校招面试数据库原理知识复习总结三之SQL语句
文章目录
- SQL语句知识总结
-
- 1. 数据库分页
- 2. 聚合函数
- 3.数据库表关联
- 4.sql查询表实现行转列
- 5. 防止sql注入
- 6. 面试题:WHERE和HAVING有什么区别?
- 7.视图
- 8. 存储过程
- 9. 触发器
- 10. 事务触发
SQL语句知识总结
1. 数据库分页
1.1 MySQL的分页语法:
在MySQL中,SELECT语句默认返回所有匹配的行,它们可能是指定表中的每个行。为了返回第一行或前几行,可使用LIMIT子句,以实现分页查询。
-- 在所有的查询结果中,返回前5行记录。
SELECT prod_name FROM products LIMIT 5;
-- 在所有的查询结果中,从第5行开始,返回5行记录。
SELECT prod_name FROM products LIMIT 5,5;
分页查询优化:
SELECT film.film_id,film.description
FROM sakila.film
INNER JOIN (
SELECT film_id FROM sakila.film ORDER BY title LIMIT 50,5
) AS lim USING(film_id);
这里的“延迟关联”将大大提升查询效率,它让MySQL扫描尽可能少的页面,获取需要访问的记录后再根据关联列回原表查询需要的所有列。这个技术也可以用于优化关联查询中的LIMIT子句。
1.2 分页查询按记录继续查询:
LIMIT和OFFSET的问题,其实是OFFSET的问题,它会导致MySQL扫描大量不需要的行然后再抛弃掉。如果可以使用书签记录上次取数的位置,那么下次就可以直接从该书签记录的位置开始扫描,这样就可以避免使用OFFSET。例如,若需要按照租赁记录做翻页,那么可以根据最新一条租赁记录向后追溯,这种做法可行是因为租赁记录的主键是单调增长的。首先使用下面的查询获得第一组结果:
SELECT * FROM sakila.rental ORDER BY rental_id DESC LIMIT 20;
假设上面的查询返回的是主键16049到16030的租赁记录,那么下一页查询就可以从16030这个点开始:
SELECT * FROM sakila.rental
WHERE rental_id < 16030 ORDER BY rental_id DESC LIMIT 20;
该技术的好处是无论翻页到多么后面,其性能都会很好。
2. 聚合函数
常用的聚合函数有COUNT()、AVG()、SUM()、MAX()、MIN(),下面以MySQL为例,说明这些函数的作用。
-
COUNT()函数:
COUNT()函数统计数据表中包含的记录行的总数,或者根据查询结果返回列中包含的数据行数,它有两种用法:
COUNT(*)计算表中总的行数,不管某列是否有数值或者为空值。
COUNT(字段名)计算指定列下总的行数,计算时将忽略空值的行。
COUNT()函数可以与GROUP BY一起使用来计算每个分组的总和。 -
AVG()函数():
AVG()函数通过计算返回的行数和每一行数据的和,求得指定列数据的平均值。
AVG()函数可以与GROUP BY一起使用,来计算每个分组的平均值。 -
SUM()函数:
SUM()是一个求总和的函数,返回指定列值的总和。
SUM()可以与GROUP BY一起使用,来计算每个分组的总和。 -
MAX()函数:
MAX()返回指定列中的最大值。
MAX()也可以和GROUP BY关键字一起使用,求每个分组中的最大值。
MAX()函数不仅适用于查找数值类型,也可应用于字符类型。 -
MIN()函数:
MIN()返回查询列中的最小值。
MIN()也可以和GROUP BY关键字一起使用,求出每个分组中的最小值。
