Linux安装Elasticsearch(手把手入门教程及下载资源)
文章目录
- 一.安装Elasticsearch
-
- 1.下载Linux版本tar包
- 2.配置Elasticsearch
- 3.运行遇到的问题
- 4.浏览器访问Elasticsearch
- 二.ik分词器
-
- 1.上传并且解压
- 2.出现的问题
- 3.使用kibana控制台测试
- 4.解决Kibana运行命令提示安全验证
- 三.安装Kibana图形界面
-
- 1.Kibana用途
- 2.配置Kibana
- 3.运行Kibana
- 四.Elasticsearch常用操作
-
- 1基本概念
- 2.创建索引
-
- 2.2查看索引设置
- 2.3删除索引
- 2.4映射配置
-
- 2.4.1创建映射字段
- 2.4.2查看映射关系
- 2.4.3字段属性详解
-
- 2.4.3.1.type
- 2.4.3.2 index
- 2.4.3.3 store
- 2.5 新增数据
-
- 2.5.1随机生成id
- 2.5.2通过id查询数据
- 2.5.2自定义插入id
- 2.5.4 智能判断识别
- 2.6 修改数据
- 2.7 删除数据
- 3.查询
-
- 3.1基本查询
-
- 3.3.1 查询所有(match_all)
- 3.3.2 匹配查询(match)
- 3.3.3 多字段查询(multi_match)
- 3.3.4 词条匹配(term)
- 3.3.5 多词条精确匹配(terms)
- 3.2查询结果过滤
-
- 3.2.1.直接指定字段
- 3.2.2.指定includes和excludes
- 3.3高级查询
-
- 3.3.1 布尔组合(bool)
- 3.3.2 范围查找(range)
- 3.3.3 模糊查询(fuzzy)
- 3.4过滤(filter)
- 3.4排序
-
- 3.4.1 单字段排序
- 3.4.2聚合查询出现的问题
- 3.4.3 多字段排序
- 4. 聚合aggregations
-
-
- 4.1 基本概念
- 4.2 导入数据测试
- 4. 3聚合为桶
- 4.4 桶内度量
- 4.5 桶内嵌套桶
- 4.6.划分桶的其它方式
-
- 4.6.1.阶梯分桶Histogram
- 4.5.2.范围分桶range
-
一.安装Elasticsearch
介绍Elasticsearch:
- 分布式,无需人工搭建集群(solr就需要人为配置,使用Zookeeper作为注册中心)
- Restful风格,一切API都遵循Rest原则,容易上手
- 近实时搜索,数据更新在Elasticsearch中几乎是完全同步的
1.下载Linux版本tar包
官网地址
点击进入官网点击去体验

下拉找到该模块点击下载
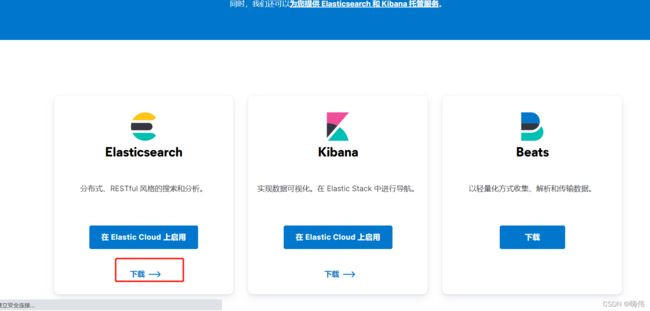
选择系统类型,点击下载

下载好的安装包,也可以某度下载地址 提取码:9htf
![]()
上传文件到linux,需要注意的是root是没办法启用Elasticsearch的,所以我们需要创建一个用户youtwo
useradd 用户名
passwd 用户名 #设置用户名的密码

创建的用户名会在/home下创建一个目录

把我们的安装包上传到youtwo目录下
但是文件是属于root的我们需要更改一下组

通过chown修改
chown user[:group] file…
user 所属用户:group用户组 file需要修改的文件
chown youtwo:youtwo elasticsearch-7.16.1-linux-x86_64.tar.gz

修改文件的权限chmod 755 elasticsearch-7.16.1-linux-x86_64.tar.gz

解压文件tar -zxvf elasticsearch-7.16.1-linux-x86_64.tar.gz
注意:后面出现问题就是因为没有切换用户导致的解压前记得切换用户 su -youtwo

修改文件的名称:mv elasticsearch-7.16.1 elasticsearch

2.配置Elasticsearch
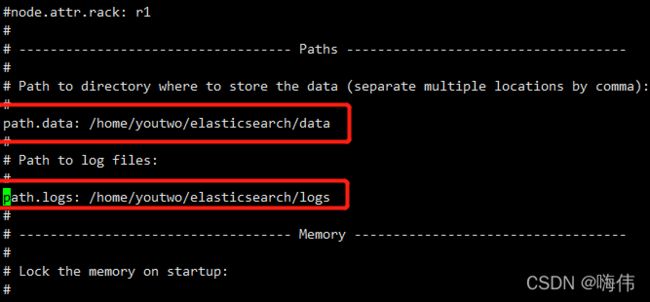
进入config目录

配置vi elasticsearch.yml文件需要把前面的#删除
/home/youtwo/elasticsearch/data #数据目录
/home/youtwo/elasticsearch/logs #日志目录
在往下一点还要把:network.host: 0.0.0.0ip改成这个
#设置允许所有ip可以连接该elasticsearch
在添加下面参数让elasticsearch-head插件可以访问es
http.cors.enabled: true
http.cors.allow-origin: "*"
不然后面运行会报错:Network is unreachable
wq保存退出
记得创建data目录,因为logs已经有了不需要创建
需要保证linux已经安装好jdk1.8及以上版本




