2019_SIGIR_A Neural Influence Diffusion Model for Social Recommendation
[论文阅读笔记]2019_SIGIR_A Neural Influence Diffusion Model for Social Recommendation
论文下载地址: https://dl.acm.org/doi/10.1145/3331184.3331214
发表期刊:SIGIR
Publish time: 2019
作者及单位:
- Le Wu Hefei University of Technology
- Peijie Sun∗ [email protected] University of Technology
- Yanjie Fu Missouri University of Science and Technology
- Richang Hong Hefei University of Technology
- Xiting Wang Microsoft Research
- Meng Wang Hefei University of Technology
数据集: 正文中的介绍
- Yelp
- Flickr 作者自己爬的
代码:
其他:
- gensim tool (https://radimrehurek.com/gensim/ (文中作者给的,一个word2vector的工具)
其他人写的文章
- 论文笔记(A Neural Influence Diffusion Model for Social Recommendation)
- 论文《A Neural Influence Diffusion Model for Social Recommendation》阅读
简要概括创新点: 不要被图吓到,递归的深度就2层。GCNs的核心思想是以图的消息传递或信息扩散方式生成节点嵌入,思想与本文是类似的,可以理解为本文把这种思想“专业化”了
- In this paper, we propose a deep influence propagation model to stimulate how users are influenced by the recursive social diffusion process for social recommendation. (在本文中,我们提出了一个深度影响传播模型来模拟用户是如何受到社会推荐的递归社会扩散过程的影响的。)
- For each user, the diffusion process starts with an initial embedding that fuses the related features and a free user latent vector that captures the latent behavior preference. (对于每个用户,扩散过程从融合相关特征的初始嵌入和捕获潜在行为偏好的自由用户潜在向量开始。)
- The key idea of our proposed model is that we design a layer-wise influence propagation structure to model how users’ latent embeddings evolve as the social diffusion process continues. (我们提出的模型的关键思想是,我们设计了一个分层的影响传播结构,来模拟随着社会扩散过程的继续,用户的潜在嵌入如何演变。)
- We propose a DiffNet model with a layer-wise influence propagation structure to model the recursive dynamic social diffusion in social recommendation. (我们提出了一个具有分层影响传播结构的DiffNet模型来模拟社会推荐中的递归动态社会扩散。)
- Besides, DiffNet has a fusion layer such that each user and each item could be represented as an embedding that encompasses both the collaborative and the feature content information. (此外,DiffNet有一个融合层,这样每个用户和每个项目都可以表示为一个包含协作和特征内容信息的嵌入。)
ABSTRACT
- (1) Precise user and item embedding learning is the key to building a successful recommender system. Traditionally, Collaborative Filtering (CF) provides a way to learn user and item embeddings from the user-item interaction history. However, the performance is limited due to the sparseness of user behavior data. With the emergence of online social networks, social recommender systems have been proposed to utilize each user’s local neighbors’ preferences to alleviate the data sparsity for better user embedding modeling. (准确的用户和项目嵌入学习是构建成功推荐系统的关键。传统上,协同过滤(CF) 提供了一种从用户项目交互历史中学习用户和项目嵌入的方法。然而,由于用户行为数据的稀疏性,性能受到限制。随着在线社交网络的出现,社交推荐系统被提出来利用每个用户的本地邻居偏好来缓解数据稀疏性,从而更好地进行用户嵌入建模。)
- We argue that, for each user of a social platform, her potential embedding is influenced by her trusted users, with these trusted users are influenced by the trusted users’ social connections. As social influence recursively propagates and diffuses in the social network, each user’s interests change in the recursive process. (我们认为,对于社交平台的每个用户,其潜在嵌入都受到其受信任用户的影响,而这些受信任用户受到受信任用户的社会关系的影响。随着社会影响力在社交网络中的递归传播和扩散,每个用户的兴趣都会在递归过程中发生变化。)
- Nevertheless, the current social recommendation models simply developed static models by leveraging the local neighbors of each user without simulating the recursive diffusion in the global social network, leading to suboptimal recommendation performance. (然而,当前的社会推荐模型只是通过利用每个用户的局部邻居来开发静态模型,而没有模拟全局社会网络中的递归扩散,从而导致次优推荐性能。)
- In this paper, we propose a deep influence propagation model to stimulate how users are influenced by the recursive social diffusion process for social recommendation. (在本文中,我们提出了一个深度影响传播模型来模拟用户是如何受到社会推荐的递归社会扩散过程的影响的。)
- For each user, the diffusion process starts with an initial embedding that fuses the related features and a free user latent vector that captures the latent behavior preference. (对于每个用户,扩散过程从融合相关特征的初始嵌入和捕获潜在行为偏好的自由用户潜在向量开始。)
- The key idea of our proposed model is that we design a layer-wise influence propagation structure to model how users’ latent embeddings evolve as the social diffusion process continues. (我们提出的模型的关键思想是,我们设计了一个分层的影响传播结构,来模拟随着社会扩散过程的继续,用户的潜在嵌入如何演变。)
- We further show that our proposed model is general and could be applied when the user (item) attributes or the social network structure is not available. (我们进一步证明了我们提出的模型是通用的,并且可以在用户(项目)属性或社交网络结构不可用时应用。)
- Finally, extensive experimental results on two real-world datasets clearly show the effectiveness of our proposed model, with more than 13% performance improvements over the best baselines for top-10 recommendation on the two datasets. (最后,在两个真实数据集上的大量实验结果清楚地表明了我们提出的模型的有效性,在两个数据集上,与前10名推荐的最佳基线相比,性能提高了13%以上。)
CCS CONCEPTS
• Information systems → Social recommendation; Personalization; • Human-centered computing → Social networks.
KEYWORDS
graph neural networks, social recommendation, influence diffusion, personalization
1 INTRODUCTION
-
(1) By providing personalized item suggestions for each user, recommender systems have become a cornerstone of the E-commerce
shopping experience [2, 23, 41]. Among all recommendation algorithms, learning low dimensional user and item embeddigs is a key building block that have been widely studied [20, 31]. With the learned user and item embeddings, it is convenient to approximate the likelihood or the predicted preference that a user would give to an item by way of a simple inner product between the corresponding user embedding and item embedding. (通过为每个用户提供个性化的商品建议,推荐系统已经成为电子商务购物体验的基石[2,23,41]。在所有推荐算法中,学习低维用户和项目嵌入是一个关键的构建块,已被广泛研究[20,31]。通过学习用户和项目嵌入,可以方便地通过相应用户嵌入和项目嵌入之间的简单内积来近似用户对项目的可能性或预测偏好。) -
(2) Many efforts have been devoted to designing sophisticated models to learn precise user and item embeddings. In the typical collaborative filtering scenario with user-item interaction behavior, the latent factor based approaches have received great success [20,31,32]. (许多工作都致力于设计复杂的模型,以了解精确的用户和项目嵌入。在具有用户项交互行为的典型 协同过滤 场景中,基于潜在因素的方法取得了巨大成功[20,31,32]。)
- However, the recommendation performance is unsatisfactory due to the sparseness of user-item interaction data. As sometimes users and items are associated with features, factorization machines generalize most latent factor models with an additional linear regression function of user and item features [31]. (然而,由于用户项交互数据的稀疏性,推荐性能并不理想。由于有时用户和项目与特征相关联,因子分解机使用用户和项目特征的额外线性回归函数来概括大多数潜在因素模型[31]。)
- Recently, researchers also designed more advanced neural models based on latent factor models and FMs [9, 12]. E.g., NeuMF extends over latent factor based models by modeling the complex relationships between user and item embedding with a neural architecture [12]. These deep embedding models advance the performance of previous shallow embedding models. Nevertheless, the recommendation performance is still hampered by the sparse data. (最近,研究人员还基于潜在因素模型和FMs设计了更先进的神经模型[9,12]。例如,NeuMF通过使用神经架构建模用户和项目嵌入之间的复杂关系,扩展了基于潜在因素的模型[12]。这些深嵌入模型提高了以前 浅嵌入模型 的性能。然而,推荐性能仍然受到稀疏数据的影响。)
-
(3) Luckily, with the prevalence of online social networks, more and more people like to express their opinions of items in these social platforms. The social recommender systems have emerged as a promising direction, which leverage the social network among users to alleviate the data sparsity issue and enhance recommendation performance [7, 16, 25, 35]. (幸运的是,随着在线社交网络的普及,越来越多的人喜欢在这些社交平台上表达他们对项目的看法。社交推荐系统已经成为一个很有前途的方向,它利用用户之间的社交网络来缓解数据稀疏问题,提高推荐性能[7,16,25,35]。)
- These social recommendation approaches are based on the social influence theory that states connected people would influence each other, leading to the similar interests among social connections [3, 4, 22]. E.g., social regularization has been empirically proven effective for social recommendation, with the assumption that connected users would share similar latent embeddings [15, 16, 25]. (这些社会推荐方法基于社会影响理论,即国家关联人会相互影响,从而在社会关联中产生相似的利益[3,4,22]。例如,经验证明,社交规范化对于社交推荐是有效的,前提是互联用户会共享类似的潜在嵌入[15,16,25]。)
- TrustSVD++ extended the classic latent factor based models by incorporating each user’s trusted friends’ feedbacks to items as the auxiliary feedback of the active user [7]. (TrustSVD++ 扩展了经典的基于潜在因素的模型,将每个用户信任的朋友对项目的反馈作为活动用户的辅助反馈[7]。)
- Despite the performance improvement by considering the first-order local neighbors of each user, we argue that, for each user, instead of the interest diffusion from a user’s neighbors to this user at one time, the social diffusion presents a dynamic recursive effect to influence each user’s embedding. (尽管通过考虑每个用户的一阶局部邻居可以提高性能,但我们认为,对于每个用户,社交扩散不是一次从用户的邻居向该用户扩散兴趣,而是一种动态递归效应,影响每个用户的嵌入。)
