Transformer相关原理
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 一、Attention
-
- 1.seq2seq
- 2.Attention
- 二、Transformer
-
- 1.Transformer宏观结构
- 2.Transformer结构细节
-
- 输入处理
-
- 词向量
- 位置向量
- 编码器encoder
- Self-Attention层
-
- 多头注意力机制
- 解码器
- 线性层和softmax
- 损失函数
- 附加资料
一、Attention
问题:Attention出现的原因是什么?
潜在的答案:基于循环神经网络(RNN)一类的seq2seq模型,在处理长文本时遇到了挑战,而对长文本中不同位置的信息进行attention有助于提升RNN的模型效果。
1.seq2seq
seq2seq是一种常见的NLP模型结构,全称是:sequence to sequence,翻译为“序列到序列”。顾名思义:从一个文本序列得到一个新的文本序列。典型的任务有:机器翻译任务,文本摘要任务。
seq2seq干了什么事情?seq2seq模型的输入可以是一个(单词、字母或者图像特征)序列,输出是另外一个(单词、字母或者图像特征)序列。以NLP中的机器翻译任务为例,序列指的是一连串的单词,输出也是一连串单词。
seq2seq模型由编码器(Encoder)和解码器(Decoder)组成。绿色的编码器会处理输入序列中的每个元素并获得输入信息,这些信息会被转换成为一个黄色的向量(称为context向量)。当我们处理完整个输入序列后,编码器把 context向量 发送给紫色的解码器,解码器通过context向量中的信息,逐个元素输出新的序列。
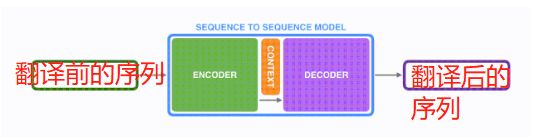
深入学习机器翻译任务中的seq2seq模型。seq2seq模型中的编码器和解码器一般采用的是循环神经网络RNN(Transformer模型还没出现的过去时代)。编码器将输入的法语单词序列编码成context向量(在绿色encoder和紫色decoder中间出现),然后解码器根据context向量解码出英语单词序列。context向量的长度是自定义的,比如可能是256,512或者1024。基于RNN的seq2seq模型的工作过程可视乎。
2.Attention
seq2seq模型处理文本序列(特别是长文本序列)时会遇到什么问题?
基于RNN的seq2seq模型编码器所有信息都编码到了一个context向量中,便是这类模型的瓶颈。一方面单个向量很难包含所有文本序列的信息,另一方面RNN递归地编码文本序列使得模型在处理长文本时面临非常大的挑战(比如RNN处理到第500个单词的时候,很难再包含1-499个单词中的所有信息了)。
通过attention技术,seq2seq模型极大地提高了机器翻译的质量。归其原因是:attention注意力机制,使得seq2seq模型可以有区分度、有重点地关注输入序列。
一个注意力模型与经典的seq2seq模型主要有2点不同:
A. 首先,编码器会把更多的数据传递给解码器。编码器把所有时间步的 hidden state(隐藏层状态)传递给解码器,而不是只传递最后一个 hidden state(隐藏层状态):
B. 注意力模型的解码器在产生输出之前,做了一个额外的attention处理。具体为:
由于编码器中每个 hidden state(隐藏层状态)都对应到输入句子中一个单词,那么解码器要查看所有接收到的编码器的 hidden state(隐藏层状态)。
