深度学习(八) Transformer 理论部分
Transformer 理论部分
- 前言
- 一、Seq2Seq
-
- 1.Encoder-Decoder
- 2.什么是Seq2Seq?
- 3.seq2seq的应用领域
- 4.Attention机制
-
- 1.为什么要引入Attention?
- 2.Attention机制是什么?
- 3.Attention机制的计算
- 二、self-attention
-
- 1.self-attention与attention的区别
- 2.self-attention的过程
- 3.计算过程简化(矩阵化)
- 4.Multi-head Self-attention(多头自注意力机制)
- 三、Positional Encoding(位置编码)
-
- 1.为什么要使用Positional Encoding?
- 2.绝对位置编码
- 3.相对位置编码
- 四、Transformer
-
- 1.Encoder
- 2.Autoregressive Decoder(自回归模型译码器)
-
- 1.Autoregressive Decoder的结构
- 2.Masked Self-attention
- 3.自动决定输出位数
- 3.Non-autoregressive Decoder(非自回归型译码器)
-
- 1.非自回归型译码器与回归型译码器的区别
- 2.fertility相关
- 3.Sequence-level knowledge distillation(知识蒸馏)
- 4. NPD-noisy parallel decoding
- 4.Cross attention
- 五、Pointer Network
-
- 1.为什么要使用Pointer Network?
- 2.如何简单实现Pointer Network
- 3.pointer network与seq2sq相结合
- 总结
前言
前面我们介绍了RNN循环神经网络,这一篇文章将会介绍一个特别重要的一个框架:Transformer,他能很好地克服RNN所带来的缺点
一、Seq2Seq
1.Encoder-Decoder
Encoder-Decoder 并不是一个具体的模型,而是一个通用的框架。
