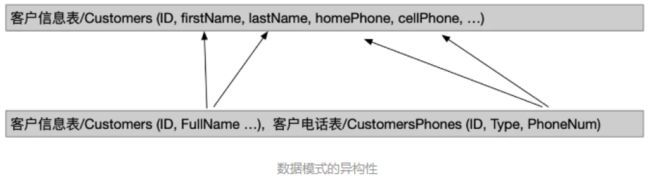
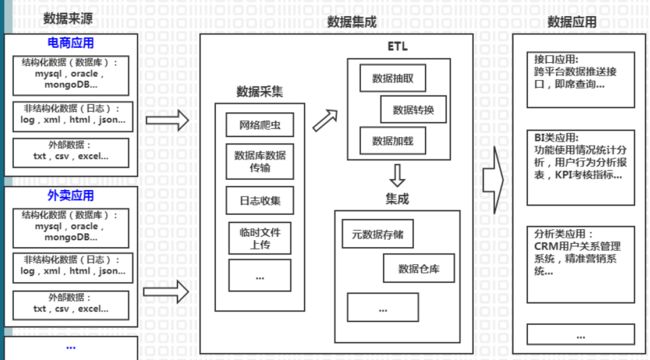
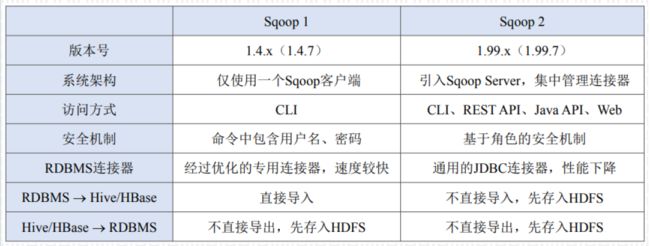
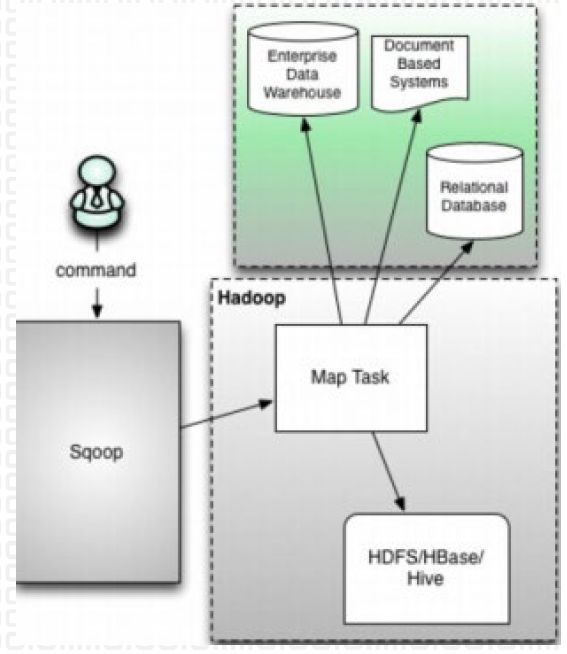
- Oracle 创建DBLink方法
夜光小兔纸
数据库Oracleoracle
一、创建新的DBLink需求说明:现有两个测试库,现想通过DBLink在测试库1连接测试库2。创建DBLink1)在测试库查看是否拥有创建DBLink的权限select*fromuser_sys_privswhereprivilegelikeupper('%DATABASELINK%');查询无结果输出,说明当前用户没有创建DBLink的权限。2)赋权当前用户创建DBLink的权限$sqlplus
- Oracle 普通用户连接hang住处理方法
夜光小兔纸
数据库Oracle运维oracle数据库运维
一、现象说明$sqlplus/assysdbaSQL*Plus:Release19.0.0.0.0-ProductiononWedDec1816:49:192024Version19.11.0.0.0Copyright(c)1982,2020,Oracle.Allrightsreserved.Connectedto:OracleDatabase19cEnterpriseEditionRelease
- 将josn字符串解析成实体
努力,别失业
C#动态解析JSONjsonmodal
dynamic_modal=Newtonsoft.Json.Linq.JToken.Parse(_json_data)asdynamic;将json字符_json_data动态解析成实体_modal,可以直接取_modal的属性字体。JsonResultResult=(JsonResult)Pay("","","","");varjsonStr=Newtonsoft.Json.JsonConver
- tensorlow中tensorboard可视化展示训练过程
张登杰踩
tensorflowtensorboardtensorflowmnist神经网络
importtensorflowastffromtensorflow.examples.tutorials.mnistimportinput_datamax_steps=1000#训练步数learning_rate=0.001#设置学习率dropout=0.9#神经元保留比例data_dir='./MNIST_data'#数据存放路径#minist数据集下载链接:https://pan.baidu
- String字符串转换为实体对象
荔枝桃子
java
将一个String字符串转换为实体对象LibraryGdsFaxingCatgDTO类publicclassLibraryGdsFaxingCatgDTO{/***层级展示*/privateStringhierarchy;/***发行分类总数据*/privateListdata;publicStringgetHierarchy(){returnhierarchy;}publicvoidsetHie
- 适配器模式详解:解决接口不兼容问题的灵活设计模式
Nita.
