李宏毅机器学习笔记p5-p8:误差和梯度下降
文章目录
- 前言
- 误差Error
-
- 偏差Bias
-
- 偏差过大
- 方差Variance
-
- 方差过大
- 选择平衡偏差和方差的模型
-
- N-折交叉验证
- 梯度下降
-
- 调整学习率
-
- 1.固定学习率
- 2.自适应学习率——Adagrad
- 随机梯度下降
- 特征缩放
- 梯度下降的理论基础
- 总结
前言
这篇开始涉及到了我未涉及的领域,也算是机器学习的慢慢深入,虽然知识点是新的,但通过视频和笔记,还是基本可以理解透彻。
提示:以下是本篇文章正文内容,下面案例可供参考
误差Error
通过前文的学习,我们了解到当次数越高的时候,模型越复杂的时候,测试效果可能不是很好(出现过拟合现象)
这些误差Error主要来源于bias (偏差) 和 variance(方差)


假设一组数据,期望为 μ \mu μ,方差为 σ 2 {\sigma ^2} σ2
偏差Bias
同一个模型在不同的数据集结果是不一样的。
bias:描述的是根据样本拟合出的模型的输出预测结果的期望与样本真实结果的差距,简单讲,就是在样本上拟合的好不好。
评估x的偏差:
当N样本不够大的时候,平均值m并不等于其期望值
m = 1 N ∑ n x n ≠ μ m = \frac{1}{N}\sum\limits_n {{x^n}} \ne \mu m=N1n∑xn=μ
但是m的期望是等于 μ \mu μ的
E [ m ] = E [ 1 N ∑ n x n ] = 1 N E [ ∑ n x n ] = μ {\rm E}[{\rm{m}}] = {\rm E}[\frac{1}{N}\sum\limits_n {{x^n}} ] = \frac{1}{N}E[\sum\limits_n {{x^n}} ]=\mu E[m]=E[N1n∑xn]=N1E[n∑xn]=μ
varience的值取决于今天取了多少sample
V a r [ m ] = σ 2 N Var[m] = \frac{{{\sigma ^2}}}{N} Var[m]=Nσ2
N比较大,则比较集中,N比较小,则会比较分散

偏差过大
偏差过大导致的结果是欠拟合。
原因:没有很好的训练数据集。
改进方法:重新设计模型。
方差Variance
varience:样本上训练出来的模型在测试集上的表现
s 2 = 1 N ∑ n ( x n − m ) 2 {s^2} = \frac{1}{N}\sum\limits_n {{{({x^n} - m)}^2}} s2=N1n∑(xn−m)2
测试 s 2 {s^2} s2的期望 :
E [ s 2 ] = N − 1 N σ 2 E[{s^2}] = \frac{{N - 1}}{N}{\sigma ^2} E[s2]=NN−1σ2
结果:
简单的模型面对多种多样的数据样本方差就会比较小——>训练集影响较小。
方差过大
方差过大的导致的是过拟合。
原因:训练集训练的很好,但在测试集上,方差过大,错误较大。
改进方法:更多的数据。
选择平衡偏差和方差的模型
1.不能因为在你的测试集上误差较小,就认为这个模型好:因为你的测试集只是所有测试数据的一部分。
N-折交叉验证

1.将训练集分成N份。
2.把其中一份作为测试集,把N-1份作为训练集,算出在备选 Model 上 err 的结果。然后选另一份作为测试集,以此类推重复N遍。
3.算出每一种模型的Average error 然后选出Error最小的那一份model。
4.用选出的model训练所有训练集,最后得出结果。
梯度下降
目标:
θ ∗ = arg min θ L ( θ ) {\theta ^*} = \arg \mathop {\min }\limits_\theta L(\theta ) θ∗=argθminL(θ)
L:损失函数, θ \theta θ:参数(可以是一串列向量)
迭代过程:
θ n = θ n − 1 − η ∇ L ( θ n − 1 ) {\theta ^n} = {\theta ^{n - 1}} - \eta \nabla L({\theta ^{n - 1}}) θn=θn−1−η∇L(θn−1)
∇ L ( θ ) = [ ∂ L ( θ 1 ) ∂ θ 1 ∂ L ( θ 2 ) ∂ θ 2 ⋮ ∂ L ( θ n ) ∂ θ n ] \nabla L(\theta ) = \left[ {\begin{matrix}{} {\frac{{\partial L({\theta _1})}}{{\partial {\theta _1}}}}\\ {\frac{{\partial L({\theta _2})}}{{\partial {\theta _2}}}}\\ \vdots \\ {\frac{{\partial L({\theta _n})}}{{\partial {\theta _n}}}} \end{matrix}} \right] ∇L(θ)=⎣⎢⎢⎢⎢⎡∂θ1∂L(θ1)∂θ2∂L(θ2)⋮∂θn∂L(θn)⎦⎥⎥⎥⎥⎤