运行elasticsearch服务
进入 bin目录下运行./elasticsearch

运行报错了,由于使用root启动导致的

我们切换到另外一个用户:su - youtwo

又遇到问题提示没有jdk,就运行查看版本存在呀

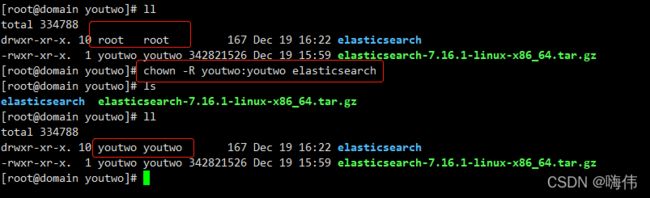
后面排查我们解压什么的都在root用户下解压地址文件还是属于root,我们创建的用户不能使用

现在改下解压后的权限,切换会root 更改权限:chown -R youtwo:youtwo elasticsearch 使用到-R :把目录下的所有权限都跟着一起修改
切换用户并运行

报这个错误是由于文件

3.运行遇到的问题
切换Root用户解决问题
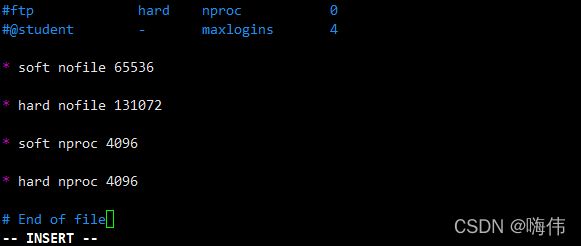
问题1:max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]我们用的是的用户,不是root,所以文件权限不足修改/etc/security/limits.conf添加下面 内容
* soft nofile 65536
* hard nofile 131072
* soft nproc 4096
* hard nproc 4096
wq保存退出
问题2:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
vm.max_map_count:限制一个进程可以拥有的VMA(虚拟内存区域)的数量,继续修改配置文件, :
vim /etc/sysctl.conf
添加:vm.max_map_count=655360
然后运行:sysctl -p


问题3:the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
修改
elasticsearch.yml配置文件
添加cluster.initial_master_nodes: ["node-1"]
wq保存退出

在次重启,切换用户运行

问题4:出现UnknownHostException: geoip.elastic.co

修改elasticsearch.yml配置添加ingest.geoip.downloader.enabled: false
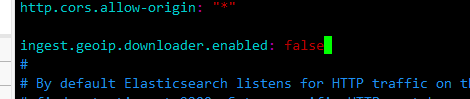
在运行就没有出现报错信息

4.浏览器访问Elasticsearch
通过Linux的ip:9200访问
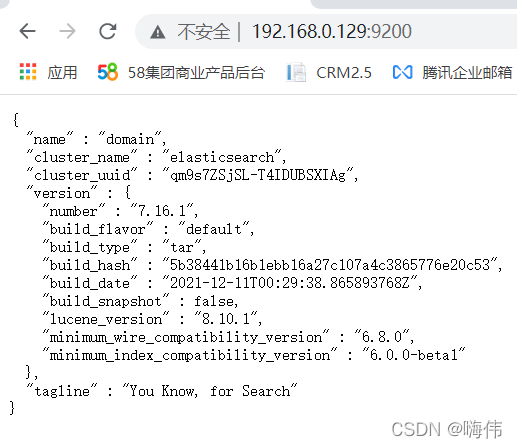
二.ik分词器
1.上传并且解压
Elasticsearch和IK的版本使用

分词器点击下载提取码:feq4
把分词器插件上传到plugins下


解压插件
unzip elasticsearch-analysis-ik-7.16.2.zip -d ik-analyzer
解压完成后记得把压缩包删除

2.出现的问题
在运行elasticsearch出现该问题

原因是ik分词器版本不一致
进入分词器插件目录 vi plugin-descriptor.properties修改配置

elasticsearch.version=改成提示错误的版本号(我这是7.16.1)
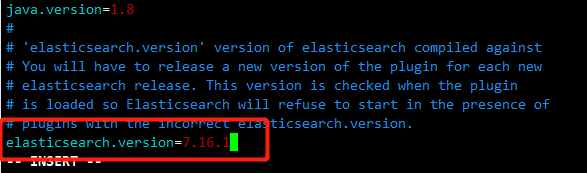
wq保存退出
运行Elasticsearch可以看出日志已经输出加载ik分词器了,并且也没有运行报错

3.使用kibana控制台测试
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人,我很骄傲"
}

发送成功后我们得到以下结果(分词的结果)
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "中国",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "国人",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "我",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 5
},
{
"token" : "很",
"start_offset" : 7,
"end_offset" : 8,
"type" : "CN_CHAR",
"position" : 6
},
{
"token" : "骄傲",
"start_offset" : 8,
"end_offset" : 10,
"type" : "CN_WORD",
"position" : 7
}
]
}
但是提示了一个错误,大致意思是Elasticsearch内置的安全特性没有被启用,没有身份验证,任何人都可以访问您的集群,测试阶段不影响

4.解决Kibana运行命令提示安全验证
#! Elasticsearch built-in security features are not enabled. Without authentication, your cluster could be accessible to anyone. See
进入Elasticsearch的config包下的 编辑vi elasticsearch.yml
在里面添加一行禁用安全选项xpack.security.enabled: false

wq保存,重启elasticsearch,先把本地运行的Kibana关闭掉等elasticsearch开启成功后在运行Kibana
三.安装Kibana图形界面
1.Kibana用途
Kibana是一个基于node.js的Elasticsearch索引数据统计工具,可以使用Elasticsearch的聚合功能,生成各种图标,还提供了索引数据控制台.