Encoder和Decoder部分可以是任意的文字,语音,图像,视频数据,模型可以采用CNN,RNN,BiRNN、LSTM、GRU等等。
Encoder-Decoder框架有一个最显著的特征就是它是一个End-to-End学习的算法
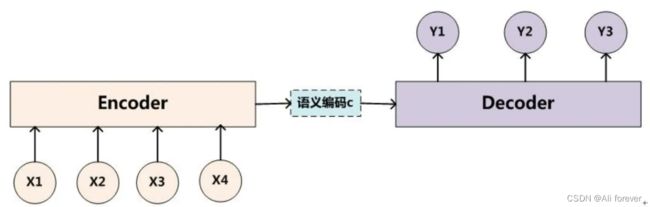
读入数据的过程叫做Encoder,即将输入的东西存储下来,而这个记忆可以叫做Context,然后我们再根据这个Context,转化成其他形式输出,这个过程叫做Decoder。其实就是编码-存储-解码的过程。
编码就是将输入序列转化转化成一个固定长度向量, 解码就是将之前生成的固定向量再转化出输出序列。
Encoder-Decoder框架最大的缺点就是中间的向量c长度是固定的,对于较长的句子,我们很难寄希望于将输入的序列转化为定长的向量而保存所有有效信息
2.什么是Seq2Seq?
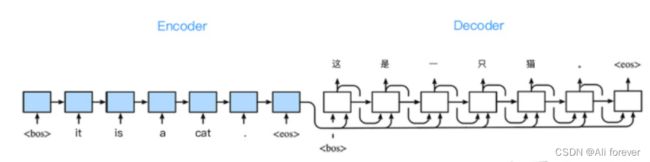
seq2seq是序列到序列,是从一个序列生成另外一个序列。 它涉及两个过程:一个是理解前一个序列,另一个是用理解到的内容来生成新的序列。至于序列所采用的模型可以是RNN,LSTM,GRU,其它序列模型等。
seq2seq中输入序列和输出序列的长度是可变的
3.seq2seq的应用领域
- 机器翻译:Google翻译就是完全基于 Seq2Seq+Attention机制开发的。
- 文本摘要自动生成:输入一段文本,输出这段文本的摘要序列。
- 聊天机器人:第二个经典应用,输入一段文本,输出一段文本作为回答。
- 语音识别:输入语音信号序列,输出文本序列。
- 阅读理解:将输入的文章和问题分别编码,再对其解码得到问题的答案。
- 图片描述自动生成:自动生成图片的描述。
- 目标检测
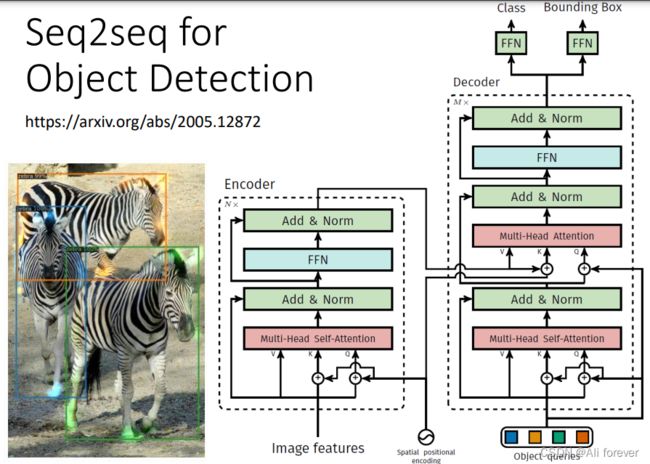
- 多标签分类
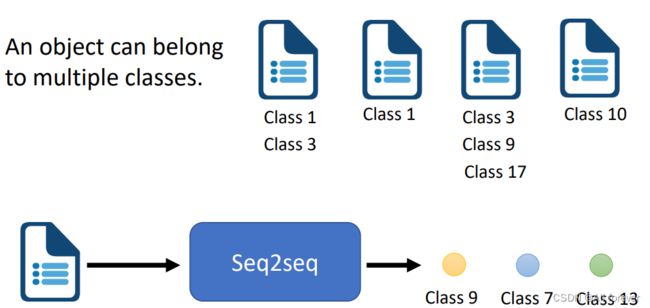
4.Attention机制
1.为什么要引入Attention?
我们前面说过,Encoder-Decoder框架的最大缺点就是无法保证存储掉所有信息,而就算使用了前面我们所说的LSTM模型也会丢失一定的信息,那么我们将引入一种新的机制:Attention ,用于解决信息过长导致信息丢失的问题。