MIN()函数与MAX()函数类似,不仅适用于查找数值类型,也可应用于字符类型。
2.1 聚合函数规则
-
having 必须和group by一起用, 且在group by后,
-
不允许使用双重聚合函数,可以用order by排序,用limit找到极值
-
where 先过滤再分组,where后不可用聚合函数过滤行信息
-
having先group by分组后,先分组,后过滤,可用聚合函数,过滤组(列)信息
-
使用顺序:
SELECT * (aS[别名])
FROM 表名
--where在前,过滤行信息
WHERE age > 10
--group by 在having前
GROUP BY score
HAVING SUM(store)>500
--排序DESC降序 ASC升序
ORDER BY id DESC
--分页从第10行开始,返回5行记录。
LIMIT 10,5
-
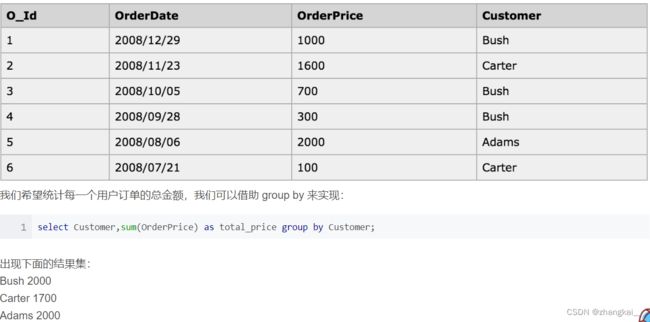
GROUP BY 列名
搜素列名为 cname的信息。
3.数据库表关联
表与表之间常用的关联方式有两种:内连接、外连接 。
内连接:
内连接通过INNER JOIN来实现,它将返回两张表中满足连接条件的数据,不满足条件的数据不会查询出来。
SELECT film.film_id,film.description
FROM sakila.film
INNER JOIN (
SELECT film_id FROM sakila.film ORDER BY title LIMIT 50,5
) AS lim USING(film_id);
外连接:
外连接通过OUTER JOIN来实现,它会返回两张表中满足连接条件的数据,同时返回不满足连接条件的数据。
外连接有两种形式:左外连接(LEFT OUTER JOIN)、右外连接(RIGHT OUTER JOIN)。
-
左外连接:可以简称为左连接(LEFT JOIN),它会返回左表中的所有记录和右表中满足连接条件的记录。
FROM 主表(LEFT JOIN 副表 ***) -
右外连接:可以简称为右连接(RIGHT JOIN),它会返回右表中的所有记录和左表中满足连接条
件的记录。FROM 副表(RIGHT JOIN 主表 ***)
除此之外,还有一种常见的连接方式:**等值连接。**这种连接是通过WHERE子句中的条件,将两张表连接在一起,它的实际效果等同于内连接。出于语义清晰的考虑,一般更建议使用内连接,而不是等值连接。
USING用法
正常表关联:
SELECT *
FROM 表1 (
INNER JOIN 表2
ON 表1.相同列=表2.相同列
)
USING,用来简化查询,不用手动选定相同列了
SELECT *
FROM 表1 (
INNER JOIN 表2
--不用再选定查询列
USING (相同列)
)
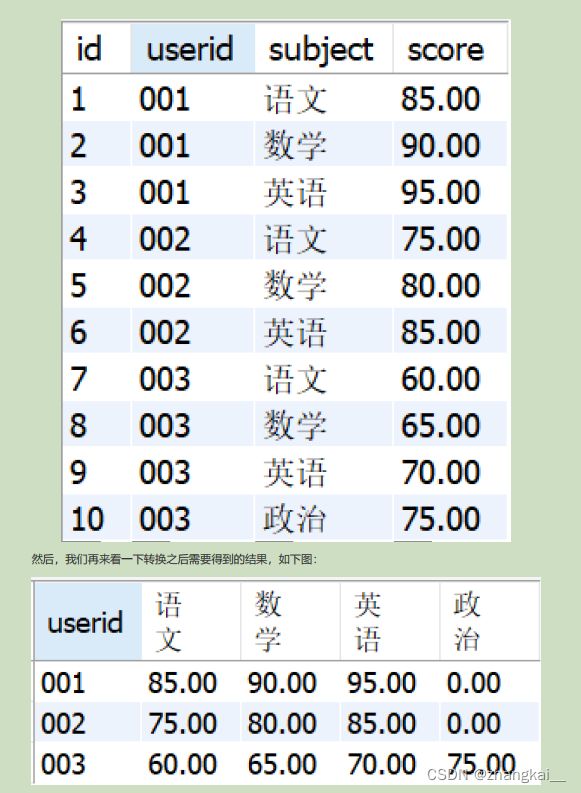
4.sql查询表实现行转列
-
使用 CASE…WHEN…THEN 语句实现行转列,参考如下代码:
SELECT userid, SUM(CASE `subject` WHEN '语文' THEN score ELSE 0 END) as '语文', SUM(CASE `subject` WHEN '数学' THEN score ELSE 0 END) as '数学', SUM(CASE `subject` WHEN '英语' THEN score ELSE 0 END) as '英语', SUM(CASE `subject` WHEN '政治' THEN score ELSE 0 END) as '政治' FROM tb_score --根据userid分组,将id相同的合并 GROUP BY userid注意,SUM() 是为了能够使用GROUP BY根据userid进行分组,因为每一个userid对应的subject="语文"的记录只有一条,所以SUM() 的值就等于对应那一条记录的score的值。