模板匹配与像素统计
模板匹配、直方图和折线图
- 模板匹配
-
- 单一匹配区域
- 多个匹配图像
- 像素统计
-
- 直方图
- 折线图
-
- 掩膜的使用
- 直方图均衡化
-
- 自适应均衡化
模板匹配
模板匹配与卷积原理相似,模板内容在原图上原点处开始对比,计算模板与原图对应像素点的差别程度,计算完成后,模板以类似于卷积核滑动的方式进行滑动,依此循环。模板匹配的核心在于差别程度的计算方法,opencv提供了六种计算方法:
- TM_SQDIFF:计算平方不同,计算出来的值越小,越相关
- TM_CCORR:计算相关性,计算出来的值越大,越相关
- TM_CCOEFF:计算相关系数,计算出来的值越大,越相关
- TM_SQDIFF_NORMED:计算归一化平方不同,计算出来的值越接近0,越相关
- TM_CCORR_NORMED:计算归一化相关性,计算出来的值越接近1,越相关
- TM_CCOEFF_NORMED:计算归一化相关系数,计算出来的值越接近1,越相关
相关方法的计算公式大家可以自行查看一下。
匹配使用的函数为:
cv2.matchTemplate(img, template, methods)
其中,第二个参数是待匹配的模板矩阵,第三个参数用来放置我们刚刚介绍的六种方法之一,带归一化的方法是最为常用的。
import cv2
img = cv2.imread('lena.jpg',cv2.IMREAD_GRAYSCALE)
template = cv2.imread('face.jpg', 0) # 第二个参数选择0和选择cv2.IMREAD_GRAYSCALE是一样的
h, w = template.shape[:2] # 将template矩阵的行(高)和列(宽)记录
res = cv2.matchTemplate(img, template,cv2.TM_CCORR_NORMED)
print(res)
print(res.shape)
这样会输出一个存储相似度的矩阵:
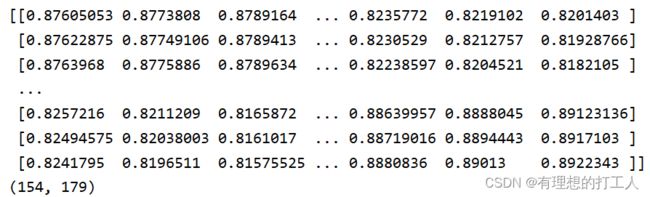
这个矩阵中的每个值都代表原图中与模板维度相同的每一部分,实际与模板的匹配程度。假设原图的矩阵是A×B大小,模板是a×b大小,则不难理解我们获得的res矩阵是一个(A-a+1)×(B-b+1)大小的矩阵。
下面问题又来了,我们虽然得到了匹配度矩阵,但是想要找到最为匹配的区域,势必要找到匹配度矩阵中元素最满足算法要求的一个(或多个)值,并且需要得到这个值所代表的原图像的区域。虽然计算方法不难,但如果交给我们自己去找会是个很大的工作量。这里就需要用到cv2.minMaxLoc (res)函数了。该函数会给我们返回四个值,分别是最小值,最大值,最小值所在区域的最左上角像素点坐标,最大值所在区域的最左上角像素点坐标。我们可以根据算法定义的匹配条件圈出匹配区域。下面我们来做个六种方式得到的单一匹配区域对比:
单一匹配区域
import cv2
import matplotlib.pyplot as plt
from matplotlib import font_manager
# 设置font使用隶书6号字
font= font_manager.FontProperties(fname=r"c:\windows\fonts\msyh.ttc", size=6)
img = cv2.imread('lena.jpg',cv2.IMREAD_GRAYSCALE)
template = cv2.imread('face.jpg', 0) # 第二个参数选择0和选择cv2.IMREAD_GRAYSCALE是一样的
h, w = template.shape[:2] # 将template矩阵的行(高)和列(宽)记录
methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR',