我这边下载windows版本的,直接去官网下载
2.配置Kibana
解压下载好的Kibana安装包在config下配置kibana.yml
修改elasticsearch.hosts

改成这个里面的ip是部署elasticsearch的服务,集群可以配置多个用逗号隔开

3.运行Kibana
不管是Linux或者windows都是需要node.js的依赖

通过浏览器访问http://安装Kibana访问的ip:5601/

找到这个界面

点进去就会进入Kibana的开发工具,我们可以通过这个来创建Elasticsearch的增上改查等操作

四.Elasticsearch常用操作
1基本概念
Elasticsearch也是基于Lucene的全文检索库,本质也是存储数据,很多概念与MySQL类似的。
对比关系:
索引(indices)--------------------------------Databases 数据库
类型(type)-------------------------Table 数据表(从7.x开始已经废弃)
文档(Document)----------------Row 行
字段(Field)-------------------Columns 列
详细说明:
| 概念 | 说明 |
|---|---|
| 索引库(indices) | indices是index的复数,代表许多的索引 |
| 类型(type) | 类型是模拟mysql中的table概念(不过从7.x开始已经废弃) |
| 文档(document) | 存入索引库原始的数据。比如每一条商品信息,就是一个文档 |
| 字段(field) | 文档中的属性 |
| 索引库(indices) | indices是index的复数,代表许多的索引 |
| 映射配置(mappings) | 字段的数据类型、属性、是否索引、是否存储等特性 |
- 索引集(Indices,index的复数):逻辑上的完整索引 collection1
- 分片(shard):数据拆分后的各个部分
- 副本(replica):每个分片的复制
注意:Elasticsearch本身就是分布式的,因此即便你只有一个节点,Elasticsearch默认也会对你的数据进行分片和副本操作,当你向集群添加新数据时,数据也会在新加入的节点中进行平衡。
2.创建索引
Elasticsearch采用Rest风格Api,因此可以使用工具发起http请求
创建索引请求的格式:
- 请求方式:PUT
- 请求路径:/索引名称
- 请求参数:Json格式
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
}
}
settings:索引库的设置
- number_of_shards:分片数量(只有一台就填写1,创建索引后就不能更改了)
- number_of_replicas:副本数量(只有一台就填写0,创建索引后也可以随时更改)
使用ApiPost发送http请求插入索引库

使用Kibana测试
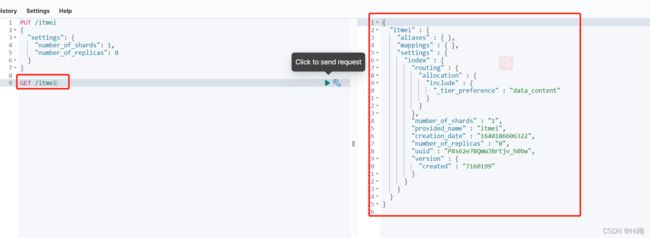
kibana的控制台,可以对http请求进行简化
PUT /itmei
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
}
}

2.2查看索引设置
Get请求可以帮我们查看索引信息,格式
GET /索引库名
可以使用*来查询所有索引库配置
GET *
2.3删除索引
DELETE /索引库名
创建索引库2

访问索引库2的数据

删除索引库2
DELETE /itmei2

查看索引库2已经返回404找不到了

2.4映射配置
2.4.1创建映射字段
- 请求方式:PUT
PUT /索引库名/_mapping/类型名称
{
"properties": {
"字段名": {
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
}
}
}
- type:类型,可以是text、long、short、date、integer、object等
- index:是否索引,默认true
- store:是否仓储,默认false
- analyzer:分词器,参数这里使用
ik_max_word即使用ik分词器
示例
如果Elasricsearch是7.x以下低版本的可以不需要拼接?include_type_name=true因为7.x之后不支持type导致的
PUT itmei/_mapping/goods?include_type_name=true
{
"properties":{
"title":{
"type":"text",
"analyzer":"ik_max_word"
},
"images":{
"type":"keyword",
"index":false
},
"price":{
"type":"float"
}
}
}

响应结果:
{
"acknowledged": true
}
2.4.2查看映射关系
语法
GET /索引库名称/_mapping
示例:
GET /itmei/_mapping

响应代码
{
"itmei" : {
"mappings" : {
"properties" : {
"images" : {
"type" : "keyword",
"index" : false
},
"price" : {
"type" : "float"
},
"title" : {
"type" : "text",
"analyzer" : "ik_max_word"
}
}
}
}
}
2.4.3字段属性详解
2.4.3.1.type
Elasticsearch支持的数据类型非常丰富,我们就拿常用的来介绍
-
String类型,又分两种:
- text:可分词,不可参与聚合
- keyword:不可分词,数据会作为完整字段进行匹配,可以参与聚合
-
Numerical:数值类型,分两类
- 基本数据类型:long、interger、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
- 需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时再还原。
-
Date:日期类型
elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。
2.4.3.2 index
index影响字段的索引情况。
- true:字段会被索引,则可以用来进行搜索。默认值就是true
- false:字段不会被索引,不能用来搜索(有些字段我们需要手动设置,因为必须要参与检索,比如商品图片)
2.4.3.3 store
是否将数据进行额外存储。
如果设置store为true,就会在_source以外额外存储一份数据,多余,因此一般我们都会将store设置为false,事实上,store的默认值就是false。
2.5 新增数据
2.5.1随机生成id
通过POST请求,可以向一个已经存在的索引库中添加数据。
语法:
POST /索引库名/类型名
{
"key":"value",
"key2":"value2"
}
示例:
POST /itmei/goods
{
"title":"红米手机",
"price":"2999",
"images":"https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg"
}

