matlab拼碎纸片过程,碎纸片拼接复原模型
1. 引言
破碎文件的拼接在司法物证复原、历史文献修复以及军事情报获取等领域都有着重要的应用。企事业、机关、院校和军队基于保密的需要,使用碎纸机对重
要文件,单据以及材料进行销毁。一些重要的文件随着时间流逝,残破不全,因此,又需要将已经破碎的文档重新恢复。
传统上,拼接复原工作需由人工完成,准确率较高,但效率很低。特别是当碎片数量巨大,人工拼接很难在短时间内完成任务。随着当代科技和计算机技术的快速发展,人们试图开发碎纸片自动拼接技术,以提高对碎纸片文件和图片的拼接复原效率。
国内一些学者对碎纸片复原技术进行了研究,其中周丰提出了一种基于序列的二维图像碎纸片轮廓匹配算法[1],何鹏飞研究了基于蚁群优化算法的纸片拼接技术[2],罗智中[3]研究了基于文字特征的文档碎纸片半自动拼接方法,除此之外学者们还提出并研究了其他各种相应的技术[4-10]。然而目前通过计算机算法对破碎文档进行恢复的技术研究还不多,基本上没有一种全自动的碎纸片恢复技术,因此,一种能够快速且高效的恢复碎纸机数据文档技术的研究有巨大的现实意义。本文在借鉴其他学者研究基础上,对边缘规范的碎纸片拼接技术进行了研究。
2. 模型假设及符号说明
2.1. 模型假设
1) 设碎纸图片与真实文件纸张大小、颜色、边缘情况相同;
2) 假设碎纸照片边缘完整,不存在破损;
3) 假设所有碎纸片的扫描情况相同;
2.2. 符号说明
A
i ——编号i的图片的灰度矩阵;
B
i ——编号i的图片二值化处理后矩阵;
C
i ——编号i的图片二维边缘矩阵;
D
,
D
′
,
D
″
,
D
‴ ——边缘匹配度矩阵;
E
i ——编号
i 的图片再次处理后的0-1矩阵;
F ——边缘匹配度之和矩阵。
3. 问题分析
3.1. 中文碎纸片的分析
本论文数据来源于2013年全国大学生数学建模试题B题附件3、4,碎纸片均为一份纸张撕裂所得,不会存在含有相同信息的公共部分,下面不再重述。
附件3、4中所给的图片为扫描原纸张碎片后得到的BMP格式的图片,图片像素均为
180
×
72 ,使用matlab中的imread函数[11,12]可做出图片的灰度矩阵
A
i (
i
=
1
,
2
,
⋯
,
209 )。举例如下(由于该像素图片转换后为
180
×
72 的矩阵,论文中无法放置,所以仅简单举例说明,论文中若还出现庞大的矩阵,同本说明):
A
i
=
(
255
255
0
255
220
150
255
0
0
)
矩阵的中元素表示该位置图片灰度,255表示为白,0为黑,图片中信息为黑白文字信息,但由于文字信息会存在阴影,所以矩阵中出现了介于0-255的元素。为了方便应用,可对黑白图片做[13]二值化处理,将上例中
A
i 转化为如下0-1矩阵:
B
i
=
(
0
0
1
0
1
1
0
1
1
)
其中白色用0值表示,非白色用1表示。
将附件3、4中
11
×
19 张图片做如上处理得0-1矩阵
B
i
(
i
=
1
,
2
,
⋯
,
209
) ,矩阵阶数为
180
×
72 。
分别提取
B
i 矩阵第1列和第72构成新的
180
×
2 阶边缘矩阵。搜索所有图片矩阵发现
C
14
,
C
128 矩阵中均有一列为0,可认为编号为014和128的图片为相邻的两张图片,两张图片匹配的原则示例如图1。
将左边矩阵的第二列元素与右边矩阵的第一列元素进行两两匹配,记录元素相同的个数,个数除以180为左边矩阵第二列对右边矩阵第一列的边缘匹配度,记为:
D
i
j
=
元
素
相
同
的
数
量
180
定义:
D
i
j
=
匹
配
�
180 ——矩阵匹配度
将所有碎纸片的0-1矩阵做如上匹配过程,可依次选取与其匹配的碎纸片。图1中左边矩阵第一列与右边矩阵第二列匹配的原则同上。
将附件3和附件4中各自的209碎纸片做同样的图像处理转化为灰度矩阵后进行二值化处理得到与其相对应的矩阵,根据结果可知图片转化后的矩阵为
180
×
72 阶的,若使用边缘匹配的方法,一张碎纸片对应其他208张碎纸片的边缘匹配相同的像素点有208种情况,变化范围为
0
-
180 可知若直接采用边缘匹配中的方法得到的结果可能出现多个相同或无法判断的情况,所以这里我们先考虑附件中碎纸片的特
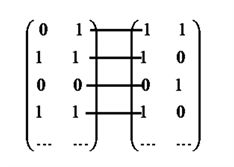
