Spark系列-2、Spark快速入门
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
大数据系列文章目录
官方网址:http://spark.apache.org/、https://databricks.com/spark/about

目录
- 版本介绍
- 环境准备
- 源码编译
- Spark安装
-
- 第一步、安装Scala-2.11.12
- 第二步、修改配置名称
- 第三步、修改配置文件,$SPARK_HOME/conf/spark-env.sh,增加如下内容:
- 第四步、启动HDFS集群,从HDFS上读取数据文件
- 运行spark-shell
- 词频统计WordCount
-
- MapReduce WordCount
- Spark WordCount
- 编程实现
- 监控页面
- 运行圆周率
- 结束
版本介绍
目前Spark最新稳定版本:2.4.x系列,官方推荐使用的版本,也是目前企业中使用较多版本, 网址:https://github.com/apache/spark/releases
Spark 2.4.x依赖其他语言版本如下,其中既支持Scala 2.11,也支持Scala 2.12,推荐使用2.11。

环境准备
我使用的有3台服务器,hadoop版本为CDH-5.16.2版本,安装目录为/export/server

源码编译
Spark 软件安装包下载:http://spark.apache.org/downloads.html

默认情况下,可以下载官方提供的针对Apache不同版本的Hadoop编译的软件包,但是在实际企业项目开发中下载Spark对应版本源码,依据所使用的Hadoop版本进行编译,同时不会使用CDH 5.x提供Spark版本(其一:Spark版本太低;其二:CDH 版本Spark功能阉割,尤其在SparkSQL模块,由于SparkSQL与Cloudera公司Impala属于竞争关系),源码下载地址:https://archive.apache.org/dist/spark/spark-2.4.5/
我使用是scala版本为2.11.12
具体如何编译Spark源码,参考官方文档,注意Maven版本:
http://spark.apache.org/docs/2.4.5/building-spark.html
整个编译大概耗时1个小时左右,具体依赖网络及下载依赖包速度,如下为编译完成截图:
Spark安装
将编译完成spark安装包【spark-2.4.5-bin-cdh5.16.2-2.11.tgz】解压至【/export/server】目录:
## 解压软件包
tar -zxf /export/software/spark-2.4.5-bin-cdh5.16.2-2.11.tgz -C /export/server/
## 创建软连接,方便后期升级
ln -s /export/server/spark-2.4.5-bin-cdh5.16.2-2.11 /export/server/spark
其中各个目录含义如下:

第一步、安装Scala-2.11.12
## 解压Scala
tar -zxf /export/softwares/scala-2.11.12.tgz -C /export/server/
## 创建软连接
ln -s /export/server/scala-2.11.12 /export/server/scala
## 设置环境变量
vim /etc/profile
### 内容如下:
# SCALA_HOME
export SCALA_HOME=/export/server/scala export PATH=$PATH:$SCALA_HOME/bin
第二步、修改配置名称
## 进入配置目录
cd /export/server/spark/conf
## 修改配置文件名称
mv spark-env.sh.template spark-env.sh
第三步、修改配置文件,$SPARK_HOME/conf/spark-env.sh,增加如下内容:
## 设置JAVA和SCALA安装目录
JAVA_HOME=/export/server/jdk SCALA_HOME=/export/server/scala
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop

第四步、启动HDFS集群,从HDFS上读取数据文件
# 启动NameNode
hadoop-daemon.sh start namenode
# 启动DataNode
hadoop-daemon.sh start datanode
运行spark-shell
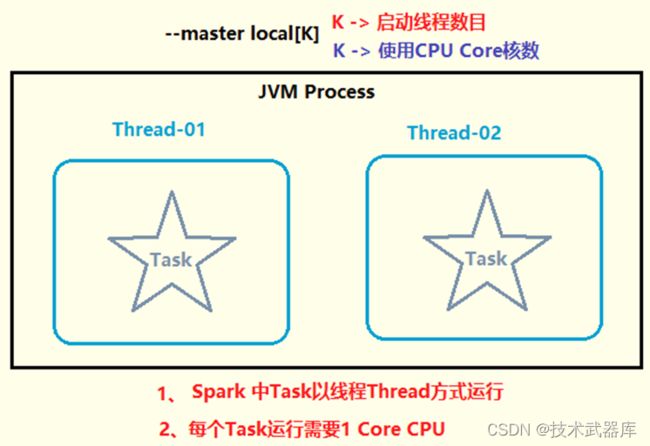
本地模式运行Spark框架提供交互式命令行:spark-shell,其中本地模式LocalMode含义为: 启动一个JVM Process进程,执行任务Task,使用方式如下:
--master local | local[*] | local[K] 建议 K >= 2 正整数
其中K表示启动线程数目(或CPU Core核数)

示意图如下:
本地模式启动spark-shell:
## 进入Spark安装目录
cd /export/server/spark
## 启动spark-shell
bin/spark-shell --master local[2]
运行成功以后,有如下提示信息:

其中创建SparkContext实例对象:sc、SparkSession实例对象:spark和启动应用监控页面端口号:4040,详细说明如下:
-
Spark context Web UI available at http://192.168.59.140:4040
表示每个Spark 应用运行时WEB UI监控页面,端口号4040 -
Spark context available as ‘sc’ (master = local[2], app id = local-1572380095682).
表示SparkContext类实例对象名称为sc
在运行spark-shell命令行的时候,创建Spark 应用程序上下文实例对象SparkContext 主要用于读取要处理的数据和调度程序执行 -
Spark session available as ‘spark’.
Spark2.x出现的,封装SparkContext类,新的Spark应用程序的入口 表示的是SparkSession实例对象,名称spark,读取数据和调度Job执行
将【$SPARK_HOME/README.md】文件上传到HDFS目录【/datas】,使用SparkContext读取文件,命令如下:
## 上传HDFS文件
hdfs dfs -mkdir -p /datas/
hdfs dfs -put /export/server/spark/README.md /datas
## 读取文件
val datasRDD = sc.textFile("/datas/README.md")
## 条目数
datasRDD.count
## 获取第一条数据
datasRDD.first
相关截图如下:

词频统计WordCount
大数据框架经典案例:词频统计WordCount,从文件读取数据,统计单词个数。

MapReduce WordCount
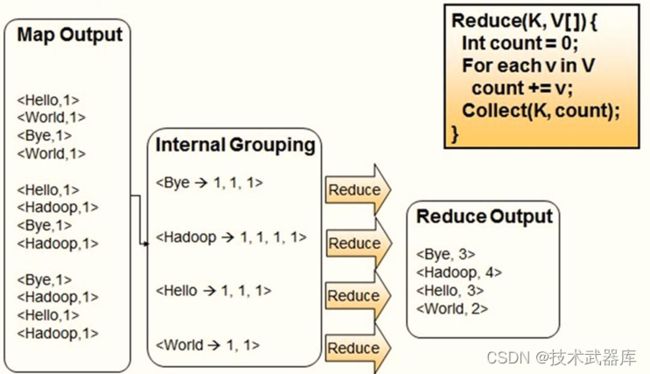
首先回顾一下MapReduce框架如何实现,流程如下图所示:

第一步、Map阶段:读取文件数据,分割为单词,出现次数为1

第二步、Reduce阶段:对map阶段输出的数据分组聚合,将相同Key的Value放在一起,聚合每个单词出现的总次数。
Spark WordCount
使用Spark编程实现,分为三个步骤:
- 第一步、从HDFS读取文件数据,sc.textFile方法,将数据封装到RDD中
- 第二步、调用RDD中高阶函数,进行处理转换处理,函数:flapMap、map和reduceByKey
- 第三步、将最终处理结果RDD保存到HDFS或打印控制台
首先回顾一下Scala集合类中高阶函数flatMap与map函数区别,map函数:会对每一条输入进行指定的func操作,然后为每一条输入返回一个对象;flatMap函数:先映射后扁平化;

Scala中reduce函数使用案例如下:

在Spark数据结构RDD中reduceByKey函数,相当于MapReduce中shuffle和reduce函数合在一起:按照Key分组,将相同Value放在迭代器中,再使用reduce函数对迭代器中数据聚合。

编程实现
准备数据文件:wordcount.data,内容如下,上传HDFS目录【/datas/】
## 创建文件
vim wordcount.data
## 内容如下
spark spark hive hive spark hive hadoop sprk spark
## 上传HDFS
hdfs dfs -put wordcount.data /datas/
编写代码进行词频统计:
## 读取HDFS文本数据,封装到RDD集合中,文本中每条数据就是集合中每条数据
val inputRDD = sc.textFile("/datas/wordcount.data")
## 将集合中每条数据按照分隔符分割,使用正则:https://www.runoob.com/regexp/regexp-syntax.html
val wordsRDD = inputRDD.flatMap(line => line.split("\\s+"))
## 转换为二元组,表示每个单词出现一次
val tuplesRDD = wordsRDD.map(word => (word, 1))
# 按照Key分组,对Value进行聚合操作, scala中二元组就是Java中Key/Value对## reduceByKey:先分组,再聚合
val wordcountsRDD = tuplesRDD.reduceByKey((tmp, item) => tmp + item)
## 查看结果
wordcountsRDD.take(5)
## 保存结果数据到HDFs中
wordcountsRDD.saveAsTextFile("/datas/spark-wc")
## 查结果数据
hdfs dfs -text /datas/spark-wc/par*

查看保存结果:

监控页面
每个Spark Application应用运行时,启动WEB UI监控页面,默认端口号为4040,使用浏览器打开页面,如下:

点击【Job 0】,进入到此Job调度界面,通过DAG图展示,具体含义后续再讲。

大多数现有的集群计算系统都是基于非循环的数据流模型。即从稳定的物理存储(如分布式文件系统)中加载记录,记录被传入由一组确定性操作构成的 DAG(Directed AcyclicGraph,有向无环图),然后写回稳定存储。 DAG 数据流图能够在运行时自动实现任务调度和故障恢复。
运行圆周率
Spark框架自带的案例Example中涵盖圆周率PI计算程序,可以使用
【$SPARK_HOME/bin/spark-submit】提交应用执行,运行在本地模式
自带案例jar包:【/export/server/spark/examples/jars/spark-examples_2.11-2.4.5.jar】

提交运行PI程序
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master local[2] \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar \ 10
运行结果截图如下:

结束
Spark快速入门介绍就这么多,下篇文章开始介绍Spark的部署方式有那些。