响应
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "NI5N5n0BFIP5QEoddtDO",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 3
}
2.5.2通过id查询数据
语法:
GET /索引库名/映射类型名名称/插入的id
示例:
GET itmei/goods/NI5N5n0BFIP5QEoddtDO

响应数据
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "NI5N5n0BFIP5QEoddtDO",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 3,
"found" : true,
"_source" : {
"title" : "红米手机",
"price" : "2999",
"images" : "https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg"
}
}
2.5.2自定义插入id
如果我们想要自己新增的时候指定id可以这样。
语法:
POST /索引库名/类型名/id值
{
"key":"value",
"key2":"value2"
}
示例:
POST /itmei/goods/1
{
"title":"小米米手机",
"price":"3999",
"images":"https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg"
}
可以发现已经自定义id成功了

响应
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "NI5N5n0BFIP5QEoddtDO",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 3
}
通过id查询数据

2.5.4 智能判断识别
Elasticsearch非常智能,你不需要给索引库设置任何mapping映射,它也可以根据你输入的数据来判断类型,动态添加数据映射
示例:
POST /itmei/goods/2
我们在用来的基础上多添加了2个映射名称,也成功插入

在查询id信息,可以正常显示

我们在查看下映射字关系
GET /itmei/_mapping/

响应数据
{
"itmei" : {
"mappings" : {
"properties" : {
"images" : {
"type" : "keyword",
"index" : false
},
"price" : {
"type" : "float"
},
"saleable" : {
"type" : "boolean"
},
"stock" : {
"type" : "long"
},
"title" : {
"type" : "text",
"analyzer" : "ik_max_word"
}
}
}
}
}
stock和saleable都被成功映射了。
2.6 修改数据
我们把刚刚的数据进行修改,修改需要指定id
- 请求方式:PUT
- id如果不存在,则新增加
- id如果存在,则修改
修改前面id为2的数据把OPPO手机改华为手机
PUT itmei/goods/2
{
"title":"华为手机",
"price":"999",
"images":"https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg",
"stock":10,
"saleable":true
}

我们现在在插入id是3的数据手机名称把华为改成OPPO重点在与我们现在还没有创建id是3的数据所以运行后是新增操作
PUT itmei/goods/3
{
"title":"OPPO手机",
"price":"1999",
"images":"https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg",
"stock":10,
"saleable":true
}

2.7 删除数据
我们把刚刚的数据进行删除,删除需要指定id
语法
DELETE /索引库名/类型名/id值
示例
DELETE itmei/goods/3

响应数据
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "3",
"_version" : 8,
"result" : "deleted",
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 14,
"_primary_term" : 3
}
3.查询
我们把查询分为多个模块进行展示
- 基本查询
_source过滤- 结果过滤
- 高级查询
- 排序
3.1基本查询
语法
GET /索引库名/_search
{
"query":{
"查询类型":{
"查询条件":"查询条件值"
}
}
}
这里的query代表一个查询对象,里面可以有不同的查询属性
- 查询类型:
- 例如:
match_all,match,term,range等等
- 例如:
- 查询条件:查询条件会根据类型的不同,写法也有差异,后面在测试
3.3.1 查询所有(match_all)

GET itmei/_search
{
"query": {
"match_all": {}
}
}
- query:代表查询对象
- match_all:代表查询所有
响应数据
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "红米手机",
"price" : "2999",
"images" : "https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg"
}
},
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"title" : "OPPO手机",
"price" : "2999",
"images" : "https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg",
"stock" : 20,
"saleable" : true
}
},
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"title" : "华为手机",
"price" : "3999",
"images" : "https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg",
"stock" : 20,
"saleable" : false
}
}
]
}
}
- took:查询花费时间,单位是毫秒
- time_out:是否超时
- _shards:分片信息
- hits:搜索结果总览对象
- total:搜索到的总条数
- max_score:所有结果中文档得分的最高分
- hits:搜索结果的文档对象数组,每个元素是一条搜索到的文档信息
- _index:索引库
- _type:文档类型
- _id:文档id
- _score:文档得分
- _source:文档的源数据
3.3.2 匹配查询(match)
我们插入一条数据和手机区分开来
PUT /itmei/goods/4
{
"title":"长虹电视",
"images":"http://image.leyou.com/12479122.jpg",
"price":3899.00
}
现在库里面有3个手机1个电视总共4条数据