- In detail, as the social influence propagation process begins (i.e., the diffusion iteration k = 1), each user’s first latent embedding is influenced by the initial embeddings of her trusted connections. With the recursive influence diffuses over time, each user’s latent embedding at k-th iteration is influenced by her trusted neighbors at the (k − 1)-th iteration. (具体而言,随着社会影响传播过程的开始(即扩散迭代k=1),每个用户的第一次潜在嵌入都会受到其信任连接的初始嵌入的影响。随着递归影响随时间扩散,每个用户在第k次迭代时的潜在嵌入受到其在(k-1)次迭代时的可信邻居的影响。)
- Therefore, the social influence recursively propagates and diffuses in the social network. Correspondingly, each user’s interests change in the recursive process. Precise simulating the recursive diffusion process in the global social network would better model each user’s embedding, thus improve the social recommendation performance. (因此,社会影响力在社会网络中递归传播和扩散。相应地,每个用户的兴趣在递归过程中都会发生变化。精确模拟全局社交网络中的递归扩散过程可以更好地模拟每个用户的嵌入,从而提高社交推荐的性能。)
-
(4) In this paper, we propose DiffNet: an Influence Diffusion neural network based model to stimulate the recursive social influence propagation process for better user and item embedding modeling in social recommendation. (我们提出了一种基于影响扩散神经网络的模型DiffNet,以刺激递归的社会影响传播过程,从而在社会推荐中更好地进行用户和项目嵌入建模。)
- The key idea behind the proposed model is a carefully designed layer-wise influence diffusion structure for users, which models how users’ latent embeddings evolve as the social diffusion process continues. (该模型背后的核心思想是为用户精心设计的分层影响扩散结构,该结构模拟了随着社会扩散过程的继续,用户的潜在嵌入如何演变。)
- Specifically, the diffusion process starts with an initial embedding for each user on top of the fusion of each user’s features and a a free user latent vector that captures the latent behavior preference. (具体地说,扩散过程始于在每个用户的特征融合和捕获潜在行为偏好的自由用户潜在向量的基础上对每个用户进行初始嵌入。)
- For the item side, as items do not propagate in the social network, each item’s embedding is also fused by the free item latent embedding and the item features. With the influence diffuses to a predefined K-th diffusion step, the K-th layer user interest embedding is obtained. (在项目方面,由于项目不会在社交网络中传播,每个项目的嵌入也会通过自由项目潜在嵌入和项目特征进行融合。通过将影响扩散到预定义的第K层扩散步骤,得到第K层用户兴趣嵌入。)
- In fact, with the learned user and item embedddings, DiffNet can be seamlessly incorporated into classical CF models, such as BPR and SVD++, and efficiently trained using SGD. (事实上,通过学习用户和项目嵌入,DiffNet可以无缝地整合到经典CF模型中,如BPR和SVD++,并使用SGD进行高效训练。)
-
(5) We summarize the contributions of this paper as follows:
- We propose a DiffNet model with a layer-wise influence propagation structure to model the recursive dynamic social diffusion in social recommendation. (我们提出了一个具有分层影响传播结构的DiffNet模型来模拟社会推荐中的递归动态社会扩散。)
- Besides, DiffNet has a fusion layer such that each user and each item could be represented as an embedding that encompasses both the collaborative and the feature content information. (此外,DiffNet有一个融合层,这样每个用户和每个项目都可以表示为一个包含协作和特征内容信息的嵌入。)
- We show that the proposed DiffNet model is time and storage efficient in comparison to most embedding based recommendation models. The proposed model is a generalization of many related recommendation models and it is flexible when user and item attributes are not available. (我们证明,与大多数基于嵌入的推荐模型相比,所提出的DiffNet模型在时间和存储方面都是高效的。该模型是许多相关推荐模型的推广,在用户和项目属性不可用时具有灵活性。)
- Experimental results on two real-world datasets clearly show the effectiveness of our proposed model. DiffNet outperforms more than 13.5% on Yelp and 15.5% on Flickr for top-10 recommendation compared to the the baselines with the best performance. (在两个真实数据集上的实验结果清楚地表明了我们提出的模型的有效性。与表现最好的基线相比,DiffNet在Yelp和Flickr上的排名分别超过13.5%和15.5%。)
2 PRELIMINARIES
-
(1) In a social recommender system, there are two sets of entities: a user set U ( ∣ U ∣ = M ) U (|U | = M) U(∣U∣=M), and an item set V ( ∣ V ∣ = N ) V (|V | = N) V(∣V∣=N).
- As the implicit feedback (e.g., watching an movie, purchasing an item, listening to a song ) are more common in, we also consider the recommendation scenario with implicit feedback [32]. (由于隐含的反馈(例如,观看电影,购买一个项目,听一首歌)是比较常见的,我们也考虑了隐含反馈的推荐场景[32 ]。)
- Let R ∈ R M × N R \in R^{M×N} R∈RM×N denote users’ implicit feedback based rating matrix, with r a i = 1 r_{ai} = 1 rai=1 if user a a a is interested in item i i i, otherwise it equals 0.
- The social network can be represented as a user-user directed graph G = [ U , S ∈ R M × M ] \mathcal{G} = [U, S \in R^{M\times M}] G=[U,S∈RM×M], with U U U is the user set and S S S represents the social connections between users. If user a a a trusts or follows user b b b, s b a = 1 s_{ba}= 1 sba=1, otherwise it equals 0.
- If the social network is undirected, then user a a a connects to user b b b denotes a a a follows b b b, and b b b also follows a a a, i.e., s a b = 1 ∧ s b a = 1 s_{ab} = 1 \land s_{ba} = 1 sab=1∧sba=1. Then, each user a a a’s ego social network, i.e., is the i i i-th column ( s a s_a sa) of S S S.
- For notational convenience, we use S a S_a Sa to denote the userset that a a a trusts, i.e., S a = [ b ∣ s b a = 1 ] S_a = [b | s_{ba} = 1] Sa=[b∣sba=1].
-
(2) Besides, each user a a a is associated with real-valued attributes (e.g, user profile), denoted as x a x_a xa in the user attribute matrix X ∈ R d 1 × M X \in R^{d1 \times M} X∈Rd1×M. Also, each item i i i has an attribute vector y i y_i yi(e.g., item text representation, item visual representation) in item attribute matrix Y ∈ R d 2 × N Y \in R^{d2 \times N} Y∈Rd2×N. Then, the social recommendation problem can be defined as:
Definition 2.1 (SOCIAL RECOMMENDATION). Given a rating matrix R R R, a social network S S S, and associated real-valued feature matrix X X X and Y Y Y of users and items, our goal is to predict users’ unknown preferences to items as: R ^ = f ( R , S , X , Y ) \hat{R} = f (R,S,X,Y) R^=f(R,S,X,Y), where R ^ ∈ R M × N \hat{R} \in R^{M \times N} R^∈RM×N denotes the predicted preferences of users to items.
Given the problem definition, we introduce the preliminaries that are closely related to our proposed model. (给出了问题的定义,我们介绍了与我们提出的模型密切相关的预备工作。)
2.1 Classical Embedding Models.
-
(1) Given the user-item rating matrix R R R, the latent embedding based models embed both users and items in a low latent space, such that each user’s predicted preference to an unknown item turns to the inner product between the corresponding user and item embeddings as[20, 31, 32]: (给定用户项目评分矩阵 R R R,基于潜在嵌入的模型 将用户和项目都嵌入到一个低潜在空间中,这样每个用户对未知项目的预测偏好将转向相应用户和项目嵌入之间的内积[20,31,32]:)
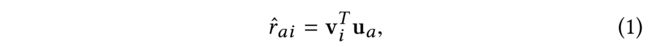
- where u a u_a ua is the embedding of a a a, which is the a a a-th column of the user embedding matrix U U U. Similarly, v i v_i vi represents item i i i’s embedding in the i i i-th column of item embedding matrix V V V.
-
(2) SVD++ is an enhanced version of the latent factor based models that leveraged the rated history items of each user for better user embedding modeling [19]. In SVD++, each user’s embedding is composed of a free embedding as classical latent factor based models, as well as an auxiliary embedding that is summarized from her rated items. Therefore, the predicted preference is modeled as: (SVD++ 是 基于潜在因素的模型 的增强版,它利用每个用户的额定历史项来更好地进行用户嵌入建模[19]。在 SVD++ 中,每个用户的嵌入都由一个自由嵌入和一个辅助嵌入组成,前者是经典的基于潜在因素的模型,后者是从用户的评分项目中总结出来的。因此,预测偏好被建模为:)
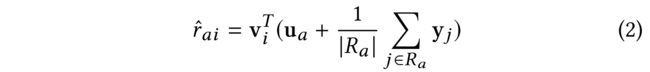
- where R a = [ j : r a j = 1 ] R_a = [j : r_{aj} = 1] Ra=[j:raj=1] is the itemset that a a a shows implicit feedback, and y j y_j yj is an implicit factor vector. (是 a a a显示隐式反馈的项目集 , y j y_j yj是一个隐式因子向量。)
-
(3) As sometimes users and items are associated with attributes, the feature enriched embedding models give the predicted preference r ^ a i \hat{r}_{ai} r^ai of user a a a to item i i i is: (由于有时用户和项目与属性相关联,特征丰富的嵌入模型给出了预测的用户 a a a对项目 i i i的偏好 r ^ a i \hat{r}_{ai} r^ai)
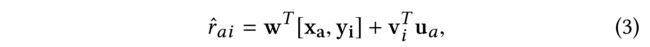
- where the first term captures the bias terms with the feature engineering, (其中,第一个项捕获特征工程中的偏差,)
- and the second term models the second-order interaction between users and items. (第二项模拟用户和项目之间的二阶交互。)
-
(4) Different embedding based models vary in the embedding matrix formulation and the optimization function. E.g., Bayesian Personalized Ranking (BPR) is one of the most successful pair-wise based optimization function for implicit feedback [32]. In BPR, it assumes that the embedding matrices U U U and V V V are free embeddings that follow a Gaussian prior, which is equivalent to adding a L2-norm regularization in the optimization function as: (不同的 基于嵌入的模型 在嵌入矩阵公式和优化函数方面有所不同。例如, 贝叶斯个性化排名(BPR) 是最成功的 基于对的隐式反馈优化函数 之一[32]。在 BPR 中,它假设嵌入矩阵 U U U和 V V V是遵循 高斯先验 的自由嵌入,这相当于在优化函数中添加 L2范数正则化,如下所示:)
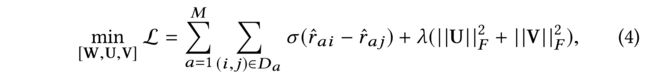
- where σ ( x ) = 1 1 + e x p ( − x ) \sigma(x) = \frac{1} {1+exp(−x)} σ(x)=1+exp(−x)1 is a logistic function that transforms the input into range ( 0 , 1 ) (0,1) (0,1).
