2021_KDD_Socially-Aware Self-Supervised Tri-Training for Recommendation
[论文阅读笔记]2021_KDD_Socially-Aware Self-Supervised Tri-Training for Recommendation
论文下载地址: https://doi.org/10.1145/3447548.3467340
发表期刊:KDD
Publish time: 2021
作者及单位:
- Junliang Yu The University of Queensland Brisbane, [email protected]
- Hongzhi Yin∗ The University of Queensland Brisbane, Australia [email protected]
- Min Gao Chongqing University Chongqing, China [email protected]
- Xin Xia The University of Queensland Brisbane, Australia [email protected]
- Xiangliang Zhang KAUST Thuwal, Saudi Arabia [email protected]
- Nguyen Quoc Viet Hung Griffith University Gold Coast, Australia [email protected]
数据集:
- Last.fm http://files.grouplens.org/datasets/hetrec2011/ 作者给的
- Douban-Book https://github.com/librahu/HIN-Datasets-for-Recommendation-and-Network-Embedding
- Yelp https://github.com/Coder-Yu/QRec
代码:
- https://github.com/Coder-Yu/QRec (作者在论文中公开的)
其他人写的文章
- Socially-Aware Self-Supervised Tri-Training for Recommendation
- Heterogeneous graph + self-supervised
简要概括创新点: (把SSL(Semi Supervised Learning)和Tri training,和对比学习(Contrastive Learning) 搬过来,完美地用起来。这波作者是MHCN的作者,有些思想接着用(尤其是User,Item三角关系))
- (1)We propose a general socially-aware self-supervised tri-training framework for recommendation. By unifying the recommendation task and the SSL task under this framework, the recommendation performance can achieve significant gains. (我们提出了一个通用的社交意识自监督tri-training推荐框架。通过在此框架下统一推荐任务和SSL任务,推荐性能可以取得显著的改进。)
- (2)by discovering self-supervision signals from two complementary views of the raw data. (通过从原始数据的两个互补视图中发现自监督信号来改进推荐。)
- (3)Under the self-supervised tri-training scheme, the neighbor-discrimination based contrastive learning method is developed to refine user representations with pseudo-labels from the neighbors=. (在self-supervised tri-training方案下,提出了基于邻居识别== 的 对比学习方法,利用邻居中的伪标签来细化用户表示。)
细节
- (1) Tri-training [47] is a popular semi-supervised learning algorithm which exploits unlabeled data using three classifiers. (tri-training是一种流行的半监督学习算法,它使用三种分类器利用无标签数据)
- (2)Then, in the labeling process of tri-training, for any classifier, an unlabeled example can be labeled for it as long as the other two classifiers agree on the labeling of this example. The generated pseudo-label is then used as the ground-truth to train the corresponding classifier in the next round of labeling. (然后,在 Tri-Training的标记过程中,对于任何一个分类器,只要其他两个分类器对这个例子的标记达成一致,就可以对一个未标记的例子进行标记。然后将生成的伪标签作为真实值,在下一轮标记中训练相应的分类器。)
- (3)LightGCN [11] is the basic encoder in SEPT.
ABSTRACT
- Self-supervised learning (SSL), which can automatically generate ground-truth samples from raw data, holds vast potential to improve recommender systems. Most existing SSL-based methods perturb the raw data graph with uniform node/edge dropout to generate new data views and then conduct the self-discrimination based contrastive learning over different views to learn generalizable representations. Under this scheme, only a bijective mapping is built between nodes in two different views, which means that the self-supervision signals from other nodes are being neglected. (自监督学习(SSL)可以从原始数据中自动生成真实样本,在改进推荐系统方面具有巨大的潜力。现有的基于ssl的方法通过节点/边dropout干扰原始数据图,生成新的数据视图,然后对不同视图进行基于对比学习的自识别,学习通用的表示。 在该模式下,只在两个不同视图的节点之间建立一个双射映射,说明忽略了来自其他节点的自监督信号。
- Due to the widely observed homophily in recommender systems, we argue that the supervisory signals from other nodes are also highly likely to benefit the representation learning for recommendation. To capture these signals, a general socially-aware SSL framework that integrates tri-training is proposed in this paper. (由于在推荐系统中被广泛观察到的同质性,我们认为来自其他节点的监督信号也很有可能有利于推荐的表示学习。为了捕获这些信号,本文提出了一种集成 tri-training的通用社交感知SSL框架。)
- Technically, our framework first augments the user data views with the user social information. (从技术上讲,我们的框架首先通过用户的社交信息来增强用户的数据视图)
- And then under the regime of tri-training for multi-view encoding, the framework builds three graph encoders (one for ecommendation) upon the augmented views and iteratively improves each encoder with self-supervision signals from other users, generated by the other two encoders. (然后在多视图编码的tri-training机制下,该框架在增强视图上构建三个图编码器(只有一个编码器用于推荐),并利用其他两个编码器生成的其他用户的自监督信号对每个编码器进行迭代更新。)
- Since the tri-training operates on the augmented views of the same data sources for self-supervision signals, we name it self-supervised tri-training. (由于tri-training是在自监督信号的相同数据源的增强视图上进行的,因此我们将其命名为 self-supervised tri-training。)
- Extensive experiments on multiple real-world datasets consistently validate the effectiveness of the self-supervised tritraining framework for improving recommendation. The code is released at https://github.com/Coder-Yu/QRec.
CCS CONCEPTS
• Information systems → Recommender systems; • Theory of computation → Semi-supervised learning.
KEYWORDS
Self-Supervised Learning, Tri-Training, Recommender Systems, Contrastive Learning
1 INTRODUCTION
-
(1) Self-supervised learning (SSL) [17], emerging as a novel learning paradigm that does not require human-annotated labels, recently has received considerable attention in a wide range of fields [5, 8, 16, 21, 23, 27, 45]. As the basic idea of SSL is to learn with the automatically generated supervisory signals from the raw data, which is an antidote to the problem of data sparsity in recommender systems, SSL holds vast potential to improve recommendation quality. The recent progress in self-supervised graph representation learning [14, 27, 40] has identified an effective training scheme for graph-based tasks. That is, performing stochastic augmentation by perturbing the raw graph with uniform node/edge dropout or random feature shuffling/masking to create supplementary views and then maximizing the agreement between the representations of the same node but learned from different views, which is known as graph contrastive learning [40]. Inspired by its effectiveness, a few studies [19, 29, 37, 46] then follow this training scheme and are devoted to transplanting it to recommendation. (自监督学习(SSL)是一种不需要人工标注标签的新型学习范式,最近在许多领域受到了相当广泛的关注。由于SSL的基本思想是从原始数据中学习自动生成的监督信号,可以解决推荐系统中的数据稀疏性问题,因此SSL在提高推荐性能方面具有巨大的潜力。自监督图表示学习的最新进展已经证明是一种有效的基于图的任务训练模式。也就是说,通过使用节点/边dropout或随机特征变换/掩蔽原始图来执行随机增强,以创建补充视图,然后最大化同一节点但从不同视图学习的表示之间的一致性,这称为图对比学习。受其有效性的启发,一些研究遵循这个训练模式,并致力于将其移植到推荐中。
-
(2) With these research effort, the field of self-supervised recommendation recently has demonstrated some promising results showing that mining supervisory signals from stochastic augmentations is desirable [29, 46]. However, in contrast to other graph-based tasks, recommendation is distinct because there is widely observed homophily across users and items [20]. Most existing SSL-based methods conduct the self-discrimination based contrastive learning over the augmented views to learn generalizable representations against the variance in the raw data. **Under this scheme, a bijective mapping is built between nodes in two different views, and a given node can just exploit information from itself in another view. Meanwhile, the other nodes are regarded as the negatives that are pushed apart from the given node in the latent space. Obviously, a number of nodes are false negatives which are similar to the given node due to the homophily, and can actually benefit representation learning in the scenario of recommendation if they are recognized as the positives. Conversely, roughly classifying them into the negatives could lead to a performance drop.
(通过这些研究的努力,自监督推荐领域最近已经被证明了一些有潜力的结果,表明从随机增强中挖掘监督信号是可取的。然而,与其他基于图的任务相比,推荐是截然不同的,因为在用户和商品之间有广泛观察到的同质性。大多数现有的基于ssl的方法是对增广视图进行基于自识别的对比学习,以学习针对原始数据的通用表示。在该方案下,在两个不同视图中的节点之间建立一个双射,一个给定的节点可以在另一个视图中从它本身挖掘信息。同时,将在潜在空间中的其他节点视为与给定节点被推开远离的==负节点==。一些节点是假负样本,由于同质性,它们与给定的节点相似,如果它们被识别为正样本,那么在推荐下,实际上可以有利于表示学习。相反,把它们粗略地归入负样本可能会导致性能下降。 -
(3) To tackle this issue, a socially-aware SSL framework which combines the tri-training [47] (multi-view co-training) with SSL is proposed in this paper. (为了解决这一问题,本文提出了一种将 tri-training(多视图共同训练)与SSL相结合的社交感知SSL框架)
- For supplementary views that can capture the homophily among users, we resort to social relations which can be another data source that implicitly reflects users’ preferences [4, 38, 41–43]. Owing to the prevalence of social platforms in the past decade, social relations are now readily accessible in many recommender systems. (补充的视图可以捕获用户之间的同质性,从另一个隐式反映用户偏好的数据源中捕捉社交关系。由于在过去的十年中社交平台的流行,社交关系现在在许多推荐系统中都很容易获得)
- We exploit the triadic structures in the user-user and user-item interactions to augment two supplementary data views, and socially explain them as profiling users’ interests in expanding social circles and sharing desired items to friends, respectively. (我们利用用户-用户和用户-项目交互中的三元结构来增强两个补充数据视图,并分别将其解释为用户在扩展社交圈的兴趣和向朋友分享项目的兴趣)
- Given the use-item view which contains users’ historical purchases, we have three views that characterize users’ preferences from different perspectives and also provide us with a scenario to fuse tri-training and SSL. (考虑到用户-项目视图包含了用户的历史购买,我们有三个视图从不同的角度描述用户的偏好,并提供一个场景来融合 tri-training和SSL。)
-
(4) Tri-training [47] is a popular semi-supervised learning algorithm which exploits unlabeled data using three classifiers. (tri-training是一种流行的半监督学习算法,它使用三种分类器利用无标签数据)
- In this work, we employ it to mine self-supervision signals from other users in recommender systems with the multi-view encoding. Technically, we first build three asymmetric graph encoders over the three views, of which two are only for learning user representations and giving pseudo-labels, and another one working on the user-item view also undertakes the task of generating recommendations. (在本工作中,我们利用它来挖掘具有多视图编码的推荐系统中其他用户的自监督信号。从技术上讲,我们首先在三个视图上构建了三个非对称图编码器,其中两个仅用于学习用户表示和给出伪标签,另一个针对用户-项目视图完成生成推荐的任务)
- Then we dynamically perturb the social network and user-item interaction graph to create an unlabeled example set. Following the regime of tri-training, during each epoch, the encoders over the other two views predict the most probable semantically positive examples in the unlabeled example set for each user in the current view. (然后,我们动态地扰乱社交网络和用户-项目交互图,创建一个无标签的样本集。在tri-training机制下,在每轮期间,其他两个视图上的编码器预测当前视图中每个用户的无标签的样本集中最可能的语义正样本。)
- Then the framework refines the user representations by maximizing the agreement between representations of labeled users in the current view and the example set through the proposed neighbor-discrimination based contrastive learning. As all the encoders iteratively improve in this process, the generated pseudo-labels also become more informative, which in turn recursively benefit the encoders again. The recommendation encoder over the user-item view thus becomes stronger in contrast to those only enhanced by the self-discrimination SSL scheme. Since the tri-training operates on the complementary views of the same data sources to learn self-supervision signals, we name it self-supervised tri-training. (然后,该框架通过所提出的基于邻居识别的对比学习细化用户表示,即==最大化当前视图中有标签与无标签数据集的用户表示之间的一致性来细化用户表示。随着所有编码器在这个过程中不断改进,生成的伪标签也变得更丰富,这反过来又递归地使编码器再次受益。因此,与仅通过自识别SSL方案增强的推荐编码器相比,用户-项目视图上的推荐编码器变得更强。由于tri-training是基于同一数据源==的补充视图来学习自监督信号,因此我们将其命名为自监督tri-training。
-
(5) The major contributions of this paper are summarized as follows:
- We propose a general socially-aware self-supervised tri-training framework for recommendation. By unifying the recommendation task and the SSL task under this framework, the recommendation performance can achieve significant gains. (我们提出了一个通用的社交意识自监督tri-training推荐框架。通过在此框架下统一推荐任务和SSL任务,推荐性能可以取得显著的改进。)
- We propose to exploit positive self-supervision signals from other users and develop a neighbor-discrimination based contrastive learning method. (我们提出从其他用户中挖掘积极自监督信号,并开发一种基于邻居识别的对比学习方法。)
- We conduct extensive experiments on multiple real-world datasets to demonstrate the advantages of the proposed SSL framework and investigate the effectiveness of each module in the framework through a comprehensive ablation study.
-
(6) The rest of this paper is structured as follows. Section 2 summarizes the related work of recommendation and SSL. Section 3 introduces the proposed framework. The experimental results are reported in Section 4. Finally, Section 5 concludes this paper.
2 RELATED WORK
2.1 Graph Neural Recommendation Models
- (1) Recently, graph neural networks (GNNs) [7, 34] have gained considerable attention in the field of recommender systems for their effectiveness in solving graph-related recommendation tasks. (近年来,图神经网络(GNNs)因其在解决图相关推荐任务的有效性而在推荐系统领域受到了广泛的关注。)
- Particularly, GCN [15], as the prevalent formulation of GNNs which is a first-order approximation of spectral graph convolutions, has driven a multitude of graph neural recommendation models like GCMC [2], NGCF [28], and LightGCN [11]. (特别是,GCN,作为GNNs的普遍公式,即谱图卷积的一阶近似,已经驱动了大量的图神经推荐模型,如GCMC,NGCF和LightGCN。)
- The basic idea of these GCN-based models is to exploit the high-order neighbors in the user-item graph by aggregating the embeddings of neighbors to refine the target node’s embeddings [33]. In addition to these general models, GNNs also empower other recommendation methods working on specific graphs such as SR-GNN [32] and DHCN [35] over the session-based graph, and DiffNet [31] and MHCN [44] over the social network. It is worth mentioning that GNNs are often used for social computing as the information spreading in social networks can be well captured by the message passing in GNNs [31]. That is the reason why we resort to social networks for self-supervisory signals generated by graph neural encoders.
这些基于GCN的模型的基本思想是通过聚合邻居的嵌入来利用用户-项目图中的高阶嵌入来细化目标节点的嵌入。除了这些通用模型之外,GNNs也被使用到其他针对特定图的推荐方法中,如基于会话的图SR-GNN和DHCN,以及社交网络上的DiffNet和MHCN。值得一提的是,GNN经常被用于社交计算,因为GNN可以很好地捕获社交网络中的信息传播。这就是为什么我们利用社交网络由图神经编码器生成自监督信号的原因。
2.2 Self-Supervised Learning in RS (这个方向值得关注)
-
(1) Self-supervised learning [17] (SSL) is an emerging paradigm to learn with the automatically generated ground-truth samples from the raw data. It was firstly used in visual representation learning and language modeling [1, 5, 10, 12, 45] for model pretraining. The recent progress in SSL seeks to harness this flexible learning paradigm for graph representation learning [22, 23, 26, 27]. SSL models over graphs mainly mine self-supervision signals by exploiting the graph structure. The dominant regime of this line of research is graph contrastive learning which contrasts multiple views of the same graph where the incongruent views are built by conducting stochastic augmentations on the raw graph [9, 23, 27, 40]. The common types of stochastic augmentations include but are not limited to uniform node/edge dropout, random feature/attribute shuffling, and subgraph sampling using random walk.
(自监督学习(SSL)是一种新兴的范式,可以通过自动从原始数据中生成的真实样本进行学习。它首先被用于视觉表示学习和语言建模进行模型预训练。SSL的最新进展试图利用这种灵活的学习范式来进行图表示学习。图上的SSL模型主要是利用图的结构来挖掘自监督信号。这一研究方向的主要机制是图对比学习,它对比了同一个图的多个视图,其中不一样的视图是通过对原始图进行随机增强来建立的。常见的随机增强类型包括但不限于节点/边dropout、随机特征/属性变换和使用随机游走的子图采样。 -
(2)Inspired by the success of graph contrastive learning, there have been some recent works [19, 29, 37, 46] which transplant the same idea to the scenario of recommendation. (受图对比学习成功的启发,最近有一些工作将同样的想法移植到推荐的场景中)
- Zhou et al. [46] devise auxiliary self-supervised objectives by randomly masking attributes of items and skipping items and subsequences of a given sequence for pretraining sequential recommendation model. (Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization通过随机屏蔽项目的属性、跳过给定序列的项目和子序列来设计辅助的自监督目标,用于预训练顺序推荐模型。)
- Yao et al. [37] propose a two-tower DNN architecture with uniform feature masking and dropout for self-supervised item recommendation. (姚等人。[37]提出了一种具有统一特征掩蔽和丢弃的双塔DNN架构,用于自我监督的项目推荐)
- Maet al.[19] mine extra signals for supervision by looking at the longer-term future and reconstruct the future sequence for self-supervision, which adopts feature masking in essence. (马氏等人。[19]通过观察长远的未来,挖掘额外的信号进行监控,重建未来的自我监控序列,本质上采用了特征掩蔽)
- Wu et al. [29] summarize all the stochastic augmentations on graphs and unify them into a general self-supervised graph learning framework for recommendation. (吴等人。[29]总结了图上所有的随机增强,并将其统一为一个一般的自监督图学习框架进行推荐。)
- Besides, there are also some studies [25, 36, 44] refining user representations with mutual information maximization among a set of certain members (e.g. ad hoc groups) for self-supervised recommendation. However, these methods are used for specific situations and cannot be easily generalized to other scenarios. (此外,还有一些研究在集合间的互信息最大化来细化用户表示。
3 PROPOSED FRAMEWORK
In this section, we present our SElf-suPervised Tri-training framework, called SEPT, with the goal of mining self-supervision signals from other users by the multi-view encoding. The overview of SEPT is illustrated in Fig. 1.
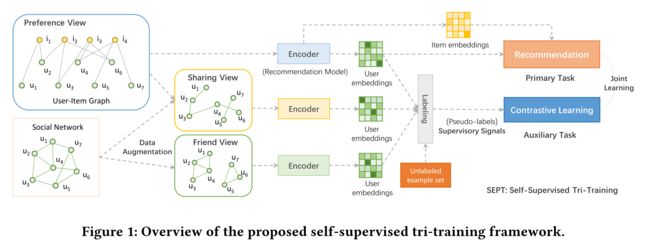
3.1 Preliminaries
3.1.1 Notations.
- In this paper, we use two graphs as the data sources including the user-item interaction graph G r \mathcal{G}_r Gr and the user social network G s \mathcal{G}s Gs.
- U = { u 1 , u 2 , . . . , u m } ( ∣ U ∣ = m ) \mathcal{U} = \{u_1, u_2, ..., u_m\} (|\mathcal{U}| = m) U={u1,u2,...,um}(∣U∣=m) denotes the user nodes across both G r \mathcal{G}r Gr and G s \mathcal{G}s Gs,
- and I = i 1 , i 2 , . . . , i n ( ∣ I ∣ = n ) \mathcal{I} = {i1,i2, ...,in} (|\mathcal{I}| = n) I=i1,i2,...,in(∣I∣=n) denotes the item nodes in G r \mathcal{G}r Gr.
- As we focus on item recommendation, R ∈ R m × n R \in R^{m\times n} R∈Rm×n is the binary matrix with entries only 0 and 1 that represent user-item interactions in G r \mathcal{G}r Gr.
- For each entry ( u , i ) (u,i) (u,i) in R R R, if user u u u has consumed/clicked item i i i, r u i = 1 r_{ui} = 1 rui=1, otherwise r u i = 0 r_{ui} = 0 rui=0.
- As for the social relations, we use S ∈ R m × m S ∈ R^{m\times m} S∈Rm×m to denote the social adjacency matrix which is binary and symmetric because we work on undirected social networks with bidirectional relations.
- We use P ∈ R m × d P \in R^{m\times d} P∈Rm×d and Q ∈ R n × d Q \in R^{n\times d} Q∈Rn×d to denote the learned final user and item embeddings for recommendation, respectively.
- To facilitate the reading, in this paper, matrices appear in bold capital letters and vectors appear in bold lower letters.
3.1.2 Tri-Training.
- Tri-training [47] is a popular semi-supervised learning algorithm which develops from the co-training paradigm [3] and tackles the problem of determining how to label the unlabeled examples to improve the classifiers. (Tri-Training是一种流行的半监督学习算法,它从co-training范式发展而来,解决了确定如何标记无标签数据以改进分类器的问题。)
- In contrast to the standard co-training algorithm which ideally requires two sufficient, redundant and conditionally independent views of the data samples to build two different classifiers, tri- training is easily applied by lifting the restrictions on training sets. (与标准的co-training算法在理想情况下需要两个足够的、冗余的和有条件独立的数据样本视图来构建两个不同的分类器相比,通过解除对训练集的限制,可以很容易地使用 Tri-Training。)
- It does not assume sufficient redundancy among the data attributes, and initializes three diverse classifiers upon three different data views generated via bootstrap sampling [6]. (它不假设数据属性之间有足够的冗余,并通过引导抽样在生成的三个不同的数据视图上初始化三个不同的分类器。)
- Then, in the labeling process of tri-training, for any classifier, an unlabeled example can be labeled for it as long as the other two classifiers agree on the labeling of this example. The generated pseudo-label is then used as the ground-truth to train the corresponding classifier in the next round of labeling. (然后,在 Tri-Training的标记过程中,对于任何一个分类器,只要其他两个分类器对这个例子的标记达成一致,就可以对一个未标记的例子进行标记。然后将生成的伪标签作为真实值,在下一轮标记中训练相应的分类器。)
3.2 Data Augmentation
3.2.1 View Augmentation.
-
(1) As has been discussed, there is widely observed homophily in recommender systems. Namely, users and items have many similar counterparts. (正如所讨论的,在推荐系统中存在广泛的同质性。也就是说,用户和项目有许多相似的对应物。)
- To capture the homophily for self-supervision, we exploit the user social relations for data augmentation as the social network is often known as a reflection of homophily [20, 39] (i.e., users who have similar preferences are more likely to become connected in the social network and vice versa). (为了获取自监督的同质性,我们利用用户的社交关系来增强数据,因为社交网络通常被称为同质性的反映。(即,有相似偏好的用户更有可能在社交网络中建立联系,反之亦然))
- Since many service providers such as Yelp1 encourage users to interact with others on their platforms, it provides their recommender systems with opportunities to leverage abundant social relations. However, as social relations are inherently noisy [41, 43], for accurate supplementary supervisory information, SEPT only utilizes the reliable social relations by exploiting the ubiquitous triadic closure [13] among users. (由于许多像Yelp这样的服务提供商鼓励用户在其平台上与他人互动,它为他们的推荐系统提供了利用丰富的社交关系的机会。然而,由于社会关系本质上是有噪声的,对于准确的补充监督信息,SEPT仅利用 用户中普遍存在的三元闭合 来使用可靠的社交关系。)
- In a socially-ware recommender system, by aligning the user-item interaction graph G r \mathcal{G}_r Gr and the social network G s \mathcal{G}_s Gs, we can readily get two types of triangles: three users socially connected with each other (e.g.u1,u2andu4in Fig. 1) and two socially connected users with the same purchased item (e.g. u1,u2and i1in Fig. 1). The former is socially explained as profiling users’ interests in expanding social circles, and the latter is characterizing users’ interests in sharing desired items with their friends. It is straightforward to regard the triangles as strengthened ties because if two persons in real life have mutual friends or common interests, they are more likely to have a close relationship. (在社交软件推荐系统中,通过对齐用户-项目交互图 G r \mathcal{G}_r Gr 和社交网络 G s \mathcal{G}_s Gs,我们可以很容易地得到两种三角形:三个用户之间的社交联系(如图1中的1、2和4)和两个购买相同项目的社交联系用户(如图1中的1、2和1)。前者被解释为描述用户在扩充社交圈中的兴趣,后者是描述用户对他的朋友分享物品的兴趣。直接认为三角形是加强的联系,因为如果现实生活中的两个人有共同的朋友或共同的利益,他们更有可能有亲密的关系。) 这个做法,其实是沿用了作者们的上一篇文章,MHCN模型中的那10个三角形
-
(2) Following our previous work [44], the mentioned two types of triangles can be efficiently extracted in the form of matrix multiplication. Let A f ∈ R m × m A_f \in R^{m\times m} Af∈Rm×m and A s ∈ R m × m A_s \in R^{m\times m} As∈Rm×m denote the adjacency matrices of the users involved in these two types of triangular relations. They can be calculated by: (根据我们之前的工作(MHCN),上述两种三角形可以有效地提取为矩阵乘法的形式, 表示包含这两种三角关系的用户邻接矩阵。它们可通过以下方法进行计算:)