假如userid =‘001’ and subject=‘语文’ 的记录有两条,则此时SUM() 的值将会是这两条记录的和,同理,使用Max()的值将会是这两条记录里面值最大的一个。但是正常情况下,一个user对应一个subject只有一个分数,因此可以使用SUM()、MAX()、MIN()、AVG()等聚合函数都可以达到行转列的效果 。
-
使用 IF() 函数实现行转列,参考如下代码:
SELECT userid, SUM(IF(`subject`='语文',score,0)) as '语文', SUM(IF(`subject`='数学',score,0)) as '数学', SUM(IF(`subject`='英语',score,0)) as '英语', SUM(IF(`subject`='政治',score,0)) as '政治' FROM tb_score GROUP BY userid注意, IF(subject=‘语文’,score,0) 作为条件,即对所有subject='语文’的记录的score字段进行SUM()、MAX()、MIN()、AVG()操作,如果score没有值则默认为0。
5. 防止sql注入
SQL注入的原理是将SQL代码伪装到输入参数中,传递到服务器解析并执行的一种攻击手法。也就是说,在一些对SERVER端发起的请求参数中植入一些SQL代码,SERVER端在执行SQL操作时,会拼接对应参数,同时也将一些SQL注入攻击的“SQL”拼接起来,导致会执行一些预期之外的操作。
举例:
我们的登录功能,其登录界面包括用户名和密码输入框以及提交按钮,登录时需要输入用户名和密码,然后提交假设正确的用户名和密码为ls和123456,输入正确的用户名和密码、提交,相当于调用了以下的SQL语句。
SELECT * FROM user WHERE username = 'ls' AND password = '123456'
SQL中会将#及–以后的字符串当做注释处理,如果我们使用 ’ or 1=1 # 作为用户名参数,那么服务端构建的SQL语句就如下:
select * from user where username='' or 1=1 #' and password='123456'
其实上面的SQL注入只是在参数层面做了些手脚,如果是引入了一些功能性的SQL那就更危险了,比如上面的登录功能,如果用户名使用这个 ’ or 1=1;delete * from users; # ,那么在";"之后相当于是另外一条新的SQL,这个SQL是删除全表,是非常危险的操作,因此SQL注入这种还是需要特别注意的。
解决sql注入
- 严格的参数校验
参数校验就没得说了,在一些不该有特殊字符的参数中提前进行特殊字符校验即可。 - SQL预编译
MySQL有预编译的功能,指的是在服务器启动时,MySQL Client把SQL语句的模板(变量采用占位符进行占位)发送给MySQL服务器,MySQL服务器对SQL语句的模板进行编译,编译之后根据语句的优化分析对相应的索引进行优化,在最终绑定参数时把相应的参数传送给MySQL服务器,直接进行执行,节省了SQL查询时间,以及MySQL服务器的资源,达到一次编译、多次执行的目的,除此之外,还可以防止SQL注入–>当将绑定的参数传到MySQL服务器,MySQL服务器对参数进行编译,即填充到相应的占位符的过程中,做了转义操作。我们常用的JDBC就有预编译功能,不仅提升性能,而且防止SQL注入。
6. 面试题:WHERE和HAVING有什么区别?