Figure 1. The matching diagram of 014 and 128 two images
图1. 014与128两张图片的匹配示意图
性。
观察图2发现,通过查阅资料分析[3]基于文字特征的文档碎纸片半自动拼接,每一行的绝大多数中文文字均可认为拥有同一上界、同一下界(图2最右端出现了“一”字,但是同行还存在其他文字,可认为同一行文字有同一上界与同一下界),我们可以根据这一特性,利用聚类分析[14]方法并使用Matlab软件将匹配度高及位置相同的碎纸片归类为一组[3]。
利用聚类方法归类步骤:
1) 搜索每一张碎纸片转化后二值化矩阵
C
i 的每一行,若矩阵该行中存在数值1,则将该行全部赋值为1,若这一行元素全为0,则将该行全部赋值为0,其中1表示本行存在灰度小于255的像素,0表示不存在灰度小于255的像素,这样将209张碎纸片做出新的二值化矩阵
E
i ;
2) 同3.1的分析取边缘做边缘匹配得修改后的边缘匹配度矩阵
D ,匹配度高则说明碎纸片的文字信息处于同一水平位置,见图2;
3) 在2)完成后如果未完全匹配,则进行再人工干预,得到较优的结果[11]见图3。
4) 得到很多组有相同位置的碎纸片后,在每一组内采用边缘匹配方法,这里为了防止出现两白边匹配造成碎纸片连接混乱的现象,要加以限制。方法为:若在组内做边缘匹配出现匹配度为1的情况,则暂时不连接此碎纸片,从剩余的碎纸片出发做边缘匹配与其他碎纸片连接,直到组内所有碎纸片均已覆盖。
5) 这样再通过一定人工干预可以得到拼接复原后的11横行碎纸片,再同样使用边缘匹配方法,将得到的11行碎纸条长边进行边缘匹配做出
11
×
11 的匹配度矩阵后找最大匹配度作为连接的碎纸条[15],同样为了防止出现两白边匹配造成碎纸片连接混乱的现象,要加以限制。方法为:若在组内做边缘匹配出
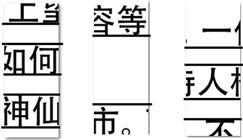
Figure 2. The images after secondary handling
图2. 处理后的图片

Figure 3. The images after secondary handling
图3. 二次处理后的图片
现匹配度为1的情况,则暂时不连接此碎纸片,从剩余的碎纸片出发做边缘匹配与其他碎纸片连接,直到11张拼接后的碎纸片均已覆盖。最后加以人工处理,得到完整的原文件。
3.2. 英文碎纸片的分析
碎纸片的英文在位置上也有一定的规则可循。如图4。
可以发现英文字母的主要的部分拥有同一上界和同一下界,但是跟中文不同,英文中会出现一些“y”、“d”之类的字母,为了同样使用3.1中的方法我们通过观察附件4中图片的像素情况,将图片中每一行中黑色像素数少于13(该值的选取是为了方便二值化转化,也可以选取别的数字)的及字母的次要部分转变为二值化矩阵中的0,将每一行中黑色像素大于等于13的及字母的主要部分转化为二值化矩阵中的1,这样得到的新的二值化矩阵
E
i ,可认为图像转变为下图5表示的方式,同样使用3.1中的分析方法将新的二值化矩阵做边缘匹配,匹配度高的可认为两碎纸片在原纸张中位于同一行,把匹配度高于0.9的元素分为一组后,对每一组进行边缘匹配。
考虑英文字符的情况,在3.1基础上,对组内图片原始二值化矩阵边缘匹配度矩阵
D 每一行的搜索,若矩阵的任意一行中出现匹配度大于0.9的元素个数超过2个,则加以人工干预,根据文章的格式、内容选择应该连接的碎纸片,其他过程同3.1,区别仅为本文中需要对软件执行过程进行人工干预。

Figure 4. Demonstrates picture 1
图4. 演示图片1
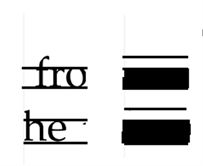
Figure 5. Demonstrates picture 2
图5. 演示图片2
4. 模型的建立与求解
4.1. 中文碎纸片复原的模型建立与求解
搜索每一张碎纸片转化后的0-1矩阵
C
i 的每一行,若存在黑色即矩阵该行中存在数值1,则将该行全部赋值为1,若这一行不存在黑即此行元素全为0,则将该行全部赋值为0,这样将209张碎纸片做出新的二值化矩阵
E
i ,之后按照3.1中的定义做边缘匹配,做出矩阵大小为
209
×
209 边缘匹配度矩阵
D (由于矩阵太大,在论文中不给出),元素
D
i
j 为处理后的碎纸片边缘二值化矩阵
i 的第二列与处理后的碎纸片边缘二值化矩阵