-
(3) The multiplication S S ( R R ⊤ ) SS (RR^{\top}) SS(RR⊤) accumulates the paths connecting two user via shared friends (items), and the **Hadamard product ⊙ S \odot S ⊙S makes these paths into triangles.
- Since both S S S and R R R are sparse matrices, the calculation is not time-consuming.
- The operation ⊙ S \odot S ⊙S ensures that the relations in A f A_f Af and A s A_s As are subsets of the relations in S S S.
- As A f A_f Af and A s A_s As are not binary matrices, Eq. (1) can be seen a special case of bootstrap sampling on S S S with the complementary information from R R R.
- Given A f A_f Af and A s A_s As as the augmentation of S S S and R R R, we have three views that characterize users’ preferences from different perspectives and also provide us with a scenario to fuse ri-training and SSL. To facilitate the understanding, we name (我们有三个视图从不同的角度来描述用户的偏好,也为我们提供了一个融合tri-training和SSL的场景)
- the view over the user-item interaction graph preference view,
- the view over the triangular social relations friend view,
- and another one sharing view,
- which are represented by R, Af, and As, respectively.
3.2.2 Unlabeled Example Set.
- To conduct tri-training, an unlabeled example set is required. We follow existing works [29,40] to perturb the raw graph with edge dropout at a certain probability ρ \rho ρ to create a corrupted graph from where the learned user presentations are used as the unlabeled examples. This process can be formulated as: (要进行tri-training,需要一个无标签样本集。我们遵循现有的工作,以概率对原始图进行边dropout,创建一个被干扰的图,从中学习的用户表示被用作无标签的样本。此过程可表述为:) (无标签的数据是怎么来的)