- or关系
match类型查询,会把查询条件进行分词,然后进行查询,多个词条之间是or的关系

GET itmei/_search
{
"query": {
"match": {
"title": "小米手机"
}
}
}
响应数据
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.8664205,
"hits" : [
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "1",
"_score" : 1.8664205,
"_source" : {
"title" : "红米手机",
"price" : "2999",
"images" : "https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg"
}
},
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "2",
"_score" : 0.77691567,
"_source" : {
"title" : "OPPO手机",
"price" : "2999",
"images" : "https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg",
"stock" : 20,
"saleable" : true
}
},
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "3",
"_score" : 0.69441146,
"_source" : {
"title" : "华为手机",
"price" : "3999",
"images" : "https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg",
"stock" : 20,
"saleable" : false
}
}
]
}
}
会把小米手机进行分词查询,由于出现的数据里面没有关于电视所以不会查询出来,多个词是之间是or关系
- and关系
有些场景需要使用精准查询所以需要使用到and
GET itmei/_search
{
"query": {
"match": {
"title": {
"query":"长虹电视",
"operator":"and"
}
}
}
}
响应数据
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 4.688036,
"hits" : [
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "4",
"_score" : 4.688036,
"_source" : {
"title" : "长虹电视",
"images" : "http://image.leyou.com/12479122.jpg",
"price" : 3899.0
}
}
]
}
}
会把长虹和电视同时包含才会查询出来
or和and之间
如果使用多个词进行匹配operator 操作符参数设置成 and 只会将此文档排除,我们想要处于中间某种结果.
可以使用match查询支持minimum_should_match最小匹配参数,可以指定必须匹配的词项数用来表示一个文档是否相关通常使用百分比来表示分词之间的的匹配度

GET itmei/_search
{
"query": {
"match": {
"title": {
"query":"红米电视4A",
"minimum_should_match":"50%"
}
}
}
}
这里我们使用了3个词50%就相当于3*50%等于1.5个字只要包含一个多词就可以被匹配到
3.3.3 多字段查询(multi_match)
multi_match与match类似,不同的是它可以在多个字段中查询
我们在创建一个数据并且在数据里面添加一个副标题
PUT /itmei/goods/5
{
"title":"麒麟手机",
"price":"4999",
"subtitle":"华为旗下手机"
}
接着我们使用多字段查询
GET itmei/_search
{
"query": {
"multi_match": {
"query":"华为",
"fields": ["title","subtitle"]
}
}
}
- fields 数组可以存放多个查询字段

响应结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 2.71415,
"hits" : [
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "3",
"_score" : 2.71415,
"_source" : {
"title" : "华为手机",
"price" : "3999",
"images" : "https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg",
"stock" : 20,
"saleable" : false
}
},
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "5",
"_score" : 0.5753642,
"_source" : {
"title" : "麒麟手机",
"price" : "4999",
"subtitle" : "华为旗下手机"
}
}
]
}
}
由于查询的华为只要存在fields多字段里面,查询里面都可以被显示出来
3.3.4 词条匹配(term)
term 查询被用于精确值 匹配,这些精确值可能是数字、时间、布尔或者那些未分词的字符串

GET itmei/_search
{
"query": {
"term": {
"price": 4999
}
}
}
响应数据
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.3862942,
"hits" : [
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "5",
"_score" : 1.3862942,
"_source" : {
"title" : "麒麟手机",
"price" : "4999",
"subtitle" : "华为旗下手机"
}
}
]
}
}
3.3.5 多词条精确匹配(terms)
terms 查询和 term 查询一样,但它允许你指定多个值进行匹配。如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件就会被查询出来

GET itmei/_search
{
"query": {
"terms": {
"price": [3999,4999,5999]
}
}
}
terms下查询的字段是用数组存放多个值进行匹配查询
响应数据
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"title" : "华为手机",
"price" : "3999",
"images" : "https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg",
"stock" : 20,
"saleable" : false
}
},
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"title" : "麒麟手机",
"price" : "4999",
"subtitle" : "华为旗下手机"
}
}
]
}
}
3.2查询结果过滤
默认情况下elasticsearch查询匹配到的数据会把_source的所有字段都进行返回,如果我们需要指定返回什么数据就要使用_source进行过滤
3.2.1.直接指定字段

GET itmei/_search
{
"_source": ["title","price"],
"query": {
"terms": {
"price": [3999,4999,5999]
}
}
}
- 添加_source值是数组里面存放需要展示的字段
不通过_source指定字段如图:

3.2.2.指定includes和excludes
我们也可以通过:
- includes:来指定想要显示的字段
- excludes:来指定不想要显示的字段
二者都是可选的。
GET itmei/_search
{
"_source": {
"includes": "title"
},
"query": {
"terms": {
"price": [3999,4999,5999]
}
}
}

不显示某个字段
GET itmei/_search
{
"_source": {
"excludes": "title"
},
"query": {
"terms": {
"price": [3999,4999,5999]
}
}
}

3.3高级查询
3.3.1 布尔组合(bool)
我们在插入一条数据进行测试,在插入一条电视数据
PUT /itmei/goods/6
{
"title":"红米电视",
"price":4999
}
我们现在查询一下索引库的所有数据
GET /itmei/_search
{
"query": {
"match_all": {}
}
}
响应数据
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 6,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"title" : "长虹电视",
"images" : "http://image.leyou.com/12479122.jpg",
"price" : 3899.0
}
},
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"title" : "麒麟手机",
"price" : "4999",
"subtitle" : "华为旗下手机"
}
},
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"title" : "华为手机",
"price" : "3999",
"images" : "https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg",
"stock" : 20,
"saleable" : false
}
},
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "红米手机",
"price" : "2999",
"images" : "https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg"
}
},
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"title" : "OPPO手机",
"price" : "1999",
"images" : "https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg",
"stock" : 20,
"saleable" : true
}
},
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "6",
"_score" : 1.0,
"_source" : {
"title" : "红米电视",
"price" : 4999
}
}
]
}
}
bool把各种其它查询通过must(与)、must_not(非)、should(或)的方式进行组合
GET /itmei/_search
{
"query": {
"bool": {
"must": [{"match":{"title":"华为"}}],
"must_not": [{"match":{"title":"电视"}}],
"should": [{"match":{"title": "手机"}}]
}
}
}
响应数据
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 2.2393317,
"hits" : [
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "1",
"_score" : 2.2393317,
"_source" : {
"title" : "红米手机",
"price" : "2999",
"images" : "https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg"
}
}
]
}
}
可以看出加了must_nottitle字段的值都会被排除,接着must会与上should的字段进行展他们都是数组格式意味着可以多个字段进行查询如在这里插入代码片
GET /itmei/_search
{
"query": {
"bool": {
"must": [{"match":{"title":"红米"}}],
"must_not": [{"match":{"title":"电视"}}],
"should": [{"match":{"title": "手机"}},{"match":{"title": "华为"}}]
}
}
}

