数据竞赛—二手车价格预测-—建模调参
reduce_mem_usage 函数通过调整数据类型,帮助我们减少数据在内存中占用的空间
因为训练数据集往往比较大,而内存会出现不够用的情况,可以通过修改特征的数据类型,从而达到优化压缩的目的
DataFrame.memory_usage(index=True, deep=False)
返回每列的内存使用情况

pandas 中.dropna()的用法:
该函数主要用于滤除缺失数据。如果是Series,则返回一个仅含非空数据和索引值的Series,默认丢弃含有缺失值的行
set_index和rest_index的用法
rest_index:原行索引作为一列保留,列名为index
drop=true:删除原行索引

回归分析是一种统计学上分析数据的方法,目的在于了解两个或多个变量间是否相关、相关方向与强度,并建立数学模型。以便通过观察特定变量(自变量),来预测研究者感兴趣的变量(因变量)
总的来说,回归分析是一种参数化方法,即为了达到分析目的,需要设定一些“自然的”假设。如果目标数据集不满足这些假设,回归分析的结果就会出现偏差。因此想要进行成功的回归分析,我们就必须先证实这些假设。
1、线性性 & 可加性
2、误差项(εε)之间应相互独立。
3、自变量(X1,X2X1,X2)之间应相互独立。
4、误差项(εε)的方差应为常数。
5、误差项(εε)应呈正态分布。
l1,l2正则化

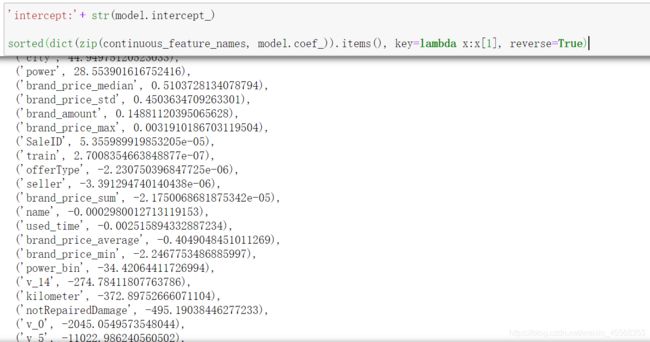
sklearn中的LinearRegression
sklearn.linear_model.LinearRegression(fit_intercept=True,normalize=False,copy_X=True,n_jobs=1)


求解思想:sklearn.linear_model.LinearRegression求解线性回归方程参数时,首先判断训练集X是否是稀疏矩阵,如果是,就用Golub&Kanlan双对角线化过程方法来求解;否则调用C库中LAPACK中的用基于分治法的奇异值分解来求解。在sklearn中并不是使用梯度下降法求解线性回归,而是使用最小二乘法求解。


归一化,标准化,正则化的概念和区别
总结:归一化是为了消除不同数据之间的量纲,方便数据比较和共同处理,比如在神经网络中,归一化可以加快训练网络的收敛性;标准化是为了方便数据的下一步处理,而进行的数据缩放等变换,并不是为了方便与其他数据一同处理或比较,比如数据经过零-均值标准化后,更利于使用标准正态分布的性质,进行处理;正则化而是利用先验知识,在处理过程中引入正则化因子(regulator),增加引导约束的作用,比如在逻辑回归中使用正则化,可有效降低过拟合的现象
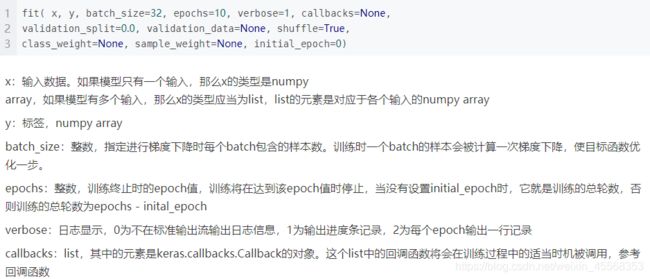
model.fit() fit函数
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表


np.random.randint():

长尾分布:就是指尾巴很长的分布。那么尾巴很长很厚的分布有什么特殊的呢?有两方面:一方面,这种分布会使得你的采样不准,估值不准,因为尾部占了很大部分。另一方面,尾部的数据少,人们对它的了解就少,那么如果它是有害的,那么它的破坏力就非常大,因为人们对它的预防措施和经验比较少。也要所谓的二八法则。