- D a = ( i , j ) ∣ i ∈ R a ∧ j ∈ V − R a D_a = {(i, j) | i \in R_a \land j \in V − R_a} Da=(i,j)∣i∈Ra∧j∈V−Ra is the training data for a a a with R a R_a Ra the itemset that a a a positively shows feedback, (是 a a a和 R a R_a Ra的训练数据,是 a a a积极显示反馈的项目集,)
- and j ∈ V − R a j \in V − R_a j∈V−Ra denotes the items that a a a does not show feedback in the training data. (表示 a a a在培训数据中未显示反馈的项目)
2.2 Social Recommendation Models
-
(1) Social influence occurs when a persons’s emotions, opinions or behaviors are affected by others [1, 24, 34]. In a social platform, social scientists have converged that social influence is a natural process for users to disseminate their preferences to the followers in the social network, such that the action (preference, interest) of a user changes with the influence from his/her trusted users [13, 17, 21, 22]. Therefore, as the social diffusion process continues, thesocial correlationphenomenon exits, with each user’s preference and behavior are similar to her social connections [3, 22]. (当一个人的情绪、观点或行为受到他人影响时,就会产生社会影响[1,24,34]。在社交平台上,社会学家们已经认识到,社交影响是用户向社交网络中的关注者传播其偏好的自然过程,因此用户的行为(偏好、兴趣)会随着其信任用户的影响而变化[13、17、21、22]。因此,随着社会扩散过程的继续,社会关联现象会出现,每个用户的偏好和行为都与她的社会关系相似[3,22]。)
-
(2) The social influence and social correlation among users’ interests are the foundation for building social recommender systems [7, 25, 34]. Due to the superiority of embedding based models for recommendation, most social recommendation models are also built on these embedding models. These social embedding models could be summarized into the following two categories: (用户兴趣的社会影响和社会关联是构建社会推荐系统的基础(7, 25, 34)。由于 基于嵌入的推荐模型 的优越性,大多数社会推荐模型也建立在这些 嵌入模型 的基础上。这些社会嵌入模型可归纳为以下两类:)
- the social regularization based approaches [15, 16, 25, 42] (基于社会规范化的方法)
- and the user behavior enhancement based approaches [7, 8]. (基于用户行为增强的方法)
- Specifically, the social regularization based approaches assumed that connected users would show similar embeddings under the social influence diffusion. (具体而言,基于社会规范化的方法假设,在社会影响扩散下,互联用户会表现出类似的嵌入。)
- As such, besides the classical collaborative filtering based loss function (e.g, Eq.(4)), an additional social regularization term is incorporated in the overall optimization function as: (因此,除了 经典的基于协同过滤 的损失函数(例如,等式(4)),在整体优化函数中还加入了一个额外的社会正则化项,如下所示:)
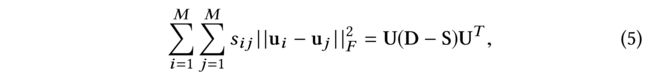
- where D D D is a diagonal matrix with d a a = ∑ b = 1 M s b b d_{aa} = \sum^{M}_{b=1} s_{bb} daa=∑b=1Msbb
-
(3) Instead of the social regularization term, some researchers argued that the social network provides valuable information to enhance each user’s behavior. TrustSVD is such a model that shows state-of-the-art performance [7, 8]. By assuming the implicit feedbacks of a user’s social neighbors’ on items could be regarded as the auxiliary feedback of this user, TrustSVD models the predicted preference as: (一些研究人员认为,社交网络提供了有价值的信息来增强每个用户的行为,而不是社交规范化术语。TrustSVD 就是这样一个展示最先进性能的模型[7,8]。通过 假设用户的社交邻居对项目的隐性反馈可被视为该用户的辅助反馈,TrustSVD 将预测偏好建模为:)
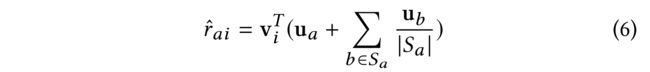
- where u b u_b ub denotes the latent embedding of user b b b, who is trusted by a a a. As such, a a a’s latent embedding is enhanced by considering the influence of her trusted users’ latent embeddings in the social network. (其中, u b u_b ub表示用户 b b b的潜在嵌入,该用户受 a a a信任。因此, a a a的潜在嵌入通过考虑其受信任用户在社交网络中的潜在嵌入的影响而增强。)
-
(4) We notice that nearly all of the current social recommendation models leveraged the observed social connections (each user’s social neighbors) for recommendation with a static process at once. (我们注意到,目前几乎所有的社交推荐模型都利用观察到的社交关系(每个用户的社交邻居)进行一次性静态推荐。)
- However, the social influence is not a static but a recursive process, with each user is influenced by the social connections as time goes on. (然而,社会影响不是一个静态的过程,而是一个递归的过程,随着时间的推移,每个用户都会受到社会关系的影响。)
- At each time, users need to balance their previous preferences with the influences from social neighbors to form their updated latent interests. Then, as the current user interest evolves, the influences from social neighbors changes. The process is recursively diffused in the social network. (每次,用户都需要平衡他们以前的偏好和来自社交邻居的影响,以形成他们最新的潜在兴趣。然后,随着当前用户兴趣的发展,社交邻居的影响也会发生变化。这个过程在社交网络中递归扩散。)
- Therefore, current solutions neglected the iterative social diffusion process for social recommendation. What’s worse, when the user features are available, these social recommendation models need to be redesigned to leverage the feature data for better correlation modeling between users [16]. In the following section, we would show how to tackle the above issues with our proposed DiffNet model. (因此,目前的解决方案忽略了社会推荐的迭代社会扩散过程。更糟糕的是,当用户功能可用时,这些社交推荐模型需要重新设计,以利用功能数据更好地建立用户之间的相关性模型[16]。在下一节中,我们将展示如何使用我们提出的DiffNet模型解决上述问题。)
3 THE PROPOSED MODEL
3.1 Model Architecture
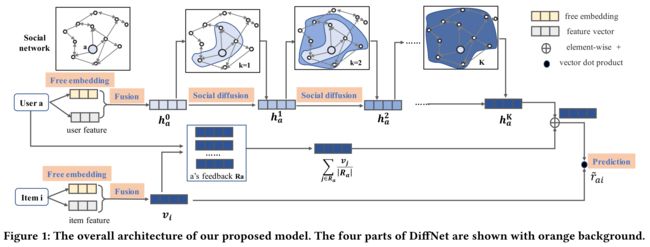
- (1) We show the overall neural architecture of DiffNet in Fig 1. By taking an user-item pair < a,i > as input, it outputs the probability r ^ a i \hat{r}_{ai} r^ai that u u u would like item i i i.
- (2) The overall neural architecture of DiffNet contains four main parts:
- the embedding layer, (嵌入层)
- the fusion layer, (熔合层,)
- the layer-wise influence diffusion layers, (分层影响扩散层,)
- and the prediction layer. (以及预测层。)
- (3) Specifically, by taking related inputs,
- the embedding layer outputs free embeddings of users and items. (嵌入层输出用户和项目的自由嵌入。)
- For each user (item), the fusion layer generates a hybrid user (item) embedding by fusing both a user’s ( an item’s) free embedding and the associated features. The fused user embedding is then sent to the influence diffusion layers. (对于每个用户(项目),融合层通过融合用户(项目)的自由嵌入和相关特征来生成混合用户(项目)嵌入。然后将融合的用户嵌入发送到影响扩散层。)
- The influence diffusion layers are built with a layer-wise structure to model the recursive social diffusion process in the social network, which is the key idea of the DiffNet. After the influence diffusion process reaches stable, (影响扩散层采用分层结构来建模社会网络中的递归社会扩散过程,这是DiffNet的核心思想。影响扩散过程达到稳定后,)
- the output layer generates the final predicted preference. (输出层生成最终的预测偏好。)
We detail each part as follows:
3.1.1 Embedding Layer
Let P ∈ R D × M P \in R^{D\times M} P∈RD×M and Q ∈ R D × N Q \in R^{D\times N} Q∈RD×N represent the free embeddings of users and items. (让 P ∈ R D × M P \in R^{D\times M} P∈RD×M 和 Q ∈ R D × N Q \in R^{D\times N} Q∈RD×N代表用户和项目的自由嵌入)
- These free embeddings capture the collaborative latent representations of users and items. (这些自由嵌入捕获了用户和项目的协作潜在表示)
- Given the one hot representations of user a a a and item i i i, the embedding layer performs an index operation and outputs the free user latent vector p a p_a pa and free item latent vector q i q_i qi from user free embedding matrix P P P and item free embedding matrix Q Q Q. (给定用户 a a a和项目 i i i的一个one hot表示,嵌入层执行索引操作,并从用户自由嵌入矩阵 P P P和项目自由嵌入矩阵 Q Q Q输出自由用户潜在向量 p a p_a pa和自由项目潜在向量 q i q_i qi。)
3.1.2 Fusion Layer
-
(1) For each user a a a, the fusion layer takes p a p_a pa and her associated feature vector x a x_a xa as input, and outputs a user fusion embedding h a 0 h^0_a ha0 that captures the user’s initial interests from different kinds of input data. We model the fusion layer as a one-layer fully connected neural network as: (对于每个用户 a a a,融合层将 p a p_a pa及其关联的特征向量 x a x_a xa 作为输入,并输出一个用户融合嵌入 h a 0 h^{0}_{a} ha0 ,从不同类型的输入数据中捕获用户的初始兴趣。我们将融合层建模为单层全连接神经网络如下:)
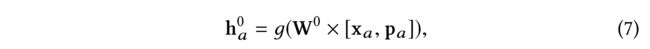
- where W 0 W^ 0 W0 is a transformation matrix, and g ( x ) g(x) g(x) is a non-linear function.
