Python之numpy和pandas
参考:
黑马4天学数据挖掘(其实就是几个常见库)
参考好文:戳我
这个更全面: 戳我
numpy和pandas是用c写出来的,效率比较高,这就是数据分析要用这些库的原因
元组,列表,Number和字典:戳我
为什么要用anaconda,创建环境,切换环境,安装,升级以及卸载Python的包,为什么说 Jupyter Notebook 是文学式开发工具?因为 Jupyter Notebook 将代码、说明文本、数学方程式、数据可视化图表内容全部组合到一起并显示在一个共享的文档中,可以实现一边写代码一边记录的效果:
戳我
Jupyter Notebook 有两种模式:编辑模式与命令模式。编辑模式下可以输入代码或文档,而命令模式下可以执行 Jupyter Notebook 命令。在编辑和命令模式之间切换,分别使用 Esc 键和 Enter 键。无论当前为何种模式,按下 Esc 键就可以进入命令模式
科学计算工具 IPython
IPython 是公认的现代科学计算中最重要的 Python 工具之一,它是一个加强版的 Python 交互式命令行工具,与系统自带的 Python 交互环境相比,IPython 主要具有以下特点:与 Shell 紧密关联,可以在 IPython 开发环境下直接执行 Shell 指令。它是可以直接进行绘图操作的 Web GUI 环境,在机器学习领域、探索数据模式、可视化数据、绘制学习曲线时,功能都非常强大。更强大的交互功能,包括内省、Tab 键自动完成、魔术命令等。在前面已经安装了 ipython 这里我就不再进行赘述。
在 shell 中输入表达式时,只要按下 Tab 键,与当前输入内容相匹配的方法、函数、对象等就会被找出来。
在变量的前面或者后面加上一个问号 ?,就可以将有关该对象的一些通用信息显示出来,这就叫作对象的内省。例如,创建一个列表 num_list,然后输入 num_list?,将输出列表 num_list 的相关信息,如类型、列表元素和长度等
那么,如果使用两个问号“??”,则显示该方法的源代码。
IPython 常用的魔法命令如下:%run:运行外部 Python 文件。在 IPython 环境中,所有文件都可以通过 %run 命令当作 Python 程序来运行,输入 %run *.py 即可(默认是当前目录)。
%hist:历史命令。简单地使用上、下翻页键就可以查看所有的历史输入。%timeit:用于快速测试代码的运行时间。%debug:用于在程序异常点启动调试器,也可以使用 %pdb 命令激活 IPython 调试器。这样,每当异常抛出时,调试器就会自动运行。%pylab:魔法命令。它可以使得 Numpy 和 Matplotlib 中的科学计算功能生效,这些功能被称为基于向量和矩阵的高效操作,具有交互可视化的特性。它能够让我们在控制台进行交互式计算和动态绘图。%paste:用于直接粘贴一段代码,前提是先复制一段代码。%paste 的执行顺序是:先将代码打印出来,然后再执行该段代码。%lsmagic:用于获取更多的魔法命令。
在 IPython 环境中可以直接执行 Shell 命令,在 Shell 命令前加上叹号 ! 即可。例如,测试百度网络连接(ping 百度,即 !ping baidu.com)
安装到system32时权限不足:
解决方法:先下载到别的位置,再复制进去
numpy
ndarray
n - 任意个
d - dimension 维度
array - 数组
ndarray - 相同类型 - 可以在内存里连续存储,效率高
list - 不同类型 - 不可以在内存里连续存储
list和元组区别?戳我
numpy有自己的数据类型,OK
empty:创建空矩阵
arange函数可以生成一个等差数列的数组,还有一个叫range

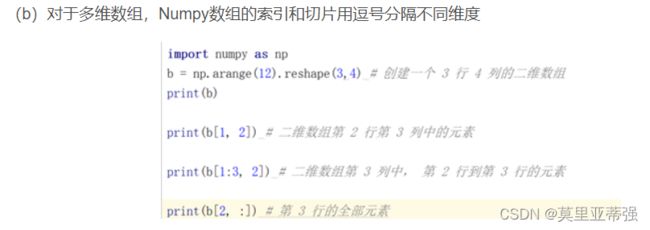
索引和切片:戳我
S[1:3]获取了从偏移为1的元素,到但是不包含偏移为3的元素
S[::-1]实际效果就是将序列进行反转(这是一个有用的技巧)
一些运算