2.Attention机制是什么?
本质上来说,Attention是从大量信息中有筛选出少量重要信息,并聚焦到这些重要信息上,忽略大多不重要的信息。权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
Attention函数的本质可以被描述为一个查询(query)到一系列(键key-值value)对的映射。
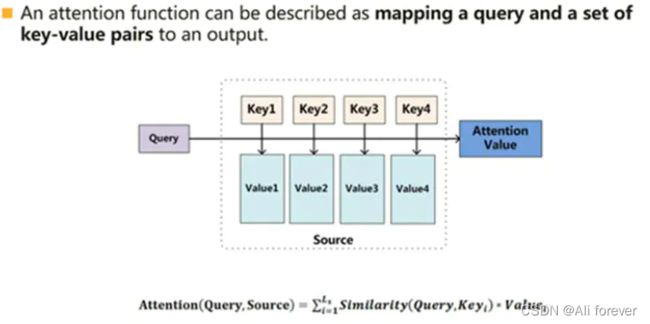
3.Attention机制的计算
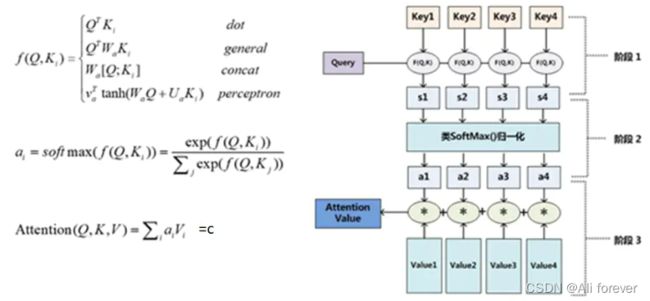
本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数
其计算方式:
- 计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数。
- 引入SoftMax对上面的得分进行数值转换,进行归一化,更加突出重要元素的权重。
- 对Value进行加权求和,即得到了最终的Attention数值。
二、self-attention
1.self-attention与attention的区别
Attention指是 Target 和 Source 之间的 Attention 机制。
Self Attention分别在source端和target端进行,仅与source input或者target input自身相关的Self Attention,捕捉source端或target端自身的词与词之间的依赖关系;然后再把source端的得到的self Attention加入到target端得到的Attention中,捕捉source端和target端词与词之间的依赖关系。
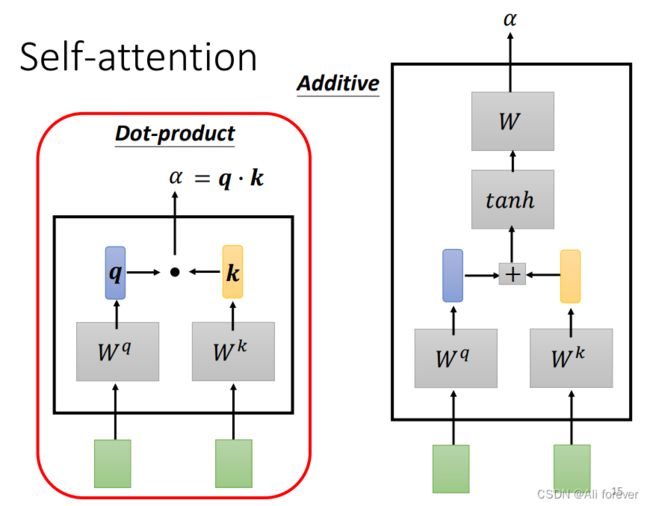
这样做不仅减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
2.self-attention的过程
- 将输入单词转化成嵌入向量,可用到我们前面所讲的word embedding