- Without confusion, we omit the bias term in a fully-connected neural network for notational convenience. This fusion layer could generalize many typical fusion operations, such as the concatenation operation as h a 0 = [ x a , p a ] h^0_a= [x_a, p_a] ha0=[xa,pa] by setting W 0 W^0 W0 as an identity matrix. (为了便于标注,我们省略了完全连接的神经网络中的偏差项。这个融合层可以概括许多典型的融合操作)
-
(2) Similarly, for each item i i i, the fusion layer models the item embedding vias a non-linear transformation between its free latent vector q i q_i qi and its feature vector y i y_i yi as: (类似地,对于每个项目i,融合层通过其自由潜在向量 q i q_i qi和其特征向量 y i y_i yi之间的非线性变换对项目嵌入进行建模:)
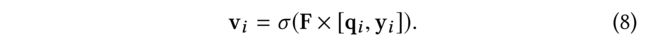
3.1.3 Influence Diffusion Layers
-
(1) By feeding the output of each user a a a’s fusion embedding h a 0 h^0_a ha0 from the fusion layer into the influence diffusion part, the influence diffusion layers model the dynamics of users’ latent preference diffusion in the social network S S S. (通过输入 每个用户 a a a从融合层到影响扩散层的融合嵌入 h a 0 h^0_a ha0的输出 ,影响扩散层对社交网络中用户潜在偏好扩散的动力学进行建模。)
- As information diffuses in the social network from time to time, the influence diffusion part is analogously built with a multi-layer structure. Each layer k k k takes the users’ embeddings from the previous layers as input, and output users’ updated embeddings after the current social diffusion process finishes. (随着信息在社交网络中的不断扩散,影响力扩散部分类似地构建为多层结构。每一层 k k k都将前一层的用户嵌入作为输入,在当前的社交扩散过程结束后输出用户更新的嵌入。)
- Then, the updated user embeddings are sent to the ( k + 1 ) (k+1) (k+1)-th layer for the next diffusion process. This process is recursively operated until it the social diffusion process reaches stable. (然后,更新后的用户嵌入被发送到第 ( k + 1 ) (k+1) (k+1)层,用于下一个扩散过程。这个过程是递归操作的,直到社会扩散过程达到稳定。)
-
(2) For each user a a a, let h a k h^k_a hak denote her latent embedding in the k k k-th layer of the influence diffusion part. By feeding the output of the k k k-th layer into the ( k + 1 ) (k +1) (k+1)-th layer, the influence diffusion operation at the ( k + 1 ) (k + 1) (k+1)-th social diffusion layer updates each user a a a’s latent embedding into h a k + 1 h^{k+1}_a hak+1 .
-
Specifically, the updated embedding h a k + 1 h^{k+1}_a hak+1 is composed of two steps: (具体来说,更新后的嵌入 h a k + 1 h^{k+1}_a hak+1由两个步骤组成)
-
diffusion influence aggregation (AGG) from a a a’s trusted users from the k k k-th layer, which transforms all the social trusted users’ influences into a fixed length vector h S a k + 1 h^{k+1}_{Sa} hSak+1: (第 k k k层 a a a的受信任用户的扩散影响聚合(AGG),将所有社交受信任用户的影响转化为固定长度向量 h S a k + 1 h^{k+1}_{Sa} hSak+1:)
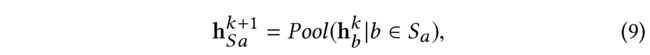
- where the Pool function could be defined as an average pooling that performs a mean operation of all the trusted users’ latent embedding at the k k k-th layer. The Pool can also be defined as a max operation that select the maximum element of all the trusted users’ latent embedding at the k k k-th layer to form h S a k + 1 h^{k+1}_{Sa} hSak+1. (其中,池化函数可以定义为一个平均池化,它在第 k k k层对所有受信任用户的潜在嵌入执行平均操作。池也可以定义为一个max操作,它选择所有受信任用户在第 k k k层的潜在嵌入的最大元素,以形成 h S a k + 1 h^{k+1}_{Sa} hSak+1 .)
-
Then, a a a-th updated embedding h a ( k + 1 ) h^{(k+1)}_a ha(k+1) is a combination of her latent embedding h a k h^k_a hak at the k k k-th layer and the influence diffusion embedding aggregation h S a k + 1 h^{k+1}_{Sa} hSak+1 from her trusted users. Since we do not know how each user balances these two parts, we use a nonlinear neural network to model the combination as: (由于我们不知道每个用户如何平衡这两部分,我们使用非线性神经网络对组合进行建模,如下所示:)
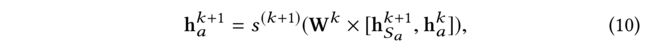
- where s k ( x ) s^k(x) sk(x) is non-linear transformation function. (是非线性变换函数)
-
-
(3) With a predefined diffusion depth K K K, for each user a a a, the influence diffusion layer starts with the layer-0 user embedding h a 0 h^0_a ha0 (Eq.(7)), i.e., the output of the fusion layer, and the layer-wise influence diffusion process then diffuses to layer 1, followed by layer 1 diffuses to layer 2. This influence diffusion step is repeated for K K K steps to reach the diffusion depth K K K, where each user a a a’s latent embedding at the K K K-th layer is h a K h^K_a haK. (使用预定义的扩散深度 K K K,对于每个用户 a a a,影响扩散层从第0层用户嵌入 h a 0 h^0_a ha0(等式(7))开始,即,融合层的输出,然后逐层影响扩散过程扩散到第1层,然后第1层扩散到第2层。对 K K K个步骤重复该影响扩散步骤以达到扩散深度 K K K,其中每个用户 a a a在第 K K K层的潜在嵌入是 h a K h^K_a haK。)
-
(4) Please note that, DiffNet only diffuses users’ latent vectors in the influence diffusion part without any item vector diffusion modeling. This is quite reasonable as item latent embeddings are static and do not propagate in the social network. (请注意,DiffNet仅在影响扩散部分扩散用户的潜在向量,而没有任何项目向量扩散建模。这是非常合理的,因为项目潜在嵌入是静态的,不会在社交网络中传播。)
3.1.4 Prediction Layer
- (1) Given each user a a a’s embedding h a K h^K_a haK at the K K K-th layer after the iterative diffusion process, each item i i i’s fusion vector v i v_i vi, we model the predicted preference of user a a a to item i i i as: (考虑到每个用户 a a a的嵌入 h a K h^K_a haK在迭代扩散过程后的第 K K K层,每个项目 i i i的融合向量 v i v_i vi, 我们将用户 a a a对项目 i i i的预测偏好建模为:)
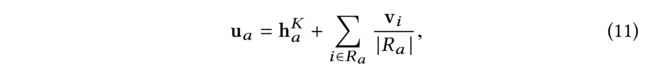
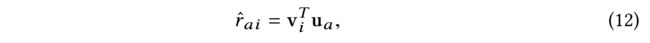
- where R a R_a Ra is the itemset that a a a likes.
- In this equation, each user’s final latent representation u a u_a ua is composed of two parts: (在这个等式中,每个用户的最终潜在表示 u a u_a ua由两部分组成:)
- the embeddings from the output of the social diffusion layers as h a K h^K_a haK, (社会扩散层输出的嵌入)
- and the preferences from her historical behaviors as: ∑ i ∈ R a v i ∣ R a ∣ \sum_{i \in R_a} \frac{vi} {|Ra|} ∑i∈Ra∣Ra∣vi. (以及从历史行为得到的偏好)
- Specifically, the first term captures the user’s interests from the recursive social diffusion process in the social network structure. The second term resembles the SVD++ model that leveraged the historical feedbacks of the user to alleviate the data sparsity of classical CF models [19], which has shown better performance over the classical latent factor based models. Thus, the final user embedding part is more representative with the recursive social diffusion modeling and the historical feedbacks of the user. After that, the final predicted rating is still measured by the inner produce between the corresponding user final latent vector and item latent vector. (具体来说,第一部分从社交网络结构中的递归社交扩散过程中捕捉用户的兴趣。第二项类似于SVD++模型,该模型利用用户的历史反馈来缓解经典CF模型[19]的数据稀疏性,与基于潜在因素的经典模型相比,后者表现出更好的性能。因此,最终的用户嵌入部分在递归的社会扩散模型和用户的历史反馈中更具代表性。之后,最终预测评分仍然由相应的用户最终潜在向量和项目潜在向量之间的内积来衡量。)
3.2 Model Training
-
(1) As we focus on implicit feedbacks of users, similar to the widely used ranking based loss function in BPR [32], we also design a pair-wise ranking based loss function for optimization: (由于我们关注用户的隐式反馈,类似于BPR[32]中广泛使用的基于排名的损失函数,我们还设计了一个基于成对排名的损失函数进行优化)
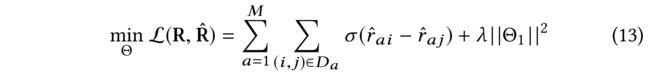
- where σ ( x ) \sigma (x) σ(x) is a sigmoid function.
- Θ = [ Θ 1 , Θ 2 ] \Theta = [\Theta_1, \Theta_2] Θ=[Θ1,Θ2], with Θ 1 = [ P , Q ] \Theta_1= [P, Q] Θ1=[P,Q], and Θ 2 = [ F , [ W k ] k = 0 K − 1 ] \Theta_2=[F, {[W^k]}^{K−1}_{k=0}] Θ2=[F,[Wk]k=0K−1].
- λ \lambda λ is a regularization parameter that controls the complexity of user and item free embedding matrices. (是一个正则化参数,用于控制用户和无项嵌入矩阵的复杂性。)
- D a = ( i , j ) ∣ i ∈ R a ∧ j ∈ V − R a D_a = {(i, j) | i \in Ra_ \land j \in V − R_a} Da=(i,j)∣i∈Ra∧j∈V−Ra denotes the pairwise training data for a a a with R a R_a Ra represents the itemset that a a a positively shows feedback. (表示 a a a的成对训练数据表示, R a R_a Ra表示 a a a积极显示反馈的项目集。)
-
(2) All the parameters in the above loss function are differentiable. In practice, we implement the proposed model with TensorFlow1 to train model parameters with mini-batch Adam. We split the minibatch according to the userset, i.e., each user’s training records are ensured in the same mini-batch. This mini-batch splitting procedure avoids the repeated computation of each user a’s latent embedding h a K h^K_a haK in the iterative influence diffusion layers. (上述损失函数中的所有参数都是可微的。在实践中,我们用TensorFlow1实现了所提出的模型,用mini-batch Adam训练模型参数。我们根据用户集分割小批量,即确保每个用户的培训记录在同一个小批量中。在迭代影响扩散层中, 这种小批量拆分过程避免了重复计算每个用户a的潜在嵌入 h a K h^K_a haK。)
-
(3) As we could only observe positive feedbacks of users with huge missing unobserved values, similar as many implicit feedback works, for each positive feedback, we randomly sample 10 missing unobserved feedbacks as pseudo negative feedbacks at each iteration in the training process [39, 40]. As each iteration the pseudo negative samples change, each missing value gives very weak negative signal. (由于我们只能观察到用户的正反馈,并且存在大量未观察到的缺失值,类似于许多隐式反馈的工作原理,对于每个正反馈,我们在训练过程中的每次迭代中随机抽取10个缺失的未观察到的反馈作为伪负反馈[39,40]。随着每次迭代伪负样本的变化,每个缺失值都会给出非常微弱的负信号。)
3.3 Discussion
3.3.1 Complexity.
Space complexity. As shown in Eq.(13), the model parameters are composed of two parts: (如式(13)所示,模型参数由两部分组成:)
- the user and item free embeddings Θ 1 = [ P , Q ] \Theta_1=[P, Q] Θ1=[P,Q],
- and the parameter set Θ 2 = [ F , [ W k ] k = 0 K − 1 ] \Theta_2 = [F, [W^k]^{K−1}_{k=0}] Θ2=[F,[Wk]k=0K−1].