random函数的介绍
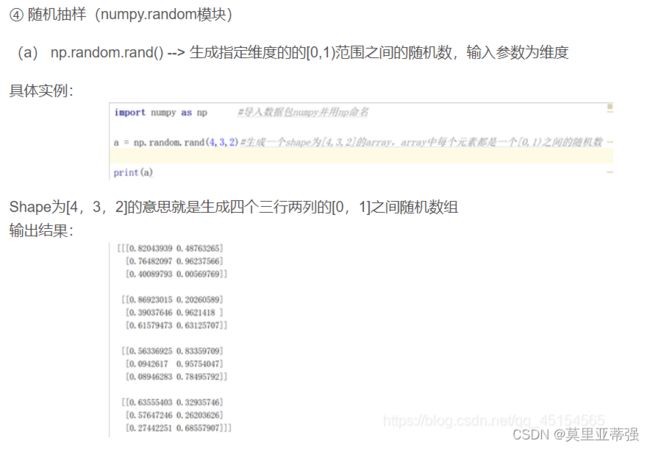
(b) np.random.randn() --> 生成指定维度的服从标准正态分布的随机数,输入参数为维度
(c) np.random.randint(low, high = None, size = None,dtype = ‘l’)–> 返回随机数或者随机数组成的array
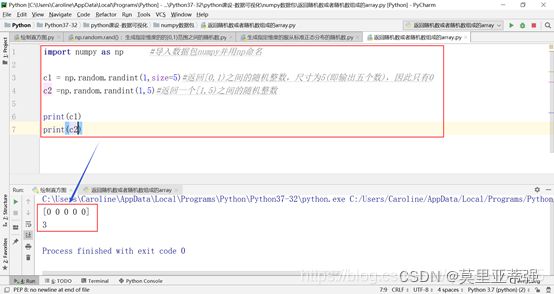
(d) np.random.random(size = (2,2))–>生成随机浮点数阵列
(e) np.random.choice(a, size = None, replace = True, p = None) --> 从给定数组a中随机选择,p可以指定a中每个元素被选择的概率
(f) np.random.seed() -->使随即数据可预测,对于同一个seed,生成的随机数相同
np.random.uniform()
np.random.normal()
3.3.1 生成数组的方法
1)生成0和1
np.zeros(shape)
np.ones(shape)
2)从现有数组中生成
np.array() np.copy() 深拷贝
np.asarray() 浅拷贝
会np.array就行了
3)生成固定范围的数组
np.linspace(0, 10, 100)
[0, 10] 等距离
np.arange(a, b, c)
range(a, b, c)
[a, b) c是步长
3.3.3 形状修改
ndarray.reshape(shape) 返回新的ndarray,原始数据没有改变
ndarray.resize(shape) 没有返回值,对原始的ndarray进行了修改
前面两种数据顺序其实都没有改变,只有下面这个改变了
ndarray.T 转置 行变成列,列变成行
3.3.4 类型修改
ndarray.astype(type)
ndarray序列化到本地,使用下面函数
序列化即将对象转化成字节
ndarray.tostring()
3.3.5 数组的去重
np.unique()
set()