给每个 hidden state(隐藏层状态)计算出一个分数(我们先忽略这个分数的计算过程)。
所有hidden state(隐藏层状态)的分数经过softmax进行归一化。
将每个 hidden state(隐藏层状态)乘以所对应的分数,从而能够让高分对应的 hidden state(隐藏层状态)会被放大,而低分对应的 hidden state(隐藏层状态)会被缩小。
将所有hidden state根据对应分数进行加权求和,得到对应时间步的context向量。
所以,attention可以简单理解为:一种有效的加权求和技术,其艺术在于如何获得权重。
结合注意力的seq2seq模型解码器全流程(以第四个时间步为例):
- 注意力模型的解码器 RNN 的输入包括:一个word embedding 向量,和一个初始化好的解码器 hidden state。
- RNN 处理上述的 2 个输入,产生一个输出和一个新的 hidden state,记为h4。
- 注意力的步骤:我们使用编码器的所有 hidden state向量和 h4 向量来计算这个时间步的context向量(C4)。
- 我们把 h4 和 C4 拼接起来,得到一个橙色向量。
- 我们把这个橙色向量输入一个前馈神经网络(这个网络是和整个模型一起训练的)。
- 根据前馈神经网络的输出向量得到输出单词:假设输出序列可能的单词有N个,那么这个前馈神经网络的输出向量通常是N维的,每个维度的下标对应一个输出单词,每个维度的数值对应的是该单词的输出概率。
- 在下一个时间步重复1-6步骤。
二、Transformer
通过上一节,我们知晓了attention为循环神经网络带来的优点。那么有没有一种神经网络结构直接基于attention构造,并且不再依赖RNN、LSTM或者CNN网络结构了呢?答案便是:Transformer。
与RNN这类神经网络结构相比,Transformer一个巨大的优点是:模型在处理序列输入时,可以对整个序列输入进行并行计算,不需要按照时间步循环递归处理输入序列。
下图先便是Transformer整体结构图,与上一节中介绍的seq2seq模型类似,Transformer模型结构中的左半部分为编码器(encoder),右半部分为解码器(decoder)

1.Transformer宏观结构
Transformer最开始提出来解决机器翻译任务,因此可以看作是seq2seq模型的一种。我们可以看到,编码部分(encoders)由多层编码器(Encoder)组成(Transformer论文中使用的是6层编码器,这里的层数6并不是固定的,你也可以根据实验效果来修改层数)。同理,解码部分(decoders)也是由多层的解码器(Decoder)组成(论文里也使用了6层解码器)。每层编码器网络结构是一样的,每层解码器网络结构也是一样的。不同层编码器和解码器网络结构不共享参数。

接下来,我们看一下单层encoder,单层encoder主要由以下两部分组成:
- Self-Attention Layer
- Feed Forward Neural Network(前馈神经网络,缩写为 FFNN)
编码器的输入文本序列w1, w2,…,wn
最开始需要经过embedding转换,得到每个单词的向量表示x1, x2,…,xnx ,其中xi ∈R^d 是维度为d的向量,然后所有向量经过一个Self-Attention神经网络层进行变换和信息交互得到h1, h2,…hn
,其中hi∈R^d 是维度为d的向量。self-attention层处理一个词向量的时候,不仅会使用这个词本身的信息,也会使用句子中其他词的信息(你可以类比为:当我们翻译一个词的时候,不仅会只关注当前的词,也会关注这个词的上下文的其他词的信息)。Self-Attention层的输出会经过前馈神经网络得到新的x1, x2,…,xn,依旧是n个维度为d的向量。这些向量将被送入下一层encoder,继续相同的操作。
解码器在编码器的self-attention和FFNN中间插入了一个Encoder-Decoder Attention层,这个层帮助解码器聚焦于输入序列最相关的部分(类似于seq2seq模型中的 Attention)。

宏观来说,Transformer由编码部分和解码部分组成,而编码部分和解码部分又由多个网络结构相同的编码层和解码层组成。每个编码层由self-attention和FFNN组成,每个解码层由self-attention、FFN和encoder-decoder attention组成。
2.Transformer结构细节
输入处理
词向量
和常见的NLP 任务一样,我们首先会使用词嵌入算法(embedding algorithm),将输入文本序列的每个词转换为一个词向量。实际应用中的向量一般是 256 或者 512 维。
。在实际应用中,我们通常会同时给模型输入多个句子,如果每个句子的长度不一样,我们会选择一个合适的长度,作为输入文本序列的最大长度:如果一个句子达不到这个长度,那么就填充先填充一个特殊的“padding”词;如果句子超出这个长度,则做截断。最大序列长度是一个超参数,通常希望越大越好,但是更长的序列往往会占用更大的训练显存/内存,因此需要在模型训练时候视情况进行决定。
输入序列每个单词被转换成词向量表示还将加上位置向量来得到该词的最终向量表示。
位置向量
Transformer模型对每个输入的词向量都加上了一个位置向量。
这些向量有助于确定每个单词的位置特征,或者句子中不同单词之间的距离特征。词向量加上位置向量背后的直觉是:将这些表示位置的向量添加到词向量中,得到的新向量,可以为模型提供更多有意义的信息,比如词的位置,词之间的距离等。
那么带有位置编码信息的向量到底遵循什么模式?原始论文中给出的设计表达式为:

当然,上述公式不是唯一生成位置编码向量的方法。但这种方法的优点是:可以扩展到未知的序列长度。例如:当我们的模型需要翻译一个句子,而这个句子的长度大于训练集中所有句子的长度,这时,这种位置编码的方法也可以生成一样长的位置编码向量。
编码器encoder
编码部分的输入文本序列经过输入处理之后得到了一个向量序列,这个向量序列将被送入第1层编码器,第1层编码器输出的同样是一个向量序列,再接着送入下一层编码器:第1层编码器的输入是融合位置向量的词向量,更上层编码器的输入则是上一层编码器的输出。
下图展示了向量序列在单层encoder中的流动:融合位置信息的词向量进入self-attention层,self-attention的输出每个位置的向量再输入FFN神经网络得到每个位置的新向量。
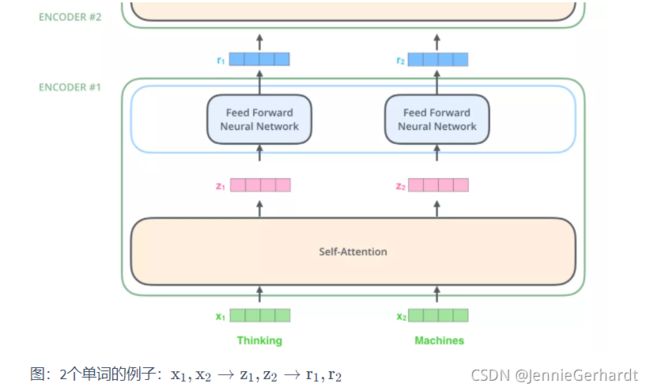
Self-Attention层
当模型处理句子中其他词时,Self Attention机制也可以使得模型不仅仅关注当前位置的词,还会关注句子中其他位置的相关的词,进而可以更好地理解当前位置的词。
self-attention计算的6个步骤进行可视化。
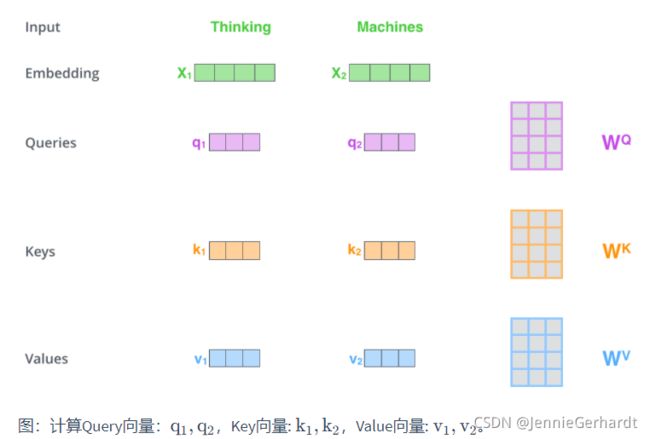
Query 向量,Key 向量,Value 向量是什么含义呢?
其实它们就是 3 个向量,给它们加上一个名称,可以让我们更好地理解 Self-Attention 的计算过程和逻辑。attention计算的逻辑常常可以描述为:query和key计算相关或者叫attention得分,然后根据attention得分对value进行加权求和。
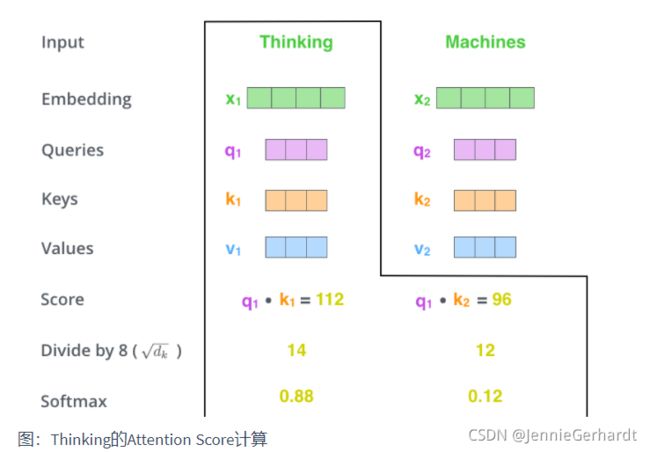
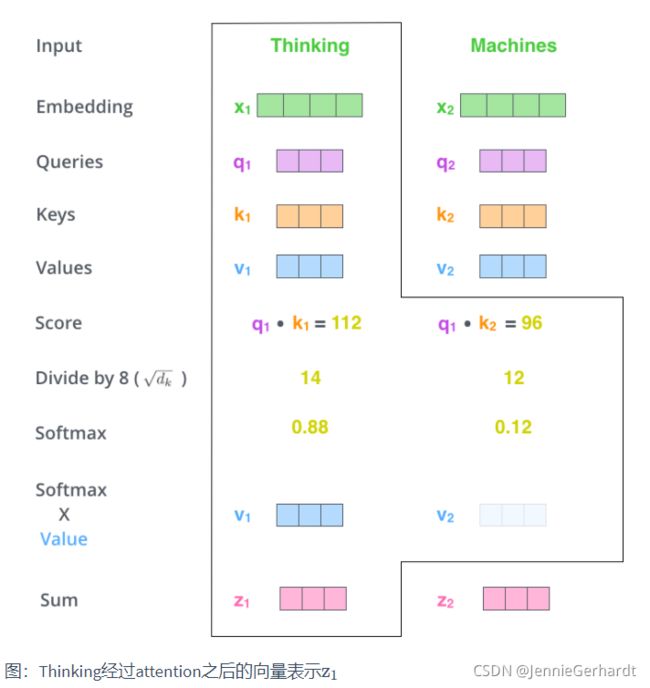
第2步:计算Attention Score(注意力分数)。假设我们现在计算第一个词Thinking 的Attention Score(注意力分数),需要根据Thinking 对应的词向量,对句子中的其他词向量都计算一个分数。这些分数决定了我们在编码Thinking这个词时,需要对句子中其他位置的词向量的权重。
Attention score是根据"Thinking" 对应的 Query 向量和其他位置的每个词的 Key 向量进行点积得到的。Thinking的第一个Attention Score就是q1和k1的内积,第二个分数就是q1和k2的点积。这个计算过程在下图中进行了展示,下图里的具体得分数据是为了表达方便而自定义的。

第3步:把每个分数除以 d k \sqrt{d_k} dk ,dk 是Key向量的维度。你也可以除以其他数,除以一个数是为了在反向传播时,求梯度时更加稳定。
第4步:接着把这些分数经过一个Softmax函数,Softmax可以将分数归一化,这样使得分数都是正数并且加起来等于1, 如下图所示。 这些分数决定了Thinking词向量,对其他所有位置的词向量分别有多少的注意力。
第5步:得到每个词向量的分数后,将分数分别与对应的Value向量相乘。这种做法背后的直觉理解就是:对于分数高的位置,相乘后的值就越大,我们把更多的注意力放到了它们身上;对于分数低的位置,相乘后的值就越小,这些位置的词可能是相关性不大的。
第6步:把第5步得到的Value向量相加,就得到了Self Attention在当前位置(这里的例子是第1个位置)对应的输出。
最后,在下图展示了 对第一个位置词向量计算Self Attention 的全过程。最终得到的当前位置(这里的例子是第一个位置)词向量会继续输入到前馈神经网络。注意:上面的6个步骤每次只能计算一个位置的输出向量,在实际的代码实现中,Self Attention的计算过程是使用矩阵快速计算的,一次就得到所有位置的输出向量。
Self-Attention矩阵计算
将self-attention计算6个步骤中的向量放一起,比如 X = [ x 1 ; x 2 ] X=[x_1;x_2] X=[x1;x2],便可以进行矩阵计算啦。下面,依旧按步骤展示self-attention的矩阵计算方法。
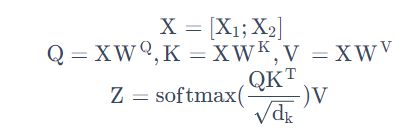
第1步:计算 Query,Key,Value 的矩阵。首先,我们把所有词向量放到一个矩阵X中,然后分别和3个权重矩阵 W Q W^Q WQ, W K W^K WK, W V W^V WV相乘,得到 Q,K,V 矩阵。矩阵X中的每一行,表示句子中的每一个词的词向量。Q,K,V 矩阵中的每一行表示 Query向量,Key向量,Value 向量,向量维度是dk。
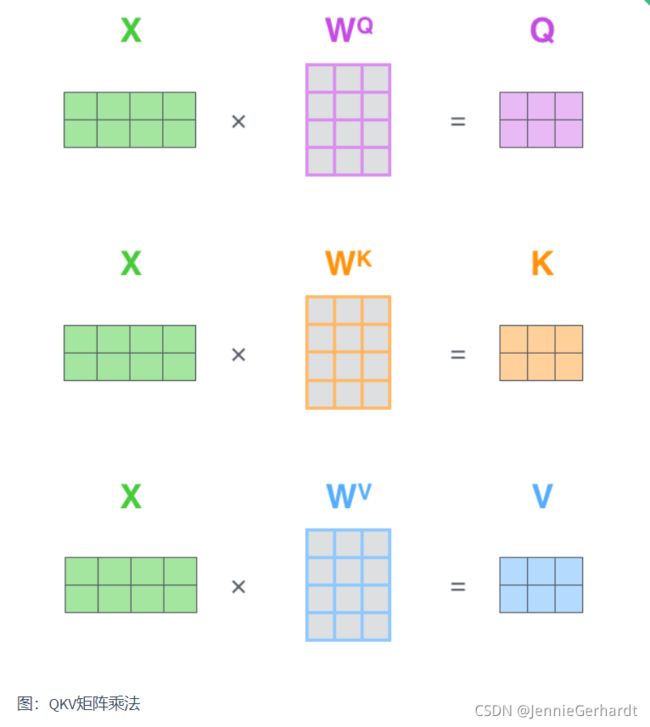
第2步:由于我们使用了矩阵来计算,我们可以把上面的第 2 步到第 6 步压缩为一步,直接得到 Self Attention 的输出。
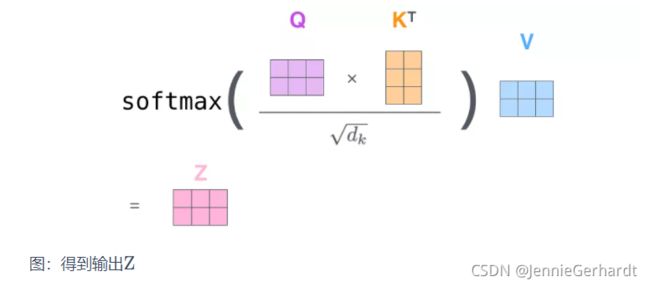
多头注意力机制
Transformer 的论文通过增加多头注意力机制(一组注意力称为一个 attention head),进一步完善了Self-Attention。这种机制从如下两个方面增强了attention层的能力:
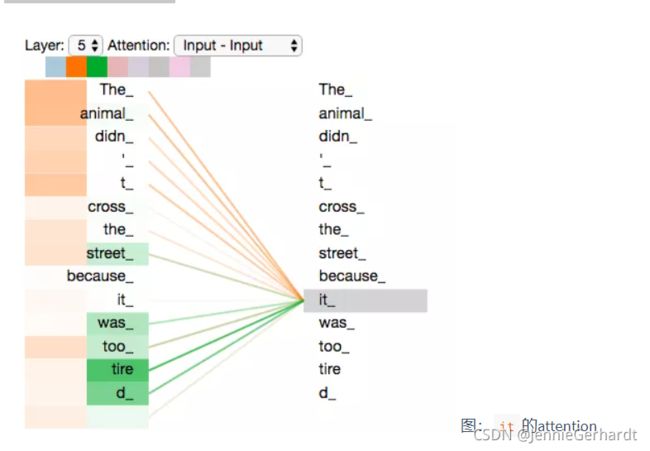
- **它扩展了模型关注不同位置的能力。**在上面的例子中,第一个位置的输出z1包含了句子中其他每个位置的很小一部分信息,但z1仅仅是单个向量,所以可能仅由第1个位置的信息主导了。而当我们翻译句子:The animal didn’t cross the street because it was too tired时,我们不仅希望模型关注到"it"本身,还希望模型关注到"The"和“animal”,甚至关注到"tired"。这时,多头注意力机制会有帮助。
- **多头注意力机制赋予attention层多个“子表示空间”。**下面我们会看到,多头注意力机制会有多组W^Q, W^K W^VW
Q
,W
K
W
V
的权重矩阵(在 Transformer 的论文中,使用了 8 组注意力),,因此可以将XX变换到更多种子空间进行表示。接下来我们也使用8组注意力头(attention heads))。每一组注意力的权重矩阵都是随机初始化的,但经过训练之后,每一组注意力的权重 W Q W^Q WQ, W K W^K WK, W V W^V WV可以把输入的向量映射到一个对应的”子表示空间“。
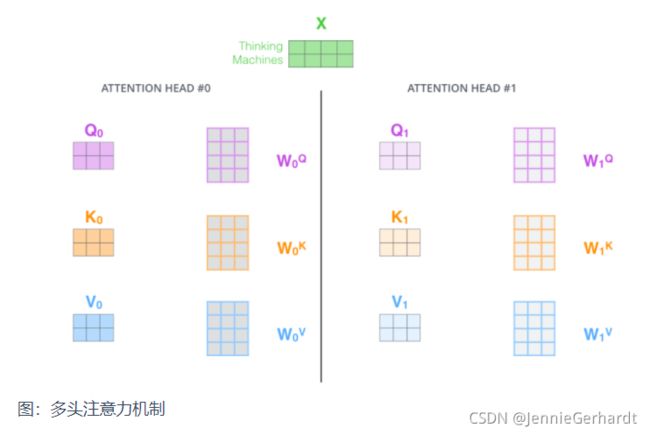
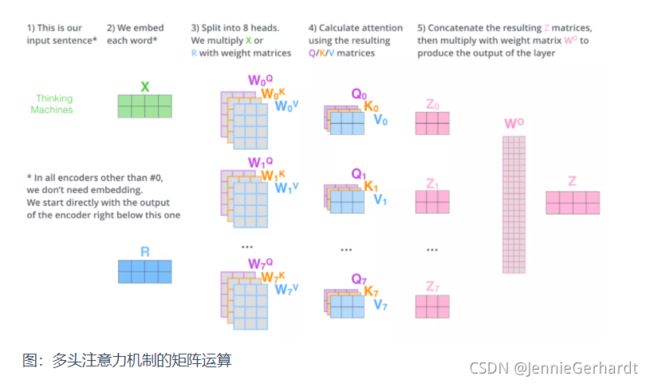
在多头注意力机制中,我们为每组注意力设定单独的 WQ, WK, WV 参数矩阵。将输入X和每组注意力的WQ, WK, WV 相乘,得到8组 Q, K, V 矩阵。
接着,我们把每组 K, Q, V 计算得到每组的 Z 矩阵,就得到8个Z矩阵
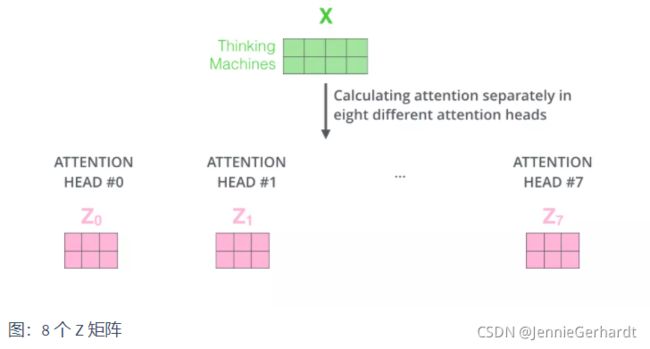
由于前馈神经网络层接收的是 1 个矩阵(其中每行的向量表示一个词),而不是 8 个矩阵,所以我们直接把8个子矩阵拼接起来得到一个大的矩阵,然后和另一个权重矩阵 W O W^O WO相乘做一次变换,映射到前馈神经网络层所需要的维度。

总结一下就是:
- 把8个矩阵 {Z0,Z1…,Z7} 拼接起来
- 把拼接后的矩阵和WO权重矩阵相乘
- 得到最终的矩阵Z,这个矩阵包含了所有 attention heads(注意力头) 的信息。这个矩阵会输入到FFNN (Feed
Forward Neural Network)层。
以上就是多头注意力的全部内容。最后将所有内容放到一张图中:
学习了多头注意力机制,让我们再来看下当我们前面提到的it例子,不同的attention heads (注意力头)对应的“it”attention了哪些内容。下图中的绿色和橙色线条分别表示2组不同的attentin heads:
解码器
编码器一般有多层,第一个编码器的输入是一个序列文本,最后一个编码器输出是一组序列向量,这组序列向量会作为解码器的K、V输入,其中K=V=解码器输出的序列向量表示。这些注意力向量将会输入到每个解码器的Encoder-Decoder Attention层,这有助于解码器把注意力集中到输入序列的合适位置,如下图所示。

解码(decoding )阶段的每一个时间步都输出一个翻译后的单词(这里的例子是英语翻译),解码器当前时间步的输出又重新作为输入Q和编码器的输出K、V共同作为下一个时间步解码器的输入。然后重复这个过程,直到输出一个结束符。

解码器中的 Self Attention 层,和编码器中的 Self Attention 层的区别:
- 在解码器里,Self Attention 层只允许关注到输出序列中早于当前位置之前的单词。具体做法是:在 Self Attention
分数经过 Softmax 层之前,屏蔽当前位置之后的那些位置(将attention score设置成-inf)。 - 解码器 Attention层是使用前一层的输出来构造Query 矩阵,而Key矩阵和 Value矩阵来自于编码器最终的输出。
线性层和softmax
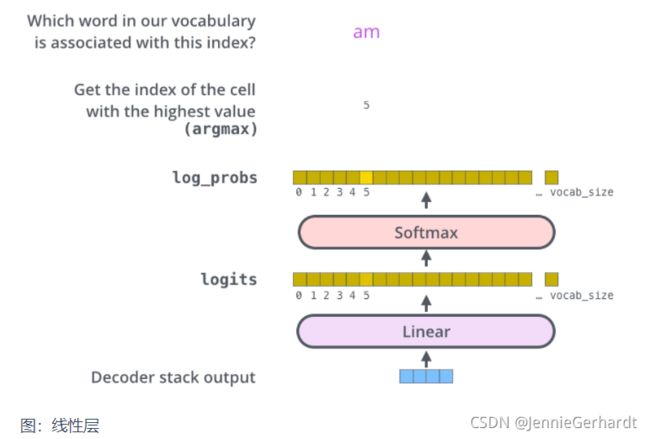
Decoder 最终的输出是一个向量,其中每个元素是浮点数。我们怎么把这个向量转换为单词呢?这是线性层和softmax完成的。
线性层就是一个普通的全连接神经网络,可以把解码器输出的向量,映射到一个更大的向量,这个向量称为 logits 向量:假设我们的模型有 10000 个英语单词(模型的输出词汇表),此 logits 向量便会有 10000 个数字,每个数表示一个单词的分数。
然后,Softmax 层会把这些分数转换为概率(把所有的分数转换为正数,并且加起来等于 1)。然后选择最高概率的那个数字对应的词,就是这个时间步的输出单词。
损失函数
Transformer训练的时候,需要将解码器的输出和label一同送入损失函数,以获得loss,最终模型根据loss进行方向传播。这一小节,我们用一个简单的例子来说明训练过程的loss计算:把“merci”翻译为“thanks”。
我们希望模型解码器最终输出的概率分布,会指向单词 ”thanks“(在“thanks”这个词的概率最高)。但是,一开始模型还没训练好,它输出的概率分布可能和我们希望的概率分布相差甚远,如下图所示,正确的概率分布应该是“thanks”单词的概率最大。但是,由于模型的参数都是随机初始化的,所示一开始模型预测所有词的概率几乎都是随机的。
只要Transformer解码器预测了组概率,我们就可以把这组概率和正确的输出概率做对比,然后使用反向传播来调整模型的权重,使得输出的概率分布更加接近整数输出。
那我们要怎么比较两个概率分布呢?:我们可以简单的用两组概率向量的的空间距离作为loss(向量相减,然后求平方和,再开方),当然也可以使用交叉熵(cross-entropy)]和KL 散度(Kullback–Leibler divergence)。
由于上面仅有一个单词的例子太简单了,我们可以再看一个复杂一点的句子。句子输入是:“je suis étudiant” ,输出是:“i am a student”。这意味着,我们的transformer模型解码器要多次输出概率分布向量:
- 每次输出的概率分布都是一个向量,长度是 vocab_size(前面约定最大vocab size,也就是向量长度是 6,但实际中的vocab
size更可能是 30000 或者 50000) - 第1次输出的概率分布中,最高概率对应的单词是 “i”
- 第2次输出的概率分布中,最高概率对应的单词是 “am”
- 以此类推,直到第 5 个概率分布中,最高概率对应的单词是 “”,表示没有下一个单词了 于是我们目标的概率分布长下面这个样子:
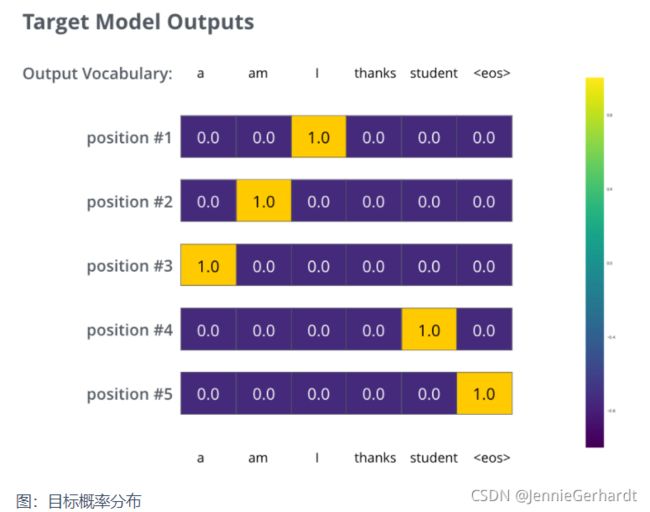
我们用例子中的句子训练模型,希望产生图中所示的概率分布 我们的模型在一个足够大的数据集上,经过足够长时间的训练后,希望输出的概率分布如下图所示:

我们希望模型经过训练之后可以输出的概率分布也就对应了正确的翻译。当然,如果你要翻译的句子是训练集中的一部分,那输出的结果并不能说明什么。我们希望模型在没见过的句子上也能够准确翻译。
附加资料
- 阅读 Transformer 的论文: 《Attention Is All You Need》
链接地址:https://arxiv.org/abs/1706.03762 - 阅读Transformer 的博客文章: 《Transformer: A Novel Neural Network
Architecture for Language Understanding》
链接地址:https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html - 阅读《Tensor2Tensor announcement》
链接地址:https://ai.googleblog.com/2017/06/accelerating-deep-learning-research.html - 观看视频 【Łukasz Kaiser’s talk】来理解模型和其中的细节
链接地址:https://www.youtube.com/watch?v=rBCqOTEfxvg - 运行这份代码:【Jupyter Notebook provided as part of the Tensor2Tensor repo】
链接地址:https://colab.research.google.com/github/tensorflow/tensor2tensor/blob/master/tensor2tensor/notebooks/hello_t2t.ipynb。 - 查看这个项目:【Tensor2Tensor repo】
链接地址:https://github.com/tensorflow/tensor2tensor