- Since most embedding based models (e.g., BPR [32], FM [31]) need to store the embeddings of each user and each item, the space complexity of Θ 1 \Theta_1 Θ1 is the same as classical embedding based models and grows linearly with users and items. (由于大多数基于嵌入的模型(例如BPR[32],FM[31])需要存储每个用户和每个项目的嵌入,因此 Θ 1 \Theta_1 Θ1的空间复杂度 与经典的基于嵌入的模型相同,并随用户和项目线性增长。)
- For parameters in Θ 2 \Theta_2 Θ2, they are shared among all users and items, with the dimension of each parameter is far less than the number of users and items. This additional storage cost is a small constant that could be neglected. (对于 θ 2 θ_2 θ2中的参数 , 它们在所有用户和项目之间共享,每个参数的维度远小于用户和项目的数量。这个额外的存储成本是一个可以忽略的小常数。)
- Therefore, the space complexity of DiffNet is the same as classical embedding models. (因此,DiffNet的空间复杂度与经典嵌入模型相同。)
Time complexity. Since our proposed loss function resembles the BPR model with the pair-wise loss function that is designed for implicit feedback, we compare the time complexity of DiffNet with BPR. (由于我们提出的损失函数类似于 BPR 模型,具有为隐式反馈设计的 成对损失函数 ,因此我们比较了DiffNet和BPR的时间复杂度。)
- The main additional time cost lies in the layer-wise influence diffusion process. (主要的额外时间成本在于分层影响扩散过程。)
- The dynamic diffusion process costs O ( M K L ) O(M K L) O(MKL),
- where M M M is the number of users, (其中 M M M是用户数,)
- and K K K denotes the diffusion depth ( K K K表示扩散深度)
- and L L L denotes the average social neighbors of each user. ( L L L表示每个用户的平均社交邻居。)
- Similarly, the additional time complexity of updating parameters is O ( M K L ) O(M K L) O(MKL). (同样,更新参数的额外时间复杂度)
- Therefore, the additional time complexity is O ( M K L ) O(M K L) O(MKL). (因此,额外的时间复杂度是)
- In fact, as shown in the empirical findings as well as our experimental results, DiffNet reaches the best performance when K = 2. Also, the average social neighbors per user are limited with L ≪ M. Therefore, the additional time complexity is acceptable and the proposed DiffNet could be applied to real-world social recommender systems. (事实上,正如实证结果和我们的实验结果所示,当K=2时,DiffNet达到最佳性能。此外,每个用户的平均社交邻居也受到 L ≪ M L \ll M L≪M的限制。因此,额外的时间复杂度是可以接受的,所提出的DiffNet可以应用于现实世界的社会推荐系统。)
3.3.2 Model Generalization.
-
(1) The proposed DiffNet model is designed under the problem setting with the input of user feature matrix X X X, item feature matrix Y Y Y, and the social network S S S. Specifically, (提出的DiffNet模型是在问题设置下设计的,输入用户特征矩阵 X X X、项目特征矩阵 Y Y Y 和 社交网络 S S S。)
- the fusion layer takes users’ (items’) feature matrix for user (item) representation learning. ( 融合层采用用户(项目)特征矩阵进行用户(项目)表示学习)
- The layer-wise diffusion layer utilized the social network structure S S S to model how users’ latent preferences are dynamically influenced from the recursive social diffusion process. ( 分层扩散层利用社会网络结构 S S S来模拟用户的潜在偏好如何受到递归社会扩散过程的动态影响 )
- Next, we would show that our proposed model is generally applicable when different kinds of data input are not available. 。接下来,我们将证明,当不同类型的数据输入不可用时,我们提出的模型通常是适用的。 )
-
(2) When the user (item) features are not available, the fusion layer disappears. In other words, as shown in Eq.(8), each item’s latent embedding v i v_i vi degenerates to q i q_i qi. Similarly, each user’s initial layer-0 latent embedding h 0 = p a h^0=p_a h0=pa (Eq.(7)). Similarly, when either the user attributes or the item attributes do not exist, the corresponding fusion layer of user or item degenerates. (当用户(项目)特征不可用时,融合层消失。换句话说,如等式(8)所示,每个项目的潜在嵌入 v i v_i vi退化为$q_i 0. 同 样 , 每 个 用 户 的 初 始 层 − 0 潜 隐 嵌 入 0. 同样,每个用户的初始层-0潜隐嵌入 0.同样,每个用户的初始层−0潜隐嵌入h^0=p_a$(等式(7))。同样,当用户属性或项目属性不存在时,相应的用户或项目融合层退化。)
-
(3) The key idea of our proposed model is the carefully designed social diffusion layers with the input social network S S S. When the recommender system does not contain any social network information, the social diffusion layers disappear with h a K = h a 0 h^K_a= h^0_a haK=ha0. Under
this circumstances, as shown in Eq. (12) our proposed model degenerates to an enhanced SVD++ model [19] for recommendation, with the user and item latent embeddings contain the fused free embeddings and the associated user and item features. (我们提出的模型的核心思想是精心设计的带有输入社会网络 S S S的社会扩散层。当推荐系统不包含任何社交网络信息时,社交扩散层随着 h a K = h a 0 h^K_a= h^0_a haK=ha0消失. 在这种情况下,如等式(12)所示,我们提出的模型退化为一个增强的SVD++模型[19],用于推荐,用户和项目潜在嵌入包含融合的自由嵌入以及相关的用户和项目特征。)
3.3.3 Comparisons to Graph Convolutional based Models.
-
(1) In our proposed DiffNet, the designed layer-wise diffusion part (Eq.(9) and Eq.(10)) presents similar idea as the Graph Convolutional Networks (GCN), which are state-of-the-art representation learning techniques of graphs [11, 18, 36]. (在我们提出的DiffNet中,设计的分层扩散部分(等式(9)和等式(10))呈现出与图卷积网络(GCN)类似的想法,后者是最先进的图表示学习技术[11,18,36])
- GCNs generate node embeddings in a recursive message passing or information diffusion manner of a graph, where the representation vector of a node is computed recursively from aggregation features in neighbor nodes. (GCN以图的递归消息传递或信息扩散方式生成节点嵌入,其中节点的表示向量是根据相邻节点中的聚合特征递归计算的。)
- GCNs has shown theoretical elegance as simplified version of spectral based graph models [18]. Besides, GCNs are time efficient and achieve better performance in many graph-based tasks. (GCNs作为基于谱的图形模型的简化版本,在理论上表现出了优雅[18]。此外,GCN在许多基于图形的任务中具有时间效率和更好的性能。)
-
(2) Due to the success of GCNs, several models have attempted to transfer the idea of GCNs for the recommendation tasks. By transferring these models to the recommendation scenario, the main components are how to construct a graph and further exploit the uniqueness of recommendation properties. Among them, the most closely related works are GC-MC [36] and PinSage [36]. (由于GCN的成功,有几个模型试图将GCN的思想转移到推荐任务中。通过将这些模型转移到推荐场景中,主要的组成部分是如何构造一个图,并进一步利用推荐属性的唯一性。其中,关系最密切的作品是GC-MC[36]和PinSage[36]。)
GC-MC: It is one of the first few attempts that directly applied the graph convolutions for recommendation. GC-MC defines a user-item bipartite graph from user-item interaction behavior [36]. Then, each user embedding is convolved as the aggregation of the embeddings of her rated items. Similarly, each item embedding= is convolved as the =aggregation of the embeddings of the rated users’ embeddings. (这是直接将图卷积应用于推荐的最初几次尝试之一。GC-MC根据用户项交互行为定义用户项二部图[36]。然后,每个用户嵌入被卷积为其分级项目嵌入的集合。类似地,每个项目嵌入被卷积为额定用户嵌入的嵌入的集合。)
- However, the graph convolution is only operated with one layer of the observed links between users and items, neglecting the layer-wise diffusion structure of the graph. (然而,图卷积只对用户和项目之间的一层观察链接进行操作,忽略了图的分层扩散结构。)
PinSage: It is designed for similar item recommendation from a large recommender system. By constructing an item-item correlation graph from users’ behaviors, a data-efficient GCN algorithm PinSage is developed [44]. (它是为大型推荐系统中的类似项目推荐而设计的。通过根据用户的行为构建项目关联图,开发了一种数据高效的GCN算法PinSage[44]。)
- PinSage could incorporate both the item correlation graph as well as node features to generate item embeddings. (PinSage可以结合项目关联图和节点特征来生成项目嵌入。)
- The main contribution lies in how to design efficient sampling techniques to speed up the training process. (主要贡献在于如何设计有效的采样技术来加快训练过程。)
Instead of message passing on item-item graph, our work performs the recursive information diffusion of the social network, which is more realistic to reflect how users are dynamically influenced by the social influence diffusion. Applying GCNs for social recommendation is quite natural and to the best of our knowledge, has not been studied before. (我们的工作不是在项目图上传递消息,而是执行社交网络的递归信息扩散,这更真实地反映了用户如何动态地受到社会影响扩散的影响。将GCN应用于社会推荐是很自然的,据我们所知,这是以前从未研究过的。)
4 EXPERIMENTS
In this section, we conduct experiments to evaluate the performance of DiffNet on two datasets. (在本节中,我们将在两个数据集上进行实验,以评估DiffNet的性能。)
4.1 Experimental Settings
4.1.1 Datasets
-
(1) Yelp is an online location-based social network. Users make friends with others and express their experience through the form of reviews and ratings. As each user give ratings in the range [0,5], similar to many works, we transform the ratings that are larger than 3 as the liked items by this user. As the rich reviews are associated with users and items, we use the popular gensim tool (https://radimrehurek.com/gensim/) to learn the embedding of each word with Word2vec model [26]. Then, we get the feature vector of each user (item) by averaging all the learned word vectors of the user(item). (Yelp是一个基于位置的在线社交网络。用户与他人交朋友,并通过评论和评分的形式表达他们的体验。由于每个用户给出的评分在[0,5]范围内,与许多作品类似,我们将大于3的评分转换为该用户喜欢的项目。由于丰富的评论与用户和项目相关,我们使用流行的gensim工具(https://radimrehurek.com/gensim/)使用Word2vec模型学习每个单词的嵌入[26]。然后,通过对用户(项)的所有学习词向量进行平均,得到每个用户(项)的特征向量。)
-
(2) Flickr is a who-trust-whom online image based social sharing platform. Users follow other users and share their preferences to images to their social followers. Users express their preferences through the upvote behavior. For research purpose, ((Flickr是一个基于谁信任谁的在线图像社交共享平台。用户跟随其他用户,并将他们对图像的偏好分享给他们的社交关注者。用户通过向上投票的行为表达他们的偏好。出于研究目的,))
- we crawl a large dataset from this platform.