布尔索引
![]()
[]里是布尔值,取布尔值为true的索引,本质上就是一个值为布尔值的n维数组
np.all和np.any的用处

np.where的用处
np.logical_and以及np.logical_or的用法

数组与数组的运算
**广播机制: 非常重要!**忘记了记得去搜
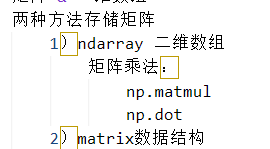
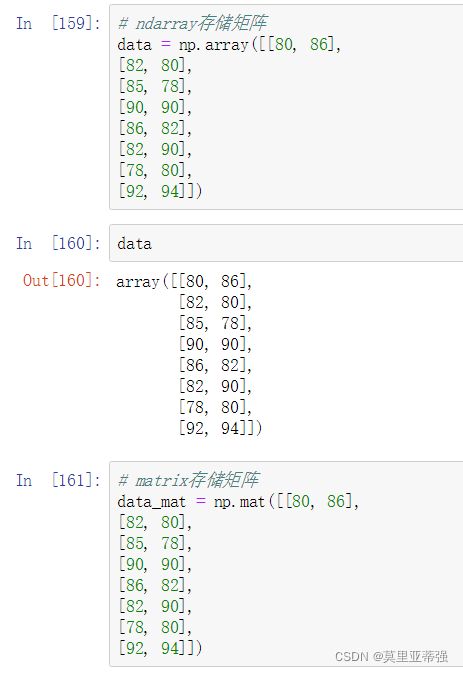
两种方法存储矩阵
合并,分割的函数
hstack水平合并
vstack竖直合并
split分割
Pandas
参考:戳我
(1)功能:
pandas 这个名称来源于panel data(面板数据),从而可见其要处理的数据是多维度的而非单维度。pandas
含有使数据清洗和分析工作变得更快更简单的数据结构与操作工具。pandas功能特性广泛,其包含的函数类型也众多,数据结构有Series与DataFrame,函数类型有索引函数、汇总函数、加载以及保存众多文件格式函数、与数据库交互函数、字符串处理函数、缺失数据处理函数、合并重塑轴向旋转表格型数据函数、简单的绘图函数、数据聚合(groupby)分组运算(apply)函数、透视表交叉表函数以及时间序列处理方面的各种函数。pandas可以读取较多类型的文件格式,从简单的txt、csv、json到excel,hdf5、pickle再到sas、sql、stata等等文件格式都有得以支持。在读取数据时,函数会使用到若干技术将数据转换成DataFrame格式,如索引、类型推断和数据转换、日期解析、迭代与不规整数据问题等。
(2)pandas的数据结构分为两种:
①Series -序列:储存任意类型的一维数组
②DataFrame -数据框:储存不同类型数据的二维数组
主要功能:(具体函数可以看上面的链接)
① Pandas 文件读写
② 生成数据表
③ 数据表信息查看
④ 数据表清洗
⑥ 数据输出
df的介绍
dataframe是带行索引列索引的二维数组
常用函数
添加行列索引
开头几行,结尾几行
修改索引
新索引的设置(什么意思要知道)
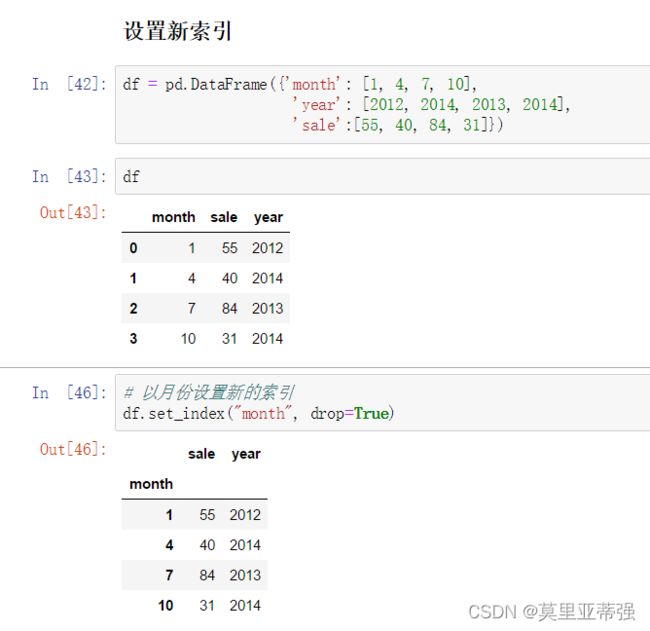
字典生成df
panel和multiIndex(以后要了再学学)
panel存储3维数组
可以看成储存df的一个容器,要输入其中一个维度才能看到一个二维数组
注:Pandas从版本0.20.0开始弃用panel,推荐的用于表示3D数据的方法是DataFrame上的MultiIndex方法
series
带索引的一维数组

基本数据操作
位置索引
- 直接索引,先列后行
=------------------------=
2)按名字索引
loc
3)按数字索引
iloc
4)组合索引(将来要过时)
ix
数字、名字
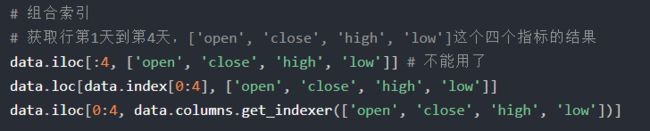
赋值操作
索引到位置之后就赋值就行了
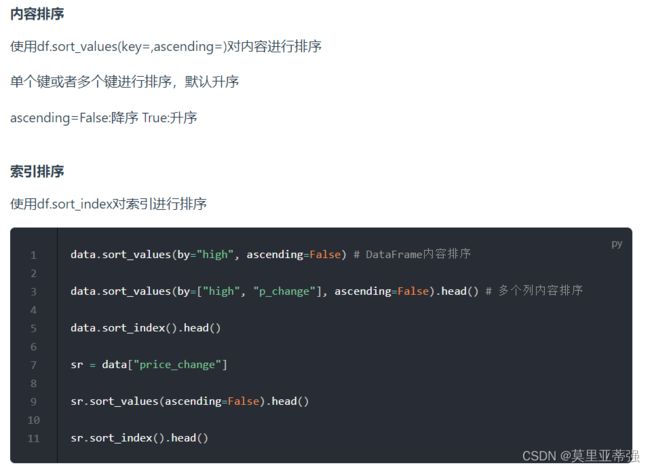
排序操作
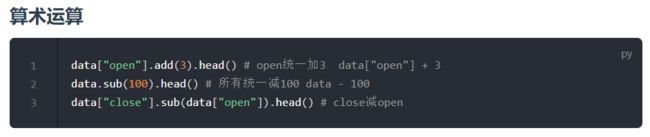
运算操作