3.3.2 范围查找(range)
range查询找出某个字段指定区间内的数字或者时间
| 操作符 | 介绍 |
|---|---|
| gt | 大于 |
| gte | 大于等于 |
| lt | 小于 |
| lte | 小于等于 |
语法
GET /索引库/_search
{
"query": {
"range": {
"FIELD": {
"gte": 10,
"lte": 20
}
}
}
}
FIELD表示查询的字段,这里标识查询字段的大于等于10小于等于20的范围数据
示例:查询price字段的范围区间
GET /itmei/_search
{
"query": {
"range": {
"price": {
"gte": 3999,
"lte": 4999
}
}
}
}
响应数据
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"title" : "麒麟手机",
"price" : "4999",
"subtitle" : "华为旗下手机"
}
},
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"title" : "华为手机",
"price" : "3999",
"images" : "https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg",
"stock" : 20,
"saleable" : false
}
},
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "6",
"_score" : 1.0,
"_source" : {
"title" : "红米电视",
"price" : 4999
}
}
]
}
}
3.3.3 模糊查询(fuzzy)
fuzzy等价于term的 模糊查询,但是查询的词条和索引库里面的词条可以允许偏差,但是偏差不能超过2位
示例
GET /itmei/_search
{
"query": {
"fuzzy": {
"title": "麒麟"
}
}
}
响应数据
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.6360589,
"hits" : [
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "5",
"_score" : 1.6360589,
"_source" : {
"title" : "麒麟手机",
"price" : "4999",
"subtitle" : "华为旗下手机"
}
}
]
}
}
可以通过fuzziness属性设置编辑偏差的距离
GET /itmei/_search
{
"query": {
"fuzzy": {
"title":{
"value": "麒麟",
"fuzziness": 1
}
}
}
}
3.4过滤(filter)
条件查询中进行过滤,有查询都会有影响到文档的评分和排名,如果查询结果中进行了过滤,标签不希望影响到过滤的评分结果,那么就不要把过滤条件作为查询条件使用,而是使用filter方式:
对标题进行模糊查询,并且对价格进行做过滤,这样就可以避免查询出来的数据结果是大于等于2000并且小于等于3000的数据
注意:filter中还可以再次进行bool组合条件过滤。
查询语句
GET itmei/_search
{
"query": {
"bool": {
"must":
{
"match": {
"title": "小米手机"
}
},
"filter": [
{
"range": {
"price": {
"gte": 2000,
"lte": 3000
}
}
}
]
}
}
}
查询结果
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.920312,
"hits" : [
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "1",
"_score" : 1.920312,
"_source" : {
"title" : "红米手机",
"price" : "2999",
"images" : "https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg"
}
},
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "2",
"_score" : 0.62958694,
"_source" : {
"title" : "OPPO手机",
"price" : "2999",
"images" : "https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg",
"stock" : 20,
"saleable" : true
}
}
]
}
}

无查询条件,直接过滤
如果一次查询只有过滤,没有查询条件,不希望进行评分,我们可以使用constant_score取代只有 filter 语句的 bool 查询。在性能上是完全相同的,但对于提高查询简洁性和清晰度有很大帮助。
查询条件
GET itmei/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"price": {
"gt": 2000,
"lt": 3000
}
}
}
}
}
}
查询结果
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "红米手机",
"price" : "2999",
"images" : "https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg"
}
},
{
"_index" : "itmei",
"_type" : "goods",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"title" : "OPPO手机",
"price" : "2999",
"images" : "https://cdn.cnbj1.fds.api.mi-img.com/product-images/redmik40ultra-k40pro/specs_header.jpg",
"stock" : 20,
"saleable" : true
}
}
]
}
}
3.4排序
3.4.1 单字段排序
sort 可以让我们按照不同的字段进行排序,并且通过order指定排序的方式
3.4.2聚合查询出现的问题
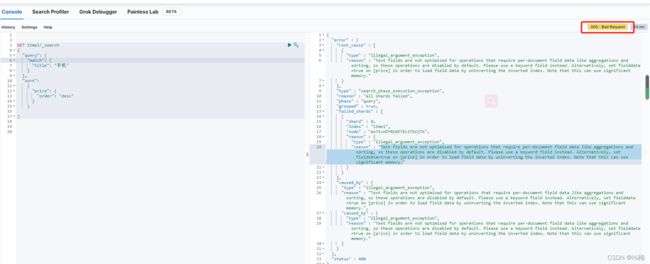
注意:文本字段没有针对需要每个文档字段数据的操作(如聚合和排序)进行优化,因此这些操作在默认情况下是禁用的,因为这样可能会作用大量的内存所以会提示错误,需要把排序的字段进行添加索引
解决办法
可以看出提示错误的字段是price价格字段添加
PUT /itmei/_mapping?pretty
{
"properties": {
"price": {
"type": "text",
"fielddata": true
}
}
}

