基于keras实现双向GRU的中文情感分析
基于keras实现双向GRU的中文情感分析
NLP作为机器学习三大方向之一,个人认为,情感分析也是自然语言处理中也是非常重要的,当然很多人觉得情感分析比较麻烦一些的,中文的情感分析更是麻烦,因为存在很多问题,评论数据有没有整体倾斜,该考虑多少个常用词,该取多少长度(不够填充)
情感分析常用的方法
1、SVM支持向量机
2、贝叶斯
3、逻辑回归
4、神经网络(LSTM,CNN,GRU)
等等还有多种方法
今天我们来尝试使用基于keras实现双向GRU的实例
情感分析步骤
1、导入原始数据,原始label (0/1)
2、清洗数据(正则),剔除符号标点
3、jieba分词
4、构建词典,将词替换整数 索引
5、将整数索引向量化
6、模型的构建
7、训练模型
8、保存模型并预测
导入数据集
*
数据集使用微博数据集约10w条正负评论
数据清洗,模型设计
通过清洗分词后,最大长度(一行数据词数)150,最小长度为3平均长度为26.6,我们取30阶段/填充,有必要时计算词汇长度分布情况,使用Tokenizer构建词典,并用整数索引替换,使用embedding层学习词嵌入(向量化),使用双向GRU网络,保存我们的词典和模型用来预测
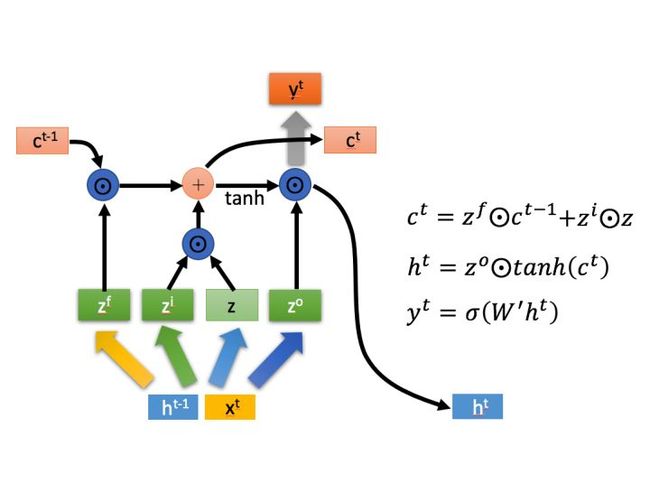
GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。
从LSTM的介绍可以知道,一个时间 t 要计算的很多,三个门/权重向量 z,完了还要计算两种信息:全局的和局部的,计算量非常大。基于此,诞生了GRU,它跟LSTM有相当的效果,但是比LSTM的计算更简单,更节省时间和算力。
//train.py
import re
import pandas as pd
import jieba
from keras.layers import Dense,Bidirectional,Embedding,LSTM,GRU
import matplotlib.pyplot as plt
from keras_preprocessing.sequence import pad_sequences
from keras import Sequential
from sklearn.model_selection import train_test_split
import numpy as np
import pickle
from keras_preprocessing.text import Tokenizer
import tensorflow as tf
from keras.optimizers import SGD, RMSprop
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
# pandas读取数据
df = pd.read_csv('weibo_senti_100k.csv',encoding='utf-8')
# 划分data与label
data = df['review']
label = df['label']
# 清洗数据,正则
def clear(text):
r3 = "[.!//_,$&%^*()<>+\"'?@#-|:~{}]+|[——!\s\\\\,;。=?、:“”‘’《》【】¥……()]+"
result=re.sub(pattern=r3,repl='',string=text)
return result
df['words'] = data.apply(lambda x: clear(str(x)))
# print(df['words'])
# 分词
data = df['words'].apply(lambda x: list(jieba.cut(x)))
data = data.tolist()
# 构建词典,将每条数据的词替换成索引
t1 = Tokenizer(num_words=10000)
t1.fit_on_texts(data)
# 将文本替换索引
sequences = t1.texts_to_sequences(data)
word_index = t1.word_index
data = pad_sequences(sequences, maxlen=30) # 对整型序列进行填充(截断),只取前30个单词
label = np.asarray(label)
print(type(data))
# 保存词典
with open('tokenizer.pickle', 'wb') as handle:
pickle.dump(t1, handle, protocol=pickle.HIGHEST_PROTOCOL)
# 拆分数据集
train_x,test_x,train_y,test_y = train_test_split(data,label,test_size=0.3,random_state=5)
print(type(train_x))
print(train_x)
# # 将序列反转
train_x = [i[::-1] for i in train_x]
test_x = [i[::-1] for i in test_x]
# 填充序列,并将数据转为numpy.ndarray(多维度数组)
max_len=30
train_x = pad_sequences(train_x, maxlen=max_len)
test_x = pad_sequences(test_x, maxlen=max_len)
print(train_x.shape)
