如何从零开始优雅整合SpringBoot框架与Kafka消息中间件
由于今年的项目基本都是B/S架构的分布式软件设计,因此被逼无奈只能开始自学JAVA WEB后端进行开发,后续会陆续总结一些技术文档,便于复现与归档。
自学教程参见B站尚硅谷大数据生态圈开发课程,https://www.bilibili.com/video/BV17t411W7wZ
真就B站大学,B站流批!
优雅整合SpringBoot框架与Kafka消息中间件
-
-
- 一、Kafka虚拟机环境搭建(非集群)
-
- 1、分布式服务管理框架——Zookeeper入门
- 2、Zookeeper环境搭建与参数配置
-
- 2.1、下载Zookeeper安装包
- 2.2、安装部署与相关功能命令
- 3、消息中间件——Kafka入门
- 4、Kafka环境搭建与参数配置
-
- 4.1、下载Kafka安装包
- 4.2、安装部署与相关功能命令
- 搭建过程问题记录 Q01
- 二、SpringBoot集成kafka全面实战
-
- 1、SpringBoot项目配置
- 2、功能代码实现
-
- 2.1、Kafka Restful
- 2.2、Kafka 生产者
-
- 2.2.1、带回调函数的生产者方法
- 2.2.2、自定义分区器方法
- 2.3、Kafka 消费者
-
- 2.3.1、指定topic、partition、offset消费
- 2.3.2、批量消费
- 2.3.3、异常处理器
- 2.3.4、消息转发
- 2.3.5、消息过滤器
-
其实一开始上手自学的时候,学习的是大数据生态圈开发课程,面向项目中高吞吐数据量、服务器集群架构、云平台等等需求,但当前开发进度下还没有涉及大数据服务端集群设计,因此本篇文档仅针对单机服务端的SpringBoot框架与Kafka消息中间件的整合思路进行总结。
安利博主自学时参考的培训视频:
大数据技术生态圈——
Hadoop2.x:尚硅谷Hadoop 2.x教程(hadoop框架精讲)
Hadoop3.x:尚硅谷丨大数据Hadoop 3.x(2021全新升级/部署+源码+实战)
Spark:尚硅谷2021迎新版大数据Spark从入门到精通
Flink:尚硅谷2021最新Java版Flink(武老师清华硕士,原IBM-CDL负责人)
Zookeeper:尚硅谷Zookeeper教程(zookeeper框架精讲)
Hive:尚硅谷2021版Hive教程(基于hive3.1.2)
HA:尚硅谷HA教程(大数据ha快速入门)
Flume:尚硅谷Flume教程(flume框架快速入门)
Kafka:尚硅谷Kafka教程(kafka框架快速入门)
HBase:尚硅谷HBase教程(hbase框架快速入门)
Sqoop:尚硅谷Sqoop教程(sqoop大数据开发标配)
Azkaban:尚硅谷Azkaban教程(azkaban大数据快速入门)
Oozie:尚硅谷Oozie教程(oozie大数据开发标配)
Scala:尚硅谷Scala教程(大数据开发标配)
一、Kafka虚拟机环境搭建(非集群)
1、分布式服务管理框架——Zookeeper入门
官网首页:
https://zookeeper.apache.org/
Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。
具体讲解如下:



Zookeeper应用场景:
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。具体讲解如下:
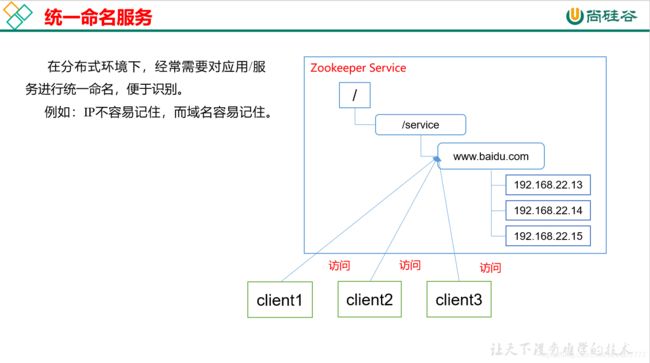




2、Zookeeper环境搭建与参数配置
2.1、下载Zookeeper安装包



2.2、安装部署与相关功能命令
由于在实际应用场景下,服务端一般会和终端分离,即服务端搭建在机房,因此在学习的时候可以使用虚拟机进行模拟远程操作,这里如何安装VM以及安装Linux系统,包括如何安装JDK不再赘述。
(1)安装前准备工作:
a. 安装JDK;
b. 使用Xftp远程拷贝Zookeeper安装包到虚拟机Linux系统下;
c. 解压到指定目录:
[atguigu@hadoop102 software]$ tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/
(2)配置修改:
a. 将/opt/module/zookeeper-3.4.10/conf这个路径下的zoo_sample.cfg修改为zoo.cfg:
[atguigu@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg
b. 打开zoo.cfg文件,修改dataDir路径:
[atguigu@hadoop102 zookeeper-3.4.10]$ vim zoo.cfg
修改如下内容:
dataDir=/opt/module/zookeeper-3.4.10/zkData
c. 在/opt/module/zookeeper-3.4.10/这个目录上创建zkData文件夹:
[atguigu@hadoop102 zookeeper-3.4.10]$ mkdir zkData
(3)相关功能命令:
a. 启动Zookeeper:
[atguigu@hadoop102 zookeeper-3.4.10]$ bin/zkServer.sh start
b. 查看进程是否启动:
[atguigu@hadoop102 zookeeper-3.4.10]$ jps
如正常启动,会显示如下:
4020 Jps
4001 QuorumPeerMain
c. 查看状态:
[atguigu@hadoop102 zookeeper-3.4.10]$ bin/zkServer.sh status
如正常启动,会显示如下:
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: standalone
d. 启动客户端:
[atguigu@hadoop102 zookeeper-3.4.10]$ bin/zkCli.sh
e. 退出客户端:
[zk: localhost:2181(CONNECTED) 0] quit
f. 停止Zookeeper:
[atguigu@hadoop102 zookeeper-3.4.10]$ bin/zkServer.sh stop
(4)Zookeeper中配置文件zoo.cfg中参数含义解读如下:
1.tickTime =2000:通信心跳数
Zookeeper服务器与客户端心跳时间,单位毫秒。
Zookeeper使用的基本时间,服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳,时间单位为毫秒。
它用于心跳机制,并且设置最小的session超时时间为两倍心跳时间。(session的最小超时时间是2*tickTime)
2.initLimit =10:LF初始通信时限
集群中的Follower跟随者服务器与Leader领导者服务器之间初始连接时能容忍的最多心跳数(tickTime的数量),用它来限定集群中的Zookeeper服务器连接到Leader的时限。
3.syncLimit =5:LF同步通信时限
集群中Leader与Follower之间的最大响应时间单位,假如响应超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer。
4.dataDir:数据文件目录+数据持久化路径
主要用于保存Zookeeper中的数据。
5.clientPort =2181:客户端连接端口
监听客户端连接的端口。
3、消息中间件——Kafka入门
Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
使用消息队列的好处:
1)解耦:
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2)可恢复性:
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
3)缓冲:
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
4)灵活性 & 峰值处理能力:
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。
如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5)异步通信:
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
Kafk基础架构:

1)Producer :消息生产者,就是向 kafka broker 发消息的客户端;
2)Consumer :消息消费者,向 kafka broker 取消息的客户端;
3)Consumer Group (CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
4)Broker :一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker可以容纳多个 topic。
5)Topic :可以理解为一个队列,生产者和消费者面向的都是一个 topic;
6)Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列;
7)Replica:副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
8)Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 leader。
9)Follower:每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据的同步。leader 发生故障时,某个 follower 会成为新的 follower。
4、Kafka环境搭建与参数配置
4.1、下载Kafka安装包
官网首页:
http://kafka.apache.org/downloads.html

4.2、安装部署与相关功能命令
1)解压安装包:
[atguigu@hadoop102 software]$ tar -zxvf kafka_2.11-0.11.0.0.tgz -C /opt/module/
2)修改解压后的文件名称:
[atguigu@hadoop102 module]$ mv kafka_2.11-0.11.0.0/ kafka
3)在/opt/module/kafka 目录下创建 logs 文件夹:
[atguigu@hadoop102 kafka]$ mkdir logs
4)修改配置文件:
[atguigu@hadoop102 kafka]$ cd config/
[atguigu@hadoop102 config]$ vi server.properties
输入以下内容:
#broker 的全局唯一编号,不能重复
broker.id=0
#删除 topic 功能使能
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘 IO 的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka 运行日志存放的路径
log.dirs=/opt/module/kafka/logs
#topic 在当前 broker 上的分区个数
num.partitions=1
#用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接 Zookeeper 集群地址(单机则只有一个)
zookeeper.connect=192.168.0.151:2181
5)配置环境变量:
[atguigu@hadoop102 module]$ sudo vi /etc/profile
加入如下内容:
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
使命令立即生效:
[atguigu@hadoop102 module]$ source /etc/profile
Kafka相关功能命令:
1)启动Kafka服务:
[atguigu@hadoop102 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
2)关闭Kafka服务:
[atguigu@hadoop102 kafka]$ bin/kafka-server-stop.sh stop
3)查看当前服务器中的所有 topic:
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper 192.168.0.151:2181 --list
4)创建 topic:
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper 192.168.0.151:2181 --create --replication-factor 3 --partitions 1 --topic first
选项说明:
–topic 定义 topic 名
–replication-factor 定义副本数
–partitions 定义分区数
5)删除 topic:
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper 192.168.0.151:2181 --delete --topic first
需要 server.properties 中设置 delete.topic.enable=true 否则只是标记删除。
6)发送消息:
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh --broker-list 192.168.0.151:9092 --topic first
7)消费消息:
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh \ --zookeeper 192.168.0.151:2181 --topic first
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh \ --bootstrap-server 192.168.0.151:9092 --topic first
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh \ --bootstrap-server 192.168.0.151:9092 --from-beginning --topic first
–from-beginning:会把主题中以往所有的数据都读取出来。
8)查看某个 Topic 的详情:
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper 192.168.0.151:2181 --describe --topic first
9)修改分区数:
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper 192.168.0.151:2181 --alter --topic first --partitions 6
搭建过程问题记录 Q01
zookeeper 集群或单点启动没有问题,集群状态也正常,但是启动kafka 报这个错误:
Timed out waiting for connection while in state: CONNECTING (连接超时)
1.关闭防火墙
systemctl status firewalld.service ##查看防火墙状态
systemctl stop firewalld.service
systemctl disable firewalld.service ##禁止防火墙开机启动
2.修改 kafka 配置连接超时间为60000毫秒。
zookeeper.connection.timeout.ms=60000
二、SpringBoot集成kafka全面实战
到此,虚拟机里的Kafka环境已配置完毕,后面开始Spring Boot项目整合。
1、SpringBoot项目配置
在项目中连接kafka,因为是外网,首先要开放kafka配置文件中的如下配置(其中IP为虚拟机本机IP):
[atguigu@hadoop102 kafka]$ cd config/
[atguigu@hadoop102 config]$ vi server.properties
添加如下内容:
advertised.listeners=PLAINTEXT://192.168.0.151:9092
之后,我们先创建两个topic:topic1、topic2,其分区和副本数都设置为2,用来测试。当然我们也可以不手动创建topic,在执行代码kafkaTemplate.send("topic1", normalMessage)发送消息时,kafka会帮我们自动完成topic的创建工作,但这种情况下创建的topic默认只有一个分区,分区也没有副本。
所以,我们可以在项目中新建一个配置类专门用来初始化topic,如下,
@Configuration
public class KafkaInitialConfiguration {
// 创建一个名为xxx的Topic并设置分区数为1,分区副本数为1 即想让生产者发送消息的分区名称
@Bean
public NewTopic initialTopic() {
return new NewTopic("initial_topic", 0, (short) 0);
}
// 如果要修改分区数,只需修改配置值重启项目即可
// 修改分区数并不会导致数据的丢失,但是分区数只能增大不能减小
@Bean
public NewTopic updateTopic() {
return new NewTopic("initial_topic", 1, (short) 1);
}
}
之后即可新建SpringBoot项目,
① 引入pom依赖:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.3.7.RELEASE</version>
</dependency>
注意这里的惊天大坑,我们在使用 springboot集成spring-kafka的时候需要注意两者之间的版本对应关系,否则可能会因为版本不兼容导致出现错误。实际上可以直接通过官方网址来查看它们之间的关系,地址如下:
https://spring.io/projects/spring-kafka#overview

