图机器学习(Graph Machine Learning)- 第三章 无监督图学习2 (Unsupervised Graph Learning)- 自编码器
第三章 无监督图学习2 - 自编码器 AutoEncoder
文章目录
- 第三章 无监督图学习2 - 自编码器 AutoEncoder
- 3.2 自编码器 AutoEncoder
-
- 3.2.1 TensorFlow和Keras——一个强大的组合
- 3.2.2 第一个自编码器
- 3.2.3 降噪自编码器 Denoising autoencoders
- 3.3 图自编码器 Graph autoencoders
- 总结
3.2 自编码器 AutoEncoder
自动编码器是一个非常强大的工具,可以有效地帮助数据科学家处理高维数据集。尽管自编码器在大约30年前首次出现,但近年来,随着基于神经网络的算法的普遍兴起,自编码器已经变得越来越普遍。除了让能进行压缩稀疏表示之外,自编码也是生成模型,如著名的生成对抗网络(generative Adversarial Network, GAN) 的的基础。而GAN用Geoffrey Hinton的话来说就是:
“The most interesting idea in the last 10 years in machine learning”
自动编码器是一种输入和输出基本相同的神经网络,但其特征是隐含层中有少量单元。 它是一个经过训练的神经网络,使用显著减少的变量数量和/或自由度来重建其输入。
由于自动编码器不需要标记的数据集,它可以被视为无监督学习和降维技术的一个例子。 然而,不同于其他技术,如主成分分析(PCA)和矩阵分解,由于神经元的非线性激活函数,自动编码器可以学习非线性变换。
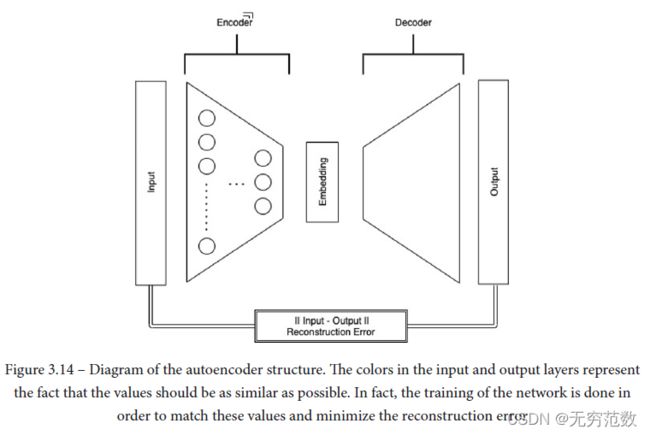
图3.14显示了一个自动编码器的简单示例。 可以看到自动编码器通常是由两部分组成的:
- 编码器网络,通过一个或多个单元处理输入,并将其映射到一个编码表示,以降低输入的维数(欠完备自动编码器)和/或约束其稀疏性(过完备正则化自动编码器)
- 解码器网络,从中间层的编码表示中重建输入信号。
然后训练编码器-解码器结构,使整个网络重构输入的能力最小化。为了完全确定一个自编码器,我们需要一个损失函数。输入和输出之间的误差可以使用不同的度量来计算,实际上,在构建自动编码器时,为重构误差选择正确的损失函数是非常关键。
测量重构误差的损失函数通常有均方误差、平均绝对误差、交叉熵和KL散度。
在下面的部分中,我们将展示如何构建一个自编码器,从一些基本概念开始,然后将这些概念应用到图结构中。但在深入讨论之前,我们觉得有必要简要介绍相关框架:TensorFlow和Keras。
3.2.1 TensorFlow和Keras——一个强大的组合
TensorFlow是谷歌在2017年以开源的形式发布的,它现在是一个标准的框架,允许符号计算和差分编程。它基本上允许你构建一个符号结构,描述如何组合输入以产生输出,定义通常称为计算图或有状态数据流图。在这个图中,节点是变量(标量、数组、张量),边表示连接单个操作的输入(边源)到输出(边目标)的操作。
在TensorFlow中,这样的图是静态的(这是与另一个非常流行的框架:torch的主要区别之一),可以通过将数据作为输入输入,清除前面提到的“dataflow”属性来执行。
通过抽象计算,TensorFlow是一个非常通用的工具,可以在多个后端上运行:由cpu、gpu驱动的机器,甚至是由特别设计的处理单元(如tpu)驱动的机器。此外,tensorflow支持的应用程序也可以部署在不同的设备上,从单个和分布式服务器到移动设备。
除了抽象计算之外,TensorFlow还允许对计算图的任何变量进行符号微分,从而产生一个新的计算图,它也可以通过微分产生高阶导数。 这种方法通常被称为符号到符号的导数,它在需要梯度估计(如梯度下降技术)来优化损失函数的情况下确实非常强大。
正如你可能知道的,许多关于参数的优化损失函数的问题是通过反向传播训练任何神经网络的核心。 这当然是TensorFlow在过去几年变得非常流行的主要原因,也是为什么它最初是由谷歌设计和生产的。
深入探究TensorFlow的用法超出了本书的范围,你可以通过专门书籍中的描述找到更多。 在下面的章节中,我们将使用它的一些主要功能,并为您提供构建神经网络的基本工具。
自从上次主要发行版2.x以来,使用TensorFlow构建模型的标准方式是使用Keras API。 Keras本来是一个与TensorFlow有关的外部项目,旨在提供一个通用的、简单的API,以便使用几种不同的编程框架(如TensorFlow、Teano和CNTK)来实现神经网络模型。 它通常抽象了计算图的底层实现,并为你提供了构建神经网络时最常用的层(尽管自定义层也很容易实现)如下:
- 卷积层
- 循环层
- 正则层
- 损失函数
Keras还发布了了与scikit-learn非常相似的API, scikit-learn是Python生态系统中最流行的机器学习库,这使得数据科学家可以非常容易地在他们的应用程序中构建、训练和集成基于神经网络的模型。
在下一节中,我们将展示如何使用Keras构建和训练一个自动编码器。我们将开始将这些技术应用于图像,以便逐步将关键概念应用于图形结构。
3.2.2 第一个自编码器
我们将以最简单的形式实现一个自编码器,即通过一个经过训练的简单前馈网络来重构其输入。我们将把这个应用到Fashion-MNIST数据集,这是一个类似于著名的MNIST数据集的数据集,MNIST数据集在黑白图像上识别手写数字。
Fashion-MNIST有10个类别,由60k + 10k(训练数据集+测试数据集)个28x28像素的灰度图像组成,代表一种服装(T-shirt, Trouser,Pullover, Dress, Coat, Sandal, Shirt, Sneaker, Bag, and Ankle boot)。与原始MNIST数据集相比,Fashion-MNIST数据集是一个更难的任务,它通常用于基准测试算法。
该数据集已经集成在Keras库中,容易使用以下代码导入:
import tensorflow as tf
from tensorflow.keras.datasets import fashion_mnist
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
实践中一个常见的做法是将输入图像的灰度级大小调整为1左右(此时激活函数是最有效的),并确保数值数据是单精度(32位)而不是双精度(64位)。这是因为训练神经网络是一个高计算量的过程,通常希望提高速度而不是精度。在某些情况下,精度甚至可以降低到半精度(16位)。我们用以下方法转换输入:
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
print (x_train.shape)
print (x_test.shape)
(60000, 28, 28)
(10000, 28, 28)
我们可以通过下面的代码从训练集中绘制一些样本来了解我们正在处理的输入类型:
from matplotlib import pyplot as plt
classes = {
0:"T-shirt/top",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle boot",
} #类名到0-9之间的映射
n = 6
plt.figure(figsize=(20, 4))
for i in range(n):
# display original
ax = plt.subplot(1, n, i + 1)
plt.imshow(x_test[i])
plt.title(classes[y_test[i]])
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
# plt.savefig("TrainingSet.png")

现在我们已经导入了输入,我们可以通过创建编码和解码来构建自编码器网络。我们将使用Keras函数API来实现这一点,它提供了更多的通用性和灵活性。我们首先定义编码网络:
from tensorflow.keras.layers import Flatten, Conv2D, Dropout, MaxPooling2D, UpSampling2D, Input
from tensorflow.keras import Model
input_img = Input(shape=(28, 28, 1))
x = Conv2D(16, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
# at this point the representation is (4, 4, 8) i.e. 128-dimensional
我们的网络一共三层,每层都是由相同的两层结构块组成:
- Conv2D,一个应用于输入的二维卷积核,有效地对应于在所有输入神经元之间共享权值。 在应用卷积核后,使用ReLU激活函数对输出进行转换。这个结构被复制到n个隐藏平面,其中n在第一个堆叠层为16,在第二个和第三个堆叠层为8。
- MaxPooling2D,它通过获取指定窗口(本例中为2x2)上的最大值来对输入进行下采样。
使用Keras API,我们还可以使用Model类来描述这些层是如何转换输入的。