在运行上面的语句就可以正常展示数据了

3.4.3 多字段排序
假定我们想要结合使用 price和 _score(得分) 进行查询,并且匹配的结果首先按照价格排序,然后按照相关性得分排序
查询语句
GET itmei/_search
{
"query": {
"bool": {
"must":{"match":{"title":"小米手机"}},
"filter": [
{
"range": {
"price": {
"gt": 2000,
"lt": 3000
}
}
}
]
}
},
"sort":
{
"price": {
"order": "desc"
},
"_score":{
"order":"desc"
}
}
}
查询结果

4. 聚合aggregations
聚合可以让我们极其方便的实现对数据的统计、分析
- 什么手机最多人买?
- 手机每个月的销售情况?
- 手机的价格平均多少,最高又是多少?
4.1 基本概念
Elasticsearch中的聚合,包含多种类型,最常用的两种,一个叫桶,一个叫度量:
桶的作用:
按照某种方式对数据进行分组,每一组数据在ES中称为一个桶,例如我们根据车品牌划分,可以得到大众桶、本田桶,奥迪桶……或者我们按照年龄段对人进行划分:0-10,10-20,20-30,30-40等
Elasticsearch中提供的划分桶的方式有很多:
- Date Histogram Aggregation:根据日期阶梯分组,例如给定阶梯为周,会自动每周分为一组
- Histogram Aggregation:根据数值阶梯分组,与日期类似
- Terms Aggregation:根据词条内容分组,词条内容完全匹配的为一组
- Range Aggregation:数值和日期的范围分组,指定开始和结束,然后按段分组
- . . . . .
度量(metrics)
分组完成以后,我们一般会对组中的数据进行聚合运算,例如求平均值、最大、最小、求和等,这些在ES中称为
度量
比较常用的一些度量聚合方式:
- Avg Aggregation:求平均值
- Max Aggregation:求最大值
- Min Aggregation:求最小值
- Percentiles Aggregation:求百分比
- Stats Aggregation:同时返回avg、max、min、sum、count等
- Sum Aggregation:求和
- Top hits Aggregation:求前几
- Value Count Aggregation:求总数
- ……
4.2 导入数据测试
创建索引:
PUT /cars
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"color": {
"type": "keyword"
},
"make": {
"type": "keyword"
}
}
}
}

注意:在ES中,需要进行聚合、排序、过滤的字段其处理方式比较特殊,因此不能被分词。这里我们将color和make这两个文字类型的字段设置为keyword类型,这个类型不会被分词,将来就可以参与聚合
导入数据
POST /cars/_bulk
{ "index": {}}
{ "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2014-05-18" }
{ "index": {}}
{ "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2014-07-02" }
{ "index": {}}
{ "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2014-08-19" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2014-01-01" }
{ "index": {}}
{ "price" : 25000, "color" : "blue", "make" : "ford", "sold" : "2014-02-12" }
4. 3聚合为桶
首先,我们按照 汽车的颜色color来划分桶
查询请求
GET /cars/_search
{
"size": 0,
"aggs": {
"popular_colors": {
"terms": {
"field": "color"
}
}
}
}
解析:
- size: 查询条数,这里设置为0,因为我们不关心搜索到的数据,只关心聚合结果,提高效率
- aggs:声明这是一个聚合查询,是aggregations的缩写
- popular_colors:给这次聚合起一个名字,
任意。- terms:划分桶的方式,这里是根据词条划分
- field:划分桶的字段
- terms:划分桶的方式,这里是根据词条划分
- popular_colors:给这次聚合起一个名字,

查询结果
{
"took" : 896,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"popular_colors" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "red",
"doc_count" : 4
},
{
"key" : "blue",
"doc_count" : 2
},
{
"key" : "green",
"doc_count" : 2
}
]
}
}
}
- hits:查询结果为空,因为我们设置了size为0
- aggregations:聚合的结果
- popular_colors:我们定义的聚合名称
- buckets:查找到的桶,每个不同的color字段值都会形成一个桶
- key:这个桶对应的color字段的值
- doc_count:这个桶中的文档数量
可以通过这次聚合查询得出卖红色颜色的车销量高!
4.4 桶内度量
前面的例子告诉我们每个桶里面的文档数量,这很有用。 但通常,我们的应用需要提供更复杂的文档度量。 例如,每种颜色汽车的平均价格是多少?
因此,我们需要告诉Elasticsearch使用哪个字段,使用何种度量方式进行运算,这些信息要嵌套在桶内,度量的运算会基于桶内的文档进行
现在,我们为刚刚的聚合结果添加 求价格平均值的度量
查询请求
GET /cars/_search
{
"size": 0,
"aggs": {
"popular_colors": {
"terms": {
"field": "color"
},
"aggs": {
"agg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
- aggs:我们在上一个aggs(popular_colors)中添加新的aggs。可见度量也是一个聚合
- avg_price:聚合的名称
- avg:度量的类型,这里是求平均值
- field:度量运算的字段
查询结果
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"popular_colors" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "red",
"doc_count" : 4,
"agg_price" : {
"value" : 32500.0
}
},
{
"key" : "blue",
"doc_count" : 2,
"agg_price" : {
"value" : 20000.0
}
},
{
"key" : "green",
"doc_count" : 2,
"agg_price" : {
"value" : 21000.0
}
}
]
}
}
}