设计模式C#适配器模式设计模式c#
适配器模式目录1概述2主要角色3适配器模式的两种实现方式类适配器3.1.1示例3.1.2Mermaid图对象适配器3.2.1示例3.2.2MerMaid类图双向适配器模式3.3.1示例接口实现具体实现3.3.2MerMaid类图缺省适配器模式3.4.1示例3.4.2Mermaid类图4适用场景具体场景示例5适配器模式的优缺点5.1优点5.2缺点6.NET中的适配器模式案例DataAdapter:H
- 什么是报文的大端和小端,有没有什么记忆口诀?
Ly.Leo
数据结构
在计算机科学中,**大端(Big-Endian)和小端(Little-Endian)**是两种不同的字节序(即多字节数据在内存中的存储顺序)。理解这两种字节序对于网络通信、文件格式解析以及跨平台编程等非常重要。1.大端(Big-Endian)定义:高位字节(最重要的字节)存储在内存的低地址处,低位字节(最不重要的字节)存储在高地址处。示例:假设有一个32位的整数0x12345678,在大端模式下的
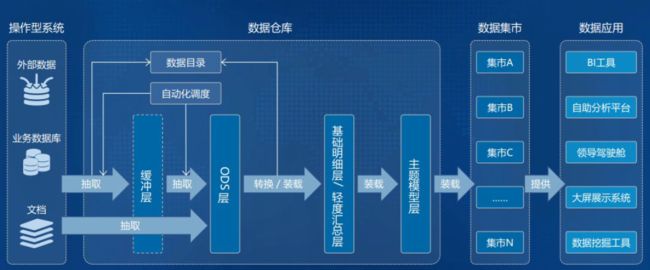
- 数据仓库基础常见面试题
兔子宇航员0301
数据开发小白成长笔记数据仓库spark大数据
1.数据仓库是什么数据仓库(DataWarehouse)是一个面向主题的、集成的、非易失的、随时间变化的数据集合,用于支持企业的管理决策。它不同于传统的操作型数据库,后者主要用于处理日常业务交易和实时查询,而数据仓库则侧重于对历史数据的整合、分析和挖掘2.数据仓库和数据库有什么区别数据来源和处理方式不同:数据库通常用于存储、管理和查询交易数据,而数据仓库则是用于处理分析性查询的数据。数据仓库通
- 不要将 Echarts 实例保存到 vue 的响应式数据上,会导致 tooltip 失效!!!
vue.jsecharts
echarts初始化echarts.init(DOMOBJ)会返回一个echarts实例对象,用一个变量接住实例对象就可以生成图表了,例如:()=>{letchartDom=document.getElementById('flg')lettimeObj=echarts.init(chartDom);timeObj.hideLoading()timeObj.setOption(dataObj);}
- sql里面的asc和desc排序原理
one996
记录程序员sql
最近遇到一个数据库的问题,sql语句是对版本进行降序排列。如下例子:用下载sql去查询,没有排序的效果。SELECT*FROMdata2WHEREpn=''ANDwsid=''ANDorder_ork=''ORDERBY'tpver'desc如下两个版本V3.7.2-R1.0Z1.3.1V3.11-R9.0Z1.4因为desc的排序方式是hashcode,按照我的理解,应该是从R开始比较,R3相等
- 技术速递|Microsoft.Extensions.VectorData 预览版简介
microsoft
作者:LuisQuintanilla-项目经理我们很高兴推出Microsoft.Extensions.VectorData.Abstractions库,该库现已提供预览版。正如Microsoft.Extensions.AI库(https://devblogs.microsoft.com/dotnet/introducing-microsoft-e...)为使用AI服务提供了一个统一层一样,此包为.