- 随机初始化Query矩阵、Key矩阵和Value矩阵,并且与词嵌入向量相乘得到q,k,v
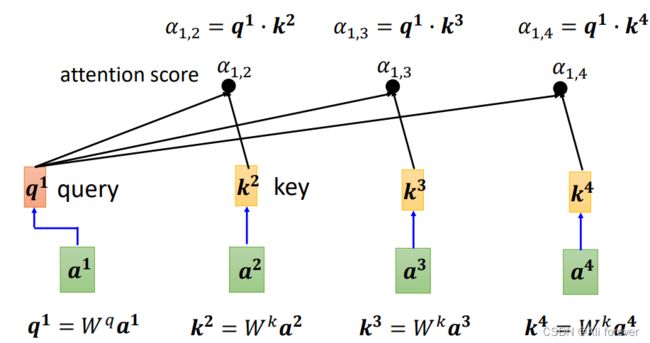
- 计算Self-Attention的分数值,分数值决定了当我们在某个位置encode一个词时,对输入句子的其他部分的关注程度。需要利用softmax函数对其进行归一化。
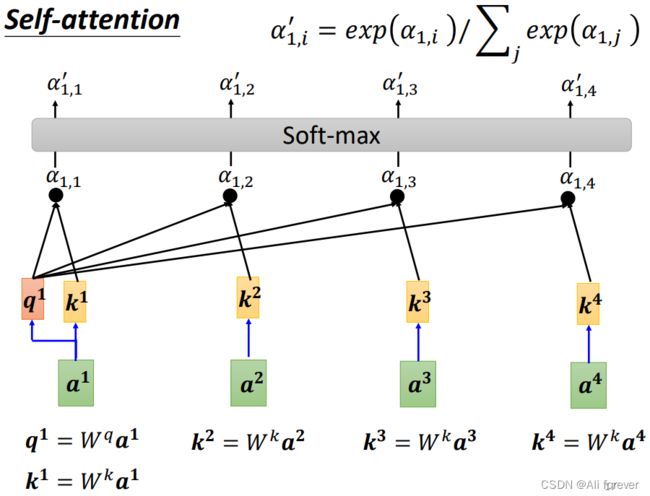
- 把每个Value向量和softmax得到的值进行相乘,然后将它们求和,力求于关注语义上相关的单词,并弱化不相关的单词。得到的结果即是self-attetion层在当前位置的输出(在我们的例子中是对于第一个单词)。

3.计算过程简化(矩阵化)
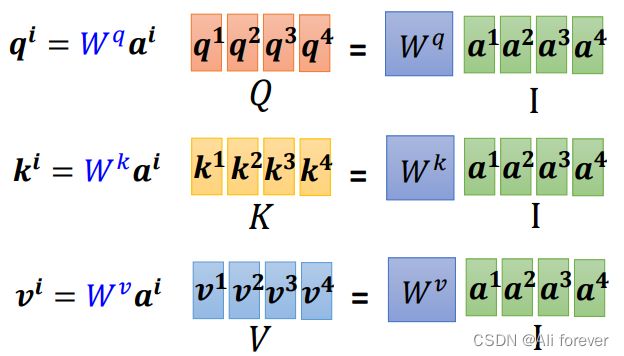
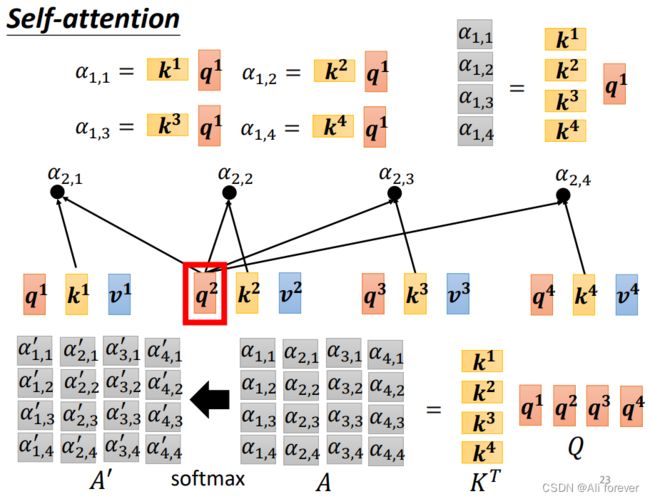
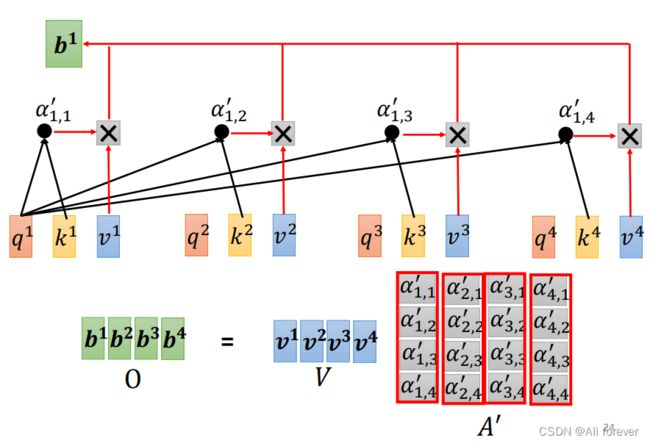

4.Multi-head Self-attention(多头自注意力机制)
多头自注意力机制希望每个注意力头,只关注最终输出序列中一个子空间,互相独立。其核心思想在于,抽取到更加丰富的特征信息。同时优化每个词汇的不同特征部分,从而均衡同一种注意力机制可能产生的偏差,让词义拥有来自更多元的表达。
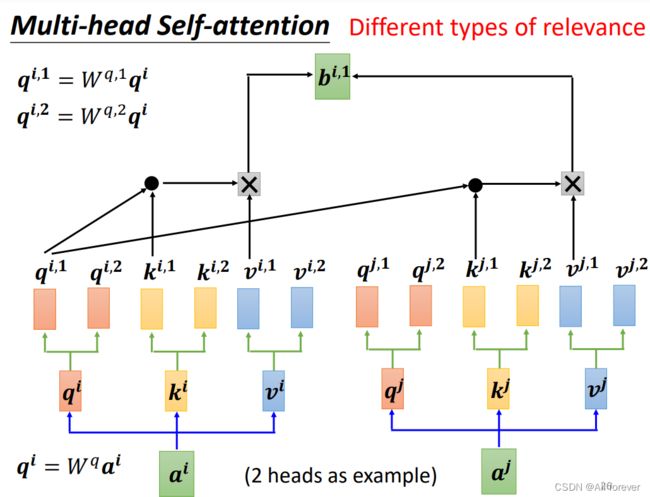
举例:
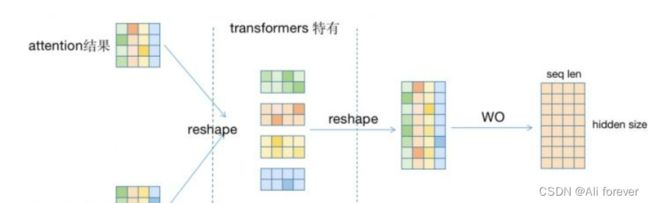
一开始我们可以看到输入的隐藏层是一个8*4的矩阵,8为每个token的embedding的维度,4是这个序列有4个token。
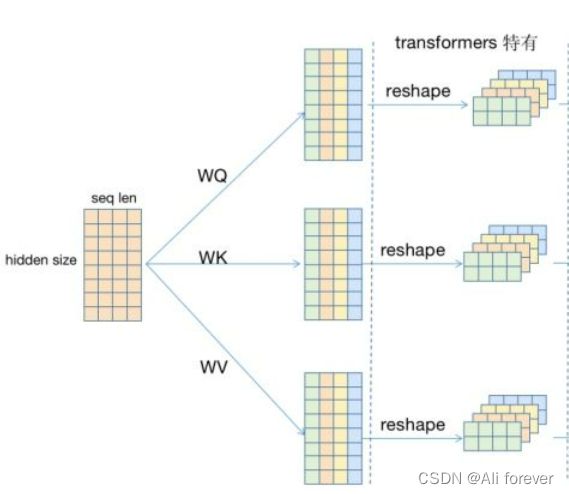
Multi-head Self-attention将矩阵拆分拆成4*4的矩阵,这样做可以分散特征的数量。
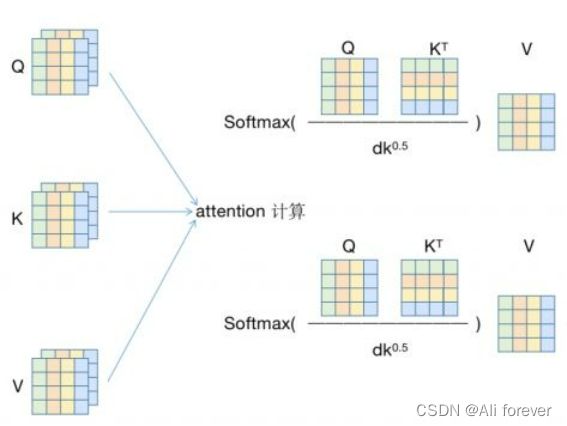
最后我们将会把结果拼接起来,完成这一次self-attention的操作
三、Positional Encoding(位置编码)
1.为什么要使用Positional Encoding?
Transformer的输入是将句子中的所有单词一次性输入到网络中进行学习,这使得序列的顺序信息丢失。因此我们需要通过其他途径将序列的顺序信息加入到模型中,这时候我们就引出了位置编码这个概念。
2.绝对位置编码
现在普遍使用的一种方法Learned Positional Embedding编码绝对位置,相对简单也很容易理解。直接对不同的位置随机初始化一个postion embedding,加到word embedding上输入模型,作为参数进行训练。

3.相对位置编码
绝对位置编码会遇见比训练时所用的序列更长的序列,不利于模型的泛化,并且还会导致编码值过大。所以我们提出了通过相对位置进行编码
-
Sinusoidal Position Encoding
使用正余弦函数表示绝对位置:这样设计的好处是位置的positional encoding可以被位置线性表示,反应其相对位置关系
P E t = [ sin ( w 0 t ) , cos ( w 0 t ) , sin ( w 1 t ) , cos ( w 1 t ) , . . . sin ( w d m o d e l 2 − 1 t ) , cos ( w d m o d e l 2 − 1 t ) ] PE_t=[\sin(w_0t),\cos(w_0t),\sin(w_1t),\cos(w_1t),...\sin(w_{\frac{d_{model}}{2}-1}t),\cos(w_{\frac{d_{model}}{2}-1}t)] PEt=[sin(w0t),cos(w0t),sin(w1t),cos(w1t),...sin(w2dmodel−1t),cos(w2dmodel−1t)]
由于sin/cos,位置向量的每一个值都位于[-1, 1]之间。同时,纵向来看,图的右半边几乎都是蓝色的,这是因为越往后的位置,频率越小,波长越长,所以不同的t对最终的结果影响不大。而越往左边走,颜色交替的频率越频繁。

-
Complex embedding
为了更好的让模型捕获更精确的相对位置关系,使用了复数域的连续函数来编码词在不同位置的表示
四、Transformer
1.Encoder
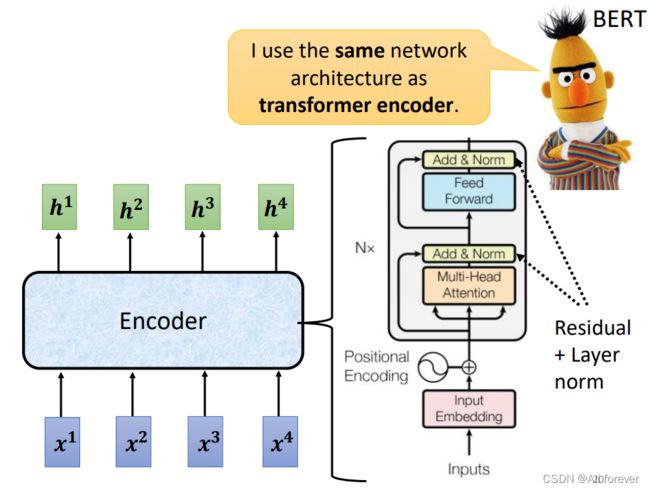
- 我们可以看到输入Input之后,我们前面说过,为了保证存放有顺序信息,我们需要Input Embedding和Positional Encoding相结合
- 将编码后的结果作为多头注意力机制的输入,得到相应的output
- 接下来我们将会剖析一下这个Add&Norm部分。他的本质上是一个ResNet加上我们前面所说的self-attention机制,然后经过归一化。

- 我们的编码器和解码器的每一层都包含一个完全连接的前馈网络,分别相同地应用于每个位置,含两个带有ReLU激活的线性转换。
Encoder 中将一个可变长度的信号序列变为固定长度的向量表达