- where N r N_r Nr and N s N_s Ns are nodes,
- E r Er Er and E s Es Es are edges in G r Gr Gr and G s Gs Gs,
- and m ∈ { 0 , 1 } ∣ E r ∪ E s ∣ m \in \{0,1\} ^{| Er\cup Es|} m∈{0,1}∣Er∪Es∣is the masking vector to drop edges.
- Herein we perturb both G r Gr Gr and G s Gs Gs instead of G r Gr Gr only, because the social information is included in the aforementioned two augmented views. (在这里,我们同时干扰 G G Gr和 G G Gs,而不是只干扰G,因为社交信息包含在上述两个增强视图中)
- For integrated self-supervision signals, perturbing the joint graph is necessary. (对于集成的自监督信号,扰动连接图是必要的。)
3.3 SEPT: Self-Supervised Tri-Training
3.3.1 Architecture.
- With the augmented views and the unlabeled example set, we follow the setting of tri-training to build three encoders. Architecturally, the proposed self-supervised training framework can be model-agnostic so as to boost a multitude of graph neural recommendation models. But for a concrete framework which can be easily followed, we adopt LightGCN [11] as the basic structure of the encoders due to its simplicity. The general form of encoders is defined as follows: (使用增强视图和无标签的样本集,我们遵循Tri-Training的设置来构建三个编码器。在结构上,所提出的自监督训练框架可以与模型无关,从而促进大量的图神经推荐模型。 但对于一个易于遵循的具体框架,由于其简单性,我们采用了LightGCN作为编码器的基本结构。编码器的一般形式的定义如下:

- where H H H is the encoder,
- Z ∈ R m × d Z \in R^{m\times d} Z∈Rm×d or R ( m + n ) × d R^{(m+n)\times d} R(m+n)×d denotes the final representation of nodes,
- E E E of the same size denotes the initial node embeddings which are the bottom shared by the three encoders,
- and V ∈ { R , A s , A f } \mathcal{V} \in \{R,A_s,A_f\} V∈{R,As,Af} is any of the three views.
- It should be noted that, unlike the vanilla tri-training, SEPT is asymmetric. (需要注意的是,与普通的tri-training不同,SEPT是不对称的)
- The two encoders H f Hf Hf and H s Hs Hs that work on the friend view and sharing view are only in charge of learning user representations through graph convolution and giving pseudo-labels, while the encoder Hrworking on the reference view also undertakes the task of generating recommendations and thus learns both user and item representations (shown in Fig. 1). (两个编码器和工作在朋友视图、分享视图上,只负责通过图卷积学习用户表示给出伪标签,而编码器工作在偏好视图上,承担生成推荐的任务,从而学习用户和项目表示(如图1所示))
- Let H r Hr Hr be the dominant encoder (recommendation model), and H f Hf Hf and H s Hs Hs be the auxiliary encoders. Theoretically, given a concrete H r Hr Hr like LightGCN [11], there should be the optimal structures of H f Hf Hf and H s Hs Hs. (设为主编码器(推荐模型),和为辅助编码器。理论上,给定像LightGCN这样的具体,应该有和的最优结构。)
- However, exploring the optimal structures of the auxiliary encoders is out of the scope of this paper. For simplicity, we assign the same structure to H f Hf Hf and H s Hs Hs. Besides, to learn representations of the unlabeled examples from the perturbed graph G ~ \tilde{G} G~, another encoder is required, but it is only for graph convolution. All the encoders share the bottom embeddings E E E and are built over different views with the LightGCN structure. (然而,探索辅助编码器的最优结构超出了本文的范围。为简单起见,我们将相同的结构分配给和。此外,为了从扰乱的图˜G中学习无标签样本的表示,需要另一个编码器,但只做图卷积。 所有的编码器都共享初始嵌入,并使用LightGCN结构在不同的视图上构建编码器。)
3.3.2 Constructing Self-Supervision Signals.
-
(1) By performing graph convolution over the three views, the encoders learn three groups of user representations. As each view reflects a different aspect of the user preference, it is natural to seek supervisory information from the other two views to improve the encoder of the current view. Given a user, we predict its semantically positive examples in the unlabeled example set using the user representations from the other two views. Taking user u u u in the preference view as an instance, the labeling is formulated as: (通过在这三个视图上进行图卷积,编码器学习了三组用户表示。由于每个视图都反映了用户偏好的不同方面,因此从其他两个视图中寻求监督信息,以改进当前视图的编码器。给定一个用户,我们使用来自其他两个视图的用户表示来预测它在无标签样本集中的语义上的正样本。以偏好视图中的用户为例子,表述为:
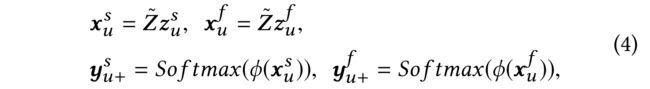
- where ϕ \phi ϕ is the cosine operation,
- z u s z^s_u zus and z u f z^f_u zuf are the representations of user u u u learned by H s H_s Hs and H f H_f Hf, respectively,
- Z ~ \tilde{Z} Z~ is the representations of users in the unlabeled example set obtained through graph convolution, (通过图卷积得到的无标签样本集中用户的表示)
- and y u + s y^s_{u+} yu+s and y u + f y^f_{u+} yu+f denote the predicted probability of each user being the semantically positive example of user u u u in the corresponding views. (每个用户在相应视图中为用户的语义正样本的预测概率。)
-
(2) Under the scheme of tri-training, to avoid noisy examples, only if both H s H_s Hs and H f H_f Hf agree on the labeling of a user being the positive sample, and then the user can be labeled for H r H_r Hr. We obey this rule and add up the predicted probabilities from the two views and obtain: (在 tri-training方案下,为了避免噪声样本,只有和都同意将用户标记为正样本,才能在将用户进行标记。) (我们遵循这一规则,并将从这两个视图中得到的预测概率加起来,得到:)