Model(input_img, encoded).summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 28, 28, 1)] 0
conv2d (Conv2D) (None, 28, 28, 16) 160
max_pooling2d (MaxPooling2D (None, 14, 14, 16) 0
)
conv2d_1 (Conv2D) (None, 14, 14, 8) 1160
max_pooling2d_1 (MaxPooling (None, 7, 7, 8) 0
2D)
conv2d_2 (Conv2D) (None, 7, 7, 8) 584
max_pooling2d_2 (MaxPooling (None, 4, 4, 8) 0
2D)
=================================================================
Total params: 1,904
Trainable params: 1,904
Non-trainable params: 0
________________________________________________________________
可以看到,在编码阶段的最后,我们有一个(4,4,8)张量,它比我们最初的输入(28x28)小6倍多。我们现在可以建立解码器网络了。请注意,编码器和解码器不需要具有相同的结构和/或共享权值:
x = Conv2D(8, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(16, (3, 3), activation='relu')(x)
x = UpSampling2D((2, 2))(x)
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
在这种情况下,解码网络类似于编码结构,其中使用MaxPooling2D层实现的输入下采样被替换为UpSampling2D层,它的目的在指定的窗口上重复输入(在本例中是2x2,有效地在每个方向重复张量)。
我们现在已经用编码和解码层完全定义了网络结构。为了完全指定我们的自动编码器,我们还需要指定一个损失函数。此外,为了构建计算图,Keras还需要知道应该使用哪些算法来优化网络权值。这两种信息,loss函数和要使用的优化器,通常在编译(compiling) 模型时提供给Keras:
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
我们现在终于可以训练我们的自编码器了。Keras Model类提供了与scikit-learn类似的API,并使用合适的方法来训练神经网络。请注意,由于自编码器的性质,我们网络的输入和输出使用相同的信息:
from tensorflow.keras.callbacks import TensorBoard
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=128,
shuffle=True,
validation_data=(x_test, x_test),
callbacks=[TensorBoard(log_dir='/tmp/autoencoder')])
autoencoder.save("./data/Batch50.p")
训练完成后,我们可以通过对比输入图像和其重构结果来检验网络重构输入的能力,这可以很容易地通过Keras Model类的预测方法计算出来,如下所示:
from tensorflow.keras.models import load_model
autoencoder_first = load_model("./data/Batch50.p")
decoded_imgs = autoencoder_first.predict(x_test)
n = 6
plt.figure(figsize=(20, 7))
for i in range(1, n + 1):
# Display original
ax = plt.subplot(2, n, i)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# Display reconstruction
ax = plt.subplot(2, n, i + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()

在图中,我们展示了重建的图像。正如你所看到的,这个网络非常擅长重建看不见的图像,尤其是考虑到大规模的特征时。细节可能会在压缩过程中丢失(例如,t恤上的标志),但总体相关信息确实被我们的网络捕获了.