- 技术速递|Microsoft.Extensions.VectorData 预览版简介
microsoft
作者:LuisQuintanilla-项目经理我们很高兴推出Microsoft.Extensions.VectorData.Abstractions库,该库现已提供预览版。正如Microsoft.Extensions.AI库(https://devblogs.microsoft.com/dotnet/introducing-microsoft-e...)为使用AI服务提供了一个统一层一样,此包为.
- 更新 Django 3.2 解决 DEFAULT_AUTO_FIELD warnings
sunjl_a
djangoweb开发djangopythonmigration
当您在Django中定义一个没有指定主键的model时,Django将自动为您创建一个主键。主键设置为整数类型(integer)。如果要覆盖该字段类型,可以在每个模型(model)的基础上执行此操作。从Django3.2开始,您现在可以在您的设置(settings)中自定义自动创建的主键的类型。在Django3.2中开始新项目时,主键的默认类型设置为BigAutoField,这是一个64位整数(6
- Python酷库之旅-第三方库Pandas(008)
神奇夜光杯
pythonpandas人工智能开发语言excel标准库及第三方库学习和成长
目录一、用法精讲16、pandas.DataFrame.to_json函数16-1、语法16-2、参数16-3、功能16-4、返回值16-5、说明16-6、用法16-6-1、数据准备16-6-2、代码示例16-6-3、结果输出17、pandas.read_html函数17-1、语法17-2、参数17-3、功能17-4、返回值17-5、说明17-6、用法17-6-1、数据准备17-6-2、代码示例1
- vue2在线生成二维码
家里有只小肥猫
javascript前端开发语言
亲情提示:如果可以让后端生成就让后端生成实在不行再前端解决(分享方法只是为了让你快点下班不是为了让你能者多劳)创建npminstallqrcodejs2pnpminstallqrcodejs2importQRCodefrom'qrcodejs2'data:{qrcode:'',}submitCode(){if(this.$refs.qrcode){this.qrcode='';this.$refs
- hive数据类型
qzWsong
hive
数字类型TINYINT(1字节整数)SMALLINT(2字节整数)INT/INTEGER(4字节整数)BIGINT(8字节整数)FLOAT(4字节浮点数)DOUBLE(8字节双精度浮点数)示例:createtablet_test(astring,bint,cbigint,dfloat,edouble,ftinyint,gsmallint)时间类型TIMESTAMP(时间戳)(包含年月日时分秒毫秒的
- hive数据操作,导入导出
qzWsong
hive
数据导入导出将数据文件导入hive的表方式1:导入数据的一种方式:手动用hdfs命令,将文件放入表目录;方式2:在hive的交互式shell中用hive命令来导入本地数据到表目录hive>loaddatalocalinpath'/root/order.data.2'intotablet_order;方式3:用hive命令导入hdfs中的数据文件到表目录hive>loaddatainpath'/ac
- ant-design-vue, a-table, 自动生成序号列
四喜花露水
Antdvue前端linuxjavascriptanti-design-vuevue.js
通过customRender:(text,record,index)=>`${index+1}`,自动生成序号列,不用再写templatecolumns:[{title:'序号',dataIndex:'index',key:'index',width:50,fixed:'left',customRender:(text,record,index)=>`${index+1}`,//关键句},....