-
(3) With the probabilities, we can select K K K positive samples with the highest confidence. This process can be formulated as: (根据这些概率,我们可以选择可信度最高的个正样本。此过程可表述为:)

-
(4) In each iteration, G ~ \tilde{\mathcal{G}} G~ is reconstructed with the random edge dropout for varying user representations. (在每次迭代中,通过随机边dropout进行 G ~ \tilde{\mathcal{G}} G~的重构,生成不同的用户表示。)
- SEPT dynamically generates positive pseudo-labels over this data augmentation for each user in every view. (SEPT在每个视图中为每个用户在数据增强中动态的生成正向伪标签)
- Then these labels are used as the supervisory signals to refine the shared bottom representations. (然后,这些标签被用作监督信号来定义初始的底部表示。)
3.3.3 Contrastive Learning.
-
(1) Having the generated pseudo-labels, we develop the neighbor-discrimination contrastive learning method to fulfill self-supervision in SEPT. (通过生成的伪标签,我们开发了邻居识别对比学习方法来实现SEPT中的自监督)
-
(2) Given a certain user,
- we encourage the consistency between his node representation and the labeled user representations from P u + \mathcal{P}_{u+} Pu+, (我们鼓励(应该就是最大化)他的节点表示和来自 P u + \mathcal{P}_{u+} Pu+,的标记用户表示之间的一致性)
- and minimizing the agreement between his representation and the unlabeled user representations. (最小化他的表示和未标记的用户表示之间的一致性。)
- The idea of the neighbor-discrimination is that, given a certain user in the current view, (最小化他的表示和未标记的用户表示之间的一致性。)
- the positive pseudo-labels semantically represent his neighbors or potential neighbors in the other two views, then we should also bring these positive pairs together in the current view due to the homophily across different views. And this can be achieved through the neighbor-discrimination contrastive learning. (在当前视图中给定确定的用户,在其他两个视图中正向的伪标签在语义上表示它的邻居或潜在的邻居,由于不同视图的同质性,那么我们也应该把这些正对放到当前视图中。这可以通过邻居辨别对比学习来实现)
- Formally, we follow the previous studies [5, 29] to adopt InfoNCE [12], which is effective in mutual information estimation, as our learning objective to maximize the agreement between positive pairs and minimize that of negative pairs: (形式上,我们遵循之前的研究,采用在互信息估计中有效的InfoNCE作为我们的学习目标,以最大化正对之间的一致性,最小化负对之间的一致性:)

- where ψ ( z v U u , z ~ p ) = e x p ( ϕ ( z u v ⋅ z ~ p ) τ ) \psi(z^vUu, \tilde{z}_p) = exp(\phi(z^v_u· \tilde{z}_p)\tau ) ψ(zvUu,z~p)=exp(ϕ(zuv⋅z~p)τ)
- ϕ ( ⋅ ) : R d × R d ⟼ R \phi(\cdot) : R^d \times R^d \longmapsto R ϕ(⋅):Rd×Rd⟼R is the discriminator function that takes two vectors as the input and then scores the agreement between them, (是一个辨别器函数,它输入两个向量,预估它们之间的一致性)
- and τ \tau τ is the temperature to amplify the effect of discrimination ( τ \tau τ = 0.1 is the best in our implementation). (是为了放大辨别效果的温度系数(在我们的实现中,=0.1是最佳的效果))
- We simply implement the discriminator by applying the cosine operation. (我们可以简单地通过应用余弦操作来实现辨别器)
- Compared with the self-discrimination, the neighbor-discrimination leverages the supervisory signals from the other users. (与自辨别器相比,邻居辨别器利用了来自其他用户的监控信号。)
- When only one positive example is used and if the user itself in Z ~ \tilde{Z} Z~ has the highest confidence in y u + y_{u+} yu+, the neighbor-discrimination degenerates to the self-discrimination. So, the self-discrimination can be seen as a special case of the neighbor-discrimination. (当只使用一个正样本,并且如果在 + _{+} yu+ 中用户自身 Z ~ \tilde{Z} Z~的得分最高时,邻居辨别器就会退化为自辨别器。因此,自辨别器可以看作是邻居辨别器的一种特例。 )
- But when a sufficient number of positive examples are used, these two methods could also be simultaneously adopted because the user itself in Z ~ \tilde{Z} Z~ is often highly likely to be in the Top-K similar examples P u + \mathcal{P}_{u+} Pu+. With the training proceeding, the encoders iteratively improve to generate evolving pseudo-labels, which in turn recursively benefit the encoders again. (但是,当使用足够数量的正样本时,这两种方法也可以同时被采用,因为 Z ~ \tilde{Z} Z~中的用户本身通常很可能在Top-K类似的示例 P + P_{+} Pu+中。随着训练过程的进行,编码器不断改进,生成不断演化的伪标签,进而递归地使编码器再次受益。)
-
(3) Compared with the vanilla tri-training, it is worth noting that in SEPT, we do not add the pseudo-labels into the adjacency matrices for subsequent graph convolution during training. Instead, we adopt a soft and flexible way to guide the user representations via mutual information maximization, which is distinct from the vanilla tri-training that adds the pseudo-labels to the training set for next-round training. The benefits of this modeling are two-fold. Firstly, adding pseudo-labels leads to reconstruction of the adjacency matrices after each iteration, which is time-consuming; secondly, the pseudo-labels generated at the early stage might not be informative; repeatedly using them would mislead the framework.
与普通的tri-training相比,值得注意的是,在SEPT中,我们没有将伪标签添加到邻接矩阵中,用于后续的图卷积。相反,我们采用了一种灵活的方式,通过互信息最大化来指导用户表示,这不同于普通的tri-training训练,后者将伪标签添加到训练集中,以进行进一步的循环训练。这种建模的好处是有两方面的。首先,添加伪标签会导致每次迭代后重建邻接矩阵,这很耗时;其次,早期生成的伪标签可能没有信息;重复使用它们会误导框架。
3.3.4 Optimization.
- (1) The learning of SEPT consists of two tasks:
- recommendation (推荐)
- and the neighbor-discrimination based contrastive learning. (基于邻居辨别的对比学习)
- (2) Let L r \mathcal{L}_r Lr be the BPR pairwise loss function [24] which is defined as:

- where I ( u ) \mathcal{I}(u) I(u) is the item set that user u u u has interacted with,
- r ^ u i = P u ⊤ Q i \hat{r}_{ui} = P^{\top}_u Q_i r^ui=Pu⊤Qi, P P P and Q Q Q are obtained by splitting Z r Z^r Zr,
- and λ \lambda λ is the coefficient controlling the L 2 L_2 L2 regularization.
- (2) The training of SEPT proceeds in two stages:
- initialization and
- joint learning.
- To start with, we warm up the framework with the recommendation task by optimizing L r L_r Lr. (首先,我们通过优化 L L_ Lr 的推荐任务来初始化框架)
- Once trained with L r Lr Lr, the shared bottom E E E has gained far strong errepresentations than randomly initialized embeddings. The self-supervised tri-training then proceeds as described in Eq. (4) - (7), ( 一旦通过 L r L_r Lr训练,共享的底部比随机初始化的嵌入获得了更强的表示能力。然后,自监督tri-training如公式(4)-(7)中所述进行)
- acting as an auxiliary task which is unified into a joint learning objective to enhance the performance of the recommendation task. The overall objective of the joint learning is defined as:。辅助任务与主要任务被合并为联合学习目标,提高推荐任务的性能。联合学习的总体目标被定义为:

- where β \beta β is a hyper-parameter used to control the magnitude of the self-supervised tri-training. The overall process of SEPT is presented in Algorithm 1. (其中是一个超参数,用来控制self-supervised tri-training的大小。算法1给出了SEPT的总体过程。)

- where β \beta β is a hyper-parameter used to control the magnitude of the self-supervised tri-training. The overall process of SEPT is presented in Algorithm 1. (其中是一个超参数,用来控制self-supervised tri-training的大小。算法1给出了SEPT的总体过程。)
3.4 Discussions
3.4.1 Connection with Social Regularization.
- (1) Social recommendation [38, 43, 44] integrates social relations into recommender systems to address the data sparsity issue. A common idea of social recommendation is to regularize user representations by minimizing the euclidean distance between socially connected users, which is termed social regularization [18]. (社会推荐将社会关系集成到推荐系统中,以解决数据稀疏性问题。社交推荐的一个常见思想是通过最小化社会连接用户之间的欧氏距离来规范用户表示,这被称为社会正则化)
- (2) Although the proposed SEPT also leverages socially-aware supervisory signals to refine user representations, it is distinct from the social regularization. The differences are also two-fold. (尽管提出的SEPT也利用了社交-感知监督信号来完善用户表示,它不同于社会的正则化。有两方面的差异)
- Firstly, the social regularization is a static process which is always performed on the socially connected users, whereas the neighbor-discrimination is dynamic and iteratively improves the supervisory signals imposed on uncertain users; (首先,社交正则化是一个静态的过程,它总是作用在有社会关联的用户上,而邻居辨别是动态的,并且迭代地改进对不确定用户施加监督信号)
- secondly, negative social relations (dislike) cannot be readily retrieved in social recommendation, and hence the social regularization can only keep socially connected users close. But SEPT can also pushes users who are not semantically positive in the three views apart. (其次,负面的社会关系(不喜欢)不能在社会推荐中被轻易地检索到,因此社交正规化只能使有社会联系的用户保持接近。但SEPT也可以将那些在三种视图中语义不正向的用户分开。
3.4.2 Complexity.
- (1) Architecturally, SEPT can be model-agnostic, and its complexity mainly depends on the structure of the used encoders. In this paper, we present a LightGCN-based architecture. Given O ( ∣ R ∣ d ) O(|R|d) O(∣R∣d) as the time complexity of the recommendation encoder for graph convolution, the total complexity for the graph convolution is less than 3 O ( ∣ R ∣ d ) 3O(|R|d) 3O(∣R∣d) because A f A_f Af and A s A_s As are usually sparser than R R R. The prime cost of the labeling process comes from the Top-K operation in ==Eq. (6), which usually requires O ( m l o g ( K ) ) O(mlog(K)) O(mlog(K)) by using the max heap. To reduce the cost and speed up training, in each batch for training, only c (c ≪ m, e.g. 1000) users in a batch are randomly selected and being the unlabeled example set of the pseudo-labels, and this sampling method can also prevent overfitting. The complexity of the neighbor-discrimination based contrastive learning is O ( c d ) O(cd) O(cd).
在结构上,SEPT可以是与模型无关的,其复杂性主要取决于所使用的编码器的结构。在本文中,我们提出了一个基于LightGCN的结构。给定O(||)作为图卷积的推荐编码器的时间复杂度,图卷积的总复杂度小于4O(||),因为、和˜G通常比R更稀疏。另一个成本来自于等式(6)中标记过程的Top-K操作,通过使用最大堆,它通常需要O(log())。为了降低成本,加快训练速度,在每批训练中,一批随机选择个(≪,如1000)用户作为伪标签的无标签样本集,这种采样方法也可以防止过拟合。基于邻居辨别的对比学习的复杂度为O()。
4 EXPERIMENTAL RESULTS
4.1 Experimental Settings
4.1.1 Datasets.
- Three real-world datasets: Last.fm2, Douban-Book3, and Yelp4 are used in our experiments to evaluate SEPT. As SEPT aims to improve Top-N recommendation, we follow the convention in previous research [43, 44] to leave out ratings less than 4 in the dataset of Douban-Book which consists of explicit ratings with a 1-5 rating scale, and assign 1 to the rest. The statistics of the datasets is shown in Table 1. For precise assessment, 5-fold cross-validation is conducted in all the experiments and the average results are presented. (三个真实的数据集:Last.fm,Douban-Book和Yelp在我们的实验中用来评估SEPT。SEPT旨在改进Top-N推荐,Douban-Book数据集包含1-5的评分,我们遵循之前研究的惯例,在豆瓣的数据集中省略小于4的评分,其余的赋值为1。数据集的统计数据如表1所示。为了进行精确的评估,对所有的实验都进行了5倍交叉验证,并给出了平均结果。

4.1.2 Baselines.
-
(1) Three recent graph neural recommendation models are compared with SEPT to test the effectiveness of the self-supervised tri-training for recommendation: (将三种最近的图神经推荐模型与SEPT进行比较,以检验 self-supervised tri-training推荐的有效性:)
- LightGCN [11] is a GCN-based general recommendation model that leverages the== user-item proximity to learn node representations== and generate recommendations, which is reported as the state-of-the-art. (LightGCN是一个基于GCN的通用推荐模型,它利用用户-项目的接近程度来学习节点表示并生成推荐,这被报告是最先进的方法。)
- DiffNet++ [30] is a recent GCN-based social recommendation method that models the recursive dynamic social diffusion in both the user and item spaces. (DiffNet++是最新的一种基于GCN的社会推荐方法,它模拟了用户和项目空间中的递归动态社交扩散。)
- MHCN [44] is a latest hypergraph convolutional network-based social recommendation method that models the complex correlations among users with hyperedges to improve recommendation performance. (MHCN是一种最新的基于超图卷积网络的社交推荐方法,它用超边形成用户之间的复杂相关性,以提高推荐性能。)
-
(2) LightGCN [11] is the basic encoder in SEPT. Investigating the performance of LightGCN and SEPT is essential. Since LightGCN is a widely acknowledged SOTA baseline reported in many recent papers [29, 44], we do not compare SEPT with other weak baselines such as NGCF [28], GCMC [2], and BPR [24]. Two strong social recommendation models are also compared to SEPT to verify that the self-supervised tri-training, rather than the use of social relations, is the main driving force of the performance improvements. (LightGCN是SEPT中的基本编码器。研究LightGCN和SEPT的性能至关重要。由于LightGCN是最近许多论文中报道的一个广泛公认的SOTA基线,我们没有将SEPT与其他弱基线如NGCF、GCMC和BPR进行比较。两种强的社交推荐模型也与SEPT进行了比较,以证明使用社交关系不是性能改进的主要驱动力。
4.1.3 Metrics.
- To evaluate all the methods, we first perform item ranking on all the candidate items. Then two relevancy-based metrics Precision@10 and Recall@10 and one ranking-based metric NDCG@10 are calculated on the truncated recommendation lists, and the values are presented in percentage. (为了评估所有的方法,我们首先对所有的候选项目进行项目排序。然后是两个基于相关性的指标,Precision@10和Recall@10,以及一个基于排名的指标NDCG@10。)
4.1.4 Settings.
- For a fair comparison, we refer to the best parameter settings reported in the original papers of the baselines and then fine tune all the hyperparameters of the baselines to ensure the best performance of them. As for the general settings of all the methods, we empirically set the dimension of latent factors (embeddings) to 50, the regularization parameter λ \lambda λ to 0.001, and the batch size to 2000. In section 4.4, we investigate the parameter sensitivity of SEPT, and the best parameters are used in section 4.2 and 4.3. We use Adam to optimize all these models with an initial learning rate 0.001. (为了进行公平的比较,我们参考基线原始论文中报告的最佳参数设置,然后微调基线的所有超参数,以确保它们的最佳性能。对于所有方法的一般设置,我们将潜在因素(嵌入)的维数设置为50,正则化参数设置为0.001,批处理大小设置为2000。在第4.4节中,我们研究了SEPT的参数敏感度,并在第4.2节和第4.3节中使用了最佳参数。我们使用Adam来优化所有这些模型,初始学习率为0.001。
4.2 Overall Performance Comparison
-
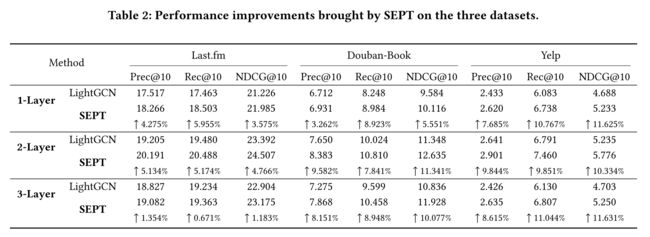
(1) In this part, we validate if SEPT can improve recommendation. The performance comparisons are shown in Table 2 and 3. We conduct experiments with different layer numbers in Table 2. In Table 3, a two-layer setting is adopted for all the methods because they all reach their best performance on the used datasets under this setting. The performance improvement (drop) marked by ↑ (↓) is calculated by using the performance difference to divide the subtrahend. According to the results, we can draw the following observations and conclusions: (在这部分中,我们验证了SEPT是否可以改进推荐。性能比较如表2和表3所示。我们在表2中使用不同的层数进行了实验。在表3中,所有方法都采用了两层设置,因为它们在此设置下在所使用的数据集上都达到了最好的性能。↑(↓)标记的性能提升(下降)是通过使用性能差除分来计算的。根据研究结果,我们可以得出以下观察结果和结论:

-
Under all the different layer settings, SEPT can significantly boost LightGCN. Particularly, on the sparser datasets: Douban-Book and Yelp, the improvements get higher. The maximum improvement can even reach 11%. This can be an evidence that demonstrates the effectiveness of self-supervised learning. Besides, although both LightGCN and SEPT suffer the over-smoothed problem when the layer number is 3, SEPT can still outperform LightGCN. We think the possible reason is that contrastive learning can, to some degree, alleviate the over-smooth problem because the dynamically generated unlabeled examples provide sufficient data variance. (在所有不同的图层设置下,SEPT可以显著提高LightGCN。特别是在更稀疏的数据集上(Douban-Book和Yelp),提升更大。最大的改进甚至可以达到11%。这可以是证明自监督学习有效性的一个证据。此外,虽然当层数为3时,LightGCN和SEPT都存在过平滑的问题,但SEPT的性能仍然优于LightGCN。我们认为可能的原因是,对比学习可以在一定程度上缓解过平滑的问题,因为动态生成的无标签的样本提供了足够的数据方差。
-
(2) In addition to the comparison with LightGCN, we also compare SEPT with social recommendation models to validate if the self-supervised tri-training rather than social relations primarily promote the recommendation performance. Since MHCN is also built upon LightGCN, comparing these two models can be more informative. Besides, S2-MHCN, which is the self-supervised variant of MHCN is also ompared. The improvements (drops) are calculated by comparing the results of SEPT and S2-MHCN. According to the results in Table 3, we make the following observations and conclusions: (除了与LightGCN进行比较外,我们还将SEPT与社会推荐模型进行了比较,以验证 selfsupervised tri-training主要不是因为社会关系提升了推荐性能。由于MHCN也建立在LightGCN之上,因此比较这两种模型可以提供更多的信息。此外,2-MHCN是MHCN自监督的变体,通过比较SEPT和2-MHCN的结果,计算了性能提升(下降)。根据表3中的结果,我们有以下观察和结论:)
-
(3) Although integrating social relations into graph neural models are helpful (comparing MHCN with LightGCN), learning under the scheme of SEPT can achieve more performance gains (comparing SEPT with MHCN). DiffNet++ is uncompetitive compared with the other three methods. Its failure can be attributed to its redundant and useless parameters and operations [11]. On both LastFM and Douban-Book, SEPT outperformsS2-MHCN. On Yelp, S2-MHCN exhibits better performance than SEPT does. The supe- riority of SEPT and S2-MHCN demonstrates that self-supervised learning holds vast capability for improving recommendation. In addition, SEPT does not need to learn other parameters except the bottom embeddings, whereas there are a number of other parameters thatS2-MHCN needs to learn. Meanwhile, SEPT runs much faster than S2-MHCN does in our experiments, which makes it more competitive even that it is beaten by S2-MHCN on Yelp by a small margin. (虽然将社会关系整合到图神经模型中是有帮助的(比较MHCN和LightGCN),但在SEPT方案下的学习可以获得更多的性能提高(比较SEPT和MHCN)。DiffNet++与其他三种方法相比没有竞争力。它的失败可以归因于其冗余和无用的参数和操作。在LastFM 和 Douban-Book上,SEPT的表现都优于2-MHCN。在Yelp上,2-MHCN的 。比SEPT更好。SEPT和2-MHCN的优越性表明,自监督学习具有巨大的提升推荐的能力。此外,SEPT不需要学习除了底部嵌入之外的其他参数,而2-MHCN还需要学习许多其他参数。与此同时,SEPT的运行速度比2-MHCN快得多,这使得它更具竞争力,即使它在Yelp上被2-MHCN小幅度击败。
4.3 Self-Discrimination v.s.Neighbor-Discrimination
- In SEPT, the generated positive examples can include both the user itself and other users in the unlabeled example set. It is not clear which part contributes more to the recommendation performance. In this part, we investigate the self-discrimination and the neighbor- discrimination without the user itself being the positive example. For convenience, we use SEPT-SD to denote the self-discrimination, and SEPT-ND to denote the latter. It also should be mentioned that, for SEPT-ND only, a small β \beta β = 0.001 can lead to the best performance on all the datasets. A two-layer setting is used in this case. (在SEPT中,生成的正样本可以包括用户本身和无标签样本集的其他用户。目前还不清楚是哪一部分对推荐性能的贡献更大。在这部分中,我们研究了在没有用户本身的情况下,自我辨别和邻居辨别。为方便起见,我们使用SEPT-SD表示自我辨别,使用SEPT-ND表示邻居辨别。还应该提到的是,仅对于SEPT-ND,=0.001可以在所有数据集上获得最好的性能。在本例中使用了两层设置