参考答案
- WHERE是一个约束声明,使用WHERE约束来自数据库的数据,WHERE是在结果返回之前起作用的,WHERE中不能使用聚合函数。
- HAVING是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作,在HAVING中可以使用聚合函数。另一方面,HAVING子句中不能使用除了分组字段和聚合函数之外的其他字段。从性能的角度来说,HAVING子句中如果使用了分组字段作为过滤条件,应该替换成WHERE子句。因为WHERE可以在执行分组操作和计算聚合函数之前过滤掉不需要的数据,性能会更好。
7.视图
视图是虚拟的表,本身不包含数据,也就不能对其进行索引操作。
对视图的操作和对普通表的操作一样。
-
视图具有如下好处:
简化复杂的 SQL 操作,比如复杂的连接;
只使用实际表的一部分数据;
通过只给用户访问视图的权限,保证数据的安全性;
更改数据格式和表示。
CREATE VIEW myview AS
SELECT Concat(col1, col2) AS concat_col, col3*col4 AS compute_col
FROM mytable
WHERE col5 = val;
8. 存储过程
存储过程可以看成是对一系列 SQL 操作的批处理。
-
使用存储过程的好处:
代码封装,保证了一定的安全性;
代码复用;
由于是预先编译,因此具有很高的性能。
命令行中创建存储过程需要自定义分隔符,因为命令行是以 ; 为结束符,而存储过程中也包含了分号,因此会错误把这部分分号当成是结束符,造成语法错误。
包含 in、out 和 inout 三种参数。
给变量赋值都需要用 select into 语句。
每次只能给一个变量赋值,不支持集合的操作。
9. 触发器
触发器会在某个表执行以下语句时而自动执行:DELETE、INSERT、UPDATE。
- DELETE 触发器包含一个名为 OLD 的虚拟表,并且是只读的。
- UPDATE 触发器包含一个名为 NEW 和一个名为 OLD 的虚拟表,其中 NEW 是可以被修改的,而 OLD 是只读的。
- MySQL 不允许在触发器中使用 CALL 语句,也就是不能调用存储过程。
触发器必须指定在语句执行之前还是之后自动执行,之前执行使用 BEFORE 关键字,之后执行使用 AFTER 关键字。BEFORE 用于数据验证和净化,AFTER 用于审计跟踪,将修改记录到另外一张表中。
INSERT 触发器包含一个名为 NEW 的虚拟表。
CREATE TRIGGER mytrigger AFTER INSERT ON mytable
FOR EACH ROW SELECT NEW.col into @result;
SELECT @result; -- 获取结果
10. 事务触发
MySQL 的事务提交默认是隐式提交,每执行一条语句就把这条语句当成一个事务然后进行提交。当出现 START TRANSACTION 语句时,会关闭隐式提交;当 COMMIT 或 ROLLBACK 语句执行后,事务会自动关闭,重新恢复隐式提交。
设置 autocommit 为 0 可以取消自动提交;autocommit 标记是针对每个连接而不是针对服务器的。
如果没有设置保留点,ROLLBACK 会回退到 START TRANSACTION 语句处;如果设置了保留点,并且在 ROLLBACK 中指定该保留点,则会回退到该保留点。
START TRANSACTION
// ...
SAVEPOINT delete1
// ...
ROLLBACK TO delete1
// ...
COMMIT