我这里的SpringBoot项目版本为2.2.6,然而我尝试了2.4.x的Kafka依旧会出现某某类不存在的版本不兼容问题,最后尝试了2.3.7完美解决…
<spring.version>5.2.5.RELEASE</spring.version>
<spring-boot.version>2.2.6.RELEASE</spring-boot.version>
② application.propertise配置(本文用到的配置项这里全列了出来):
###########【Kafka集群】###########
spring.kafka.bootstrap-servers=192.168.171.128:9092
###########【初始化生产者配置】###########
# 重试次数
spring.kafka.producer.retries=0
# 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
spring.kafka.producer.acks=1
# 批量大小
spring.kafka.producer.batch-size=16384
# 提交延时
spring.kafka.producer.properties.linger.ms=0
# 当生产端积累的消息达到batch-size或接收到消息linger.ms后,生产者就会将消息提交给kafka
# linger.ms为0表示每接收到一条消息就提交给kafka,这时候batch-size其实就没用了
# 生产端缓冲区大小
spring.kafka.producer.buffer-memory = 33554432
# Kafka提供的序列化和反序列化类
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# 自定义分区器
# spring.kafka.producer.properties.partitioner.class=com.felix.kafka.producer.CustomizePartitioner
###########【初始化消费者配置】###########
# 默认的消费组ID
spring.kafka.consumer.properties.group.id=defaultConsumerGroup
# 是否自动提交offset
spring.kafka.consumer.enable-auto-commit=true
# 提交offset延时(接收到消息后多久提交offset)
spring.kafka.consumer.auto.commit.interval.ms=1000
# 当kafka中没有初始offset或offset超出范围时将自动重置offset
# earliest:重置为分区中最小的offset;
# latest:重置为分区中最新的offset(消费分区中新产生的数据);
# none:只要有一个分区不存在已提交的offset,就抛出异常;
spring.kafka.consumer.auto-offset-reset=latest
# 消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作)
spring.kafka.consumer.properties.session.timeout.ms=120000
# 消费请求超时时间
spring.kafka.consumer.properties.request.timeout.ms=180000
# Kafka提供的序列化和反序列化类
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
# 消费端监听的topic不存在时,项目启动会报错(关掉)
spring.kafka.listener.missing-topics-fatal=false
# 设置批量消费
spring.kafka.listener.type=batch
# 批量消费每次最多消费多少条消息
spring.kafka.consumer.max-poll-records=50
2、功能代码实现
项目源码已上传资源,欢迎下载运行,https://download.csdn.net/download/nannan7777/16139759
项目整体结构如下所示:

2.1、Kafka Restful
先写一个简单的GET方法的Kafka生产者服务:
创建一个KafkaCommonProducer类,添加一个简单生产者的sendMessage()函数:
@Component
public class KafkaCommonProducer {
@Autowired
private KafkaTemplate<String, String> kafkatemplate;
//简单 发送消息
public void sendMessage(String kafkaMessage) {
this.kafkatemplate.send("topic1", kafkaMessage);
}
}
之后创建一个KafkaController类,添加GET方法的Restful服务:
@RestController
@RequestMapping(value = "/kafka")
public class KafkaController {
@Autowired
private KafkaCommonProducer kafkaProducer;
@RequestMapping(value = "/message", method = RequestMethod.GET)
public String sendKafkaMessage(String Message){
this.kafkaProducer.sendMessage(Message);
return Message;
}
}
最后写一个Kafka监听即简单消费者功能:
@Component
public class KafkaConsumer {
// 消费监听
@KafkaListener(topics = {"topic1"})
public void onMessage1(ConsumerRecord<String, String> record){
// 消费的哪个topic、partition的消息,打印出消息内容