'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']
i=0
fig, ax = plt.subplots(6,2)
for meth in methods:
img2 = img.copy()
# 字符串类型不能被当做matchTemplate()函数的参数
# 将存储的方法名转换成对应的序号
method = eval(meth)
print(method,end=' ')
res = cv2.matchTemplate(img, template, method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# 如果是平方差匹配TM_SQDIFF或归一化平方差匹配TM_SQDIFF_NORMED,取最小值
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
# 画矩形,框选出最佳匹配的原图区域
cv2.rectangle(img2, top_left, bottom_right, 255, 2)
ax[i, 0].set_title(meth,fontproperties=font)
ax[i, 0].imshow(res, cmap='gray')
ax[i, 0].axis('off') # 关闭坐标轴显示
ax[i,1].imshow(cv2.cvtColor(img2,cv2.IMREAD_GRAYSCALE))
ax[i,1].axis('off')
i+=1
plt.show()
# 控制台输出为:4 5 2 3 0 1

可以看到,除了TM_CCORR方法以外,其他的方法得到的匹配内容和模板都比较一致。如果小伙伴觉得图片输出太小的话,可以更改每次输出图片的数量。
多个匹配图像
想要得到多个匹配区域,我们就需要对匹配矩阵中,匹配指数大于设定值(如大于90%的区域)位置都加以保留。比如我们想要从下图中:

找出所有的金币:
![]()
import cv2
import numpy as np
import matplotlib.pyplot as plt
img_rgb = cv2.imread('mario.jpg')
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
template = cv2.imread('mario_coin.jpg', 0)
h, w = template.shape[:2]
res = cv2.matchTemplate(img_gray, template, cv2.TM_CCOEFF_NORMED)
threshold = 0.85
# 取匹配程度大于85%的坐标
loc = np.where(res >= threshold)
# loc[::-1]可以把loc中的序列调换位置,自行查看一下
# print(loc)
# print(loc[::-1])
for pt in zip(*loc[::-1]):
bottom_right = (pt[0] + w, pt[1] + h)
cv2.rectangle(img_rgb, pt, bottom_right, (0, 0,255), 1)
cv2.imshow('img_rgb', img_rgb)
cv2.waitKey(0)
可以从这里查看zip函数的使用。
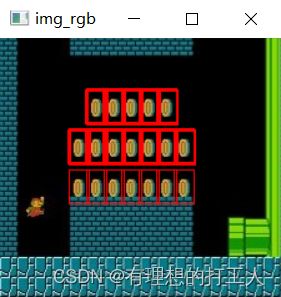
threshold选择多大比较合适是需要我们在实测中确定的,这里圈金币的框有深有浅,原因在于浅的地方只被圈出一次,而深的地方被圈出了多次,这就是因为我们设置的threshold标准对于这些地方来说过于宽松,其附近的位置也会满足res >= threshold的条件,因此一个金币附近会被圈出很多次。
像素统计
直方图