- Given each image, we have a ground truth classification of this image on the dataset. (给定每幅图像,我们在数据集上对这幅图像进行了一个基本真相分类。)
- We send images to a VGG16 convolutional neural network and treat the 4096 dimensional representation in the last connected layer in VGG16 as the feature representation of the image [33]. (我们将图像发送到VGG16卷积神经网络,并将VGG16中最后一个连接层中的4096维表示作为图像的特征表示[33]。)
- For each user, her feature representation is the average of the image feature representations she liked in the training data. (对于每个用户,她的特征表示是她在训练数据中喜欢的图像特征表示的平均值。)
-
(3) In the data preprocessing step, for both datasets, we filtered out users that have less than 2 rating records and 2 social links, and removed the items which have been rated less than 2 times. (在数据预处理步骤中,对于这两个数据集,我们筛选出评分记录和社交链接少于2次的用户,并删除评分少于2次的项目。)
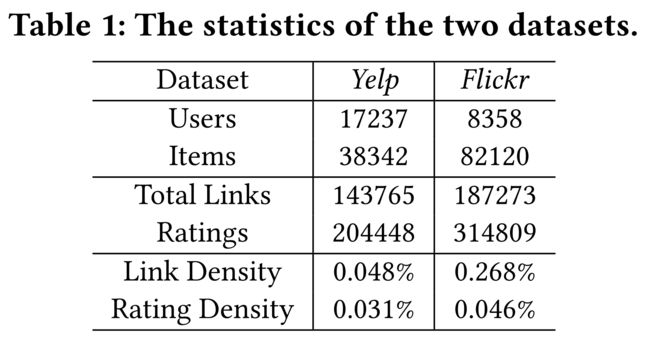
- We randomly select 10% of the data for the test. In the remaining 90% data, to tune the parameters, we select 10% from the training data as the validation set. The detailed statistics of the data after preprocessing is shown in Table 1.
4.1.2 Baselines and Evaluation Metrics.
-
(1) We compare DiffNet with various state-of-the-art baselines, including
- the classical pair-wise based recommendation model BPR [32], (经典的基于对的推荐模型BPR[32],)
- feature enhanced latent factor model FM [30], (特征增强潜在因素模型FM[30],)
- a state-of-the-art social recommendation model TrustSVD [7], (最先进的社会推荐模型TrustSVD[7],)
- a context-aware social recommendation model ContextMF that utilized the same input as our proposed model for recommendation [16]. (一个上下文感知的社会推荐模型ContextMF,它使用了与我们建议的推荐模型相同的输入[16]。)
- Besides, we also compare our proposed model with two graph convolutional based recommendation models: (此外,我们还将我们提出的模型与两种基于图卷积的推荐模型进行了比较)
- GC-MC [36]
- and PinSage [44].
- As the original PinSage focuses on generating high-quality embeddings of items, we generalize this model by constructing a user-item bipartite for recommendation [44]. (由于最初的PinSage专注于生成高质量的项目嵌入,我们通过构建用户项目二部来推广该模型,以供推荐[44]。)
- Both of these two convolutional recommender models utilized the user-item bipartite and the associated features of users and items for recommendation. (这两个卷积推荐模型都利用了用户项的二分性以及用户和推荐项的相关特征。)
-
(2) As we focus on recommending top-N items for each user, we use two widely adopted ranking based metrics: (当我们专注于为每个用户推荐前N项时,我们使用了两种广泛采用的基于排名的指标:)
- Hit Ratio (HR) (命中率(HR))
- and Normalized Discounted Cumulative Gain(NDCG) [34]. (以及归一化贴现累积增益(NDCG)[34]。)
- Specifically, HR measures the number of items that the user likes in the test data that has been successfully predicted in the top-N ranking list. (具体来说,HR测量用户在测试数据中喜欢的项目数量,这些项目已成功预测在排名前N的列表中。)
- And NDCG considers the hit positions of the items and gives a higher score if the hit items in the top positions. For both metrics, the larger the values, the better the performance. (NDCG会考虑项目的命中位置,如果命中项目位于顶部位置,则会给出更高的分数。对于这两个指标,值越大,性能越好。)
- Since there are too many unrated items, in order to reduce the computational cost, for each user, we randomly sample 1000 unrated items at each time and combine them with the positive items the user likes in the ranking process. We repeat this procedure 10 times and report the average ranking results. (由于未评分项目太多,为了降低计算成本,我们对每个用户每次随机抽取1000个未评分项目,并将其与用户在排名过程中喜欢的积极项目相结合。我们重复这个过程10次,并报告平均排名结果。)
4.1.3 Parameter Setting.
- (1) For all the models that are based on the latent factor models, we initialize the latent vectors with small random values. (对于所有基于潜在因子模型的模型,我们用小的随机值初始化潜在向量。)
- In the model learning process, we use Adam as the optimizing method for all models that relied on the gradient descent based methods with an initial learning rate of 0.001. (在模型学习过程中,我们使用Adam作为所有依赖基于梯度下降的方法的模型的优化方法,初始学习率为0.001。)
- And the batch size is set as 512. In our proposed DiffNet model, we try the regularization parameterλ in the range [0.0001,0.001,0.01,0.1], (批量大小设置为512。在我们提出的DiffNet模型中,我们尝试在[0.0001,0.001,0.01,0.1]范围内使用正则化参数λ,)
- and find λ = 0.001 reaches the best performance. (并发现λ=0.001达到最佳性能。)
- For the aggregation function in Eq.(9), we have tried the max pooling and average pooling. We find the average pooling usually shows better performance. Hence, we set the average pooling as the aggregation function. (对于等式(9)中的聚合函数,我们尝试了最大池和平均池。我们发现平均池通常表现出更好的性能。因此,我们将平均池设置为聚合函数。)
- Similar to many GCN models [18, 44], we set the depth parameter K = 2. (与许多GCN模型[18,44]类似,我们设置了深度参数K=2。)
- With the user and item free embedding size D, in the fusion layer and the following influence diffusion layers, each layer’s output is also set as D dimension. (在融合层和后续影响扩散层中,使用用户和项目自由嵌入尺寸D,每个层的输出也设置为D维。)
- For the non-linear function g(x) in the fusion layer, we use a sigmoid function that transforms each value into range (0,1). (对于融合层中的非线性函数g(x),我们使用一个sigmoid函数将每个值转换为范围(0,1)。)
- And we set the non linear functions of [ s k ( x ) ] k = 0 K − 1 [s^k(x)]^{K−1}_{k=0} [sk(x)]k=0K−1 with the ReLU function to avoid the vanishing gradient problem. (使用ReLU函数来避免消失梯度问题。)
- After the training of each layer, we use batch normalization to avoid the internal covariate shift problem [14]. There are several parameters in the baselines, we tune all these parameters to ensure the best performance of the baselines for fair comparison. Please note that as generating user and item features are not the focus of our paper, we use the feature construction techniques as mentioned above. However, our proposed model can be seamlessly incorporated with more advanced feature engineering techniques. (在对每一层进行训练后,我们使用批量归一化来避免 内部协变量移位问题 [14]。基线中有几个参数,我们调整所有这些参数以确保基线的最佳性能,以便进行公平比较。请注意,由于生成用户和项目特征不是本文的重点,我们使用了上述特征构建技术。然而,我们提出的模型可以与更先进的特征工程技术无缝结合。)
4.2 Overall Comparison
-
(1) In this section, we compare the overall performance of all models on two datasets. ()在本节中,我们将比较两个数据集上所有模型的总体性能。
-
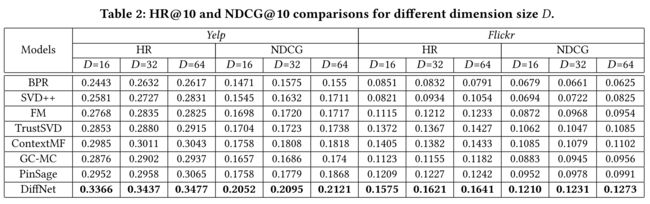
Specifically, Table 2 shows the HR@10 and NDCG@10 results for both datasets with varying latent dimension size D. (具体而言,表2显示了HR@10和NDCG@10两个数据集的结果都具有不同的潜在维度大小D。)
-
Among all the baselines, BPR only considered the user-item rating information for recommendation, (在所有的基线中,BPR只考虑了推荐的用户项目评级信息,)
-
FM and TrustSVD improve over BPR by leveraging the node features and social network information. (FM和TrustSVD通过利用节点功能和社交网络信息来改进BPR。)
-
PinSage takes the same kind of input as FM and shows better performance than FM, showing the effectiveness of modeling the information passing of a graph. (PinSage采用与FM相同的输入类型,并显示出比FM更好的性能,显示了对图形信息传递建模的有效性。)
-
ContextMF is the baseline that uses the user and item features, as well as the social network structure. It performs better than most baselines. (ContextMF是使用用户和项目功能以及社交网络结构的基线。它的性能比大多数基线都好。)
-
Our proposed model consistently outperforms ContextMF, showing the effectiveness of modeling the recursive social diffusion process in the social recommendation process. (我们提出的模型始终优于ContextMF,表明了在社会推荐过程中对递归社会扩散过程建模的有效性。)

-
(2) When comparing the results of the two datasets, we observe that leveraging the social network structure and the social diffusion process contributes more on Flickr compared to Yelp. (在比较这两个数据集的结果时,我们观察到,与Yelp相比,利用社交网络结构和社交扩散过程对Flickr的贡献更大。)
-
On both datasets, PinSAGE is the best baseline that leverages the node features without the social network information. E.g., DiffNet improves over PinSAGE about 13% on Yelp, and nearly 30% on Flickr. We guess a possible reason is that, the Flickr is a social based image sharing platform with a stronger social influence diffusion effect. (在这两个数据集上,PinSAGE是在不使用社交网络信息的情况下利用节点功能的最佳基线。例如,DiffNet在Yelp上比PinSAGE提高了约13%,在Flickr上提高了近30%。我们猜测一个可能的原因是,Flickr是一个基于社交的图像共享平台,具有更强的社会影响力扩散效应。)
-
In contrast, Yelp is a location based social network, and users’ food and shopping preferences are not easily influenced in the social platform. (相比之下,Yelp是一个基于位置的社交网络,用户的食物和购物偏好在社交平台上不容易受到影响。)
-