System.out.println("简单消费:"+record.topic()+"-"+record.partition()+"-"+record.value());
}
}
添加单元测试代码进行上述代码模块功能测试,运行测试类SpringkafkaApplicationTests:
@RunWith(SpringRunner.class)
@SpringBootTest
public class KafkaTest {
@Autowired
private KafkaCommonProducer producer;
@Test
public void contextLoads() throws InterruptedException {
producer.sendMessage("It's beautiful");
Thread.sleep(5000);
}
}
单元测试结果如下:

Restful服务可使用Postman进行测试,这里不再赘述。
2.2、Kafka 生产者
2.2.1、带回调函数的生产者方法
kafkaTemplate提供了一个回调方法addCallback,我们可以在回调方法中监控消息是否发送成功,或失败时做补偿处理,写法如下:
//带回调函数 发送消息
public void sendMessage2(String callbackMessage) {
kafkatemplate.send("topic1", callbackMessage).addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable ex) {
System.out.println("发送消息失败:"+ex.getMessage());
}
@Override
public void onSuccess(SendResult<String, String> result) {
System.out.println("发送消息成功:" + result.getRecordMetadata().topic() + "-"
+ result.getRecordMetadata().partition() + "-" + result.getRecordMetadata().offset());
}
});
}
2.2.2、自定义分区器方法
Kafka中每个Topic被划分为多个分区,那么生产者将消息发送到Topic 时,具体追加到哪个分区呢?这就是所谓的分区策略,Kafka 提供了默认的分区策略,同时它也支持自定义分区策略。其路由机制为:
① 若发送消息时指定了分区(即自定义分区策略),则直接将消息append到指定分区;
② 若发送消息时未指定Partition,但指定了 Key (Kafka允许为每条消息设置一个Key ),则对Key 值进行hash计算,根据计算结果路由到指定分区,这种情况下可以保证同一个 Key 的所有消息都进入到相同的分区;
③ Partition和 Key 都未指定,则使用Kafka默认的分区策略,轮询选出一个Partition;
※ 这里可以自定义一个分区策略,将消息发送到自己指定的Partition,首先新建一个分区器类实现Partitioner接口,重写方法,其中Partition方法的返回值就表示将消息发送到几号分区:
public class CustomizePartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 自定义分区规则(这里假设全部发到0号分区)
// ......
return 0;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
在application.propertise中配置自定义分区器,配置的值就是分区器类的全路径名:
# 自定义分区器
spring.kafka.producer.properties.partitioner.class=com.felix.kafka.producer.CustomizePartitioner
2.3、Kafka 消费者
2.3.1、指定topic、partition、offset消费
前面在监听消费topic1的时候,监听的是topic1上所有的消息,如果想指定topic、指定partition、指定offset来消费呢?也很简单,@KafkaListener注解已全部为我们提供相关方法:
/**
* @Title 指定topic、partition、offset消费
* @Description 同时监听topic1和topic2,监听topic1的0号分区、topic2的 "0号和1号" 分区,指向1号分区的offset初始值为8
* @Author Rina
* @Date 2020/3/26 13:38
* @Param [record]
* @return void
**/
@KafkaListener(id = "consumer1",groupId = "felix-group",topicPartitions = {
@TopicPartition(topic = "topic1", partitions = { "0" }),
@TopicPartition(topic = "topic2", partitions = "0", partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "8"))
})
public void onMessage(ConsumerRecord<?, ?> record) {
System.out.println("topic:"+record.topic()+"|partition:"+record.partition()+"|offset:"+record.offset()+"|value:"+record.value());
}
属性解释:
① id:消费者ID;
② groupId:消费组ID;
③ topics:监听的topic,可监听多个;
④ topicPartitions:可配置更加详细的监听信息,可指定topic、parition、offset监听。
上面onMessage2监听的含义:监听topic1的0号分区,同时监听topic2的0号分区和topic2的1号分区里面offset从8开始的消息。