j 第一列的边缘匹配度,匹配度高则说明碎纸片的文字信息处于同一水平位置。在矩阵
D 中每一行选取匹配度大于0.9的元素,进行统计分组,可得结果如表1。
可以看出在取匹配度为0.9及以上时,分出了20个组,其中组内元素最多的为19,组内元素最少的为1。而最后的结果应该为11行,我们需要对这些组中的元素进行合并后得到11行,所以我们要先考虑元素数量为19的组,再考虑其他元素数多的组,对组内图片进行3.1中的边缘匹配,匹配后的结果在与元素数少的组做匹配与人工处理。
以第2组为例,该组包含19个元素,对于组内的19个元素的原始二值化矩阵进行上述中的边缘匹

Table 1. Grouping
表1. 分组情况
配,通过结果观察本题模型第一步确定模型的可行性,其他的组的处理情况相同,不再重述。结果如表2。
分别复原得到图片,观察图6、图7。
对于第二问中文碎纸片的复原问题,通过上面的结果发现匹配结果较好,对于中文的碎纸片的拼接复原即使过程中未加入人工干预也可以得到较优的结果。
可发现该组中文字位置符合想象,及同一行中的文字拥有同一上界和同一下界,在这一组中Matlab软件很好的将碎纸片拼接出来,思考为什么会出现上面图6、图7两者不能匹配在一起的原因。可发现拼
Table 2. Internal group
表2. 内部分组

Figure 6. The second set of splice results (1)
图6. 第二组拼接结果(1)

Figure 7. The second set of splice results (2)
图7. 第二组拼接结果(2)
接复原后的图6、图7左右两侧均存在白边,仅用计算机无法识别两者先后,需加以人工干预,通过对文章的内容、结构、形式的观察人工拼接,得出结果。改进后的图片排序见表2,复原图片见图8。
通过结果可以发现拼接程度较好,所以也验证了本问题中碎纸片拼接复原模型可行性。
其他组做相同处理,这样可得到拼接好的11横行的碎纸条,对11横行的碎纸条的长边进行边缘匹配,建立新的边缘匹配矩阵,结果如表3。
以上做出的表格把一些横行碎纸片拼接在一起,未能拼接的原因是由于拼接后的横行碎纸片两端都存在白边,计算机无法做出顺序的判断,所以我们要根据文字内容、规格、形式等因素人工将它们结合起来,人机结合后的原文件以表4。
观察发现拼接复原后结果较好。
4.2. 英文碎纸片复原的模型建立与求解
搜索每一张碎纸片转化后的0-1矩阵Ci的每一行,若存在黑色像素数量大于等于13即矩阵该行中数值1的数量大于等于13,则将该行全部赋值为1,若这一行黑色像素数量小于13,则将该行全部赋值为0,这样将209张碎纸片做出新的二值化矩阵Ei,之后同4.1的求解过程做边缘匹配,做出矩阵大小为
209
×
209 边缘匹配度矩阵D(由于矩阵太大,在论文中不做出),

Figure 8. The second set of results after splicing human intervention
图8. 人工干预后第二组拼接结果
元素
D
i
j 为处理后的碎纸片边缘二值化矩阵i的第二列与处理后的碎纸片边缘二值化矩阵j第一列的边缘匹配度,匹配度高则说明碎纸片的文字信息处于同一水平位置。同样在矩阵D中每一行选取匹配度大于0.9的元素,进行统计分组。
在这里需要强调的是,若分完组后的组内元素进行4.1中的边缘匹配进行残片复原,小组成员发现结果十分的不理想,任举一例,见图9。
根据图9可以发现对于本文中的英文残纸片的文字信息主要内容处于相同水平位置,文字信息处于同一水平位置,结合4.1可以认为首先判断文字信息未知的方法是正确的。但是组内英文碎纸片的拼接复原程度结果差,图中部分碎纸片得到了复原,而大部分却进行了错误的拼接。对比4.1的中文复原结果,可以认为英文相对中文会有一定的特殊性。
分析产生问题的原因,由于碎纸片的连接是按照组内图片两两边缘匹配的大小来决定的,发生如图的情况说明:实际的对应的碎纸片的边缘匹配度一般在0.9以上,英文碎纸片实际对应的碎纸片的边缘匹配度会出现比其他碎纸片的边缘匹配对小的情况。面对这种问题,我们需要对检测边缘匹配度的程序的过程进行人工干预,方法为:其他图片对当前图片的边缘匹配度若出现两个及两个以上大于0.9的匹配度,则进行人工干预,根据文章的内容、格式等进行人工拼接复原,其他步骤同4.1。对于本文中对于英文碎纸片的拼接复原问题可用图10的流程图表示。