Last but not least, we find the performance of all models does not increase as the latent dimension size D increases from 16 to 64. Some models reach the best performance when D = 32 (e.g., BPR) while other models reach the best performance when D = 64 (e.g., DiffNet). In the following experiment, we set the proper D for each model with the best performance in order to ensure fairness. (最后但并非最不重要的是,我们发现所有模型的性能并不会随着潜在维度D从16增加到64而增加。一些模型在D=32(例如BPR)时达到最佳性能,而其他型模型在D=64(例如DiffNet)时达到最佳性能。在接下来的实验中,我们为每个性能最好的模型设置了合适的D,以确保公平性。)
-
(3) Table 3 shows the HR@N and NDCG@N on both datasets with varying top-N recommendation size N. From the results, we also find similar observations as Table 2, with our proposed model DiffNet always shows the best performance. Based on the overall experiment results, we could empirically conclude that our proposed DiffNet model outperforms all the baselines under different ranking metrics and different parameters. (表3显示了HR@N和NDCG@N在两个具有不同top-N推荐大小N的数据集上。从结果中,我们还发现类似于表2的观察结果,我们提出的模型DiffNet总是表现出最好的性能。基于整体实验结果,我们可以经验地得出结论,我们提出的DiffNet模型在不同的排名指标和不同的参数下优于所有基线。)
4.3 Performance under Different Data Sparsity
- (1) The data sparsity issue is a main challenge for most CF based recommender systems. In this part, we would like to show the performance of various models under different sparsity. (数据稀疏性问题是大多数基于CF的推荐系统面临的主要挑战。在这一部分中,我们将展示各种模型在不同稀疏度下的性能。)
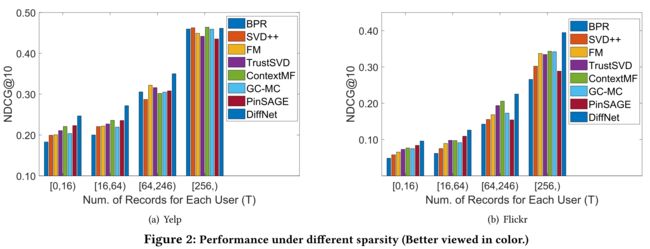
- (2) Specifically, we bin users into different groups based on the number of observed feedbacks in the training data. Then we show the performance of each group with different models on NDCG@10 in Fig 2. In this figure, the horizontal axis shows the user group information. E.g., [16,64) means for each user in this group, the training records satisfy 16 ≤ |Ra| < 64. (具体来说,我们根据训练数据中观察到的反馈数量将用户分为不同的组。然后,我们在屏幕上展示了不同模型的各组的性能NDCG@10在图2中。在该图中,横轴显示用户组信息。例如,[16,64]表示对于该组中的每个用户,训练记录满足16≤ |Ra |<64。)
- As can be observed from this figure, for both datasets, with the increase of the user rating records, the performance increases quickly for all models. When the rating records of each user is less than 16, the BPR baseline could not work well as this model only exploited the very sparse user-item interaction behavior for recommendation. Under this situation, all improvement is significant by leveraging various kinds of side information. E.g., FM, SVD++, and ContextMF improves over BPR by 9.6%, 15.2% and 20.7% on Yelp, and 34.9%, 50.3%, 58.4% on Flickr. (从该图可以看出,对于这两个数据集,随着用户评级记录的增加,所有模型的性能都会快速提高。当每个用户的评分记录小于16时,BPR基线无法很好地工作,因为该模型仅利用非常稀疏的用户项交互行为进行推荐。在这种情况下,通过利用各种辅助信息,所有改进都是显著的。例如,FM、SVD++和ContextMF在Yelp上比BPR提高了9.6%、15.2%和20.7%,在Flickr上分别提高了34.9%、50.3%和58.4%。)
- The improvement of Flick is much more significant than that of Yelp, as Flickr has much more items compared to Yelp. By considering the iteratively social diffusion process in social recommendation, our proposed model improves BPR by 34.8% and 97.1% on Flick and Yelp, which far exceeds the remaining models. With the increase of user rating records, the performance improvements of all models over BPR decrease, but the overall trend is that all models have better performance than BPR. (Flick的改进比Yelp显著得多,因为Flickr的项目比Yelp多得多。通过考虑社会推荐中的迭代社会扩散过程,我们提出的模型在Flick和Yelp上分别提高了34.8%和97.1%的BPR,远远超过了其他模型。随着用户评分记录的增加,所有模型相对于BPR的性能改进都有所下降,但总体趋势是所有模型的性能都优于BPR。)
- We also observe that when users have more than 256 records, some methods have similar results as BPR or even a little worse than BPR. We guess a possible reason is that BPR could well learn the user interests from enough interaction data. Withe the additional side information, some noises are introduced to decrease the performance. (我们还观察到,当用户有超过256条记录时,一些方法的结果与BPR相似,甚至比BPR差一点。我们猜测一个可能的原因是BPR可以从足够的交互数据中很好地了解用户的兴趣。由于附加的旁侧信息,会引入一些噪声来降低性能。)
4.4 Detailed Model Analysis
-
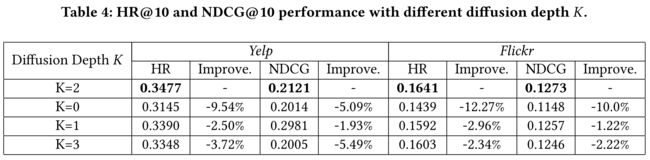
(1) We would analyze the recursive social diffusion depth K, and the impact of the fusion layer that combines the collaborative free embedding and associated entity feature vector. (我们将分析递归的社会扩散深度K,以及结合协作自由嵌入和关联实体特征向量的融合层的影响。)
-
(2) Table 4 shows the results on DiffNet with different K values. The column of “Improve” show the performance changes compared to the best setting of DiffNet, i.e., K = 2. When K = 0, the layer-wise diffusion part disappears, and our proposed model degenerates to an enhanced SVD++ with entity feature modeling. (表4显示了DiffNet上具有不同K值的结果。“改进”一栏显示了与DiffNet的最佳设置(即K=2)相比的性能变化。当K=0时,分层扩散部分消失,我们提出的模型退化为具有实体特征建模的增强SVD++模型。)
-
As can be observed from this figure, as we leverage the layer wise diffusion process fromK = 0 to K = 1, the performance increases quickly for for both datasets. For both datasets, the best performance reaches with two recursive diffusion depth, i.e., K = 2. When K continues to increase to 3, the performance drops for both datasets. We hypothesis that, considering the K-step recursive social diffusion process resembles the k-hop neighbors of each user. Since the social diffusion diminishes with time and the distance between each user and the k-hop neighbors, setting K with 2 is enough for social recommendation. In fact, other related studies have empirically find similar trends, with the best diffusion size is set as K = 2 or K = 3 [18, 44]. (从图中可以看出,当我们利用从K=0到K=1的分层扩散过程时,两个数据集的性能都会快速提高。对于这两个数据集,在两个递归扩散深度(即K=2)下达到最佳性能。当K继续增加到3时,两个数据集的性能都会下降。我们假设,考虑到K步递归社会扩散过程类似于每个用户的K-hop邻居。由于社交扩散会随着时间和每个用户与k-hop邻居之间的距离而减小,因此将k设置为2就足以进行社交推荐。事实上,其他相关研究在经验上也发现了类似的趋势,最佳扩散大小设定为K=2或K=3[18,44]。)
-
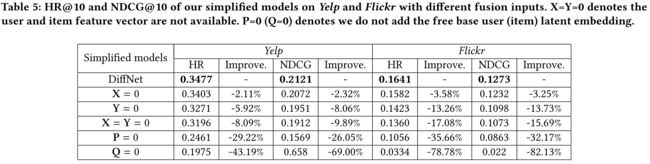
(3) Table 4 shows the performance on DiffNet with different fusion inputs. As can be seen from this figure, the performance drops when the user and (or) item features are not available. We also notice that it is very important to add the free latent embeddings of users and items in the modeling process. As can be observed from this figure, the performance drops very quickly when either the user free latent embedding matrix P or the item free embedding matrix Q are not considered. E.g., the performance drops about 80% on Flickr when the item free embedding is not considered. The reason is that, the item (user) latent factors could not be captured by the item (user) features. Therefore, learning the collaborative effect between users and items with the free embeddings is very important for the recommendation task. (表4显示了DiffNet在不同融合输入下的性能。从这个图可以看出,当用户和(或)项目功能不可用时,性能会下降。我们还注意到,在建模过程中添加用户和项目的自由潜在嵌入非常重要。从该图可以看出,当不考虑用户自由潜在嵌入矩阵P或项目自由嵌入矩阵Q时,性能会迅速下降。例如,如果不考虑无项目嵌入,Flickr的性能会下降约80%。原因是,项目(用户)特征无法捕捉到项目(用户)潜在因素。因此,了解用户和自由嵌入项之间的协作效果对于推荐任务非常重要。)
5 RELATED WORK
5.1 Collaborative Filtering
- (1) Given an user-item rating matrix R, CF usually projected both users and items in a same low latent space for comparison [20]. In reality, compared to the explicit ratings, it is more common for users implicitly express their feedbacks through action or inaction, such as click, add to cart or consumption [32]. (给定一个用户项目评级矩阵R,CF通常将用户和项目都投影到同一个低潜在空间中进行比较[20]。实际上,与显式评分相比,更常见的情况是用户通过行动或不行动(如单击、添加到购物车或消费)隐式表达反馈[32]。)
- Bayesian Personalized Ranking (BPR) is a state-of-the-art latent factor based technique for dealing with implicit feedback. Instead of directly predicting each user’s point-wise explicit ratings, BPR modeled the pair-wise preferences with the assumption that users prefer the observed implicit feedbacks compared to the unobserved ones [32]. Despite the relatively high performance, the data sparsity issue is a barrier to the performance of these collaborative filtering models. (贝叶斯个性化排名(BPR)是一种基于潜在因素的最新技术,用于处理内隐反馈。BPR没有直接预测每个用户的逐点显式评分,而是假设用户更喜欢观察到的隐式反馈,而不是未观察到的反馈[32]。尽管性能相对较高,但数据稀疏性问题是这些协同过滤模型性能的障碍。)
- To tackle the data sparsity issue, many models have been proposed by extending these classical CF models. E.g., SVD++ is proposed to combine users’ implicit feedbacks and explicit feedbacks for modeling users’ latent interests [19]. Besides, as users and items are associated with rich attributes, Factorization Machine (FM) is such a unified model that leverages the user and item attributes in latent factor based models [37]. (为了解决数据稀疏性问题,人们通过扩展这些经典CF模型提出了许多模型。例如,SVD++被提议将用户的隐式反馈和显式反馈结合起来,以建模用户的潜在兴趣[19]。此外,由于用户和项目与丰富的属性相关联,因子分解机(FM)是一种统一的模型,它在基于潜在因子的模型中利用了用户和项目属性[37]。)