直方图的概念我在数据分析:数据可视化3(2)中具体讲过,这里说的直方图也是一样:

针对像素矩阵值绘制直方图,也是要使用plt.hist()函数:
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('dog.jpg',0)
# ravel函数可以把img矩阵变成一个一维列表
plt.hist(img.ravel(),256)
plt.show()
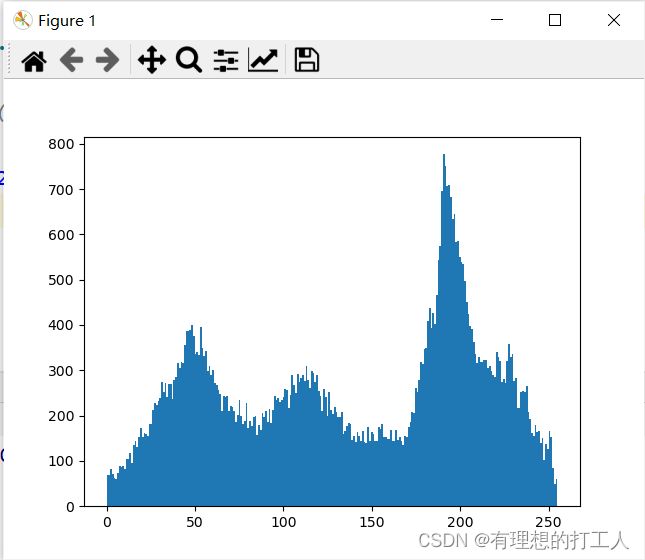
需要注意的是,ravel函数也可以把(n×m×3)的矩阵转换成一维列表。我们如果传入的是彩色图像,绘制出的直方图将会统计三个通道中所有像素值的分布情况。
折线图
折线图我在之前的数据分析:数据可视化2中也有过介绍。在这里,绘制折线图需要使用的额外函数为:
cv2.calcHist(images,channels,mask,histSize,ranges)
其中:
- images: 原图像图像格式为 uint8 或 float32。当传入函数时 用中括号 [] 括来,例如[img]。
- channels: 同样用中括号括起来。它会告函数我们需要的统计图。如果输入图像是灰度图,这个参数就可以写成 [0],如果需要传入的图像是彩色的,这个参数可以是 [0](B通道矩阵) [1] (G通道矩阵)[2] (R通道矩阵)。
- mask: 掩模图像。如果要统计所有像素点,这个值设置成None。但是如果你想统图像的某一分并制作直方图,就需要制作一个掩膜,盖住不需要统计的部分并传递给函数。
- histSize:分成的区域数量,例如我们想要以(0-10,10-20,…)为分组方式,这个参数要写成[26]。
- ranges: 像素值范围,常为 [0,256]。
- 该函数的返回值是一个(histSize)行1列的矩阵,存储每个范围内包括的像素值总个数。
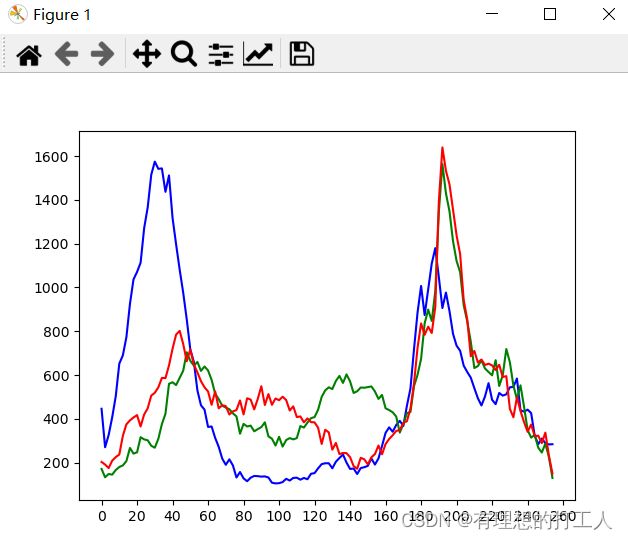
那么我们还用刚才的图像绘制一个折线图,以[0-2),[2-4),…,[254-256)的方式进行分组,绘制出每一组内包含的所有像素点个数:
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('dog.jpg',0)
histr = cv2.calcHist([img],[0],None,[128],[0,256])
plt.plot(histr)
x=range(261) # 设置x轴显示略大一些
plt.xticks(range(0,131,10),x[0:261:20]) # 将x轴分为13段,标注值从0开始,到260结束,步长为20
plt.show()
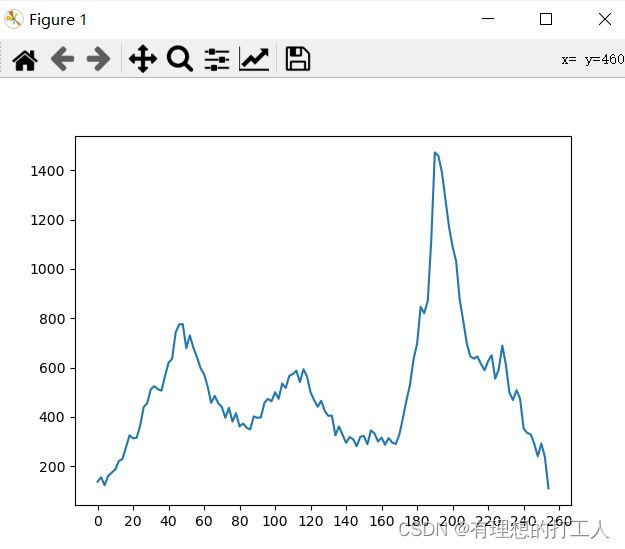
当然,我们也可以稍微修改一下代码,绘制出彩色图像三个通道的折线图:
img = cv2.imread('dog.jpg')
color = ('b','g','r')
# enumerate(color)函数可以生成类似(0,color[0])的组合
for i,col in enumerate(color):
histr = cv2.calcHist([img],[i],None,[128],[0,256])
plt.plot(histr,color = col)
x=range(261)
plt.xticks(range(0,131,10),x[0:261:20])
plt.show()
掩膜的使用
上文我们讲过,想要统计某个区域的像素,那就需要制作一个掩膜。制作眼膜也很简单,我们只需要先做一个与图片等大的黑底,然后将所需要统计的部分做成白色:
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('dog.jpg',0)
m,n=img.shape