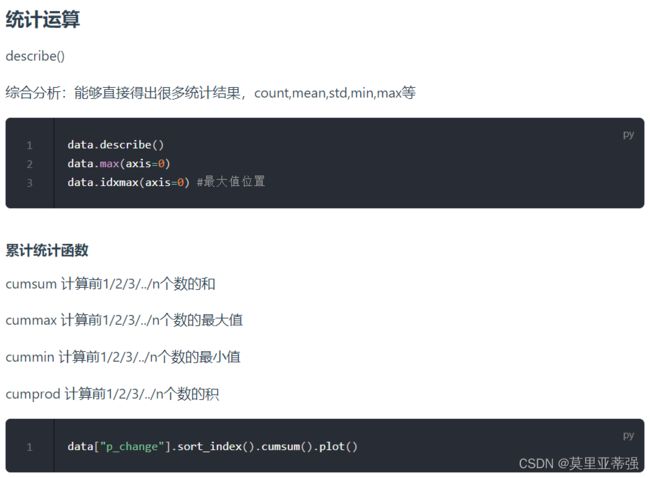
Pandas画图
pandas.DataFrame.plot
DataFrame.plot(x=None, y=None, kind=‘line’)
文件读取
csv:一个文本文件 hdf5:二进制文件
read_csv
重要参数: usecols, name
to_csv
重要参数: columns , index , mode , header
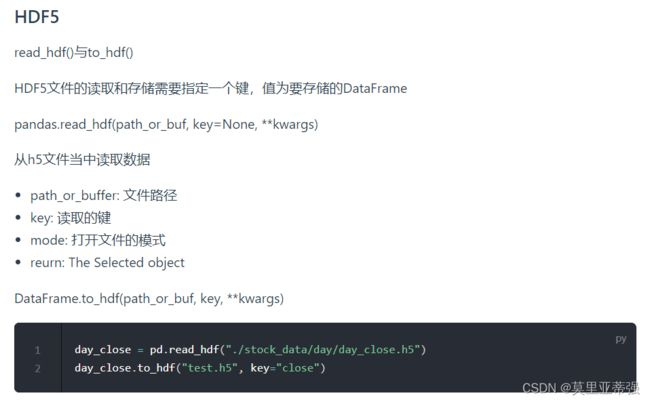
hdf储存的时候可以有多个键,多个键时就要参数里用key注明要读哪个键对应的df
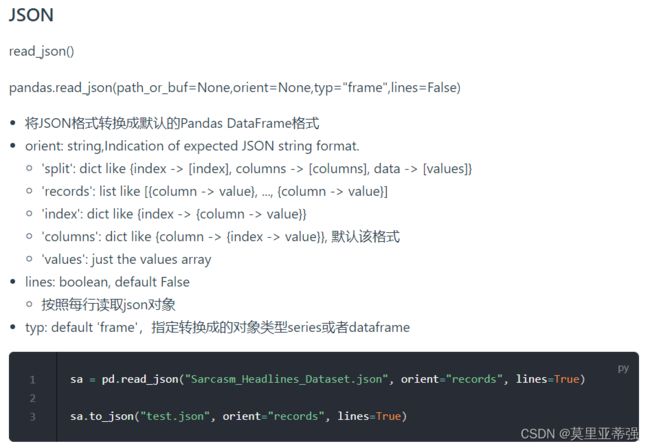
重要参数:
orient:就写records就行了
lines:是否按照每行读取JSON对象,默认是false