- (2) According to Fig. 2, we can observe that both SEPT-SD and SEPTND exhibit better performances than LightGCN does, which proves that both the supervisory signals from the user itself and other users can benefit a self-supervised recommendation model. Our claim about the self-supervision signals from other users is validated. Besides, the importance of the self-discrimination and the neighbor-discrimination varies from dataset to dataset. On LastFM, they almost contribute equally. On Douban-Book, self-discrimination shows much more importance. On Yelp, neighbor-discrimination is more effective. ((根据图2,我们可以观察到,SEPT-SD和SEPT-ND都表现出比LightGCN更好的性能,这证明了来自用户本身和其他用户的监督信号都可以受益于自监督推荐模型。我们认为来自其他用户的自监督信号的想法得到了验证。此外,自我辨别和邻居辨别的重要性也因数据集而异。在LastFM上,他们的贡献几乎相同。在 Douban-Book上,自我辨别表现得更为重要。在Yelp上,邻居辨别更有效。)
- (3)This phenomenon can be explained by Fig. 5. With the increase of the used positive examples, we see that the performance of SEPT almost remains stable on LastFM and Yelp but gradually declines on Douban-Book. We guess that there is widely observed homophily in LastFM and Yelp, so a large number of users share similar preferences, which can be the high-quality positive examples in these two datasets. However, users in Douban-Book may have more diverse interests, which results in the quality drop when the number of used positive examples increases. (这种现象可以用图5来解释。随着正例的增加,我们看到SEPT在LastFM和Yelp上的表现几乎保持稳定,但在Douban-Book上逐渐下降。我们推测在LastFM和Yelp中存在广泛观察到的同质性,因此大量用户具有相似的偏好,这可能是这两个数据集中高质量的正例。然而,Douban-Book的用户可能会有更多样化的兴趣,当使用的正面例子数量增加时,就会导致性能下降。)
4.4 View Study
- (1) In SEPT, we build two augmented views to conduct tri-training for mining supervisory signals. In this part, we ablate the framework to investigate the contribution of each view. A two-layer setting is used in this case. In Fig. 3, ‘Friend’ or ‘Sharing’ means that the corresponding view is detached. When only two views are used, SEPT degenerates to the self-supervised co-training. ‘Preference Only’ means that only the preference view is used. In this case, SEPT further degenerates to the self-training. (在SEPT中,我们构建了两个增强视图来对挖掘监控信号进行tri-training。在这部分中,我们研究每个视图的贡献。在本研究中使用了两层设置。在图3中,“Friend”或“Sharing”意味着对应的视图被分离。当只使用两个视图时,SEPT退化为自我监督的co-training。“Preference-Only”意味着只使用偏好视图,在这种情况下,SEPT进一步退化为 self-training。

- (2) From Fig. 3, we can observe that on both LastFM and Yelp, all the views contribute, whereas on Douban-Book, the self-supervised co-training setting achieves the best performance. Moreover, when only the preference view is used, SEPT shows lower performance but it is still better than that of LightGCN. With the decrease of used number of views, the performance of SEPT slightly declines on LastFM, and an obvious performance drop is observed on Yelp. On Douban-Book, the performance firstly gets a slight rise and then declines obviously when there is only one view. The results demonstrate that, under the semi-supervised setting, even a single view can generate desirable self-supervised signals, which is encouraging since social relations or other side information are not always accessible in some situations. Besides, increasing the used number of views may bring more performance gains, but it is not absolutely right. (从图3中,我们可以看到,在LastFM和Yelp上,所有的视图都有贡献,而在Douban-Book上,自监督的co-training设置表现最好。此外,当只使用Preference-Only视图时,SEPT的性能较低,但仍优于LightGCN。随着使用视图数的减少,SEPT在LastFM上的性能略有下降,而在Yelp上的性能明显下降。在Douban-Book上,当只有一种视图时,表现先略有上升,然后明显下降。结果表明,在半监督设置下,即使是一个单一的视图也能产生理想的自监督信号,因为社会关系或其他方面的信息在某些情况下并不总是可获得的。此外,增加视图的使用数量可能会带来更多的性能提高,但这并不是绝对正确的。
4.5 Parameter Sensitivity Analysis
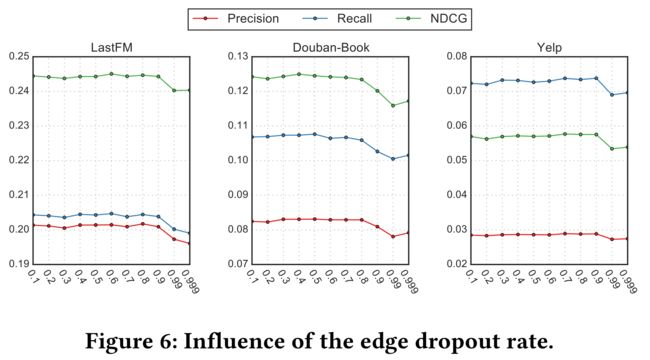
- (1) There are three important hyper-parameters used in SEPT: β for controlling the magnitude of self-supervised tri-training, K - the number of used positive examples and ρ - the edge dropout rate of ˜G. We choose some representative values for them to investigate the parameter sensitivity of SEPT. The results are presented in Fig. 4 - 6. When investigating the influence of β, we fix K = 10 and ρ = 0.3. For the influence of K in Fig. 5, we fix β = 0.005 on LastFM and Yelp, β = 0.02 on Douban-Book, and ρ = 0.3. Finally, for the effect of ρ in Fig. 6, the setting of β is as the same as the last case, and K = 10. A two-layer setting is used in this case. (在SEPT中使用了三个重要的超参数:是用于控制self-supervised tri-training的大小,是使用的正例的数量和是˜G的边dropout。我们选择了一些具有代表性的值来研究SEPT的参数敏感性。结果如图4 - 6.所示。在研究的影响时,我们固定了=10和=0.3。对于图5中的影响,我们在LastFM和Yelp上设置了=0.005,在Douban-Book上设置了=0.02,=0.3。最后,对于图6中的影响,=0.02,=10。在本研究中使用了两层设置。

- (2) As can be observed from Fig. 4, SEPT is sensitive to β \beta β. On different datasets, we need to choose different values of β \beta β for the best performance. Generally, a small value of β \beta β can lead to a desirable performance, and a large value of β \beta β results in a huge performance drop. Figure 5 has been interpreted in Section 4.3. According to Fig. 6, we observe that SEPT is not sensitive to the edge dropout rate. Even a large value of ρ (e.g., 0.8) can create informative self-supervision signals, which is a good property for the possible wide use of SEPT. When the perturbed graph is highly sparse, it cannot provide useful information for self-supervised learning. (从图4中可以看出。SEPT对很敏感。在不同的数据集上,我们需要选择不同的值以获得最佳性能。一般来说,一个小的值就会导致理想的性能,而一个大的值就会导致性能的巨大下降。图5已在第4.3节中进行了解释。根据图6中。我们看到SEPT对边dropout不敏感。即使是一个很大的值(例如,0.8)也可以创建提供信息的自监督信号,这对于SEPT可能的广泛使用是一个很好的特性。当被扰乱的图是高度稀疏时,它不能为自监督学习提供有用的信息。

5 CONCLUSION AND FUTURE WORK
-
(1) The self-supervised graph contrastive learning, which is widely used in the field of graph representation learning, recently has
been transplanted to recommendation for improving the recommendation performance. However, most SSL-based methods only exploit self-supervision signals through the self-discrimination, and SSL cannot fully exert itself in the scenario of recommendation to leverage the widely observed homophily. (自监督图对比学习被广泛应用于图表示学习领域,最近被移植到推荐学习中,以提高推荐性能。然而,大多数基于SSL的方法只通过自我识别来利用自监督信号,而SSL不能在推荐的场景中充分利用广泛观察到的同质性。) -
(2) To address this issue, in this paper,
- we propose a socially-aware self-supervised tri-training framework named SEPT to improve recommendation (我们提出了一个名为SEPT的社交-意识self-supervised tri-training框架)
- by discovering self-supervision signals from two complementary views of the raw data. (通过从原始数据的两个互补视图中发现自监督信号来改进推荐。)
- Under the self-supervised tri-training scheme, the neighbor-discrimination based contrastive learning method is developed to refine user representations with pseudo-labels from the neighbors=. (在self-supervised tri-training方案下,提出了基于邻居识别== 的 对比学习方法,利用邻居中的伪标签来细化用户表示。)
-
(3) Extensive experiments demonstrate the effectiveness of SEPT, and a thorough ablation study is conducted to verify the rationale of the self-supervised tri-training.
-
(4) In this paper, only the self-supervision signals from users are exploited. However, items can also analogously provide informative pseudo-labels for self-supervision. This can be implemented by leveraging the multimodality of items. We leave it as our future work. We also believe that the idea of self-supervised multi-view co-training can be generalized to more scenarios beyond recommendation.
(本文只利用了来自用户的自监督信号。然而,项目也可以类似地为自监督提供信息性的伪标签。这可以通过利用项目的多模式来实现。我们把它作为我们未来的工作。我们还相信,自我监督的多视图共同训练的想法可以推广到除推荐之外的更多的场景。)