一文看懂推荐系统:排序11:Deep & Cross Network(DCN)
一文看懂推荐系统:排序11:Deep & Cross Network(DCN)
提示:最近系统性地学习推荐系统的课程。我们以小红书的场景为例,讲工业界的推荐系统。
我只讲工业界实际有用的技术。说实话,工业界的技术远远领先学术界,在公开渠道看到的书、论文跟工业界的实践有很大的gap,
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
王树森娓娓道来**《小红书的推荐系统》**
GitHub资料连接:http://wangshusen.github.io/
B站视频合集:https://space.bilibili.com/1369507485/channel/seriesdetail?sid=2249610
基础知识:
【1】一文看懂推荐系统:概要01:推荐系统的基本概念
【2】一文看懂推荐系统:概要02:推荐系统的链路,从召回粗排,到精排,到重排,最终推荐展示给用户
【3】一文看懂推荐系统:召回01:基于物品的协同过滤(ItemCF),item-based Collaboration Filter的核心思想与推荐过程
【4】一文看懂推荐系统:召回02:Swing 模型,和itemCF很相似,区别在于计算相似度的方法不一样
【5】一文看懂推荐系统:召回03:基于用户的协同过滤(UserCF),要计算用户之间的相似度
【6】一文看懂推荐系统:召回04:离散特征处理,one-hot编码和embedding特征嵌入
【7】一文看懂推荐系统:召回05:矩阵补充、最近邻查找,工业界基本不用了,但是有助于理解双塔模型
【8】一文看懂推荐系统:召回06:双塔模型——模型结构、训练方法,召回模型是后期融合特征,排序模型是前期融合特征
【9】一文看懂推荐系统:召回07:双塔模型——正负样本的选择,召回的目的是区分感兴趣和不感兴趣的,精排是区分感兴趣和非常感兴趣的
【10】一文看懂推荐系统:召回08:双塔模型——线上服务需要离线存物品向量、模型更新分为全量更新和增量更新
【11】一文看懂推荐系统:召回09:地理位置召回、作者召回、缓存召回
【12】一文看懂推荐系统:排序01:多目标模型
【13】一文看懂推荐系统:排序02:Multi-gate Mixture-of-Experts (MMoE)
【14】一文看懂推荐系统:排序03:预估分数融合
【15】一文看懂推荐系统:排序04:视频播放建模
【16】一文看懂推荐系统:排序05:排序模型的特征
【17】一文看懂推荐系统:排序06:粗排三塔模型,性能介于双塔模型和精排模型之间
【18】一文看懂推荐系统:特征交叉01:Factorized Machine (FM) 因式分解机
【19】一文看懂推荐系统:物品冷启01:优化目标 & 评价指标
【20】一文看懂推荐系统:物品冷启02:简单的召回通道
【21】一文看懂推荐系统:物品冷启03:聚类召回
【22】一文看懂推荐系统:物品冷启04:Look-Alike 召回,Look-Alike人群扩散
【23】一文看懂推荐系统:物品冷启05:流量调控
【24】一文看懂推荐系统:物品冷启06:冷启的AB测试
【25】推荐系统最经典的 排序模型 有哪些?你了解多少?
【26】一文看懂推荐系统:排序07:GBDT+LR模型
【27】一文看懂推荐系统:排序08:Factorization Machines(FM)因子分解机,一个特殊的案例就是MF,矩阵分解为uv的乘积
【28】一文看懂推荐系统:排序09:Field-aware Factorization Machines(FFM),从FM改进来的,效果不咋地
【29】一文看懂推荐系统:排序10:wide&deep模型,wide就是LR负责记忆,deep负责高阶特征交叉而泛化
提示:文章目录
文章目录
- 一文看懂推荐系统:排序11:Deep & Cross Network(DCN)
- Deep & Cross Network(DCN)
- 一、动机
- 二、DCN网络结构
-
- 2.1 DCN整体结构
- 2.2 cross network部分
- 我们来看个paddle的实现,完整的代码参见 DCN
- 三、DCN网络一些参数设置
- 总结
Deep & Cross Network(DCN)
这篇文章是斯坦福和谷歌合作发表在ADKDD’17上的成果,
这篇paper的一作是斯坦福的数学&统计系的学生,
在谷歌实习时,与谷歌的研究人员合作发表了这篇文章。
这篇文章的思想依然是推荐系统模型的永恒主题——
如何得到更有效的交叉特征,从而提高模型的表达能力。
其主要工作是针对wide&deep网络中wide部分做了改进,
在wide&deep网络中,wide部分是个简单的线性模型,其交叉特征依然需要人工设计,
而在DCN中设计了专门的cross网络用于自动学习交叉特征。
关于这个cross网络目前存在一定的争议,
比如在xdeepFM这篇论文中认为DCN中cross网络交叉的本质
只是对输入向量x 0 x_0 做了一个和x 0的相关的放缩。
我个人认为,DCN中cross网络还是有一定作用的,但这个交叉是bit-wise的,
并不像FM系列的vector-wise,
所以其交叉能力应该不像FM系列这么强。
至于到实践中,其效果还需要在具体的场景中来验证,
如果你的场景中目前还在用LR等模型,想要应用深度模型,个人更推荐直接跨越到deepFM。
言归正传,我们来看看这篇文章,还是和以前的博客结构差不多,从动机、模型结构、细节等入手。
一、动机
这篇文章的动机可以归纳为两个点:
普通的DNN虽然理论上可以逼近任意的函数,
随着网络层数加深能学到任意的特征组合,
但实际上其很难有效的学到特征的二阶交叉甚至三阶交叉。
个人认为那些怀抱着只要有足够的数据,其他的都交给DNN去办想法的,
基本上很难取得令人满意的效果。
引用本文作者在DCN V2论文中的一段话:
People generally consider DNNs as universal function approximators, that could potentially learn all kinds of feature interactions. However, recent studies found that DNNs are inefficient to even approximately model 2nd or 3rd-order feature crosses。
正因为DNN无法有效的学到明显的交叉特征,
所以大多还是人工手动的做一些交叉特征,
比如wide&deep模型中wide部分的特征,
但显然人工的去设计,会面临着诸多的痛点:组合爆炸问题,需要先验的专家知识等。
基于以上两个痛点,这篇文章提出了DCN模型,
其包含两个部分:
cross网络和普通的dnn网络,
cross网络能够自动的学习任意高阶的交叉特征。

二、DCN网络结构
2.1 DCN整体结构
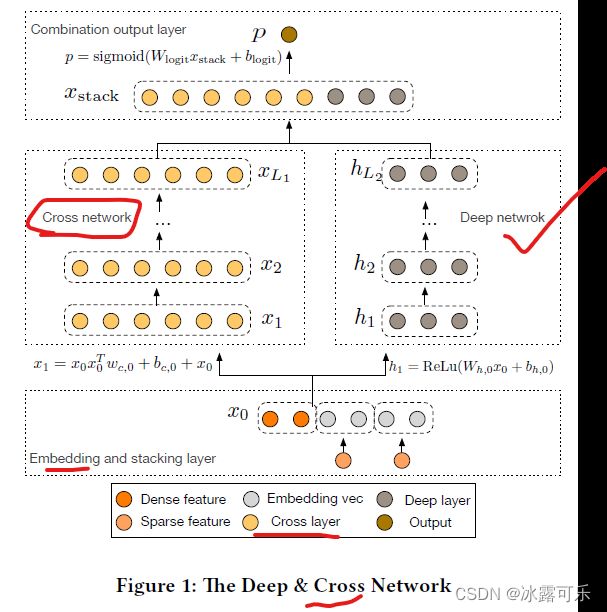
这里直接拿原始论文中的网络结构图,如下图所示。
从图中能够比较清晰的看到DCN的结构也是类似于wide&deep这种范式,
不同的是用了一个cross network替代了wide network,
右边都是一样的,用了普通的DNN。
所以我们接下来也是把重心放在cross network上。
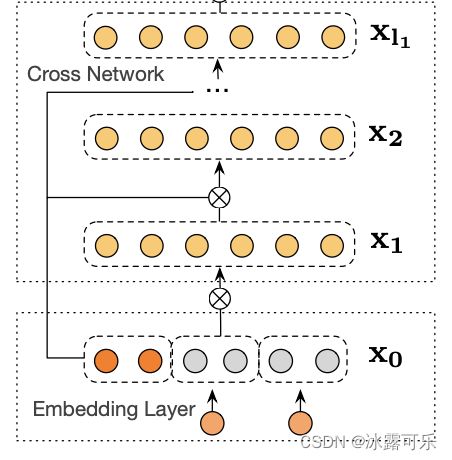
2.2 cross network部分
整篇论文的核心,也将是本篇博客的重点笔墨的部分。
cross network的网络结构如下所示(引用DCN V2论文[2]中的的图):
其中一层的计算是

再结合形式化的公式一起,感觉更好理解:
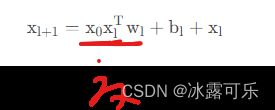
在实践中显然是不能按照这个公式去算得,因为复杂度有点高。
我们稍微把这个公式变个形,
一来更方面计算,
二来也更加有利于理解及实现(作者在dcn v2这篇论文中也是这样写的):
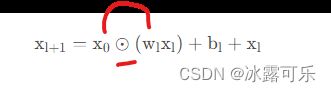
我们来看个paddle的实现,完整的代码参见 DCN
def _cross_layer(self, input_0, input_x):
"""
input_0: Tensor(shape=[8, 247]), 8=batch_size
input_x: Tensor(shape=[8, 247])
"""
# input_x, Tensor(shape=[8, 247]) --> 8=batch_size
# layer_w, shape=[247]
# input_w, Tensor(shape=[8, 247])
input_w = paddle.multiply(input_x, self.layer_w)
# Tensor(shape=[8, 1])
input_w1 = paddle.sum(input_w, axis=1, keepdim=True)
# input_0=[8, 247], input_w1=[8,1]
# broadcast --> [8, 247]
input_ww = paddle.multiply(input_0, input_w1)
input_layer_0 = paddle.add(input_ww, self.layer_b)
input_layer = paddle.add(input_layer_0, input_x)
# print("-----input_layer----", input_layer)
return input_layer, input_w
这里是用的数据集是Criteo的Display Advertising Challenge数据集,
26个类别特征,13个连续值特征,
这里类别特征embedding维度为9,因此x 0的维度为13+26*9=247。
一步步来看下这个代码:
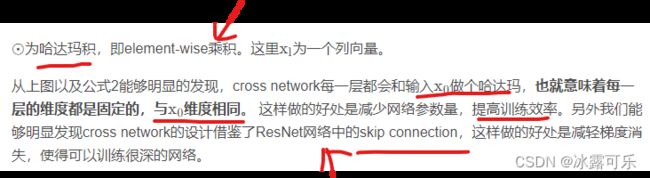
input_w = paddle.multiply(input_x, self.layer_w) 为一个哈达玛积,即对应元素相乘
input_w1 = paddle.sum(input_w, axis=1, keepdim=True) 然后做一个sum,这两步的结果为一个 8 ∗ 1 8*18∗1的矩阵:




上面的例子能够比较清晰的看出cross network这种结构是如何做到特征交叉的,
并且cross network的网络层数决定了特征交叉的阶数。
三、DCN网络一些参数设置
通过看这些网络结构的一些超参数的设置以及训练时的一些小trick,
多多少少能对我们有一些帮助,下面来看看DCN的一些超参数的设置:

总结
提示:如何系统地学习推荐系统,本系列文章可以帮到你
(1)找工作投简历的话,你要将招聘单位的岗位需求和你的研究方向和工作内容对应起来,这样才能契合公司招聘需求,否则它直接把简历给你挂了
(2)你到底是要进公司做推荐系统方向?还是纯cv方向?还是NLP方向?还是语音方向?还是深度学习机器学习技术中台?还是硬件?还是前端开发?后端开发?测试开发?产品?人力?行政?这些你不可能啥都会,你需要找准一个方向,自己有积累,才能去投递,否则面试官跟你聊什么呢?
(3)今日推荐系统学习经验:DCN是对wide&deep网络中wide部分做了改进为cross network