2.Autoregressive Decoder(自回归模型译码器)
1.Autoregressive Decoder的结构
我们的译码器一般有两种方式:Autoregressive和Non-autoregressive,而AutoRegressive(AR, 自回归)模型又称为时间序列模型,数学表达式为:
y ( t ) = ∑ i = 1 n a i y ( t − i ) + e ( t ) y(t)=\sum_{i=1}^na_iy(t-i)+e(t) y(t)=i=1∑naiy(t−i)+e(t)
可以看出这是一个线性模型,因为在实际情况下我们需要实时对进入的数据进行翻译,而不可能知道未来的数据,所以我们利用前期若干时刻的随机变量的线性组合来描述以后某时刻随机变量的线性回归模型。
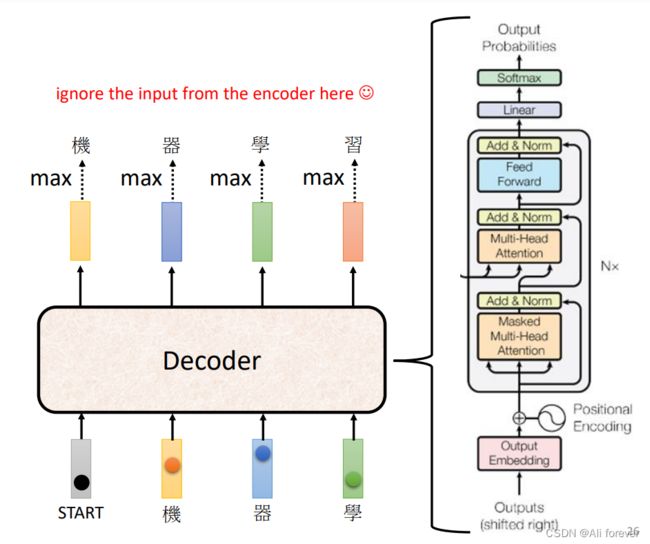
2.Masked Self-attention
同时我们可以看到,这个Decoder的结构与Encoder十分地相似,只是比Encoder模型多了一个Masked的Attention层,接下来将会看看这个层的不同之处。
前面我们所介绍的self-attention它会将所有的输入一起关联起来,可以理解为一次性输入整个语句,然后在内部作一个全连接,把所有的输入关联起来的一个注意力机制。
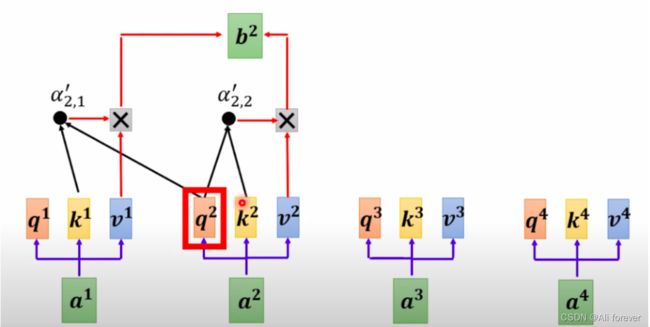
但考虑到现实情况中,我们只能知道前面的输入,而无法知道未来的输入,所以我们并不考虑未来的输入,而是一开始输入一个shifted right即前面所转换过的内容。然后在masked self-attention里面并只考虑前面的情况,把未来的输入给masked掉了。
3.自动决定输出位数
前面我们说过,Transformer可以做到自行决定输出序列的长度,这是CNN中不具备的,那么他是如何实现这一个功能的呢
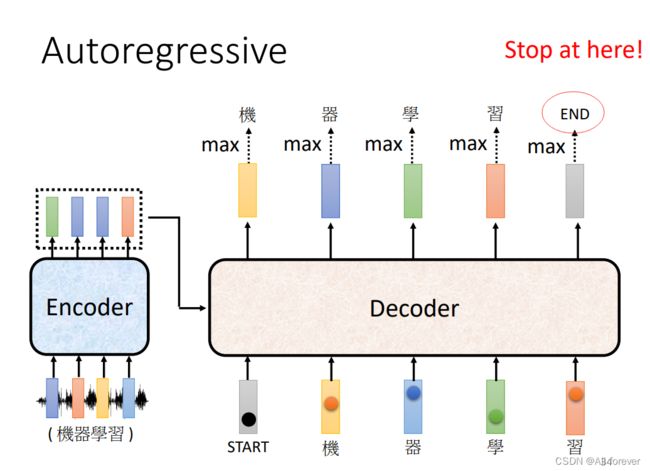
其实实际上很简单,我们只需要在输入给它一个特别的符号,然后在输出端识别到这个符号,让它输出了这个符号后,就停止了译码了,这个符号就是END。
3.Non-autoregressive Decoder(非自回归型译码器)
1.非自回归型译码器与回归型译码器的区别
Autoregressive 模型需要用已生成的词来预测下一个位置的词,Non-Autoregressive模型打破了生成时的串行顺序,可以并行解码出整个目标句子,从而解决AT模型所带来的问题。
NAT需要通过另外用一个模型来预测输出长度,或者输出很长的序列,而忽略结束字符后面的所有输出
但是非自回归模型直接假设目标序列的每个词都是独立的,会产生 Multi-modality(多模态问题),
