深度学习课后week2 编程(识别猫)
参考:https://blog.csdn.net/u013733326/article/details/79639509
1.编程要求
具有神经网络思维的Logistic回归,搭建一个能够 识别猫 的简单的神经网络
2.所用到的库
| 库 | 说明 |
|---|---|
| h5py | 读写超大数据,使用HDF5模块,是存放两类对象的容器:数据集(dataset)、组(group) |
| matplotlib.pyplot | pyplot是matplotlib子库,用于绘制2D图表 |
| numpy | 进行矩阵计算 |
3. 具体步骤
- 导入库
- 导入数据(训练集和测试集)
- 整合数据,取出训练、测试数据集
- 数据维度处理及数据标准化
- 初始化参数
- 定义函数(sigmoid函数、代价函数、前向传播函数、梯度下降)
- 优化
- 预测
- 模型整合
- 测试
- 绘制图
- 单个图片查看
- 比较不同学习速率的准确性
4.实现
1.导入库
2.导入数据
#导入库
import numpy as np
import matplotlib.pyplot as plt
import h5py
#导入数据
test_data = h5py.File('E:/深度学习课后作业/week2/datasets/test_catvnoncat.h5','r') #测试集
train_data = h5py.File('E:/深度学习课后作业/week2/datasets/train_catvnoncat.h5','r')#训练集
#查看含有映射训练集中所有键的集合的视图
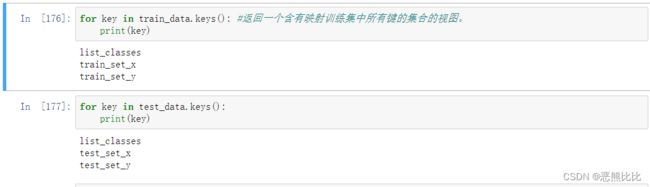
说明:
- train_set_x :保存的是训练集里面的图像数据(本训练集有209张64x64的图像)。
- train_set_y:保存的是训练集的图像对应的分类值(【0 | 1】,0表示不是猫,1表示是猫)。
- classes : 保存的是以bytes类型保存的两个字符串数据,数据为:[b’non-cat’ b’cat’]

3.整合数据,取出训练、测试数据集
#整合数据,取出训练、测试数据集
train_data_org = train_data['train_set_x'][:] #冒号表示取出全部
train_labels_org = train_data['train_set_y'][:]
test_data_org = test_data['test_set_x'][:]
test_labels_org = test_data['test_set_y'][:]
4.维度处理和数据标准化
#维度处理和数据标准化
#为了方便计算将(209,64,64,3)数组构造成(64*64*3,209)的数组
m_train = train_data_org.shape[0] #取样本,训练集图片数量
m_test = test_data_org.shape[0]
train_data_tran = train_data_org.reshape(m_train,-1).T #取209样本不变,将训练集的维度降低并转置 (209,64,64,3)-> (12288, 209)
test_data_tran = test_data_org.reshape(m_test,-1).T
train_labels_tran = train_labels_org[np.newaxis,:] #转格式 (209,)-->(1, 209)
test_labels_tran = test_labels_org[np.newaxis,:]
#标准化
#目的是为了使数据之间的差别变小
train_data_sta = train_data_tran / 255
test_data_sta = test_data_tran / 255
5.初始化参数
#初始化参数
n_dim = train_data_sta.shape[0] #维度 12288
def initialize(dim):
w = np.zeros((n_dim,1)) #权重(12288, 1)
b = 0 #偏差
return w,b
6.定义函数
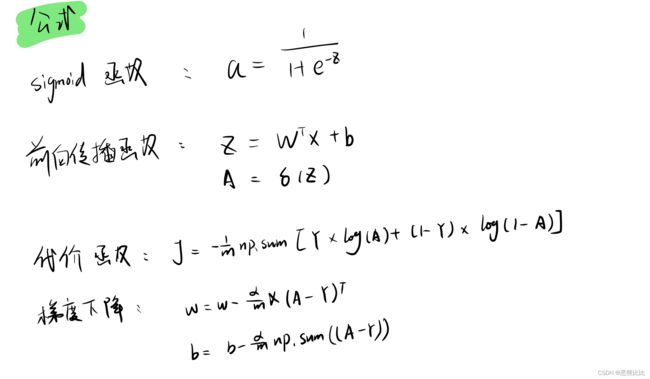
#定义函数
#sigmod()函数
def sigmoid(z):
a = 1/(1+np.exp(-z))
return a
#成本函数 propagate()
def propagate(w,b,X,Y):
m = X.shape[1]
#正向传播
z = np.dot(w.T,X)+b
A = sigmoid(z)
J = -(1/m)*np.sum(Y*np.log(A)+(1-Y)*np.log(1-A)) #代价函数:计算成本
#反向传播(梯度下降)
dw = (1/m)* np.dot(X,(A-Y).T)
db = (1/m) * np.sum(A-Y)
#保存结果
grads = {'dw':dw,'db':db}
return grads,J
7.优化
#优化 使用渐变下降更新参数
#目的是为了最小化成本函数J来学习w,b
#iter :迭代次数,学习效率,没一百步打印一次结果
def optimize(w,b,X,Y,iters,learning_rate,print_cost=False):
costs = [] #保存结果
for i in range(iters):
grads,J = propagate(w,b,X,Y)
dw = grads['dw']
db = grads['db']
w = w - learning_rate*dw
b = b - learning_rate*db
if i%100 == 0:
costs.append(J)
if (i%100==0) and (print_cost):
print("迭代次数:%d,误差值%f"%(i,J))
params = {'w':w,'b':b}
grads = {'dw':dw,'db':db}
return params,grads,costs
8.预测
#预测部分
#优化部分输出已学习过的w和b的值,我们可以使用w和b来预测x的标签
def predict(w,b,X):
m = X.shape[1] #图片的数量
y_pred = np.zeros((1,m))
z = np.dot(w.T,X)+b #预测猫在图片中出现的概率
A = sigmoid(z)
for i in range(A.shape[1]):
if A[:,i]>0.5:
y_pred[:,i] = 1
else:
y_pred[:,i] = 0
return y_pred
9.模型整合
#模型整合
def model(X_train,Y_train,X_test,Y_test,iters=2000,learning_rate=0.5,print_cost=False):
n_dim = train_data_sta.shape[0] #维度 12288
w,b = initialize(n_dim)
params,grads,costs = optimize(w,b,X_train,Y_train,iters,learning_rate,print_cost)
w,b = params['w'],params['b']
Y_pred_train = predict(w,b,X_train)
Y_pred_test = predict(w,b,X_test)
print("训练集的准确性:"+format(100-np.mean(np.abs(Y_pred_train-Y_train))*100),"%")
print("测试集的准确性:"+format(100-np.mean(np.abs(Y_pred_test-Y_test))*100),"%")
d = {'costs':costs,'Y_pred_train':Y_pred_train,'Y_pred_test':Y_pred_test,'w':w,'b':b,'iters':iters,'learning_rate':learning_rate}
return d
10.测试
#测试
d = model(train_data_sta,train_labels_tran,test_data_sta,test_labels_tran,iters=2000,learning_rate=0.005,print_cost=True)