- element ui, el-tree, 自定义图标
四喜花露水
Vue前端javascriptelementuivue.js
template{{node.label}}datatreeData:[{id:'',label:'全部',level:'1',children:[{id:'201',label:'一级',level:'2',children:[{id:'2011',label:'二级',level:'3'},{id:'2012',label:'二级',level:'3'},{id:'2013',label:'二
- Flink之kafka消息解析器2
怎么才能努力学习啊
flinkkafka大数据
概要昨天的话题,FlinkSource消费kafka数据自定义反序列化,获取自己想要的数据和类型实现过程publicclassTestWithMetadataDeserializationSchemaimplementsKafkaRecordDeserializationSchema{第一步:自定义实现这个接口,这里的泛型一般的都是自定义类@Overridepublicvoiddeserializ
- vue 设置iframe的内部样式
撒库拉-琳琳
vue.jsjavascript前端
在没有加载完iframe时,直接使用document去获取元素是获取不到iframe内部的元素;就算加载完,也是难以获取不到内部的元素,何况还要设置样式。下面直接上代码:myselectedimport{ref}from'vue';constdata=ref('url');//iframe的srclettimer;//定时器//加载完成constiframeLoad=(event)=>{//设置定
- 【Spark】Spark Join类型及Join实现方式
DataCrafter
Spark大数据计算框架spark大数据分布式
如果觉得这篇文章对您有帮助,别忘了点赞、分享或关注哦!您的一点小小支持,不仅能帮助更多人找到有价值的内容,还能鼓励我持续分享更多精彩的技术文章。感谢您的支持,让我们一起在技术的世界中不断进步!SparkJoin类型1.InnerJoin(内连接)示例:valresult=df1.join(df2,df1("id")===df2("id"),"inner")执行逻辑:只返回那些在两个表中都有匹配的行
- Spark运行模式及Spark on Yarn两种运行模式的区别
DataCrafter
Spark大数据计算框架spark大数据
如果觉得这篇文章对您有帮助,别忘了点赞、分享或关注哦!您的一点小小支持,不仅能帮助更多人找到有价值的内容,还能鼓励我持续分享更多精彩的技术文章。感谢您的支持,让我们一起在技术的世界中不断进步!Spark运行模式1.Standalone模式描述:Standalone模式是Spark的独立集群模式,Spark自己管理资源和调度任务。适合小型集群或个人开发环境。特点:简单易用,适合开发和测试。不依赖外部
- docker-compose 部署Kong、PG、Konga
qiandeqiande
dockerkong容器
version:'2'networks:kong-net:driver:bridgeservices:kong-database:image:postgres:9.6container_name:kong-databaserestart:alwaysnetworks:-kong-netenvironment:POSTGRES_USER:kongPOSTGRES_DB:kongPOSTGRES_PA
- 【大数据入门核心技术-Hive】(十六)hive表加载csv格式数据或者json格式数据
forest_long
大数据技术入门到21天通关大数据hivehadoop开发语言后端数据仓库
一、环境准备hive安装部署参考:【大数据入门核心技术-Hive】(三)Hive3.1.2非高可用集群搭建【大数据入门核心技术-Hive】(四)Hive3.1.2高可用集群搭建二、hive加载Json格式数据1、数据准备vistu.json[{"id":111,"name":"name111"},{"id":222,"name":"name22"}]上传到hdfshadoopfs-putstu.j
- 运维之道 | Ansible 自动化项目实战 LNMP 服务安装部署
VillianTsang
Ansible
一、LNMP部署规划Mysql部署详情信息:mysql_basedir:/usr/local/mysql/源码目录mysql_datadir:/data/mysql/数据目录mysql_user:mysqlmysql用户mysql_database_user:root数据库用户mysql_passwd:'123456789'数据库密码mysql_port:3306mysql监听端口mysql_so
- 非关系型数据库NoSQL(Not Only SQL)(非关系型数据库非常灵活)
Dontla
数据库nosqlsql数据库
文章目录NoSQL的本质NoSQL的主要类型1.文档型数据库(DocumentStore)2.键值存储(Key-ValueStore)3.列式存储(ColumnStore)4.图形数据库(GraphDatabase)NoSQL的优势1.灵活的数据模型:2.高性能:3.可扩展性:适用场景使用建议1.数据一致性要求2.查询复杂度3.数据规模NoSQL的本质NoSQL是对非关系型数据库的统称。这个术语最
- 【前端知识】简单易懂的vue前端页面元素权限控制
问道飞鱼