以下是使用学习率=0.0005时的结果:
from tensorflow.keras.optimizers import Adam
autoencoder.compile(optimizer=Adam(learning_rate=0.0005), loss='binary_crossentropy')
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=128,
shuffle=True,
validation_data=(x_test, x_test),
callbacks=[TensorBoard(log_dir='/tmp/autoencoder')])
autoencoder.save("./data/Batch100.p")
decoded_imgs = autoencoder.predict(x_test)
n = 10
plt.figure(figsize=(20, 4))
for i in range(1, n + 1):
# Display original
ax = plt.subplot(2, n, i)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# Display reconstruction
ax = plt.subplot(2, n, i + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()

我们使用经过训练的层来获得自动编码器中间层的核心表示,并使用TSNE表示它们。
(t-SNE)是一种降维技术,用于在二维或三维的低维空间中表示高维数据集,从而使其可视化。与其他降维算法(如PCA)相比,t-SNE创建了一个缩小的特征空间,相似的样本由附近的点建模,不相似的样本由高概率的远点建模。
import numpy as np
import pandas as pd
from matplotlib.cm import tab10
from sklearn.manifold import TSNE
embeddings = Model(input_img, Flatten()(encoded)).predict(x_test)
tsne = TSNE(n_components=2)
emb2d = tsne.fit_transform(embeddings)
x,y = np.squeeze(emb2d[:, 0]), np.squeeze(emb2d[:, 1])
summary = pd.DataFrame({"x": x, "y": y, "target": y_test, "size": 10})
plt.figure(figsize=(10,8))
for key, sel in summary.groupby("target"):
plt.scatter(sel["x"], sel["y"], s=10, color=tab10.colors[key], label=classes[key])
plt.legend()
plt.axis("off")

T-SNE提供的坐标如图所示,用样本所属类的颜色表示。不同服装的聚类可以清楚地看到,特别是对于一些与其他很好分开的类。
然而,自动编码器很容易过度拟合,因为它们倾向于精确地重建训练的图像,并且不能很好地泛化。在下一小节中,我们将看到如何防止过拟合,以构建更健壮、更可靠的密集表示。
3.2.3 降噪自编码器 Denoising autoencoders
除了允许我们将稀疏的表示压缩成密集的向量外,自动编码器还被广泛用于处理信号,以便过滤掉噪声,只提取相关(特征)信号。这在许多应用程序中非常有用,特别是在识别异常和离群值时。
降噪自编码器是已经实现自编码器的一个小变形。如前一节所述,使用相同的图像作为输入和输出来训练基本的自编码器。去噪自编码器使用不同强度的噪声破坏输入,同时保持相同的无噪声目标。这可以通过在输入中添加高斯噪声来实现。加入噪声的目的是为了训练更加鲁棒的自编码器。
from tensorflow.keras.layers import GaussianNoise
input_img = Input(shape=(28, 28, 1))
noisy_input = GaussianNoise(0.1)(input_img) # 通过GaussianNoise在输入图像中加入高斯噪声
x = Conv2D(16, (3, 3), activation='relu', padding='same')(noisy_input)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
# at this point the representation is (4, 4, 8) i.e. 128-dimensional
x = Conv2D(8, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(16, (3, 3), activation='relu')(x)
x = UpSampling2D((2, 2))(x)