可以看出agg_price 每种颜色车的平均价格
4.5 桶内嵌套桶
刚刚的案例中,我们在桶内嵌套度量运算。事实上桶不仅可以嵌套运算, 还可以再嵌套其它桶。也就是说在每个分组中,再分更多组。
比如:我们想统计每种颜色的汽车中,分别属于哪个制造商,按照make字段再进行分桶
查询请求
GET /cars/_search
{
"size": 0,
"aggs": {
"popular_colors": {
"terms": {
"field": "color"
},
"aggs": {
"agg_price": {
"avg": {
"field": "price"
}
},
"maker":{
"terms": {
"field": "make"
}
}
}
}
}
}
- 原来的color桶和avg计算我们不变
- maker:在嵌套的aggs下新添一个桶,叫做maker
- terms:桶的划分类型依然是词条
- filed:这里根据make字段进行划分
查询结果
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"popular_colors" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "red",
"doc_count" : 4,
"maker" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "honda",
"doc_count" : 3
},
{
"key" : "bmw",
"doc_count" : 1
}
]
},
"agg_price" : {
"value" : 32500.0
}
},
{
"key" : "blue",
"doc_count" : 2,
"maker" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "ford",
"doc_count" : 1
},
{
"key" : "toyota",
"doc_count" : 1
}
]
},
"agg_price" : {
"value" : 20000.0
}
},
{
"key" : "green",
"doc_count" : 2,
"maker" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "ford",
"doc_count" : 1
},
{
"key" : "toyota",
"doc_count" : 1
}
]
},
"agg_price" : {
"value" : 21000.0
}
}
]
}
}
}
- 我们可以看到,新的聚合maker被嵌套在原来每一个color的桶中。
- 每个颜色下面都根据 make字段进行了分组
- 我们能读取到的信息:
- 红色车共有4辆
- 红色车的平均售价是 $32,500 美元。
- 其中3辆是 Honda 本田制造,1辆是 BMW 宝马制造。

4.6.划分桶的其它方式
前面讲了,划分桶的方式有很多,例如:
- Date Histogram Aggregation:根据日期阶梯分组,例如给定阶梯为周,会自动每周分为一组
- Histogram Aggregation:根据数值阶梯分组,与日期类似
- Terms Aggregation:根据词条内容分组,词条内容完全匹配的为一组
- Range Aggregation:数值和日期的范围分组,指定开始和结束,然后按段分组
刚刚的案例中,我们采用的是Terms Aggregation,即根据词条划分桶。
接下来,我们再学习几个比较实用的:
4.6.1.阶梯分桶Histogram
原理:
histogram是把数值类型的字段,按照一定的阶梯大小进行分组。你需要指定一个阶梯值(interval)来划分阶梯大小。
比如:
价格字段做了阶梯分组,那么就需要设置interal的值为500,那么阶梯就是 0,500,1000,1500,…
上面列出的是每个阶梯的key,也是区间的启点(0-500,500-1000)。
阶梯公式
bucket_key = Math.floor((value - offset) / interval) * interval + offsetvalue:就是当前数据的值,本例中是450
offset:起始偏移量,默认为0
interval:阶梯间隔,比如500
对汽车价格进行阶梯分组,设置interval为5000:
查询请求
GET /cars/_search
{
"size": 0,
"aggs": {
"price":{
"histogram": {
"field": "price",
"interval": 5000
}
}
}
}
查询结果
{
"took" : 16,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"price" : {
"buckets" : [
{
"key" : 10000.0,
"doc_count" : 2
},
{
"key" : 15000.0,
"doc_count" : 1
},
{
"key" : 20000.0,
"doc_count" : 2
},
{
"key" : 25000.0,
"doc_count" : 1
},
{
"key" : 30000.0,
"doc_count" : 1
},
{
"key" : 35000.0,
"doc_count" : 0
},
{
"key" : 40000.0,
"doc_count" : 0
},
{
"key" : 45000.0,
"doc_count" : 0
},
{
"key" : 50000.0,
"doc_count" : 0
},
{
"key" : 55000.0,
"doc_count" : 0
},
{
"key" : 60000.0,
"doc_count" : 0
},
{
"key" : 65000.0,
"doc_count" : 0
},
{
"key" : 70000.0,
"doc_count" : 0
},
{
"key" : 75000.0,
"doc_count" : 0
},
{
"key" : 80000.0,
"doc_count" : 1
}
]
}
}
}
你会发现doc_count有很多结果都是为0那么就,显得很多数据是无用的,那么要怎么避免呢?
需要用到参数min_doc_count为1,来约束最少文档数量为1,这样文档数量为0的桶会被过滤
请求参数
GET /cars/_search
{
"size": 0,
"aggs": {
"price":{
"histogram": {
"field": "price",
"interval": 5000,
"min_doc_count": 1
}
}
}
}
请求结果

4.5.2.范围分桶range
范围分桶与阶梯分桶类似,也是把数字按照阶段进行分组,只不过range方式需要你自己指定每一组的起始和结束大小。
查询请求
GET /cars/_search
{
"size": 0,
"aggs": {
"price_range":{
"range": {
"field": "price",
"ranges": [
{
"from": 5000,
"to": 50000
}
]
}
}
}
}
查询结果
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"price_range" : {
"buckets" : [
{
"key" : "5000.0-50000.0",
"from" : 5000.0,
"to" : 50000.0,
"doc_count" : 7
}
]
}
}
}
