ZeRO & DeepSpeed:可以让训练模型拥有超过1000亿个参数的优化(微软)
来源:AINLPer 微信公众号
编辑: ShuYini
校稿: ShuYini
时间: 2020-2-12
论文获取方式:
1、官网地址下载:https://arxiv.org/abs/1910.02054
2、关注 AINLPer 回复: ZeRO
引言
人工智能的最新趋势是拥有更大的自然语言模型提供更好的准确性。但是,由于成本、时间和代码集成简单(没有对代码进行专门的优化),这将导致较大的模型很难训练。微软发布了一个名为DeepSpeed的开源库,该库通过提高规模、速度、成本和可用性,极大地推进了大型模型的训练,释放了训练1000亿个参数模型的能力。DeepSpeed可与PyTorch兼容。这个库的一个部分称为ZeRO(它是一个新的并行优化器),它极大地减少了模型和数据并行所需的资源,同时极大地增加了可以训练的参数的数量。研究人员利用这些突破创造了Turing- NLG,这是已知的最大的语言模型,有170亿个参数。
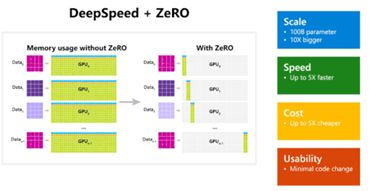
ZeRO(The Zero Redundancy Optimizer)介绍
ZeRO(The Zero Redundancy Optimizer)是一种用于大规模分布式深度学习的新型内存优化技术。ZeRO可以在当前的GPU集群上训练具有1000亿个参数的深度学习模型,其吞吐量是当前最佳系统的三到五倍。它还为训练具有数万亿个参数的模型提供了一条清晰的道路,这表明深度学习系统技术有了空前的飞跃。我们将发布ZeRO作为DeepSpeed的一部分,DeepSpeed是我们用于加速分布式深度学习培训的高性能库。
训练大型深度学习模型的挑战
大型模型可以让精度得到显著的提高,但是训练数十亿到数万亿个参数常常会遇到硬件限制。为了使这些模型适合内存,现有的解决方案需要在计算,通信和开发效率之间进行权衡:
•数据并行并不有助于减少每个设备的内存占用:一个模型有超过10亿个参数,即使在32GB内存的gpu上也会耗尽内存。
•由于细粒度的计算和昂贵的通信,模型并行性无法有效地扩展到单个节点之外。 模型并行性框架经常需要广泛的代码集成,而这些代码集成可能是特定于模型架构的。例如,NVIDIA Megatron-LM创下了83亿个参数的新模型尺寸记录。 对于适用于单个节点的多个GPU的模型,它的伸缩性很好,但是在跨节点伸缩时,其性能会降低。 例如,当在NVIDIA DGX-2节点上运行400亿个参数时,我们观察到大约五个teraflops / GPU。
克服数据并行性和模型并行性的限制
微软开发ZeRO是为了克服数据并行性和模型并行性的限制,同时实现两者的优点。ZeRO通过在数据并行进程中划分模型状态(参数,梯度和优化器状态),而不是复制它们,从而消除了数据并行进程中的内存冗余。 它在训练期间使用动态通信计划,以在分布式设备之间共享必要的状态,以保持计算粒度和数据并行性的通信量。
ZeRO驱动的数据并行性,它允许每个设备的内存使用量随数据并行性的程度线性扩展,并产生与数据并行性相似的通信量。 ZeRO支持的数据并行性可以适合任意大小的模型,只要聚合的设备内存足够大以共享模型状态即可
ZeRO的三个阶段及其优势
ZeRO具有三个主要的优化阶段(如图1所示),分别对应于优化器状态,梯度和参数的划分。 累计启用时:
1. 优化器状态分区(Pos) -减少了4倍的内存,通信容量与数据并行性相同
2. 增加梯度分区(Pos+g) - 8x内存减少,通信容量与数据并行性相同
3.增加参数分区(Pos+g+p) -内存减少与数据并行度和复杂度成线性关系。例如,跨64个gpu (Nd = 64)进行拆分将减少64倍的内存。通信容量适度增加了50%。
ZeRO消除了内存冗余,并使群集的全部聚合内存容量可用。 启用所有三个阶段后,ZeRO可以仅在1024个NVIDIA GPU上训练一个万亿参数模型。 一个具有16位精度的类似Adam之类的优化器的参数化万亿模型需要大约16 TB的内存来保存优化器的状态,梯度和参数。 16TB除以1024即为16GB,这在GPU的合理范围内。。
DeepSpeed: PyTorch兼容性和系统性能