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
noisy_autoencoder = Model(input_img, decoded)
GaussianNoise层是正则化层的一个例子,这是一个通过在网络中插入随机部分来帮助减少神经网络过拟合的层。高斯噪声层使模型更鲁棒,能够更好地泛化,避免了自动编码器学习恒等函数。
另一个正则化层的常见例子是dropout层,它有效地将一些输入设置为0(随机概率为 p 0 p_0 p0),并将其他输入缩放为 1 1 − p 0 \frac{}1{1-p_0} 11−p0,以(统计上)保持所有单位的总和不变。
Dropout对应于随机杀死层间的一些连接,以减少对特定神经元的输出依赖。正则化层只在训练时有效,而在测试时它们仅仅对应于identity层。
noisy_autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
noisy_autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=128,
shuffle=True,
validation_data=(x_test, x_test),
callbacks=[TensorBoard(log_dir='/tmp/noisy_autoencoder')])
autoencoder.save("./data/DenoisingAutoencoder.p")
#直接在静态图像中加入噪声
noise_factor = 0.1
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
如果直接在静态图像中加入噪声的话,噪声可能会在不同的迭代次数之间发生变化,网络有可能会学习噪声。
decoded_imgs = autoencoder.predict(x_test_noisy)
decoded_imgs_denoised = noisy_autoencoder.predict(x_test_noisy)
n = 6
plt.figure(figsize=(20, 10))
for i in range(1, n + 1):
# Display original
ax = plt.subplot(3, n, i)
plt.imshow(x_test_noisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
if i==0:
plt.ylabel("Original")
else:
ax.get_yaxis().set_visible(False)
# Display reconstruction
ax = plt.subplot(3, n, i + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
if i==0:
plt.ylabel("Vanilla Autoencoder")
else:
ax.get_yaxis().set_visible(False)
ax = plt.subplot(3, n, i + 2*n)
plt.imshow(decoded_imgs_denoised[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
if i==0:
plt.ylabel("Denoising Autoencoder")
else:
ax.get_yaxis().set_visible(False)
plt.show()

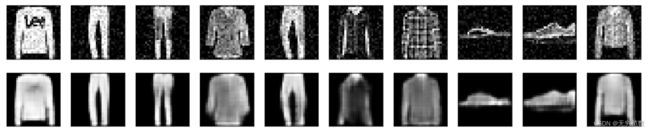
在上图中,我们比较了前一节中的非正则化网络来重构带噪输入图像,以及本节构造的带高斯噪声层的网络的重构情况。可以看出(例如比较裤子的图像),正则化模型具有更强的鲁棒性,重构出无噪声的输出:
decoded_imgs = noisy_autoencoder.predict(x_test_noisy)
n = 10
plt.figure(figsize=(20, 4))
for i in range(1, n + 1):
# Display original
ax = plt.subplot(2, n, i)
plt.imshow(x_test_noisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# Display reconstruction
ax = plt.subplot(2, n, i + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
正则化层通常用于处理倾向于过拟合的深度神经网络,并能够为自编码器学习恒等函数。通常,引入dropout或GaussianNoise层,重复由正则化和可学习层,这种模式我们通常称其为堆叠去噪层(stacked denoising layers) 。
3.3 图自编码器 Graph autoencoders