注意:topics和topicPartitions不能同时使用。
2.3.2、批量消费
设置application.prpertise开启批量消费即可:
# 设置批量消费
spring.kafka.listener.type=batch
# 批量消费每次最多消费多少条消息
spring.kafka.consumer.max-poll-records=50
接收消息时用List来接收,监听代码如下:
@KafkaListener(id = "consumer2",groupId = "felix-group", topics = "topic1")
public void onMessage(List<ConsumerRecord<?, ?>> records) {
System.out.println(">>>批量消费一次,records.size()="+records.size());
for (ConsumerRecord<?, ?> record : records) {
System.out.println(record.value());
}
}
2.3.3、异常处理器
通过异常处理器,可以处理consumer在消费时发生的异常。
新建一个 ConsumerAwareListenerErrorHandler 类型的异常处理方法,用@Bean注入,BeanName默认就是方法名,然后将这个异常处理器的BeanName放到@KafkaListener注解的errorHandler属性里面,当监听抛出异常的时候,则会自动调用异常处理器:
// 新建一个异常处理器,用@Bean注入
@Bean
public ConsumerAwareListenerErrorHandler consumerAwareErrorHandler() {
return (message, exception, consumer) -> {
System.out.println("消费异常:"+message.getPayload());
return null;
};
}
// 批量消费,异常处理器的message.getPayload()也可以拿到各条消息的信息
@KafkaListener(topics = "topic1",errorHandler="consumerAwareErrorHandler")
public void onMessage(List<ConsumerRecord<String, String>> records) throws Exception {
for (ConsumerRecord<String, String> record : records) {
System.out.println("消费一次..." + record.value());
//throw new Exception("模拟异常"); //在某条件下可以自动抛出异常信息
}
}
2.3.4、消息转发
在实际开发中可能有这样的需求:应用A从TopicA获取到消息,经过处理后转发到TopicB,再由应用B监听处理消息,即一个应用处理完成后将该消息转发至其他应用,完成消息的转发。
在SpringBoot集成Kafka实现消息的转发也很简单,只需要通过一个@SendTo注解,被注解方法的return值即转发的消息内容,如下,
/**
* @Title 消息转发
* @Description 从topic1接收到的消息经过处理后转发到topic2
* @Param [record]
* @return void
**/
@KafkaListener(topics = {"topic1"})
@SendTo("topic2")
public String onMessage(ConsumerRecord<?, ?> record) {
return record.value()+"-forward message";
2.3.5、消息过滤器
消息过滤器可以在消息抵达consumer之前被拦截,在实际应用中,可以根据自己的业务逻辑,筛选出需要的信息再交由KafkaListener处理,不需要的消息则过滤掉。
配置消息过滤只需要为 监听器工厂 配置一个RecordFilterStrategy(消息过滤策略),返回true的时候消息将会被抛弃,返回false时,消息能正常抵达监听容器。
例如实现一个"过滤奇数、接收偶数"的过滤策略:
@Component
public class KafkaConsumer {
@Autowired
ConsumerFactory consumerFactory;
// 消息过滤器
@Bean
public ConcurrentKafkaListenerContainerFactory filterContainerFactory() {
ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory();
factory.setConsumerFactory(consumerFactory);
// 被过滤的消息将被丢弃
factory.setAckDiscarded(true);
// 消息过滤策略
factory.setRecordFilterStrategy(consumerRecord -> {
if (Integer.parseInt(consumerRecord.value().toString()) % 2 == 0) {
return false;
}
//返回true消息则被过滤
return true;
});
return factory;
}
// 消息过滤监听
@KafkaListener(topics = {"topic1"},containerFactory = "filterContainerFactory")
public void onMessage(ConsumerRecord<?, ?> record) {
System.out.println(record.value());
}
}
至此,SpringBoot框架与Kafka消息中间件已整合完毕,也实现了部分Kafka基础功能,可以根据应用场景与相关需求深入与详细开发啦!
————————————————————————————————
家猫离家出走后伤心欲绝的乔木小姐
记于2021年03月26日