由于同一段原文经常有多种可行的潜在译文,使得非自回归翻译模型在解码时会出现不同位置的目标语言词是从不同的潜在译文中选取的问题。然而这一独立性假设过强,显然与实际问题不符,所以一般NAT模型的表现率会比AT要差
2.fertility相关
为了抑制Multi-modality问题,我们采取一种新的方法fertitity预测器,他的最主要特点是:一个source word可以对应到几个target (language) words的度量
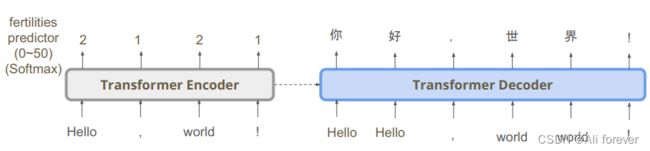
我们的Encoder输出的是词汇所需要翻译出来的长度,之后我们将相应的英文词语复制相应的次数,输入到Decoder中,就能翻译出相应的句子,并且他能进行多标签对应,根据不同的次数还能翻译出不同的效果

还有一种fine-tune的方法,把”静态“的词对齐,扩展为”动态的“。即,把强化学习的loss加到fertility的classifier的loss上面,从而”迭代式”地更新fertility model的能力
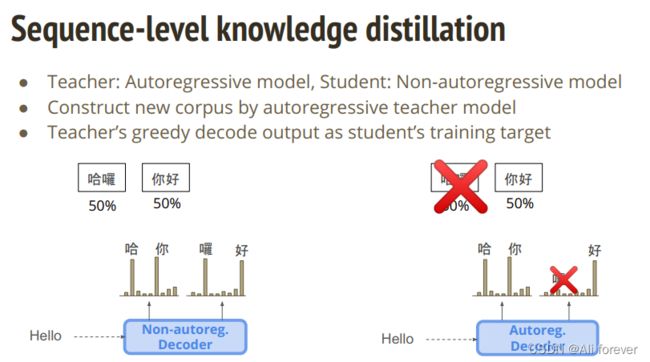
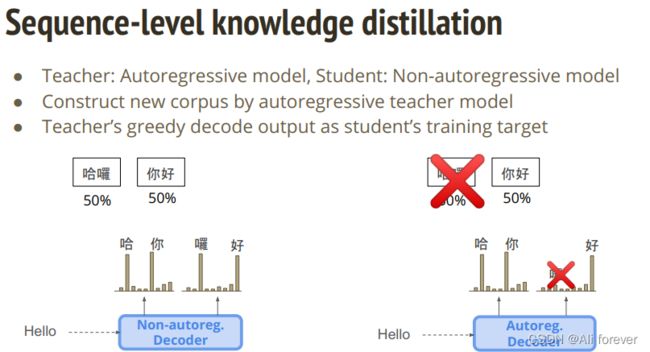
3.Sequence-level knowledge distillation(知识蒸馏)
还有另外一种方法,就是进行知识蒸馏,它的过程是这样的:
-
teacher=自回归模型;student=非自回归模型;
-
根据自回归模型teacher来构造新的corpus,即
-
新的corpus是:
这样做利用了AT中的非独立性,可以有更大的偏向性,大大降低了NAT中出现概率相等的情况。
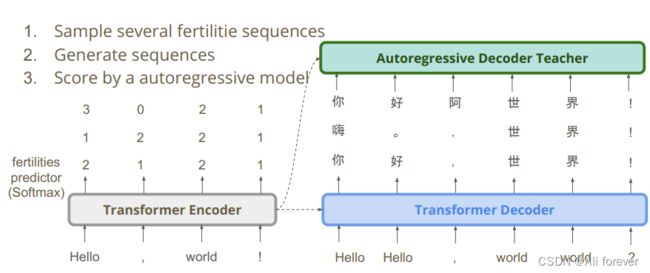
4. NPD-noisy parallel decoding
- 采样出来多个不同的fertility的序列。
- 让NAT根据上面的多个fertility序列,分别生成不同的目标语言序列;
- 让“自回归模型”来给上面的多个候选打分
4.Cross attention

Cross Attention只在Self Attention基础上做了模块输入上的改动。它通常作为decoder模块,与Self Attention作为encoder共同使用。它输入的Query来自encoder(Self Attention)的输出,而Key和Value则来自初始的input,即encoder的输入,意思是将encoder输出作为预测句子的一种表示,然后其来查询与原始输入句子中每个单词的相似性。也就是说,Cross Attention就是评估原始句子中的单词对于构建预测句子y的相关程度,相关性越高权重就越高。
Cross Attention的Query和Key也可以来自两个不同的输入,这样有利于图像-文本任务的实现。
五、Pointer Network
1.为什么要使用Pointer Network?