η \eta η:学习率
调整学习率
1.固定学习率
整场learning rate都不改变:
learning rate:太小——>走得很慢(蓝线);比较大——>走得很快,会导致在谷区振荡(绿线);超级大——>直接跳跃出谷区,飞出去了。(黄线)

2.自适应学习率——Adagrad
learning rate在改变
调整方法:
刚开始:设置较大的learning rate——>因为离最优点较远
在几次update:慢慢减少自己的learning rate
——————————————————————————————
较好的方法是:每个不同的参数,都给予不同的learning rate——>经典方法:Adagrad
{ w t + 1 = w t − η t σ t g t g t = ∂ L ( θ t ) ∂ w σ t = 1 t + 1 ∑ i = 0 t ( g i ) 2 \left\{ {\begin{matrix}{} {{w^{t + 1}} = {w^t} - \frac{{{\eta ^t}}}{{{\sigma ^t}}}{g^t}}\\ {{g^t} = \frac{{\partial L({\theta ^t})}}{{\partial w}}}\\ {{\sigma ^t} = \sqrt {\frac{1}{{t + 1}}\sum\limits_{i = 0}^t {{{({g^i})}^2}} } } \end{matrix}} \right. ⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧wt+1=wt−σtηtgtgt=∂w∂L(θt)σt=t+11i=0∑t(gi)2
η t = n t + 1 {\eta ^t} = \frac{n}{{\sqrt {t + 1} }} ηt=t+1n
σ t {{\sigma ^t}} σt:是之前参数所有微分的均方根
化简得:
w t + 1 = w t − η ∑ i = 0 t ( g i ) 2 g t {w^{t + 1}} = {w^t} - \frac{\eta }{{\sqrt {\sum\limits_{i = 0}^t {{{({g^i})}^2}} } }}{g^t} wt+1=wt−i=0∑t(gi)2ηgt
改编之后: ∑ i = 0 t ( g i ) 2 {\sqrt {\sum\limits_{i = 0}^t {{{({g^i})}^2}} } } i=0∑t(gi)2和 g t {g^t} gt当t越大的时候,他们造成的影响是反差的
原因是:
最好的步伐:
一个参数:步伐 ∝ \propto ∝一次微分
多个参数:步伐 ∝ \propto ∝一次微分/二次微分
跟adgrad的关系:
g t {g^t} gt ——>一次微分
∑ i = 0 t ( g i ) 2 {\sqrt {\sum\limits_{i = 0}^t {{{({g^i})}^2}} } } i=0∑t(gi)2——>反应了二次微分
随机梯度下降
普通的梯度下降:
计算所有的loss,然后再算 θ n {\theta ^n} θn
θ n = θ n − 1 − η ∇ L ( θ n − 1 ) {\theta ^n} = {\theta ^{n - 1}} - \eta \nabla L({\theta ^{n - 1}}) θn=θn−1−η∇L(θn−1)
随机的梯度下降:
只取某一个example算loss function,就可以算 θ n {\theta ^n} θn
优势:在计算相同个数的例子的时候,随机梯度下降法更新的速度更快。
特征缩放
目的:不同的特征所处的范围是类似的
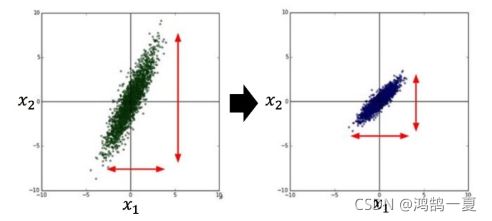
原因:参照上图,当 x 1 {x_1} x1的系数和 x 2 {x_2} x2的系数发生一样幅度的变化,明显 x 2 {x_2} x2对结果的影响比 x 1 {x_1} x1大
转化完之后——>参数更新会比较容易。
方法:
常见方法:
x i r = x i r − m i σ i {x_i}^r = \frac{{{x_i}^r - {m_i}}}{{{\sigma _i}}} xir=σixir−mi
m i {m_i} mi为同一维度的平均数, σ i {\sigma_i } σi为同一维度标准差
梯度下降的理论基础
假设有两个变量 θ 1 \theta_1 θ1 θ 2 \theta_2 θ2
在(a,b)点
利用泰勒展开得