- Recently, some deep learning based models have been proposed to tackle the CF problem [12]. As sometimes the user and item features are sparse, many deep learning based models have been proposed to tackle how to model these sparse features [9, 37]. In contrast to these works, we do not consider the scenario of sparse features and put emphasis on how to model the recursive social diffusion process for social recommendation. (最近,有人提出了一些基于深度学习的模型来解决CF问题[12]。由于有时用户和项目特征是稀疏的,因此提出了许多基于深度学习的模型来解决如何对这些稀疏特征建模的问题[9,37]。与这些作品相比,我们没有考虑稀疏特征的场景,而是强调如何对社会推荐的递归社会扩散过程进行建模。)
5.2 Social Recommendation
- (1) Social recommendation leverages the social network among users to enhance recommendation performance [7, 16, 25]. In fact, social scientists have long converged that as information diffuses in the social networks, users are influenced by their social connections with the social influence theory, leading to the phenomenon of similar preferences among social neighbors [3, 4, 23, 29]. (社交推荐利用用户之间的社交网络来提高推荐性能[7,16,25]。事实上,社会学家早就认识到,随着信息在社交网络中的扩散,用户会受到他们与社会影响理论的社会联系的影响,从而导致社会邻居之间出现类似偏好的现象[3,4,23,29]。)
- Social regularization has been empirically proven effective for social recommendation, with the assumption that similar users would share similar latent preferences under the popular latent factor based models [15, 25, 42]. (经验证明,社交规则化对于社交推荐是有效的,假设在流行的基于潜在因素的模型下,相似的用户会共享相似的潜在偏好[15,25,42]。)
- SBPR model is proposed into the pair-wise BPR model with the assumption that users tend to assign higher ratings to the items their friends prefer [45]. By treating the social neighbors’ preferences as the auxiliary implicit feedbacks of an active user, (SBPR模型是在成对BPR模型中提出的,假设用户倾向于将更高的评分分配给他们的朋友喜欢的项目[45]。通过将社交邻居的偏好视为活跃用户的辅助隐性反馈,)
- TrustSVD [7, 8] is proposed to incorporate the trust influence from social neighbors on top of SVD++ [19]. As items are associated with attribute information (e.g., item description, item visual information), (TrustSVD[7,8]建议在SVD++[19]的基础上加入来自社会邻居的信任影响。由于项目与属性信息(例如,项目描述、项目视觉信息)相关联,)
- ContextMF is proposed to combine social context and social network under a collective matrix factorization framework with carefully designed regularization terms [16]. (ContextMF被提议在集体矩阵分解框架下结合社会背景和社会网络,并精心设计正则化项[16]。)
- Social recommendation has also been extended with social circles [28], temporal context [34], and visual item information [38]. Instead of simply considering the local social neighbors of each user, our work differs from these works in explicitly modeling the recursive social diffusion process to better model each user’s latent preference in the global social network. (社交推荐还扩展到社交圈[28]、时间上下文[34]和视觉项目信息[38]。我们的工作与这些工作不同,不是简单地考虑每个用户的本地社交邻居,而是显式地建模递归社交扩散过程,以便更好地建模每个用户在全球社交网络中的潜在偏好。)
5.3 Graph Convolutional Networks and Applications
-
(1) Our proposed model with recursive social diffusion process borrows the recent advances of graph convolutional networks (GCN) [11,18,36]. GCNs have shown success to extend the convolution operation from the regular Euclidean domains to non-Euclidean graph domains. Spectral graph convolutional neural network based approaches provide localized convolutions in the spectral domain [5, 6]. (我们提出的递归社会扩散过程模型借鉴了图卷积网络(GCN)[11,18,36]的最新进展。GCNs已成功地将卷积运算从正则欧几里德图域扩展到非欧几里德图域。基于谱图卷积神经网络的方法在谱域中提供局部卷积[5,6]。)
-
These spectral models usually handle the whole graph simultaneously, and are difficult to parallel or scale to large graphs. (这些谱模型通常同时处理整个图,并且难以并行或缩放到大型图。)
-
Recently, Kipf et al. designed a graph convolutional network (GCN) for semi-supervised learning on graph data, which can be motivated based on the spectral graph convolutional networks [10, 11, 18, 36]. The key idea of GCNs is to generate node embeddings in a message passing or information diffusion manner of a graph, which advanced previous spectral based models with much less computational cost. (最近,Kipf等人设计了一种用于对图形数据进行半监督学习的图卷积网络(GCN),该网络可以基于谱图卷积网络[10,11,18,36]进行激励。GCNs的核心思想是以图的消息传递或信息扩散方式生成节点嵌入,这大大降低了以前基于谱的模型的计算成本。)
-
(2) Researchers also exploited the possibility of applying spectral models and GCNs to recommender systems. As in the collaborative setting, the user-item interaction could be defined as a bipartite graph, some works adopted the spectral graph theory for recommendation [27,46]. (研究人员还探索了将谱模型和GCN应用于推荐系统的可能性。在协作环境中,用户项交互可以定义为一个二部图,一些作品采用谱图理论进行推荐[27,46]。)
-
Nevertheless, these models showed high computational cost and it is non-trivial to incorporate user (item) features in the modeling process. As GCNs showed improved efficiency and effectiveness over the spectral models [18], a few research works exploited GCNs for recommendation [36, 43, 44]. (然而,这些模型显示出很高的计算成本,并且在建模过程中加入用户(项目)特征是非常重要的。由于GCN显示出比光谱模型更高的效率和有效性[18],一些研究工作利用GCN作为建议[36,43,44]。)
-
These models all share the commonality of applying the graph convolution operation that aggregates the information of the graph’s first-order connections. (这些模型都具有应用图卷积运算的共性,该运算聚合了图的一阶连接的信息。)
-
GC-MC is one of the first few attempts that directly applied the graph convolutions on the user-item rating graph [36]. However, the graph convolution is only operated with one layer of the observed links between users and items, neglecting the higher order structure of the graph. (GC-MC是在用户项目评级图上直接应用图卷积的最初几次尝试之一[36]。然而,图卷积只在用户和项目之间观察到的一层链接中操作,忽略了图的高阶结构。)
-
GCMC is proposed for bipartite edge prediction with inputs of user-item interaction matrix [43]. This model is consisted of two steps: constructing a user-user graph and item-item graph from the user-item interaction matrix, then updating user and item vectors are based on the convolutional operations of the constructed graphs. Hence, the performance of GCMC relies heavily on the user-user and item-item construction process, and the two step process is not flexible compared to the end-to-end training process. By constructing an item correlation graph, researchers developed a data-efficient GCN algorithm PinSage, which combines efficient random walks and graph convolutions to generate embeddings of nodes that incorporate both graph structure as well as node feature information [44]. (GCMC被提出用于输入用户项交互矩阵的二部边缘预测[43]。该模型由两个步骤组成:从用户-项目交互矩阵构造用户-用户图和项目-项目图,然后根据所构造图的卷积运算更新用户和项目向量。因此,GCMC的性能在很大程度上依赖于用户和项目构建过程,与端到端培训过程相比,两步过程并不灵活。通过构建项目关联图,研究人员开发了一种数据高效的GCN算法PinSage,该算法将高效随机游动和图卷积结合起来,生成包含图结构和节点特征信息的节点嵌入[44]。)
-
Our work differs from them as we leverage the graph convolution operation for the recursive social diffusion in the social networks, which is quite natural. Besides, our proposed model is general and could be applied when the user (item) attributes or the social network structure is not available. (我们的工作与他们不同,因为我们利用图卷积运算来实现社交网络中的递归社交扩散,这是很自然的。此外,我们提出的模型是通用的,可以在用户(项目)属性或社交网络结构不可用时应用。)
6 CONCLUSIONS
- (1) In this paper, we proposed a DiffNet neural model for social recommendation. (我们提出了一个用于社会推荐的DiffNet神经模型。)
- (2) Our main contribution lies in designing a layer-wise influence diffusion part to model how users’ latent preferences are recursively influenced by the her trusted users. (我们的主要贡献在于设计了一个分层的影响扩散部分,来模拟用户的潜在偏好是如何被他信任的用户递归地影响的。)
- (3) We showed that the proposed DiffNet model is time and storage efficient. It is also flexible when the user and item attributes are not available. (我们证明了所提出的DiffNet模型具有时间和存储效率。当用户和项目属性不可用时,它也很灵活。)
- (4)The experimental results clearly showed the flexibility and effectiveness of our proposed models. E.g., DiffNet improves more than 15% over the best baseline with NDCG@10 on Flickr dataset. In the future, we would like to extend our model for temporal social recommendation, where the temporal changes of users’ interests are implicitly reflected from their temporal feedback patterns. (实验结果清楚地表明了我们提出的模型的灵活性和有效性。例如,DiffNet与最佳基线相比提高了15%以上NDCG@10在Flickr数据集上。在未来,我们希望扩展我们的时态社会推荐模型,在该模型中,用户兴趣的时态变化隐含地反映在他们的时态反馈模式中。)