概率论知识点总结(下)
参考资料
- 最大似然估计例题
- 何书元《概率论与数理统计》
6. 描述性统计
统计学的做法分为两种:
- 描述性统计:
从数据样本中计算一些平均值、标准差、最小值、最大值等概括 统计量, 画直方图、散点图等描述图形。 - 推断性统计:
假定要研究的对象服从某种概率模型, 收集数据后把数据用模型 解释, 并做出有概率意义的结论。
6.1 总体与样本
总体
- 总体参数是描述总体特性的指标, 简称参数。
- 如果总体中的个体是有限个, 称个体总数 N N N 为总体容量。
- 总体平均或总体均值是参数。常用 μ \mu μ 表示。如果知道总体的全部个体 (比如, 某小学所有一年级新生的身高) y 1 , y 2 , … , y N y_{1}, y_{2}, \ldots, y_{N} y1,y2,…,yN 则
μ = 1 N ∑ i = 1 N y i \mu=\frac{1}{N} \sum_{i=1}^{N} y_{i} μ=N1i=1∑Nyi - 总体方差是参数。常记为 σ 2 \sigma^{2} σ2 。如果知道总体的全部个体 y 1 , y 2 , … , y N y_{1}, y_{2}, \ldots, y_{N} y1,y2,…,yN 则
σ 2 = 1 N ∑ i = 1 N ( y i − μ ) 2 \sigma^{2}=\frac{1}{N} \sum_{i=1}^{N}\left(y_{i}-\mu\right)^{2} σ2=N1i=1∑N(yi−μ)2
σ \sigma σ 称为总体标准差。
样本
- 如果总体只有有限个样本虽然可以测量所有样本计算总体参数, 但可 能会消耗过大。
- 有些总体有无限个个体, 比如, 对某放射性物质测量固定长度时间内 放射出的粒子数, 每试验一次就有一个不同结果。
- 为了得到总体的信息, 可以从总体中抽取一个有代表性的个体的集合, 称为总体的一个样本。也叫观测数据。样本中个体的个数叫做样本量 (sample size)。
- 试图用样本的情况去判断总体的情况。注意, “有代表性” 是一个不容 忽视的要求。
- 从总体中抽取样本的工作叫做抽样 (sampling)。
- 设一个样本为 x 1 , x 2 , … , x n x_{1}, x_{2}, \ldots, x_{n} x1,x2,…,xn, 可计算
- 样本均值
x ˉ = 1 n ∑ i = 1 n x i \bar{x}=\frac{1}{n} \sum_{i=1}^{n} x_{i} xˉ=n1i=1∑nxi - 样本方差
s 2 = 1 n − 1 ∑ i = 1 n ( x i − x ˉ ) 2 . s^{2}=\frac{1}{n-1} \sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)^{2} . s2=n−11i=1∑n(xi−xˉ)2.
s = s 2 s=\sqrt{s^{2}} s=s2 称为样本标准差。
6.2 抽样调查方法
随机抽样
- 如果总体中的每个个体都有相同的机会被抽中, 就称这样的抽样方法 为随机抽样方法。
- 简单地分, 抽样分为有放回抽取和无放回抽取。
- 无放回随机抽样指在总体中随机抽出一个个体后, 下次在余下的个体 中再进行随机抽样.
- 有放回随机抽样指抽出一个个体, 记录下抽到的结果后放回, 摇匀后再 进行下一次随机抽样.
- 无放回抽取从实现上和从精度上更好, 总体容量 N N N 很大时两者差异 很小。
- 提高样本量可以提高估计精度, 但不是总体越大, 考虑的特征越多, 样 本量也需要随之增大。
- 不论是有放回还是无放回,随机抽样是无偏的
分层抽样方法
- 把总体 A A A 分成 L L L 个互不相交子总体:
A = A 1 + A 2 + ⋯ + A L . A=A_{1}+A_{2}+\cdots+A_{L} . A=A1+A2+⋯+AL.
称这些子总体为层 (strata), 称 A i A_{i} Ai 为第 i i i 层. 然后在每层中独立地进行随机抽样. - 用 N N N 表示总体 A A A 的个体总数, 用 N i N_{i} Ni 表示第 i i i 层的个体总数时, 有
N = N 1 + N 2 + ⋯ + N L . N=N_{1}+N_{2}+\cdots+N_{L} . N=N1+N2+⋯+NL. - 我们称
w i = N i N , ( i = 1 , 2 , ⋯ , L ) w_{i}=\frac{N_{i}}{N},(i=1,2, \cdots, L) wi=NNi,(i=1,2,⋯,L)
为第 i i i 层的层权 (weight). - 用 μ \mu μ 表示 A A A 的总体均值.
