清华&旷视:RepVGG,更佳的速度-精度trade-off!
点击上方“计算机视觉工坊”,选择“星标”
干货第一时间送达
![]()
文章题目:RepVGG:Make VGG-style ConvNets outstanding again
代码地址:在公众号「计算机视觉工坊」,后台回复「RepVGG」,即可直接下载。
摘要:
本文提出一种简单而强有力的CNN架构RepVGG,在推理阶段,它具有与VGG类似的架构,而在训练阶段,它则具有多分支架构体系,这种训练-推理解耦的架构设计被称为“重参数化”。
研究现状:
尽管许多复杂的ConvNet都比简单的ConvNet提供更高的准确性,但缺点很明显。1)复杂的多分支设计(例如ResNet中的残差加法和Inception中的分支级联)使模型难以实现和定制,减慢了推理速度并降低了内存利用率。2)一些组件增加了内存访问成本,并且缺乏对各种设备的支持。此外,还有影响的因素,浮点运算(FLOP)的数量不能准确反映实际速度。因此,VGG和ResNets的原始版本仍然在学术界和工业界广泛用于现实世界的应用程序。
研究贡献:
基于上述研究现状,本文的研究人员提出了一种简单有强有的CNN架构RepVGG,相比其他架构,具有更佳的精度-速度均衡;对plain架构采用重参数化技术;并在图像分类、语义分割等任务上验证了RepVGG的有效性。
研究细节:
1. 选择ConvNet的原因:
快速:相比VGG,现有的多分支架构理论上具有更低的计算速度,但推理速度并未更快。计算速度与推理速度的矛盾主要源自两个关键因素:(1)内存访问消耗,比如多分支结构的运算很小,但内存访问消耗很高;(2)并行度,并行度高的模型要比并行度低的模型推理速度更快。
节省内存:多分支结构是一种内存低效的架构,这是因为每个分支的结构都需要在运算之前保存,这会导致更大的峰值内存占用;而plain模型则具有更好的内存高效特征。
灵活:多分支结构会限制CNN的灵活性,与此同时,多分支结构对于模型剪枝不够友好。
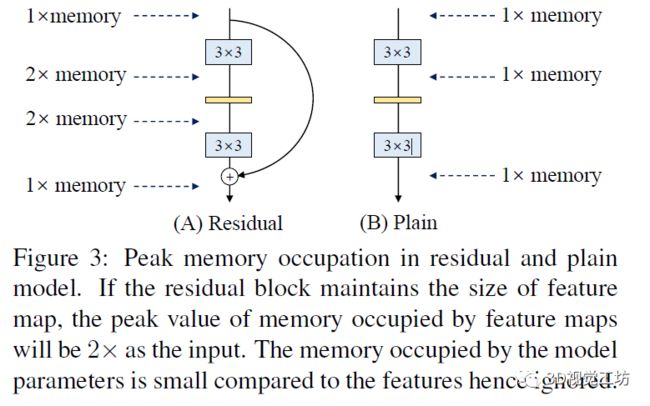
2. 训练中的多分支架构体系
Palin模型存在性能差的缺点。本文设计的RepVGG,其ResNet的ResBlock构建了一个短连接模型信息流,当的维度不匹配时,则转变为。尽管多分支结构对于推理不友好,但适合于训练,研究人员将RepVGG设计为训练时多分支,推理时单分支结构。研究人员设计了如下形式模块:
其中,分别对应,卷积。在训练阶段,通过简单的堆叠上述模块构建CNN架构;而在推理阶段,上述模块可以轻易转换为形式,且的参数可以通过线性组合方式从已训练好的模型中转换得到。
3. Plain架构的重新参数化
研究中将已训练模块转换成单一的卷积用于推理。下图给出了参数转换示意图。
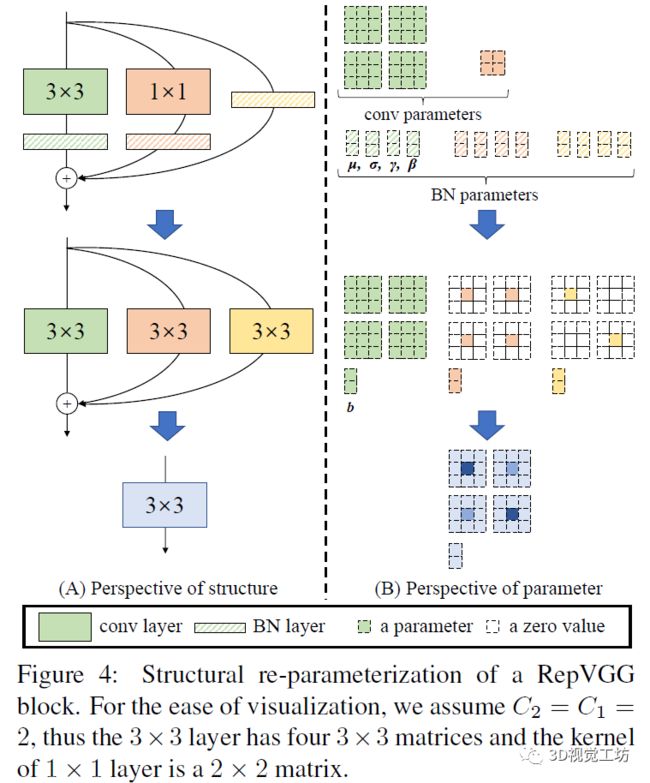
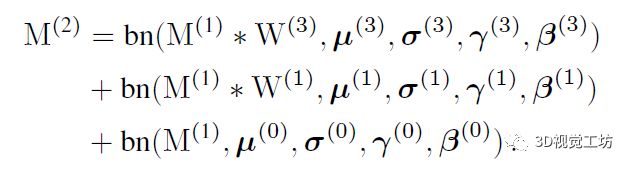
模块中仅具有一个卷积核,两个1卷积核以及三个bias参数,三个bias参数相加即可合并为一个bias,卷积核是通过将卷积核参数与卷积核的中心点相加获取的。
4. RepVGG网络设计
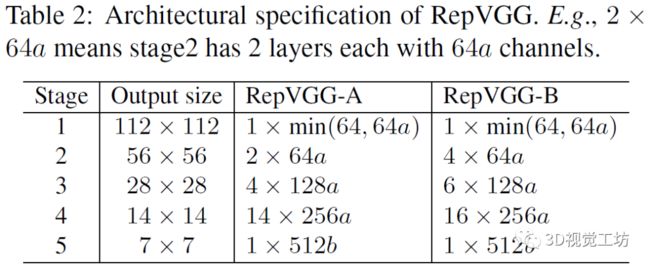