实现了ZeRO的第一阶段(优化器状态分区(简称ZeRO-OS)),具有支持1000亿参数模型的强大能力。 该代码将与我们的培训优化库DeepSpeed一起发布。 DeepSpeed通过与PyTorch兼容的轻量级API带来了最新的培训技术,例如ZeRO,分布式培训,混合精度和检查点。 只需对PyTorch模型进行几行代码更改,就可以利用DeepSpeed解决潜在的性能挑战,并提高培训速度和规模。 DeepSpeed在四个方面表现出色(如图2所示):
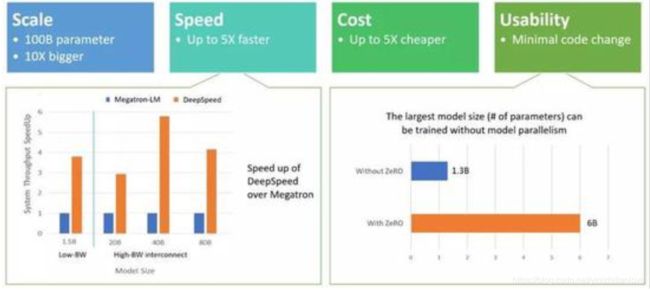
•最先进的大型模型,例如OpenAI GPT-2,NVIDIA Megatron-LM和Google T5,分别具有15亿,83亿和110亿个参数。 DeepSpeed的ZeRO第一阶段提供系统支持,以运行多达1000亿个参数的模型,该参数大10倍。 将来,我们计划增加对ZeRO第二和第三阶段的支持,从而释放将2000亿个参数训练为数万亿个参数的模型的能力。
•速度: 在各种硬件上,我们观察到的吞吐量是最新技术的五倍。 例如,为了在GPT系列工作负载上训练大型模型,DeepSpeed将基于ZeRO的数据并行性与NVIDIA Megatron-LM模型并行性相结合。 在具有低带宽互连的NVIDIA GPU群集上(没有NVIDIA NVLink或Infiniband),与仅对具有15亿参数的标准GPT-2模型使用Megatron-LM相比,我们将吞吐量提高了3.75倍。 在具有高带宽互连的NVIDIA DGX-2群集上,对于20至800亿个参数的模型,速度要快三到五倍。 这些吞吐量的提高归因于DeepSpeed更高的内存效率以及使用较低的模型并行度和较大的批处理量来适应这些模型的能力。
•成本: 吞吐量的提高可以转化为训练成本的大幅降低。 例如,要训练具有200亿个参数的模型,DeepSpeed需要的资源要少三倍。
•可用性:只需几行代码更改,PyTorch模型就可以使用DeepSpeed和ZeRO。与当前的模型并行性库相比,DeepSpeed不需要重新设计代码或重构模型。它也没有对模型尺寸(例如注意头的数量、隐藏的大小和其他)、批量大小或任何其他训练参数进行限制。对于多达60亿个参数的模型,您可以方便地使用数据并行性(由0提供支持),而不需要模型并行性,相反,对于参数超过13亿个的模型,标准的数据并行性将耗尽内存。ZeRO第二和第三阶段将进一步增加仅通过数据并行性即可训练的模型大小。 此外,DeepSpeed支持ZeRO支持的数据并行性与模型并行性的灵活组合。
Turing-NLG和DeepSpeed大型模型训练
在DeepSpeed中利用ZeRO-OS来训练一个170亿参数的Turing-NLG模型,其准确性和训练效率高于当前的最新方法。 具体可以点这里,其中显示了该模型建立的新准确性记录及其在自由格式文本生成,摘要和答案综合方面的广泛应用。
ZeRO-OS与不同类型的模型并行性是互补的、兼容的,对于不适合单个节点(约200亿个参数或更多)的大型模型,与单独使用模型并行性相比,它提供了显著的性能收益、资源节省和模型设计灵活性。
使用ZeRO-OS和NVIDIA的Megatron-LM在DeepSpeed中组合来训练Turning-NLG模型。与使用NVIDIA Megatron-LM相比,ZeRO-OS节省的内存使Turning-NLG模型的并行度降低了4倍,批处理大小增加了4倍。因此,我们实现了3倍的吞吐量增益。此外,与仅使用Megatron-LM所需的1024个GPU相比,我们仅需256个GPU即可以512个的批量训练。 最终,Megatron-LM无法运行此精确模型-不支持模型结构,因为其关注头(= 28)无法用模型并行度(= 16)整除。 DeepSpeed使模型从不可行运行变为可行而高效的训练!
GitHub项目地址:https://github.com/microsoft/DeepSpeed
往期回顾
【AAAI 2020】全部接受论文列表(一)
【AAAI 2020】全部接受论文列表(二)
【AAAI 2020】全部接受论文列表(三)
【AAAI 2020】全部接受论文列表(四)
【AAAI 2020】全部接受论文列表(五)
【AAAI 2020】全部接受论文列表(六)
重磅!「自然语言处理(NLP)」全球学术界”巨佬“信息大盘点(一)!
重磅!「自然语言处理(NLP)」全球学术界”巨佬“信息大盘点(二)!
重磅!「自然语言处理(NLP)」全球学术界”巨佬“信息大盘点(三)!