- 对 i = 1 , 2 , ⋯ , L i=1,2, \cdots, L i=1,2,⋯,L, 用 n i n_{i} ni 表示从第 i i i 层抽出样本的个数, x ˉ i \bar{x}_{i} xˉi 表示从第 i i i 层抽出样本的样本均值. 称
x ˉ s t = w 1 x ˉ 1 + w 2 x ˉ 2 + ⋯ + w L x ˉ L \bar{x}_{s t}=w_{1} \bar{x}_{1}+w_{2} \bar{x}_{2}+\cdots+w_{L} \bar{x}_{L} xˉst=w1xˉ1+w2xˉ2+⋯+wLxˉL
是总体均值 μ \mu μ 的简单估计. - 称
V ( x ˉ s t ) ≡ w 1 2 Var ( x ˉ 1 ) + w 2 2 Var ( x ˉ 2 ) + ⋯ + w L 2 Var ( x ˉ L ) V\left(\bar{x}_{s t}\right) \equiv w_{1}^{2} \operatorname{Var}\left(\bar{x}_{1}\right)+w_{2}^{2} \operatorname{Var}\left(\bar{x}_{2}\right)+\cdots+w_{L}^{2} \operatorname{Var}\left(\bar{x}_{L}\right) V(xˉst)≡w12Var(xˉ1)+w22Var(xˉ2)+⋯+wL2Var(xˉL)
是简单估计 x ˉ s t \bar{x}_{s t} xˉst 的抽样方差. - 抽样方差 V ( x ˉ s t ) V\left(\bar{x}_{s t}\right) V(xˉst) 是评价简单估计 x ˉ s t \bar{x}_{s t} xˉst 的估计精度的指标. V ( x ˉ s t ) V\left(\bar{x}_{s t}\right) V(xˉst) 越 小, 说明 x ˉ s t \bar{x}_{s t} xˉst 越好.
- 当各层内总体方差相近时, 各层样本量 n i n_{i} ni 应该正比于各层总体容量 N i N_{i} Ni
7. 参数估计
如果 X 1 , X 2 , ⋯ , X n X_{1}, X_{2}, \cdots, X_{n} X1,X2,⋯,Xn 独立同分布, 和 X X X 同分布, 就称 X X X 是 总体, 称 X 1 , X 2 , ⋯ , X n X_{1}, X_{2}, \cdots, X_{n} X1,X2,⋯,Xn 是总体 X X X 的简单随机样本, 称观测数据的个 数 n n n 为样本量.
7.1 点估计和矩估计
估计量 (统计量)
- 设 X 1 , X 2 , ⋯ , X n X_{1}, X_{2}, \cdots, X_{n} X1,X2,⋯,Xn 是总体 X X X 的简单随机样本, θ \theta θ 是总体 X X X 的末知参 数. 如果 g ( x 1 , x 2 , ⋯ , x n ) g\left(x_{1}, x_{2}, \cdots, x_{n}\right) g(x1,x2,⋯,xn) 是已知函数, 就称
θ ^ = g ( X 1 , X 2 , ⋯ , X n ) \hat{\theta}=g\left(X_{1}, X_{2}, \cdots, X_{n}\right) θ^=g(X1,X2,⋯,Xn)
是 θ \theta θ 的估计量, 简称为估计 (estimator). 换句话说, 估计或估计量是从 观测数据 X 1 , X 2 , ⋯ , X n X_{1}, X_{2}, \cdots, X_{n} X1,X2,⋯,Xn 能够直接计算的量. 计算后得到的值称为估 计值. 估计量也称为统计量 (statistic). - 设 θ ^ \hat{\theta} θ^ 是总体参数 θ \theta θ 的估计, 作为随机变量 X 1 , X 2 , ⋯ , X n X_{1}, X_{2}, \cdots, X_{n} X1,X2,⋯,Xn 的函数, 估 计量 θ ^ \hat{\theta} θ^ 也是随机变量. 估计量是样本的函数.