原来的数据集分割为训练集和测试集之后,其中测试集起到的作用有两个,一个是用来调整参数,一个是用来评价模型的好坏,这样会导致评分值会比实际效果要好。(因为我们将测试集送到了模型里面去测试模型的好坏,而我们目的是要将训练模型应用在没使用过的数据上
sklearn中的cross_val_score()函数
sklearn.cross_validation.cross_val_score(estimator, X, y=None, scoring=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch=‘2*n_jobs’)


返回:交叉验证每次运行的评分数组
sklearn.metrics.mean_absolute_error:
sklearn.metrics.mean_squared_error(y_true, y_pred, sample_weight=None, multioutput=’uniform_average’)
 同理
同理
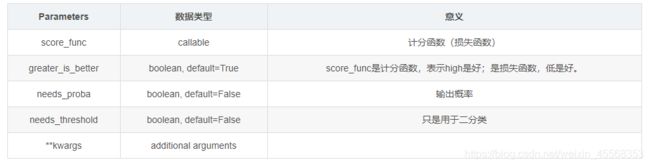
通过sklearn.metrics.make_scorer将估算器传递到自定义得分函数
sklearn.metrics.make_scorer(score_func, greater_is_better=True, needs_proba=False, needs_threshold=False, **kwargs)

但在事实上,由于我们并不具有预知未来的能力,五折交叉验证在某些与时间相关的数据集上反而反映了不真实的情况。通过2018年的二手车价格预测2017年的二手车价格,这显然是不合理的,因此我们还可以采用时间顺序对数据集进行分隔。在本例中,我们选用靠前时间的4/5样本当作训练集,靠后时间的1/5当作验证集,最终结果与五折交叉验证差距不大
、
learning_curve学习曲线
sklearn.model_selection.learning_curve(estimator, X, y, groups=None, train_sizes=array([0.1, 0.33, 0.55, 0.78, 1. ]), cv=’warn’, scoring=None, exploit_incremental_learning=False, n_jobs=None, pre_dispatch=’all’, verbose=0, shuffle=False, random_state=None, error_score=’raise-deprecating’


岭回归
岭回归是一种正则化方法,通过在损失函数中加入L2范数惩罚系项,来控制线性模型的复杂程度,从而使模型更加稳健
lasso回归
Lasso回归和岭回归的区别在于它的惩罚项是基于L1的范数,因此,它可以将系数控制收缩到0,从而达到变量选择的效果。
除了线性模型以外,还有许多我们常用的非线性模型如下

sklearn.svm.SVC详解
sklearn中的SVC函数是基于libsvm实现的,所以在参数设置上有很多相似的地方
决策树参数:
添加链接描述
sklearn.tree.DecisionTreeClassifier(criterion=’gini’, splitter=’best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False)

随机森林:
参数详解:
sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion='gini', max_depth=None,min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0,max_features='auto', max_leaf_nodes=None, min_impurity_split=1e-07,bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0,warm_start=False, class_weight=None)
GradientBoostingRegressor
python中的scikit-learn包提供了很方便的GradientBoostingRegressor和GBDT的函数接口,可以很方便的调用函数就可以完成模型的训练和预测GradientBoostingRegressor函数的参数如下:
sklearn.ensemble.GradientBoostingRegressor(loss='ls', learning_rate=0.1, n_estimators=100, subsample=1.0, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3, init=None, random_state=None, max_features=None, alpha=0.9, verbose=0, max_leaf_nodes=None, warm_start=False, presort='auto')

sklearn.neural_network.MLPClassifier
MLPClassifier(hidden_layer_sizes=(100, ), activation='relu',
solver='adam', alpha=0.0001, batch_size='auto',
learning_rate='constant', learning_rate_init=0.001,
power_t=0.5, max_iter=200, shuffle=True,
random_state=None, tol=0.0001, verbose=False,
warm_start=False, momentum=0.9, nesterovs_momentum=True,
early_stopping=False, validation_fraction=0.1,
beta_1=0.9, beta_2=0.999, epsilon=1e-08,
n_iter_no_change=10)
参数详解
XGBRegressor:



xgb函数
lightgbm
Sklearn接口形式使用lightgbm(from lightgbm import LGBMRegressor)
原生形式使用lightgbm(import lightgbm as lgb)