11.绘制图
#绘制图
costs = np.squeeze(d['costs'])
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds) ')
plt.title("learning rate = "+str(d['learning_rate']))
plt.show()

12.查看图片(单个图片预测和真是对比)
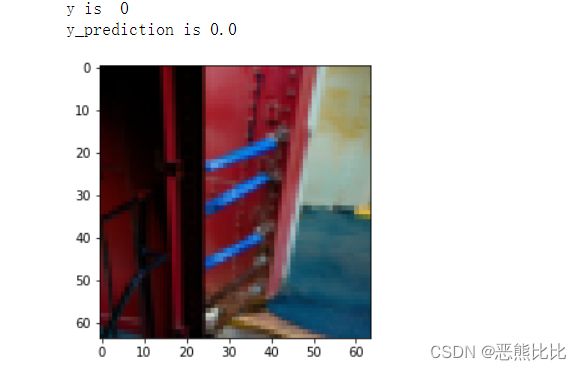
#查看图片
index = 45
plt.imshow(train_data_org[index]) #第index张图片
print('y is ',test_labels_tran[0,index]) #真实值
print('y_prediction is',d['Y_pred_train'][0,index]) #预测值
13.比较不同学习速率的准确性
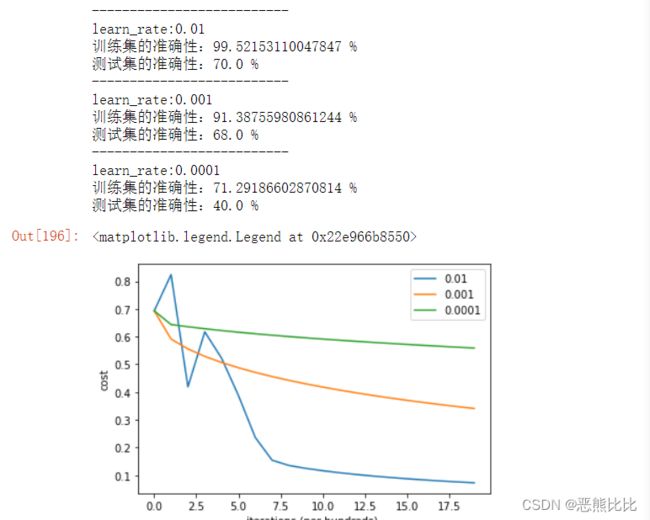
#比较不同学习速率的准确性
learn_rates = [0.01,0.001,0.0001]
for i in learn_rates:
print("--------------------------")
print("learn_rate:"+str(i))
d = model(train_data_sta,train_labels_tran,test_data_sta,test_labels_tran,iters=2000,learning_rate=i,print_cost=False)
costs = np.squeeze(d['costs'])
plt.plot(costs,label = str(i))
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds) ')
#plt.title("learning rate = "+str(d['learning_rate']))
plt.legend()
5.关于Jupyter的快捷使用
-
运行单元格(Cell):Shift+Enter
-
删除单元格:先按ESC,让单元格脱离输入状态,连续按两个D(即D+D),此处类似Vim的删除命令。此处D表示『Delete』
-
向上添加一个新的单元格:先按ESC,再按A
-
向下添加一个新的单元格:先按ESC,再按B
-
合并单元格:按住Shift,用鼠标选中相邻的单元格,再按M(即Shift +M),这里的M表示『Merge(融合)』之意
-
拆分单元格:光标移动到拆分的行,然后按Ctrl+Shift±。这里的『-』就好像一条分割线一样,将单元格一分为二。