无偏估计,相合估计
- 设 θ ^ \hat{\theta} θ^ 是 θ \theta θ 的估计.
- 如果 E θ ^ = θ \mathrm{E} \hat{\theta}=\theta Eθ^=θ, 称 θ ^ \hat{\theta} θ^ 是 θ \theta θ 的无偏估计;
- 如果当样本量 n → ∞ , θ ^ n \rightarrow \infty, \hat{\theta} n→∞,θ^ 依概率收敛到 θ \theta θ, 就称 θ ^ \hat{\theta} θ^ 是 θ \theta θ 的相合估 计 (consistent estimator);
- 如果当样本量 n → ∞ , θ ^ n \rightarrow \infty, \hat{\theta} n→∞,θ^ 以概率 1 收敛到 θ \theta θ, 就称 θ ^ \hat{\theta} θ^ 是 θ \theta θ 的强相合估计 (strongly consistent estimator).
- 由于以概率 1 收玫可以推出依概率收玫, 所以强相合估计一定是相合 估计.
均值的估计
- 设总体均值 μ = E X \mu=\mathrm{E} X μ=EX 存在, X 1 , X 2 , ⋯ , X n X_{1}, X_{2}, \cdots, X_{n} X1,X2,⋯,Xn 是总体 X X X 的简单随机样 本.
- 均值 μ \mu μ 的估计定义为
X ˉ n = 1 n ∑ i = 1 n X i \bar{X}_{n}=\frac{1}{n} \sum_{i=1}^{n} X_{i} Xˉn=n1i=1∑nXi - 由于 X ˉ n \bar{X}_{n} Xˉn 是从样本计算出来的, 所以是样本均值.
- 样本均值 X ˉ n \bar{X}_{n} Xˉn 有如下的性质.
(1) X ˉ n \bar{X}_{n} Xˉn 是 μ \mu μ 的无偏估计. 这是因为 E X ˉ n = μ \mathrm{E} \bar{X}_{n}=\mu EXˉn=μ.
(2) X ˉ n \bar{X}_{n} Xˉn 是 μ \mu μ 的强相合估计, 从而是相合估计. 这是因为从强大数律得 到
lim n → ∞ X ˉ n = μ , w p 1. \lim _{n \rightarrow \infty} \bar{X}_{n}=\mu, \mathrm{wp} 1 . n→∞limXˉn=μ,wp1.
方差的估计
-
总体方差 σ 2 = Var ( X ) \sigma^{2}=\operatorname{Var}(X) σ2=Var(X) 的点估计由
S 2 = 1 n − 1 ∑ j = 1 n ( X j − μ ^ ) 2 S^{2}=\frac{1}{n-1} \sum_{j=1}^{n}\left(X_{j}-\hat{\mu}\right)^{2} S2=n−11j=1∑n(Xj−μ^)2
定义. 由于 S 2 S^{2} S2 是从样本计算出来的, 所以是样本方差. -
定义 Y j = X j − μ Y_{j}=X_{j}-\mu Yj=Xj−μ, 有
Y ˉ n = 1 n ∑ j = 1 n Y j = μ ^ − μ , Y j − Y ˉ n = X j − μ ^ , E Y ˉ n 2 = σ 2 n . \begin{aligned} &\bar{Y}_{n}=\frac{1}{n} \sum_{j=1}^{n} Y_{j}=\hat{\mu}-\mu, \\ &Y_{j}-\bar{Y}_{n}=X_{j}-\hat{\mu}, \\ &\mathrm{E} \bar{Y}_{n}^{2}=\frac{\sigma^{2}}{n} . \end{aligned} Yˉn=n1j=1∑nYj=μ^−μ,Yj−Yˉn=Xj−μ^,EYˉn2=nσ2. -
于是得到