前端开发技术vue.js前端javascript权限控制
文章目录设计思路代码实现1.**权限数据管理**2.**权限判断方法**3.**动态控制元素**4.**路由权限控制**5.**无权限页面**总结相关文献在前端实现基于Vue的权限控制,通常需要结合后端返回的用户权限数据,动态控制页面元素的显示与隐藏、按钮的可点击状态等。以下是设计思路和代码实现:设计思路权限数据管理:从后端获取用户的权限数据(如角色、权限列表等),并存储在Vuex或组件的data
- Wav文件格式
昉钰
多媒体WavAndroid
目录1、文件整体结构1.1RIFFChunk块1.2FormatChunk区块1.3DATA块1.4文件示例分析2、Android上Wav录制2.1首先初始化AudioRecord(忽略权限相关代码):2.2启动录制2.3格式转换(Wav)3、参考文章1、文件整体结构WAV文件的数据体区块一般由3个区块组成:RIFFChunk、FormatChunk和DataChunk。如上图三个不同颜色区域。1
- 为什么redis会开小差?Redis 频繁异常的深度剖析与解决方案
磐基Stack专业服务团队
redis数据库缓存
文章目录导读为什么redis会开小差?1.连接数过多2.bigkey3.慢命令操作4.内存策略不合理5.外部数据双写一致性6.保护机制未开启7.数据集中过期8.CPU饱和9.持久化阻塞10.网络问题结论导读提起分布式缓存,想必大多数同学脑海中都会浮出redis这个名字来……但是,对于它,你真的玩转了吗?为什么你的redis会慢,会卡顿,会崩溃?现在带你一探究竟。为什么redis会开小差?本文主要简
- windows下源码安装golang
616050468
golang安装golang环境windows
系统: 64位win7, 开发环境:sublime text 2, go版本: 1.4.1
1. 安装前准备(gcc, gdb, git)
golang在64位系
- redis批量删除带空格的key
bylijinnan
redis
redis批量删除的通常做法:
redis-cli keys "blacklist*" | xargs redis-cli del
上面的命令在key的前后没有空格时是可以的,但有空格就不行了:
$redis-cli keys "blacklist*"
1) "blacklist:12:
[email protected]
- oracle正则表达式的用法
0624chenhong
oracle正则表达式
方括号表达示
方括号表达式
描述
[[:alnum:]]
字母和数字混合的字符
[[:alpha:]]
字母字符
[[:cntrl:]]
控制字符
[[:digit:]]
数字字符
[[:graph:]]
图像字符
[[:lower:]]
小写字母字符
[[:print:]]
打印字符
[[:punct:]]
标点符号字符
[[:space:]]
- 2048源码(核心算法有,缺少几个anctionbar,以后补上)
不懂事的小屁孩
2048
2048游戏基本上有四部分组成,
1:主activity,包含游戏块的16个方格,上面统计分数的模块
2:底下的gridview,监听上下左右的滑动,进行事件处理,
3:每一个卡片,里面的内容很简单,只有一个text,记录显示的数字
4:Actionbar,是游戏用重新开始,设置等功能(这个在底下可以下载的代码里面还没有实现)
写代码的流程
1:设计游戏的布局,基本是两块,上面是分
- jquery内部链式调用机理
换个号韩国红果果
JavaScriptjquery
只需要在调用该对象合适(比如下列的setStyles)的方法后让该方法返回该对象(通过this 因为一旦一个函数称为一个对象方法的话那么在这个方法内部this(结合下面的setStyles)指向这个对象)
function create(type){
var element=document.createElement(type);
//this=element;
- 你订酒店时的每一次点击 背后都是NoSQL和云计算
蓝儿唯美
NoSQL
全球最大的在线旅游公司Expedia旗下的酒店预订公司,它运营着89个网站,跨越68个国家,三年前开始实验公有云,以求让客户在预订网站上查询假期酒店时得到更快的信息获取体验。
云端本身是用于驱动网站的部分小功能的,如搜索框的自动推荐功能,还能保证处理Hotels.com服务的季节性需求高峰整体储能。
Hotels.com的首席技术官Thierry Bedos上个月在伦敦参加“2015 Clou
- java笔记1
a-john
java
1,面向对象程序设计(Object-oriented Propramming,OOP):java就是一种面向对象程序设计。
2,对象:我们将问题空间中的元素及其在解空间中的表示称为“对象”。简单来说,对象是某个类型的实例。比如狗是一个类型,哈士奇可以是狗的一个实例,也就是对象。
3,面向对象程序设计方式的特性:
3.1 万物皆为对象。
- C语言 sizeof和strlen之间的那些事 C/C++软件开发求职面试题 必备考点(一)
aijuans
C/C++求职面试必备考点
找工作在即,以后决定每天至少写一个知识点,主要是记录,逼迫自己动手、总结加深印象。当然如果能有一言半语让他人收益,后学幸运之至也。如有错误,还希望大家帮忙指出来。感激不尽。
后学保证每个写出来的结果都是自己在电脑上亲自跑过的,咱人笨,以前学的也半吊子。很多时候只能靠运行出来的结果再反过来
- 程序员写代码时就不要管需求了吗?
