A释放客户端B锁的情况:
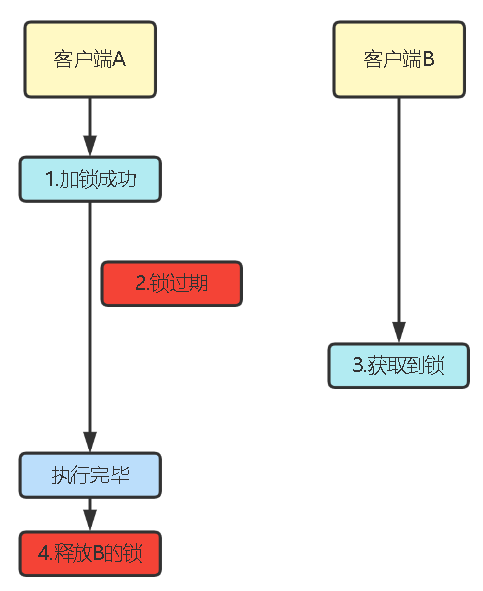
2.避免释放别人的锁
超时时间提前过期,会导致:
1.其他线程也能进入临界区,导致业务出错,出现超卖问题。
2.释放其他线程的锁,导致连锁反应,每次都有两个线程可以同时进入临界区。
这里主要是讲解如何避免释放别人的锁。
解决办法:客户端在加锁时,给锁打上自己的标志,解锁时再校验一下是否为当初的标志,如果是才能解锁,否则啥也不干。
可以用线程ID或UUID作为该标志,如下:
//加锁流程
SET lock $threadId EX 5 NX解锁时进行校验,类似:
if( threadId == redis.get("lock") ){
redis.del("lock");
}但是该逻辑也是两条语句组成的,不是原子的,而且redis没有单独的语句和这两条语句的作用相同。在极端情况下,就会出现一个问题:
当线程A判断该锁的id是自己的时候,还没释放锁之前,可能就停了,如果这时候锁突然过期了,而且又冲过来一个线程B趁机抢到了redis的锁,此时线程A继续执行,结果把线程B的锁给释放了。
那怎么办? 这就需要融合Lua脚本来玩了。
在Redis中可以执行Lua脚本,且是单线程的执行,执行时其他请求必须等待,直到Lua脚本执行完毕。这样就保证了原子性。redis提供的调用函数:
#以另一种方式执行redis命令
redis.call('命令名称','key','参数',...)
#执行LUA脚本(可以传参)。 格式:eval 脚本 参数个数 参数.. 其他参数..
eval script numkeys key [key ...] arg [arg ...]例如:
eval "return redis.call('set','name','jack')" 0它就是执行set name jack操作。
我们的解锁Lua脚本可以如下:
if redis.call('GET',KEYS[1]) == ARGV[1] then
return redis.call('DEL',KEYS[1])
else
return 0
endStringRedisTemplate通过如下方法调用lua脚本:

所以改造后的解锁流程应该如下:
public static final String LOCK_NAME = "service:product:lock";
//脚本对象
private static final DefaultRedisScript UNLOCK_SCRIPT;
//初始化解锁的lua脚本对象
static {
UNLOCK_SCRIPT = new DefaultRedisScript<>();
//设置脚本,可以从外部文件获取,也可以硬编码
UNLOCK_SCRIPT.setScriptText("if redis.call('GET',KEYS[1]) == ARGV[1] then\n" +
" return redis.call('DEL',KEYS[1])\n" +
"else\n" +
" return 0\n" +
"end");
//UNLOCK_SCRIPT.setLocation(new ClassPathResource("unlock.lua"));
UNLOCK_SCRIPT.setResultType(Long.class);
}
private void unlock() {
//执行脚本对象
stringRedisTemplate.execute(UNLOCK_SCRIPT,
Collections.singletonList(LOCK_NAME),
Thread.currentThread().getId()+"");