S 2 = 1 n − 1 ∑ j = 1 n ( X j − X ˉ n ) 2 = 1 n − 1 ∑ j = 1 n ( Y j − Y ˉ n ) 2 = 1 n − 1 ∑ j = 1 n ( Y j 2 − 2 Y j Y ˉ n + Y ˉ n 2 ) = 1 n − 1 [ ∑ j = 1 n Y j 2 − 2 n Y ˉ n Y ˉ n + n Y ˉ n 2 ] = 1 n − 1 [ ∑ j = 1 n Y j 2 − n Y ˉ n 2 ] \begin{aligned} S^{2} &=\frac{1}{n-1} \sum_{j=1}^{n}\left(X_{j}-\bar{X}_{n}\right)^{2}=\frac{1}{n-1} \sum_{j=1}^{n}\left(Y_{j}-\bar{Y}_{n}\right)^{2} \\ &=\frac{1}{n-1} \sum_{j=1}^{n}\left(Y_{j}^{2}-2 Y_{j} \bar{Y}_{n}+\bar{Y}_{n}^{2}\right) \\ &=\frac{1}{n-1}\left[\sum_{j=1}^{n} Y_{j}^{2}-2 n \bar{Y}_{n} \bar{Y}_{n}+n \bar{Y}_{n}^{2}\right] \\ &=\frac{1}{n-1}\left[\sum_{j=1}^{n} Y_{j}^{2}-n \bar{Y}_{n}^{2}\right] \end{aligned} S2=n−11j=1∑n(Xj−Xˉn)2=n−11j=1∑n(Yj−Yˉn)2=n−11j=1∑n(Yj2−2YjYˉn+Yˉn2)=n−11[j=1∑nYj2−2nYˉnYˉn+nYˉn2]=n−11[j=1∑nYj2−nYˉn2] -
从而有
E S 2 = 1 n − 1 [ ∑ j = 1 n E Y j 2 − n E Y ˉ n 2 ] = 1 n − 1 ( n σ 2 − σ 2 ) = σ 2 . \mathrm{E} S^{2}=\frac{1}{n-1}\left[\sum_{j=1}^{n} \mathrm{E} Y_{j}^{2}-n \mathrm{E} \bar{Y}_{n}^{2}\right]=\frac{1}{n-1}\left(n \sigma^{2}-\sigma^{2}\right)=\sigma^{2} . ES2=n−11[j=1∑nEYj2−nEYˉn2]=n−11(nσ2−σ2)=σ2.
说明 S 2 S^{2} S2 是 σ 2 \sigma^{2} σ2 的无偏估计.
样本均值、方差、标准差的理论结果
- 设 X 1 , X 2 , ⋯ , X n X_{1}, X_{2}, \cdots, X_{n} X1,X2,⋯,Xn 是总体 X X X 的简单随机样本, μ = E X \mu=\mathrm{E} X μ=EX, σ 2 = Var ( X ) \sigma^{2}=\operatorname{Var}(X) σ2=Var(X)
- 样本均值 X ˉ n \bar{X}_{n} Xˉn 是总体均值 μ \mu μ 的强相合无偏估计,
- 样本方差 S 2 S^{2} S2 是总体方差 σ 2 \sigma^{2} σ2 的强相合无偏估计,
- 样本标准差 S S S 是总体标准差 σ \sigma σ 的强相合估计.
点估计
- 设 X 1 , X 2 , ⋯ , X n X_{1}, X_{2}, \cdots, X_{n} X1,X2,⋯,Xn 是总体 X X X 的简单随机样本, 则 X 1 j , X 2 j , ⋯ , X n j X_{1}^{j}, X_{2}^{j}, \cdots, X_{n}^{j} X1j,X2j,⋯,Xnj 是 总体 X j X^{j} Xj 的简单随机样本, 所以当原点矩 ν j = E X j \nu_{j}=\mathrm{E} X^{j} νj=EXj 存在时,
ν ^ j = 1 n ∑ i = 1 n X i j (1.7) \tag{1.7} \hat{\nu}_{j}=\frac{1}{n} \sum_{i=1}^{n} X_{i}^{j} ν^j=n1i=1∑nXij(1.7)
是 ν j \nu_{j} νj 的点估计. - ν ^ j \hat{\nu}_{j} ν^j 具有无偏性和强相合性.