asia007
程序员不能一味跟需求走
编程也有2年了,刚开始不懂的什么都跟需求走,需求是怎样就用代码实现就行,也不管这个需求是否合理,是否为较好的用户体验。当然刚开始编程都会这样,但是如果有了2年以上的工作经验的程序员只知道一味写代码,而不在写的过程中思考一下这个需求是否合理,那么,我想这个程序员就只能一辈写敲敲代码了。
我的技术不是很好,但是就不代
- Activity的四种启动模式
百合不是茶
android栈模式启动Activity的标准模式启动栈顶模式启动单例模式启动
android界面的操作就是很多个activity之间的切换,启动模式决定启动的activity的生命周期 ;
启动模式xml中配置
<activity android:name=".MainActivity" android:launchMode="standard&quo
- Spring中@Autowired标签与@Resource标签的区别
bijian1013
javaspring@Resource@Autowired@Qualifier
Spring不但支持自己定义的@Autowired注解,还支持由JSR-250规范定义的几个注解,如:@Resource、 @PostConstruct及@PreDestroy。
1. @Autowired @Autowired是Spring 提供的,需导入 Package:org.springframewo
- Changes Between SOAP 1.1 and SOAP 1.2
sunjing
ChangesEnableSOAP 1.1SOAP 1.2
JAX-WS
SOAP Version 1.2 Part 0: Primer (Second Edition)
SOAP Version 1.2 Part 1: Messaging Framework (Second Edition)
SOAP Version 1.2 Part 2: Adjuncts (Second Edition)
Which style of WSDL
- 【Hadoop二】Hadoop常用命令
bit1129
hadoop
以Hadoop运行Hadoop自带的wordcount为例,
hadoop脚本位于/home/hadoop/hadoop-2.5.2/bin/hadoop,需要说明的是,这些命令的使用必须在Hadoop已经运行的情况下才能执行
Hadoop HDFS相关命令
hadoop fs -ls
列出HDFS文件系统的第一级文件和第一级
- java异常处理(初级)
白糖_
javaDAOspring虚拟机Ajax
从学习到现在从事java开发一年多了,个人觉得对java只了解皮毛,很多东西都是用到再去慢慢学习,编程真的是一项艺术,要完成一段好的代码,需要懂得很多。
最近项目经理让我负责一个组件开发,框架都由自己搭建,最让我头疼的是异常处理,我看了一些网上的源码,发现他们对异常的处理不是很重视,研究了很久都没有找到很好的解决方案。后来有幸看到一个200W美元的项目部分源码,通过他们对异常处理的解决方案,我终
- 记录整理-工作问题
braveCS
工作
1)那位同学还是CSV文件默认Excel打开看不到全部结果。以为是没写进去。同学甲说文件应该不分大小。后来log一下原来是有写进去。只是Excel有行数限制。那位同学进步好快啊。
2)今天同学说写文件的时候提示jvm的内存溢出。我马上反应说那就改一下jvm的内存大小。同学说改用分批处理了。果然想问题还是有局限性。改jvm内存大小只能暂时地解决问题,以后要是写更大的文件还是得改内存。想问题要长远啊
- org.apache.tools.zip实现文件的压缩和解压,支持中文
bylijinnan
apache
刚开始用java.util.Zip,发现不支持中文(网上有修改的方法,但比较麻烦)
后改用org.apache.tools.zip
org.apache.tools.zip的使用网上有更简单的例子
下面的程序根据实际需求,实现了压缩指定目录下指定文件的方法
import java.io.BufferedReader;
import java.io.BufferedWrit
- 读书笔记-4
chengxuyuancsdn
读书笔记
1、JSTL 核心标签库标签
2、避免SQL注入
3、字符串逆转方法
4、字符串比较compareTo
5、字符串替换replace
6、分拆字符串
1、JSTL 核心标签库标签共有13个,
学习资料:http://www.cnblogs.com/lihuiyy/archive/2012/02/24/2366806.html
功能上分为4类:
(1)表达式控制标签:out
- [物理与电子]半导体教材的一个小问题
comsci
问题
各种模拟电子和数字电子教材中都有这个词汇-空穴
书中对这个词汇的解释是; 当电子脱离共价键的束缚成为自由电子之后,共价键中就留下一个空位,这个空位叫做空穴
我现在回过头翻大学时候的教材,觉得这个
- Flashback Database --闪回数据库
daizj
oracle闪回数据库
Flashback 技术是以Undo segment中的内容为基础的, 因此受限于UNDO_RETENTON参数。要使用flashback 的特性,必须启用自动撤销管理表空间。