L ( θ ) ≈ L ( a , b ) + ∂ L ( a , b ) ∂ θ 1 ( θ 1 − a ) + ∂ L ( a , b ) ∂ θ 2 ( θ 2 − b ) L(\theta ) \approx L(a,b) + \frac{{\partial L(a,b)}}{{\partial {\theta _1}}}({\theta _1} - a) + \frac{{\partial L(a,b)}}{{\partial {\theta _2}}}({\theta _2} - b) L(θ)≈L(a,b)+∂θ1∂L(a,b)(θ1−a)+∂θ2∂L(a,b)(θ2−b)
问题转化为:
min L ( θ ) \begin{matrix}{} {\min }&{L(\theta )} \end{matrix} minL(θ)
{ ( θ 1 − a ) 2 + ( θ 2 − b ) 2 ≤ d 2 L ( θ ) ≈ L ( a , b ) + ∂ L ( a , b ) ∂ θ 1 ( θ 1 − a ) + ∂ L ( a , b ) ∂ θ 2 ( θ 2 − b ) θ = { θ 1 , θ 2 } \left\{ {\begin{matrix}{} {{{({\theta _1} - a)}^2} + {{({\theta _2} - b)}^2} \le {d^2}}\\ {L(\theta ) \approx L(a,b) + \frac{{\partial L(a,b)}}{{\partial {\theta _1}}}({\theta _1} - a) + \frac{{\partial L(a,b)}}{{\partial {\theta _2}}}({\theta _2} - b)}\\ {\theta = \{ {\theta _1},{\theta _2}\} } \end{matrix}} \right. ⎩⎨⎧(θ1−a)2+(θ2−b)2≤d2L(θ)≈L(a,b)+∂θ1∂L(a,b)(θ1−a)+∂θ2∂L(a,b)(θ2−b)θ={θ1,θ2}
我们可以得出:
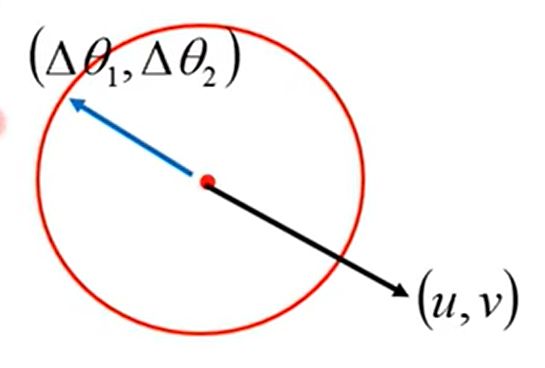
[ θ 1 − a θ 2 − b ] = − η [ ∂ L ( a , b ) ∂ θ 1 ∂ L ( a , b ) ∂ θ 2 ] \left[ {\begin{matrix}{} {{\theta _1} - a}\\ {{\theta _2} - b} \end{matrix}} \right] = - \eta \left[ {\begin{matrix}{} {\frac{{\partial L(a,b)}}{{\partial {\theta _1}}}}\\ {\frac{{\partial L(a,b)}}{{\partial {\theta _2}}}} \end{matrix}} \right] [θ1−aθ2−b]=−η[∂θ1∂L(a,b)∂θ2∂L(a,b)]
时, L ( θ ) {L(\theta )} L(θ)最小。
变形得
[ θ 1 θ 2 ] = [ a b ] − η [ ∂ L ( a , b ) ∂ θ 1 ∂ L ( a , b ) ∂ θ 2 ] \left[ {\begin{matrix}{} {{\theta _1}}\\ {{\theta _2}} \end{matrix}} \right] = \left[ {\begin{matrix}{} a\\ b \end{matrix}} \right] - \eta \left[ {\begin{matrix}{} {\frac{{\partial L(a,b)}}{{\partial {\theta _1}}}}\\ {\frac{{\partial L(a,b)}}{{\partial {\theta _2}}}} \end{matrix}} \right] [θ1θ2]=[ab]−η[∂θ1∂L(a,b)∂θ2∂L(a,b)]
和上文的 θ n = θ n − 1 − η ∇ L ( θ n − 1 ) {\theta ^n} = {\theta ^{n - 1}} - \eta \nabla L({\theta ^{n - 1}}) θn=θn−1−η∇L(θn−1)相同。推导成立。
但前提是:能如此泰勒展开需要学习率足够小才可以。
扩展:上文时泰勒一次展开项,若二次项(牛顿法)则过于繁琐。
总结
提示:这里对文章进行总结:
例如:学习误差包括偏差和方差,里面的那张图真的非常生动形象,比较容易理解。还学习了N-折交叉验证,在我意识里测试集好的话,那模型一定好,看来是我的误解,也算纠正了我错误的地方。然后学习了自适应学习率,在上一章代码有涉及,也提前了解过。通过理论推导梯度下降,是一个看似复杂但可以理解的更加透彻的过程。