- 最后指出, 在实际数据的计算中, 也常用 x ˉ n , s 2 \bar{x}_{n}, s^{2} xˉn,s2 和 s s s 分别表示样本均 值, 样本方差和样本标准差:
x ˉ n = 1 n ∑ j = 1 n x j , s 2 = 1 n − 1 ∑ j = 1 n ( x j − x ˉ n ) 2 , s = s 2 . (1.8) \tag{1.8} \bar{x}_{n}=\frac{1}{n} \sum_{j=1}^{n} x_{j}, s^{2}=\frac{1}{n-1} \sum_{j=1}^{n}\left(x_{j}-\bar{x}_{n}\right)^{2}, s=\sqrt{s^{2}} . xˉn=n1j=1∑nxj,s2=n−11j=1∑n(xj−xˉn)2,s=s2.(1.8)
矩估计
- 设 X 1 , X 2 , ⋯ , X n X_{1}, X_{2}, \cdots, X_{n} X1,X2,⋯,Xn 是总体 X X X 的简单随机样本, 已知 X X X 有分布函数
F ( x ; θ 1 , θ 2 , ⋯ , θ m ) . (1.9) \tag{1.9} F\left(x ; \theta_{1}, \theta_{2}, \cdots, \theta_{m}\right) . F(x;θ1,θ2,⋯,θm).(1.9)
其中的 θ 1 , θ 2 , ⋯ , θ m \theta_{1}, \theta_{2}, \cdots, \theta_{m} θ1,θ2,⋯,θm 是末知参数. - 如果能得到表达式
{ θ 1 = g 1 ( ν 1 , ν 2 , ⋯ , ν m ) θ 2 = g 2 ( ν 1 , ν 2 , ⋯ , ν m ) ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ , θ m = g m ( ν 1 , ν 2 , ⋯ , ν m ) (1.10) \tag{1.10} \left\{\begin{array}{l} \theta_{1}=g_{1}\left(\nu_{1}, \nu_{2}, \cdots, \nu_{m}\right) \\ \theta_{2}=g_{2}\left(\nu_{1}, \nu_{2}, \cdots, \nu_{m}\right) \\ \cdots \cdots \cdots \cdots \cdots \cdots, \\ \theta_{m}=g_{m}\left(\nu_{1}, \nu_{2}, \cdots, \nu_{m}\right) \end{array}\right. ⎩ ⎨ ⎧θ1=g1(ν1,ν2,⋯,νm)θ2=g2(ν1,ν2,⋯,νm)⋯⋯⋯⋯⋯⋯,θm=gm(ν1,ν2,⋯,νm)(1.10)
其中
ν j = E X j , j = 1 , 2 , ⋯ , m , \nu_{j}=\mathrm{E} X^{j}, j=1,2, \cdots, m, νj=EXj,j=1,2,⋯,m, - 就称由
{ θ ^ 1 = g 1 ( ν ^ 1 , ν ^ 2 , ⋯ , ν ^ m ) , θ ^ 2 = g 2 ( ν ^ 1 , ν ^ 2 , ⋯ , ν ^ m ) , ⋯ ⋯ ⋯ ⋯ ⋯ , ν ^ m ) θ ^ m = g m ( ν ^ 1 , ν ^ 2 , ⋯ , (1.11) \tag{1.11} \left\{\begin{array}{l} \hat{\theta}_{1}=g_{1}\left(\hat{\nu}_{1}, \hat{\nu}_{2}, \cdots, \hat{\nu}_{m}\right), \\ \hat{\theta}_{2}=g_{2}\left(\hat{\nu}_{1}, \hat{\nu}_{2}, \cdots, \hat{\nu}_{m}\right), \\ \left.\cdots \cdots \cdots \cdots \cdots, \hat{\nu}_{m}\right) \\ \hat{\theta}_{m}=g_{m}\left(\hat{\nu}_{1}, \hat{\nu}_{2}, \cdots,\right. \end{array}\right. ⎩ ⎨ ⎧θ^1=g1(ν^1,ν^2,⋯,ν^m),θ^2=g2(ν^1,ν^2,⋯,ν^m),⋯⋯⋯⋯⋯,ν^m)θ^m=gm(ν^1,ν^2,⋯,(1.11)
定义的 θ ^ 1 , θ ^ 2 , ⋯ , θ ^ m \hat{\theta}_{1}, \hat{\theta}_{2}, \cdots, \hat{\theta}_{m} θ^1,θ^2,⋯,θ^m 分别是 θ 1 , θ 2 , ⋯ , θ m \theta_{1}, \theta_{2}, \cdots, \theta_{m} θ1,θ2,⋯,θm 的矩估计 (moment estimator). 这里的 ν ^ j \hat{\nu}_{j} ν^j 是 ν j \nu_{j} νj 的点估计, 由 (1.7) 定义. - 由于总体分布 (1.9) 中含有末知参数, 所以 ν j \nu_{j} νj 是参数 θ 1 , θ 2 , ⋯ , θ m \theta_{1}, \theta_{2}, \cdots, \theta_{m} θ1,θ2,⋯,θm 的 函数, 而方程 ( 1.10 ) (1.10) (1.10) 通常是由下面的估计方程