网格调参
Sklearn调参之sklearn.model_selection.GridSearchCV
GRIDSCACHCV实现了一个“拟合”和“得分”方法。在所使用的估计器中实现了“预测”、“预测函数”、“决策函数”、“变换”和“逆变换”。应用这些方法的估计器的参数通过参数网格上的交叉验证网格搜索来优化。
sklearn.model_selection.GridSearchCV(estimator, param_grid, scoring=None, fit_params=None, n_jobs=1,iid=True, refit=True, cv=None, verbose=0, pre_dispatch=‘2*n_jobs’, error_score=’raise’, return_train_score=’warn’)


贝叶斯调参
原理:给定优化的目标函数(广义的函数,只需指定输入和输出即可,无需知道内部结构以及数学性质),通过不断地添加样本点来更新目标函数的后验分布(高斯过程,直到后验分布基本贴合于真实分布。简单的说,就是考虑了上一次参数的信息,从而更好的调整当前的参数。


贝叶斯包安装

rf_bo.res[‘max’] 这个可以查看当前最优的参数和结果
模型调参
LightGBM是个快速的,分布式的,高性能的基于决策树算法的梯度提升框架。可用于排序,分类,回归以及很多其他的机器学习任务中
XGBoost算法非常热门,它是一种优秀的拉动框架,但是在使用过程中,其训练耗时很长,内存占用比较大
LightGBM。在不降低准确率的前提下,速度提升了10倍左右,占用内存下降了3倍左右。因为他是基于决策树算法的,它采用最优的叶明智策略分裂叶子节点,然而其它的提升算法分裂树一般采用的是深度方向或者水平明智而不是叶,明智的。因此,在LightGBM算法中,当增长到相同的叶子节点,叶明智算法比水平-wise算法减少更多的损失。因此导致更高的精度,而其他的任何已存在的提升算法都不能够达
xgboost和lightgbm对比:LightGBM是直接去选择获得最大收益的结点来展开,而XGBoost是通过按层增长的方式来做

higgs和expo都是分类数据,yahoo ltr和msltr都是排序数据,在这些数据中,LightGBM都有更好的准确率和更强的内存使用量。
怎么调参
贪心调参:
调参的目标:偏差和方差的协调
坐标下降法是一类优化算法,其最大的优势在于不用计算待优化的目标函数的梯度。我们最容易想到一种特别朴实的类似于坐标下降法的方法,与坐标下降法不同的是,其不是循环使用各个参数进行调整,而是贪心地选取了对整体模型性能影响最大的参数。参数对整体模型性能的影响力是动态变化的,故每一轮坐标选取的过程中,这种方法在对每个坐标的下降方向进行一次直线搜索(line search)。首先,找到那些能够提升整体模型性能的参数,其次确保提升是单调或近似单调的。这意味着,我们筛选出来的参数是对整体模型性能有正影响的,且这种影响不是偶然性的,要知道,训练过程的随机性也会导致整体模型性能的细微区别,而这种区别是不具有单调性的。最后,在这些筛选出来的参数中,选取影响最大的参数进行调整即可
参数又可分为两类:过程影响类及子模型影响类。在子模型不变的前提下,某些参数可以通过改变训练的过程,从而影响模型的性能,诸如:“子模型数”(n_estimators)、“学习率”(learning_rate)等。另外,我们还可以通过改变子模型性能来影响整体模型的性能,诸如:“最大树深度”(max_depth)、“分裂条件”(criterion)等
正由于bagging的训练过程旨在降低方差,而boosting的训练过程旨在降低偏差,过程影响类的参数能够引起整体模型性能的大幅度变化。一般来说,在此前提下,我们继续微调子模型影响类的参数,从而进一步提高模型的性能
Grid Search 调参:
通过循环遍历,尝试每一种参数组合,返回最好的得分值的参数组合
总结
在本章中,我们完成了建模与调参的工作,并对我们的模型进行了验证。此外,我们还采用了一些基本方法来提高预测的精度,提升如下图所示