print(type(train_x))
# 模型设计
model = Sequential()
# 使用embedding层学习词嵌入
model.add(Embedding(input_dim=10000, output_dim=64,))
# 双向GRU
model.add(Bidirectional(GRU(units=64)))
model.add(Dense(1, activation="sigmoid"))
model.summary()
# 模型的编译
model.compile(optimizer=RMSprop(), loss="binary_crossentropy", metrics=["accuracy"])
# 训练模型
his = model.fit(x=train_x, y=train_y, batch_size=128, epochs=2, validation_data=(test_x,test_y),verbose=0)
d1=his.history
est_loss, test_acc = model.evaluate(test_x, test_y, verbose=2)
print('Test accuracy:', test_acc)
# 训练数据绘图
plt.rcParams['font.sans-serif']=['SimHei']
# plt.ylim(0.5,1)
plt.plot(d1.get("val_accuracy"),color="green", label="val_acc")
plt.plot(d1.get("accuracy"), color="red", label="acc")
plt.legend()
plt.show()
model.save('weibo_senti.h5')
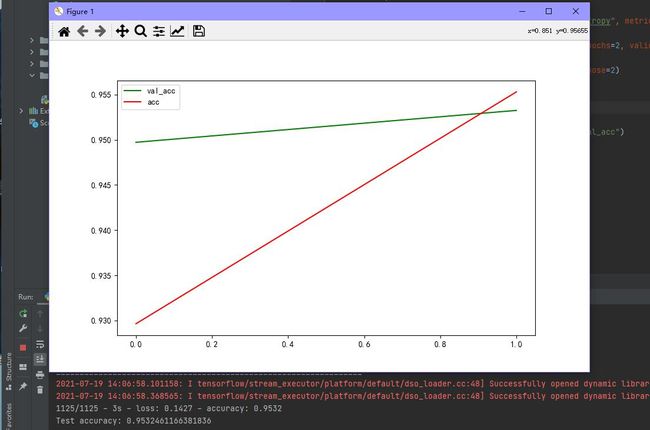
验证精度达到0.95
模型预测
//test.py
import pickle
import re
import jieba
from keras.models import load_model
import numpy as np
from keras_preprocessing.sequence import pad_sequences
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
class SentimentAnalysis():
def __init__(self):
pass
# 清洗数据,正则
def clear(self,text):
r3 = "[.,!//_,$&%^*()<>+\"'?@#-|:~{}]+|[——!\s\\\\,;。=?、:“”‘’《》【】¥……()]+"
result=re.sub(pattern=r3,repl='',string=text)
return result
def data_cut(self,data):
# 分词
for i in range(len(data)):
data[i] = self.clear(data[i])
data[i] = list(jieba.cut(data[i]))
# print(data[i])
return data
def tokenize_load(self, data):
# 构建词典,将每条数据的词替换成索引
with open('tokenizer.pickle', 'rb') as handle:
t1 = pickle.load(handle)
sequences = t1.texts_to_sequences(self.data_cut(data))
# # 序列反转
# print(sequences)
# data = [i[::-1] for i in sequences]
# # 填充序列,并将数据转为numpy.ndarray
max_len = 30
data = pad_sequences(sequences,maxlen=max_len)
return data
def modeload(self):
# 模型加载
model = load_model("weibo_senti.h5")
# model.summary()
np.set_printoptions(suppress=True)
return model
def res(self,data):
# 预测
print("预测")
data = self.tokenize_load(data)
self.model = self.modeload()
result = self.model.predict(data)
print(result)
if __name__ == '__main__':
data = ['[鼓掌]//@慕春彦: 一流的经纪公司是超模的摇篮![鼓掌] //@姚戈:东方宾利强大的名模军团!',
'好感动[亲亲]大家都陆陆续续收到超极本尼泊尔的奖品了,没想到你还带着去看瓷房子~祝蜜月快乐哦'
,'烦死了,又要加班了,我都要哭了呀',
'反正我很喜欢用电动牙刷。你买个200以上的都很好用。用完每颗牙齿都像洗了个牙。滑溜溜的。你占便宜买个几十块的他也就是个震动棒[嘻嘻]',
]
sa = SentimentAnalysis()
sa.res(data)
预测数据data是我们从微博随便扣几条评论进行测试
预测效果:

自己下载数据集,复制代码可用,有什么不对的地方欢迎大家提出意见,本人菜鸟,请勿diss
注意:训练会保存tokenizer词典,如需重新训练,必须删除目录中上次保存的tokenizer.pickle