{ ν 1 = h 1 ( θ 1 , θ 2 , ⋯ , θ m ) , ν 2 = h 2 ( θ 1 , θ 2 , ⋯ , θ m ) , ⋯ ⋯ ⋯ ⋯ ⋯ , ν m = h m ( θ 1 , θ 2 , ⋯ , θ m ) (1.12) \tag{1.12} \left\{\begin{array}{l} \nu_{1}=h_{1}\left(\theta_{1}, \theta_{2}, \cdots, \theta_{m}\right), \\ \nu_{2}=h_{2}\left(\theta_{1}, \theta_{2}, \cdots, \theta_{m}\right), \\ \cdots \cdots \cdots \cdots \cdots, \\ \nu_{m}=h_{m}\left(\theta_{1}, \theta_{2}, \cdots, \theta_{m}\right) \end{array}\right. ⎩ ⎨ ⎧ν1=h1(θ1,θ2,⋯,θm),ν2=h2(θ1,θ2,⋯,θm),⋯⋯⋯⋯⋯,νm=hm(θ1,θ2,⋯,θm)(1.12)
得到的. 注意这里的 ν j = E X j \nu_{j}=\mathrm{E} X^{j} νj=EXj.
例题:正态分布参数的矩估计
- 设 X X X 服从正态分布 N ( μ , σ 2 ) N\left(\mu, \sigma^{2}\right) N(μ,σ2).
- 由于
μ = E X , σ 2 = E X 2 − ( E X ) 2 = ν 2 − ν 1 2 , \mu=\mathrm{E} X, \sigma^{2}=\mathrm{E} X^{2}-(\mathrm{E} X)^{2}=\nu_{2}-\nu_{1}^{2}, μ=EX,σ2=EX2−(EX)2=ν2−ν12, - 所以 μ , σ 2 \mu, \sigma^{2} μ,σ2 的矩估计分别是
μ ^ = X ˉ n , σ ^ 2 = ν ^ 2 − ( ν ^ 1 ) 2 = 1 n ∑ j = 1 n X j 2 − ( X ˉ n ) 2 = 1 n ∑ j = 1 n ( X j − μ ^ ) 2 . \begin{aligned} \hat{\mu} &=\bar{X}_{n}, \\ \hat{\sigma}^{2} &=\hat{\nu}_{2}-\left(\hat{\nu}_{1}\right)^{2} \\ &=\frac{1}{n} \sum_{j=1}^{n} X_{j}^{2}-\left(\bar{X}_{n}\right)^{2} \\ &=\frac{1}{n} \sum_{j=1}^{n}\left(X_{j}-\hat{\mu}\right)^{2} . \end{aligned} μ^σ^2=Xˉn,=ν^2−(ν^1)2=n1j=1∑nXj2−(Xˉn)2=n1j=1∑n(Xj−μ^)2.
7.2 最大似然估计
最大似然估计定义 (离散情况)
- 设离散随机变量 X 1 , X 2 , ⋯ , X n X_{1}, X_{2}, \cdots, X_{n} X1,X2,⋯,Xn 有联合分布
p ( x 1 , x 2 , ⋯ , x n ; θ ) = P ( X 1 = x 1 , X 2 = x 2 , ⋯ , X n = x n ) , p\left(x_{1}, x_{2}, \cdots, x_{n} ; \theta\right)=P\left(X_{1}=x_{1}, X_{2}=x_{2}, \cdots, X_{n}=x_{n}\right), p(x1,x2,⋯,xn;θ)=P(X1=x1,X2=x2,⋯,Xn=xn),
其中 θ \theta θ 是末知参数, 给定观测数据 x 1 , x 2 , ⋯ , x n x_{1}, x_{2}, \cdots, x_{n} x1,x2,⋯,xn 后, 我们称 θ \theta θ 的函数
L ( θ ) = p ( x 1 , x 2 , ⋯ , x n ; θ ) L(\theta)=p\left(x_{1}, x_{2}, \cdots, x_{n} ; \theta\right) L(θ)=p(x1,x2,⋯,xn;θ)
为基于 x 1 , x 2 , ⋯ , x n x_{1}, x_{2}, \cdots, x_{n} x1,x2,⋯,xn 的似然函数, 称 L ( θ ) L(\theta) L(θ) 的最大值点 θ ^ \hat{\theta} θ^ 为 θ \theta θ 的最大 似然估计 (maximum likelihood estimator). - θ \theta θ 也可以是向量 θ = ( θ 1 , θ 2 , ⋯ , θ m ) \boldsymbol{\theta}=\left(\theta_{1}, \theta_{2}, \cdots, \theta_{m}\right) θ=(θ1,θ2,⋯,θm).