} 3.锁超时问题
解决方法:
1.加锁时,先设置一个相对较短的过期时间,然后启动一个守护线程,它定时的去检测这个锁的过期时间,如果锁快要过期了,但是锁的持有者还没有完成操作共享资源,那就自动对锁进行续命,重新设置过期时间。
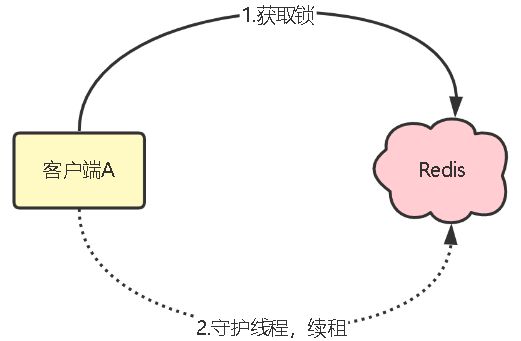
该守护线程称为看门狗线程,是在Redisson框架中的一个实现
2.超时回滚:当我们解锁时发现锁已经被其他线程获取了,说明此时我们执行的操作已经是“不安全”的了,此时需要进行回滚,并返回失败。该方法是乐观锁的一个思想。
使用看门狗这种方式较可靠,但是在极端情况下还是会发生问题:
- 客户端1获取到锁,将值写入到redis的master节点
- 在master节点同步锁的值到slave节点之前,master发生故障
- redis触发故障转移,将其中一个slave升级为新的master
- 此时新的master节点中并不包含锁的信息,因此其它客户端依旧能获取锁
- 此时相当于有两个线程获取到了锁,可能会导致各种预期之外的情况发生,例如最常见的脏数据
解决方法:上述问题的根本原因主要是由于 redis 异步复制带来的数据不一致问题导致的,因此解决的方向就是保证数据的一致。
当前比较主流的解法和思路有两种:
- Redis作者提出的RedLock
- Zookeeper实现的分布式锁
因为这种情况是很少遇见的,也比较难,所以就不做过多讲解。
如果想让分布式锁有更多功能,可以看看Redssion。
RedLock
整体的流程是这样的,一共分为5步:
- 获取当前时间戳T1。
- 依次尝试从5个实例,使用相同的key和value获取锁。当向Redis请求获取锁时,客户端应该设置一个超时时间,这个超时时间应该小于锁的失效时间。例如你的锁自动失效时间为10秒,则超时时间应该在5-50毫秒之间。防止在宕机的Redis实例上浪费时间。如果一个实例不可用,客户端应该尽快尝试去另外一个Redis实例请求获取锁。
- 获取当前时间戳T2。当且仅当从大多数(N/2+1)的Redis节点都取到锁,并且获取锁使用的时间小于锁失效时间时(T2-T1<过期时间),锁才算获取成功。
- 如果取到了锁,其有效时间等于有效时间减去获取锁所使用的时间,T2-T1。
- 如果由于某些原因未能获得锁(无法在至少N/2+1个Redis实例获取锁、或获取锁的时间超过了有效时间),客户端应该在所有的Redis实例上进行解锁(即便某些Redis实例根本就没有加锁成功,防止某些节点获取到锁但是客户端没有得到响应而导致接下来的一段时间不能被重新获取锁)。
可以看出,该方案为了解决数据不一致的问题,直接舍弃了异步复制,只使用 master 节点,同时由于舍弃了slave,为了保证可用性,引入了N个节点,官方建议是5。
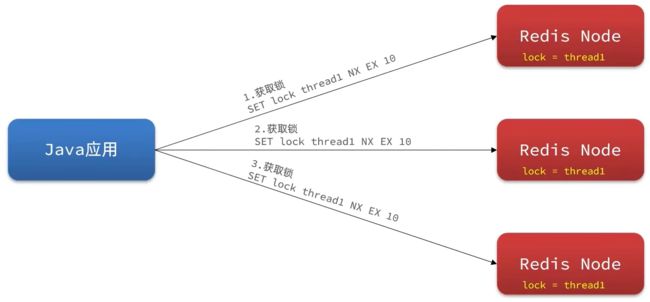
该方案看着挺美好的,但是实际上我所了解到的在实际生产上应用的不多,主要有两个原因:
1)该方案的成本似乎有点高,需要使用5个实例;
2)该方案一样存在问题。
该方案主要存以下问题:
1)严重依赖系统时钟。如果线程1从3个实例获取到了锁,但是这3个实例中的某个实例的系统时间走的稍微快一点,则它持有的锁会提前过期被释放,当他释放后,此时又有3个实例是空闲的,则线程2也可以获取到锁,则可能出现两个线程同时持有锁了。
2)如果线程1从3个实例获取到了锁,但是万一其中有1台重启了,则此时又有3个实例是空闲的,则线程2也可以获取到锁,此时又出现两个线程同时持有锁了。
针对以上问题其实后续也有人给出一些相应的解法,但是整体上来看还是不够完美,所以目前实际应用得不是那么多。