一旦理解了自编码器的基本概念,我们现在就可以把这个框架应用到图结构中。将网络结构分解成一个介于两者之间的低维表示的编码-解码结构仍然适用,那么在处理网络时,需要对需要优化的损失函数的定义多加小心。首先,我们需要将重构误差调整到一个有意义的公式,该公式可以适应图结构的特点。但是,为了做到这一点,让我们首先介绍一阶和高阶邻近性的概念。
当将自编码器应用于图结构时,网络的输入和输出应该是图的表示形式,例如邻接矩阵。重构损失可以定义为输入和输出矩阵之差的Frobenius范数。然而,当将自动编码器应用到这样的图结构和邻接矩阵时,出现了两个关键问题:
- 连接的存在表示两个顶点之间的关系或相似性,而它们的缺失通常并不表示顶点间相异。
- 邻接矩阵是非常稀疏的,因此模型自然会倾向于预测0而不是正值。
为了解决图结构的这种特性,在定义重构损失时,我们对非零元素带来的误差的惩罚要大于零元素。这可以通过以下loss函数来实现:
L 2 n d = ∑ i = 1 n ∣ ∣ ( X l ~ − X i ) ⊙ b i ∣ ∣ L_{2nd} = \sum_{i=1}^{n} ||( \tilde{X_l}-X_i) \odot b_i|| L2nd=i=1∑n∣∣(Xl~−Xi)⊙bi∣∣
其中,$ \odot$ 是元素间的Hadamard乘积,如果节点 i i i和 j j j间存在边,则 b i j = β > 1 b_{ij} = \beta >1 bij=β>1,否则 b i j = β = 0 b_{ij} = \beta =0 bij=β=0。以上损失函数保证了共享一个邻域的顶点(即它们的邻接向量是相似的)在嵌入空间中也是接近的。因此,上述公式将自然地保持重构图的二阶邻近性 。
另一方面,也可以提高重构图的一阶邻近性 ,从而使连通节点在嵌入空间中保持接近。可以使用以下损失函数来达到此条件:
L 1 s t = ∑ i , j = 1 n s i j ∣ ∣ y j − y i ∣ ∣ L_{1st} = \sum_{i,j=1}^{n} s_{ij}||y_j - y_i|| L1st=i,j=1∑nsij∣∣yj−yi∣∣
其中, y i y_i yi和 y j y_j yj是节点在嵌入空间中的表示。这个损失函数迫使相邻节点在嵌入空间中接近。如果两个节点紧紧相连, s i j s_{ij} sij就会很大。因此,他们在嵌入空间上的差 ∣ ∣ y j − y i ∣ ∣ 2 2 ||y_j - y_i||_2^2 ∣∣yj−yi∣∣22应限定(表示两个节点在嵌入空间内距离较近)以保持损失函数较小。这两个损失也可以合并成一个损失函数,其中,为了防止过拟合,可以加入一个与权重系数范数成正比的正则化损失:
L t o t = L 2 n d + α L t o t + ν L r e g = L 2 n d + α L t o t + ν ∣ ∣ W ∣ ∣ F 2 L_{tot} = L_{2nd} + \alpha L_{tot} + \nu L_{reg} = L_{2nd} + \alpha L_{tot} + \nu ||W||_F^2 Ltot=L2nd+αLtot+νLreg=L2nd+αLtot+ν∣∣W∣∣F2
在上式中, W W W表示整个网络中使用的所有权重值。以上公式由Wang等人于2016年提出,称为结构深度网络嵌入(Structural Deep Network Embedding,SDNE) 。
前面的损失函数可以直接用TensorFlow和Keras实现,可以在我们前面提到的GEM包中找到这个网络。和前面一样,提取节点嵌入可以用几行代码来完成,如下所示:
#此处代码在tf2.x不能运行, 需安装tf1.x
import tensorflow as tf
import networkx as nx
from gem.embedding.sdne import SDNE
from matplotlib import pyplot as plt
graph = nx.karate_club_graph()
m1 = SDNE(d=2, beta=5, alpha=1e-5, nu1=1e-6, nu2=1e-6, K=3,n_units=[50, 15,], rho=0.3, n_iter=10,
xeta=0.01,n_batch=50,
modelfile=['enc_model.json', 'dec_model.json'],
weightfile=['enc_weights.hdf5', 'dec_weights.hdf5'])
sdne.learn_embedding(graph)
embeddings = m1.get_embedding()
x, y = list(zip(*m1.get_embedding()))
plt.plot(x, y, 'o',linewidth=None)
总结
尽管功能非常强大,但这些图形自动编码器在处理大型图形时会遇到一些问题。此时自编码器的输入是邻接矩阵的一行,其元素与网络中的节点一样多。在大型网络中,这种规模很容易达到数百万或数千万。
在下一节中,我们将描述一种不同的网络信息编码策略,在某些情况下,这些信息可能只在局部邻域上迭代聚合嵌入,使其可扩展到大型图。