最大似然估计 (连续型)
- 设随机向量 X = ( X 1 , X 2 , ⋯ , X n ) \boldsymbol{X}=\left(X_{1}, X_{2}, \cdots, X_{n}\right) X=(X1,X2,⋯,Xn) 有联合密度 f ( x ; θ ) f(x ; \boldsymbol{\theta}) f(x;θ), 其 中 θ \theta θ 是末知参数. 得到 X X X 的观测值 x x x 后, 称 θ \theta θ 的函数
L ( θ ) = f ( x ; θ ) L(\boldsymbol{\theta})=f(\boldsymbol{x} ; \boldsymbol{\theta}) L(θ)=f(x;θ)
为基于 x \boldsymbol{x} x 的似然函数. 称似然函数 L ( θ ) L(\boldsymbol{\theta}) L(θ) 的最大值点 θ ^ \hat{\boldsymbol{\theta}} θ^ 为参数 θ \boldsymbol{\theta} θ 的最 大似然估计. - 最大似然估计通常被缩写成 MLE(Maximum Likelihood Estimator).
- 设总体 X X X 有密度函数 f ( x ; θ ) , X 1 , X 2 , ⋯ , X n f(x ; \boldsymbol{\theta}), X_{1}, X_{2}, \cdots, X_{n} f(x;θ),X1,X2,⋯,Xn 是总体 X X X 的简单随机 样本, 则 ( X 1 , X 2 , ⋯ , X n ) \left(X_{1}, X_{2}, \cdots, X_{n}\right) (X1,X2,⋯,Xn) 的联合密度是
f ( x 1 , x 2 , ⋯ , x n ; θ ) = ∏ j = 1 n f ( x j ; θ ) , f\left(x_{1}, x_{2}, \cdots, x_{n} ; \boldsymbol{\theta}\right)=\prod_{j=1}^{n} f\left(x_{j} ; \boldsymbol{\theta}\right), f(x1,x2,⋯,xn;θ)=j=1∏nf(xj;θ), - 基于观测值 x = ( x 1 , x 2 , ⋯ , x n ) \boldsymbol{x}=\left(x_{1}, x_{2}, \cdots, x_{n}\right) x=(x1,x2,⋯,xn) 的似然函数是
L ( θ ) = ∏ j = 1 n f ( x j ; θ ) . L(\boldsymbol{\theta})=\prod_{j=1}^{n} f\left(x_{j} ; \boldsymbol{\theta}\right) . L(θ)=j=1∏nf(xj;θ). - 由于
l ( θ ) = ln L ( θ ) l(\boldsymbol{\theta})=\ln L(\boldsymbol{\theta}) l(θ)=lnL(θ)
和似然函数有相同的最大值点, 所以称上式为对数似然函数. 实际问题中, 求对数似然函数 l ( θ ) l(\boldsymbol{\theta}) l(θ) 的最大值点往往要方便得多.
参数估计还有区间估计、置信区间等相关知识点,由于本人在实际工程上用得不多,所以这一块不总结了。
例题






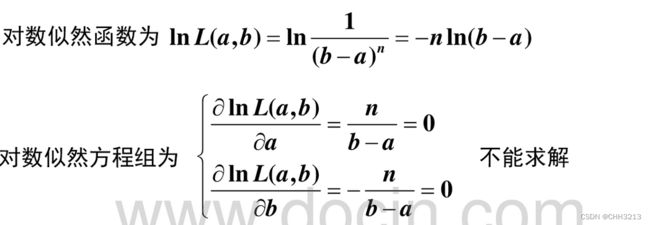



7. 马尔可夫链
该部分来自知乎:https://zhuanlan.zhihu.com/p/418319247