通过上述步骤可一把相同行的纸片先拼接好,得到新的11张横行碎纸片,这里拼接11张碎纸片的方法同4.1,不再重述,得到的结果见表5。
4.3. 实现算法
索贝尔算子(Sobel operator)是图像处理中的算子之一,主要用作边缘检测。在技术上,它是一离散性差分算子,用来运算图像亮度函数的梯度之近似值。在图像的任何一点使用此算子,将会产生对应的梯度矢量或是其法矢量。
Table 3. Long-edge stitching result of shredded paper
表3. 碎纸条的长边拼接结果
Table 4. The recovery results of Annex 3
表4. 附件3的复原结果
![]()
Figure 9. Part of the mosaic picture of the results of the English group after completion
图9. 英文图片分完组后的部分拼接结果
该算子包含两组3 × 3的矩阵,分别为横向及纵向,将之与图像作平面卷积,即可分别得出横向及纵
向的亮度差分近似值。如果以A代表原始图像,Gx及Gy分别代表经横向及纵向边缘检测的图像,其公式如下:
G
x
=
(
−
1
0
+
1
−
2
0
+
2
−
1
0
+
1
)
∗
A
G
y
=
(
+
1
+
2
+
1
0
0
0
−
1
−
2
−
1
)
∗
A
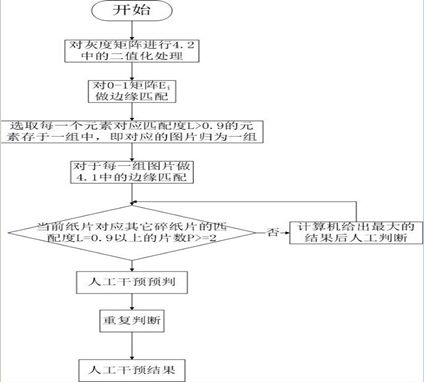
Figure 10. The flow chart
图10. 流程图
Table 5. The recovery results of Annex 4
表5. 附件4的复原结果
图像的每一个像素的横向及纵向梯度近似值可用以下的公式结合,来计算梯度的大小。
G
=
G
x
2
+
G
y
2
然后可用以下公式计算梯度方向
Θ
=
arctan
(
G
y
G
x
)
在以上例子中,如果以上的角度Θ等于零,即代表图像该处拥有纵向边缘,左方较右方暗。在边沿检测中,常用的一种模板是Sobel算子。Sobel算子有两个,一个是检测水平边沿的;另一个是检测垂直平边
沿的。Sobel算子对于象素的位置的影响做了加权,因此效果更好。Sobel算子另一种形式是各向同性Sobel(Isotropic Sobel)算子,也有两个,一个是检测水平边沿的,另一个是检测垂直平边沿的。各向同性Sobel算子和普通Sobel算子相比,它的位置加权系数更为准确,在检测不同方向的边沿时梯度的幅度一致。
4.4. 聚类精度和算法时间复杂度分析
1) 聚类精度分析
传统的k-means算法,所求的解往往是局部最优解,使用k-means算法在一定程度上减少了局部最优可能性,但从聚类过程看,求的解也往往是局部最优解,本文提出的调整簇阀值的加速算法,由于采用了近似的k-means算法,导致该算法只能找到局部近似解。适当地设置阀值,也能得到和k-means算法相当的聚类精度。
2) 时间复杂度分析
传统k-means算法的时间复杂度为
O
(
n
k
d
t
) ,其中,n为样本个数,k为簇数目,d为数据维数,t为迭代次数。
5. 模型的评价与推广
5.1. 模型的优点
通过对复原后图片验证结果认为碎纸片复原拼接模型对于本问题有很高的可行性。对于中、英文两种情况,发现了中文需要人工干预较少,英文人工干预较多的规律,说明不同语言有各自的特性,中文到英文由于难度的增加依次将模型进行改进,给出了严谨的说明过程,模型对该类问题有很好的可用性。
5.2. 模型的缺点
本模型仅适合规则碎纸片黑白信息的复原问题,不能解决不规则碎纸片的复原与非黑白信息的复原。人工干预占总过程时间的比例相对较高(35%),对于数据量大的碎纸片复原问题,人工干预可能会花掉大部分时间。
5.3. 模型的推广
该模型适用于规则碎纸片的拼接复原问题。本模型给出了中英文碎片处理的算法,根据复原结果,可认为本论文中的模型很好的适用于该类问题的解决。对于一些不熟悉的语言和符号信息,碎纸片的倒置情况未知,需要先对倒置情况进行判断,再进行类似的算法进行图片复原处理问题。
对于规则残片,如考古挖出的规则的文物、规则的钞票残片等残片复原问题,只需将它们用照片照好转化为灰度矩阵,对颜色进行一定的处理后借鉴本模型方法进行复原。