在Oracle 10g中, Flash back家族分为以下成员: Flashback Database, Flashback Drop,Flashback Query(分Flashback Query,Flashbac
- 简单排序:插入排序
dieslrae
插入排序
public void insertSort(int[] array){
int temp;
for(int i=1;i<array.length;i++){
temp = array[i];
for(int k=i-1;k>=0;k--)
- C语言学习六指针小示例、一维数组名含义,定义一个函数输出数组的内容
dcj3sjt126com
c
# include <stdio.h>
int main(void)
{
int * p; //等价于 int *p 也等价于 int* p;
int i = 5;
char ch = 'A';
//p = 5; //error
//p = &ch; //error
//p = ch; //error
p = &i; //
- centos下php redis扩展的安装配置3种方法
dcj3sjt126com
redis
方法一
1.下载php redis扩展包 代码如下 复制代码
#wget http://redis.googlecode.com/files/redis-2.4.4.tar.gz
2 tar -zxvf 解压压缩包,cd /扩展包 (进入扩展包然后 运行phpize 一下是我环境中phpize的目录,/usr/local/php/bin/phpize (一定要
- 线程池(Executors)
shuizhaosi888
线程池
在java类库中,任务执行的主要抽象不是Thread,而是Executor,将任务的提交过程和执行过程解耦
public interface Executor {
void execute(Runnable command);
}
public class RunMain implements Executor{
@Override
pub
- openstack 快速安装笔记
haoningabc
openstack
前提是要配置好yum源
版本icehouse,操作系统redhat6.5
最简化安装,不要cinder和swift
三个节点
172 control节点keystone glance horizon
173 compute节点nova
173 network节点neutron
control
/etc/sysctl.conf
net.ipv4.ip_forward =
- 从c面向对象的实现理解c++的对象(二)
jimmee
C++面向对象虚函数
1. 类就可以看作一个struct,类的方法,可以理解为通过函数指针的方式实现的,类对象分配内存时,只分配成员变量的,函数指针并不需要分配额外的内存保存地址。
2. c++中类的构造函数,就是进行内存分配(malloc),调用构造函数
3. c++中类的析构函数,就时回收内存(free)
4. c++是基于栈和全局数据分配内存的,如果是一个方法内创建的对象,就直接在栈上分配内存了。
专门在
- 如何让那个一个div可以拖动
lingfeng520240
html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml
- 第10章 高级事件(中)
onestopweb
事件
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- 计算两个经纬度之间的距离
roadrunners
计算纬度LBS经度距离
要解决这个问题的时候,到网上查了很多方案,最后计算出来的都与百度计算出来的有出入。下面这个公式计算出来的距离和百度计算出来的距离是一致的。
/**
*
* @param longitudeA
* 经度A点
* @param latitudeA
* 纬度A点
* @param longitudeB
*
- 最具争议的10个Java话题
tomcat_oracle
java
1、Java8已经到来。什么!? Java8 支持lambda。哇哦,RIP Scala! 随着Java8 的发布,出现很多关于新发布的Java8是否有潜力干掉Scala的争论,最终的结论是远远没有那么简单。Java8可能已经在Scala的lambda的包围中突围,但Java并非是函数式编程王位的真正觊觎者。
2、Java 9 即将到来
Oracle早在8月份就发布
- zoj 3826 Hierarchical Notation(模拟)
阿尔萨斯
rar
题目链接:zoj 3826 Hierarchical Notation
题目大意:给定一些结构体,结构体有value值和key值,Q次询问,输出每个key值对应的value值。
解题思路:思路很简单,写个类词法的递归函数,每次将key值映射成一个hash值,用map映射每个key的value起始终止位置,预处理完了查询就很简单了。 这题是最后10分钟出的,因为没有考虑value为{}的情