mask = np.zeros((m,n), np.uint8)
mask[70:200, 70:200] = 255
# 显示掩膜
cv2.imshow('mask', mask)
cv2.waitKey(0)
cv2.destroyAllWindows()
这样,我们的掩膜就职做好了: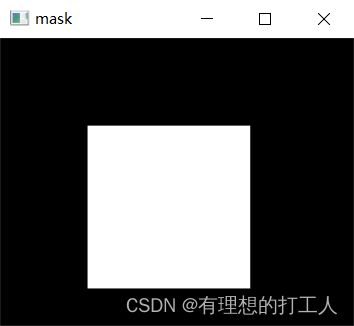
掩膜制做好之后我们只需要使用能够处理掩膜的函数对图像进行加工,如:
bitwise_and(src1, src2, dst=None, mask=None)
- src1代表第一张输入图片;
- src2代表第二章输入图片;
- dst一般为默认参数None,这里我们不需要管;
- mask代表掩膜,为8位单通道的灰度图像。
bitwise_and()是按位与操作,它会将scr1和scr2两张图片的像素矩阵值一一对应的做按位与操作。需要注意的是,按位与是对二进制数做的操作(我们不需要额外操作原像素矩阵)。做好与操作之后,会得到一个新的图像,并将这个图像与掩膜运算,掩膜矩阵中数值为0的点会遮盖住新图像的对应部分内容后返回。
通俗的理解,掩膜是一张黑纸挖了几个洞,我们把掩膜贴在原图上就会遮盖掉黑色的部分了。由于我们只需要掩盖原图的一部分,所以我们可以用“自己与自己”的方式得到自己,再与掩膜操作:
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('dog.jpg')
# 制作掩膜
mask = np.zeros(img.shape[:2], np.uint8)
mask[20:95, 140:200] = 255
# 用掩膜遮盖部分原图
masked_img = cv2.bitwise_and(img, img, mask=mask)
# 显示掩盖后的图片
cv2.imshow('masked_img', masked_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
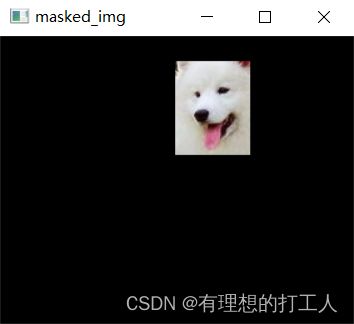
做完了掩膜,我们来绘制个折线图对比一下:
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('dog.jpg',0) # 这里我们用灰度图对比
# 制作掩膜
mask = np.zeros(img.shape[:2], np.uint8)
mask[20:95, 140:200] = 255
# 用掩膜遮盖部分原图
masked_img = cv2.bitwise_and(img, img, mask=mask)
hist_full = cv2.calcHist([img], [0], None, [256], [0, 256])
hist_mask = cv2.calcHist([img], [0], mask, [256], [0, 256])
# 绘制折线图对比
plt.subplot(221), plt.imshow(img, 'gray')
plt.subplot(222), plt.imshow(mask, 'gray')
plt.subplot(223), plt.imshow(masked_img, 'gray')
plt.subplot(224), plt.plot(hist_full), plt.plot(hist_mask)
plt.xlim([0, 256])
plt.show()

可以看出,狗的脸部是整体偏亮的。
直方图均衡化
在很多图片中,像素值都会出现“扎堆”的现象,表现为像素矩阵值在某个或某几个较小的范围内大量聚集(还用狗图像的直方图):

图像均衡化的就是要消灭这种聚集现象,操作的方法如下:

opencv中也给我们提供了均衡化函数:
cv2.equalizeHist(img)
这个函数没有过多参数,非常简单:
import cv2
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import font_manager
# 中文显示
font = font_manager.FontProperties(fname=r"c:\windows\fonts\msyh.ttc", size=10)
img = cv2.imread('dog.jpg',0)
equ = cv2.equalizeHist(img)
# 原图与均衡化后图像进行对比
plt.subplot(221), plt.imshow(img, 'gray'),plt.title('原狗',fontproperties=font)
plt.subplot(222), plt.imshow(equ, 'gray'),plt.title('均衡化狗',fontproperties=font)
plt.subplot(223), plt.hist(img.ravel(),256)
plt.subplot(224), plt.hist(equ.ravel(),256)
plt.xlim([0, 256])
plt.show()
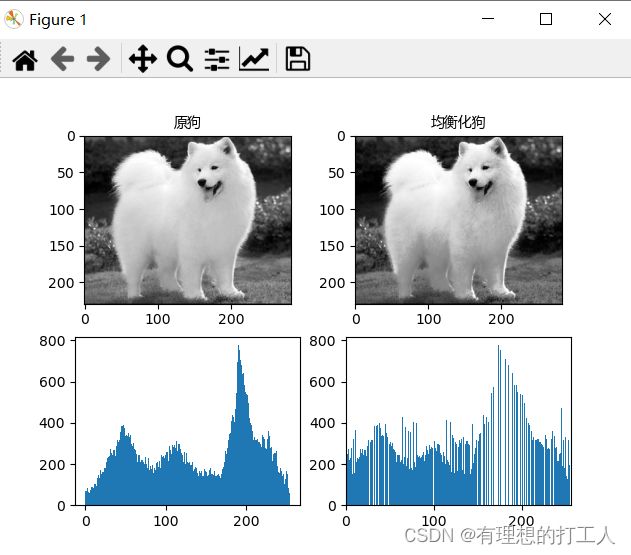
可以看出,均衡化会图像像素点分布会更“平均”,在这幅图中,均衡化图像确实会让我们觉得看起来更舒服。但是,和求取平均数一样,如果我们的图片上就是有一小片区域细节非常多,贸然的均衡化会导致这些细节被淹没。比如:

自适应均衡化
自适应均衡化就是将一幅图片拆成多个小图,分别进行均衡化然后再拼到一起,以此削弱平均对原图个别细节部分的影响,使用函数如下:
cv2.createCLAHE(clipLimit,tileGridSize)
- clipLimit1:该值越大,局部对比度越高;
- tileGridSize:将图像分为m行n列的图像进行均衡化,默认为分为8行8列共64个小图片。
我们来看看自适应均衡化的结果吧:
import cv2
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import font_manager
# 中文显示
font = font_manager.FontProperties(fname=r"c:\windows\fonts\msyh.ttc", size=10)
img = cv2.imread('clahe.jpg',0)
# 自适应均衡化
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8))
# 统一矩阵存储数据的维度和类型
clahe = clahe.apply(img)
# 原图与均衡化后图像进行对比
plt.subplot(121), plt.imshow(img, 'gray'),plt.title('原图',fontproperties=font)
plt.subplot(122), plt.imshow(clahe, 'gray'),plt.title('自适应均衡化图',fontproperties=font)
plt.show()
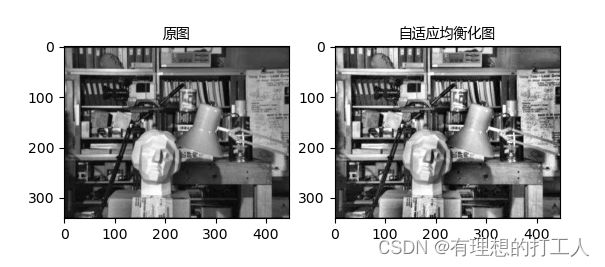
这样一来我们就能把细节处理得更好了。还有一点需要注意,如果一幅图片噪点过多,均衡化处理会导致噪点的影响扩散,因此对于噪声干扰较多的图片,自适应均衡化也不能得到令人满意的结果。那么,今天的内容就这么多了,下一节我们开始介绍傅里叶变换及其应用。下节见~
细节越清晰裁剪限制,此值与对比度受限相对应,对比度限制这个参数是用每块的直方图的每个bins的数和整图的平均灰度分布数的比值来限制的。 裁剪则是将每块图像直方图中超过ClipLimit的bins多出的灰度像素数去除超出部分,然后将所有bins超出的像素数累加后平均分配到所有bins。 ↩︎