Seq2Seq 模型中输入到Decoder中的数量是一个固定值,这导致 Seq2Seq 不能用于一些组合优化的问题,例如凸包问题,三角剖分,旅行商问题 (TSP) 等,这是因为这些问题输出往往是输入集合的子集。
Pointer Network 可以解决输出字典大小可变的问题,Pointer Network 的输出字典大小等于 Encoder 输入序列的长度并修改了 Attention 的方法,根据 Attention 的值从 Encoder 的输入中选择一个作为 Decoder 的输出,能够充分地利用整个输入,在训练完后产生新的概率分布模型
2.如何简单实现Pointer Network
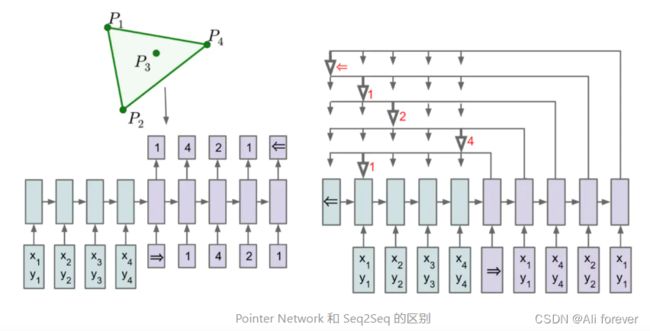
用attention机制对每一个输入元素做attention,取这个attention weight来做softmax,然后取argmax得到当前时间步的输出。因为输出每一步会对输入的所有元素去attention,这个attention vector的维度正好等于输入的个数,所以每个时间步的分类个数就等于输入元素数。
传统带有注意力机制的seq2seq模型输出的是针对输出词汇表的一个概率分布,而Pointer Networks输出的则是针对输入文本序列的概率分布。
3.pointer network与seq2sq相结合
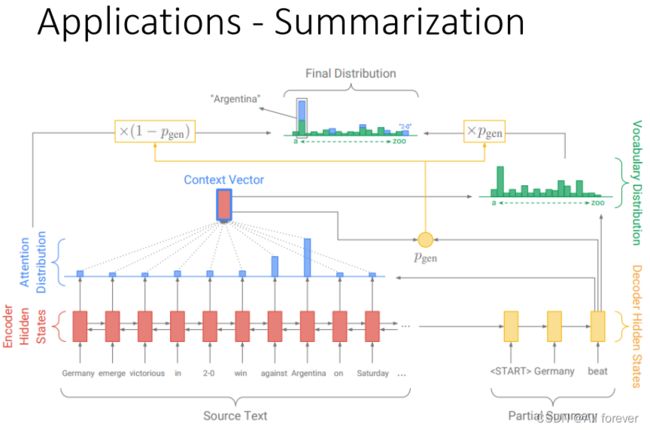
在每一次预测的时候,通过传统seq2seq模型的预测(即softmax层的结果)可以得到针对词汇表的概率分布(图7中绿色柱形图),然后通过Pointer Networks可以得到针对输入序列的概率分布(图7中蓝色柱形图),对二者做并集就可以得到结合了输入文本中词汇和预测词汇表的一个概率分布(最终结果的柱形图中的“2-0”这个词不在预测词汇表中,它来自输入文本),这样一来模型就有可能直接从输入文本中复制一些词到输出结果中。当然,直接这样操作未必会有好的结果,因此作者又加入了一个Pgen来作为软选择的概率。Pgen的作用可以这样理解:决定当前预测是直接从源文本中复制一个词过来还是从词汇表中生成一个词出来。
总结
本文介绍了Transformer的理论部分,希望大家能从中获取到想要的东西,下面附上一张思维导图帮助记忆。