RepVGG是一种类VGG的架构,文中对于每个阶段的层数按照如下规则进行相应的设计。研究人员遵循三个简单的准则来决定每个阶段的层数。1)第一阶段以高分辨率运行,很耗时,因此仅使用一层来降低延迟。2)最后一级应具有更多通道,因此仅使用一层来保存参数。3)紧随ResNet及其最新版本之后,研究人员将最多的层放到倒数第二级(在ImageNet上具有的输出分辨率),设置五个阶段分别具有1、2、4、14、1层,以构造一个名为RepVGG-A的实例。此外还构建了更深的RepVGG-B,在stage2、3和4中又增加了2层。使用RepVGG-A与其他轻型和中等重量型号竞争,包括ResNet-18 / 34/50,而RepVGG-B与高性能机型竞争
基于上述规则,RepVGG-A中的层数对应为1,2,4,14,1;RepVGG-B中的层数对应为1,4,6,16,1,下图为两者的对比。
5. 实验:
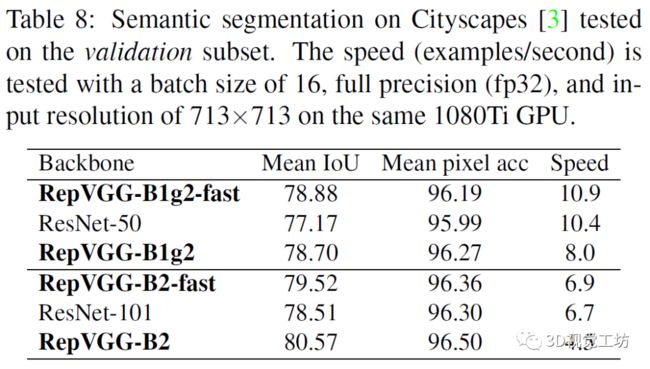
实验中,研究人员将RepVGG的性能与ImageNet上的基线进行比较,通过一系列消融研究和比较证明结构重新参数化的重要性,并验证RepVGG在语义分割上的泛化性能
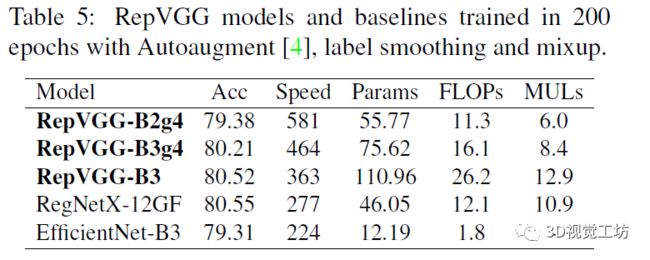
本文主要是在ImageNet图像分类任务上进行了实验,实验结果如下图所示,主要反映了RepVGG和不同计算量的ResNe和变体在精度、速度、参数量上的对比,从中不难发现,RepVGG具有更好的精度-速度均衡。在ImageNet数据集上,RepVGG取得了超过80%的top-1精度,这是plain模型首次达到如此高的精度。在NVIDIA 1080TiGPU上,RepVGG比ResNet50快83%,比ResNet101快101%,同时具有更高的精度。

与此同时,RepVGG在参数量和推理速度上也具有较好的性能。
不足:RepVGG模型是快速,简单和实用的ConvNet架构,在GPU和专用硬件上以最快的速度运行,而无需考虑参数等。尽管RepVGG模型的参数效率比ResNets高,但在低功耗设备应用上,它们可能不如MobileNets和ShuffleNets等移动系统模型。
总结:本文提出了RepVGG,一个简单的体系结构,适用于GPU和专用推理芯片。研究人员通过结构重新参数化方法,使其在ImageNet上可以达到80%的top-1精度,并且与最新的复杂模型相比,它显示出良好的速度-精度性能。
备注:作者也是我们「3D视觉从入门到精通」特邀嘉宾:一个超干货的3D视觉学习社区
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「计算机视觉工坊」公众号后台回复:深度学习,即可下载深度学习算法、3D深度学习、深度学习框架、目标检测、GAN等相关内容近30本pdf书籍。
下载2
在「计算机视觉工坊」公众号后台回复:计算机视觉,即可下载计算机视觉相关17本pdf书籍,包含计算机视觉算法、Python视觉实战、Opencv3.0学习等。
下载3
在「计算机视觉工坊」公众号后台回复:SLAM,即可下载独家SLAM相关视频课程,包含视觉SLAM、激光SLAM精品课程。
重磅!计算机视觉工坊-学习交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有ORB-SLAM系列源码学习、3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、深度估计、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 