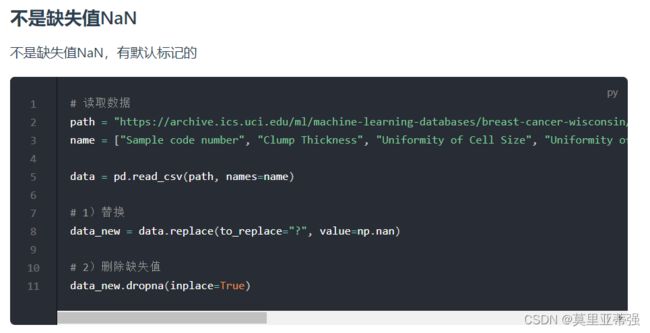
数据离散化(先略了)
合并
按方向
pd.concat([data1, data2], axis=1) axis:0为列索引;1为行索引
按索引
pd.merge(left, right, how=“inner”, on=[]) on:索引
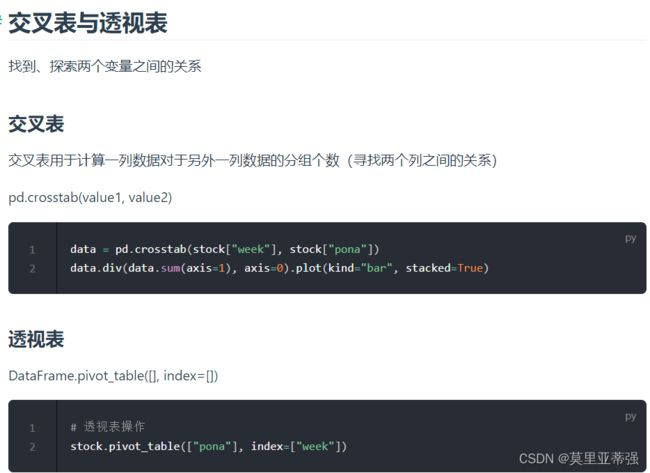
这个以后再研究
分组与聚合
分组与聚合通常是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况。
DataFrame.groupby(key, as_index=False) key:分组的列数据,可以多个
3、statistics包(也是2的链接)
(1)功能:
我们在统计分析和建模的过程中,大致可以分为数据获取和处理、数据分析和建模及预测、结果可视化这三个步骤。statsmodels是统计建模分析的核心工具包,其包括了几乎所有常见的各种回归模型、非参数模型和估计、时间序列分析和建模以及空间面板模型等,其功能是很强大的,使用也相当便捷。
(2)statistics中常用的分析方法即举例:
①mean(data)函数
mean(data) 函数用于计算一组数字的平均值,参数 data 可以是多种形式的,比如 int 型数组或 decimal 型数组等。
②harmonic_mean(data)函数(调和平均数)
③中位数函数median()、median_low()、median_high()、median_grouped()
⑤ pstdev()函数
pstdev()函数返回总体标准差。
⑥ pvariance()函数
pvariance()函数返回总体方差或二次矩。
⑦ mode()函数
mode()函数返回最常见数据或出现次数最多的数据。
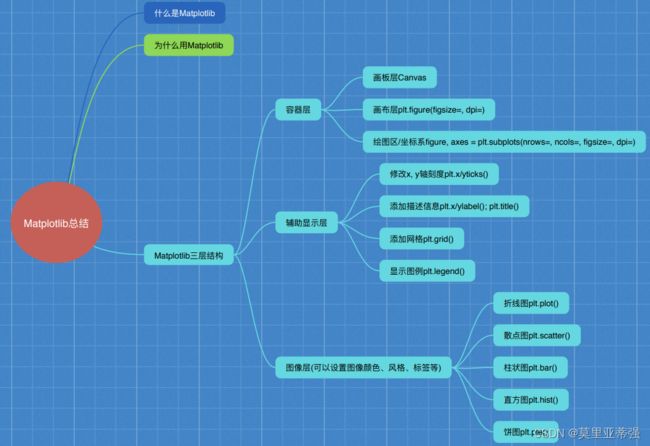
三、可视化工具matplotlib(好搜的)
参考:
黑马笔记
plt.figure()->创建一个画布
里面可以加一些 参数,如figuresize,dpi等等
dpi : dot per inch -> 清晰度
图像保存: plt.savefig
注意,要写在show函数之前,因为show之后会释放所有资源
for in语法等会搜
自定义x,y刻度范围
x,y轴描述信息,以及添加标题
plt.xticks(x[::5], x_label[::5])
x_label = [“11点{}分”.format(i) for i in x]
添加网格显示
显示图例(以及他的参数)
面向对象的画图方法以及多个子图

plot不仅可以画折线图,也可以画各种数学函数图像
其他图:
散点图
柱状图
直方图
饼图
总结: