GPT:Generative Pre-training Transformer
基本概念
Embedding嵌入层
GPT模型的嵌入层分成两层,一层是token的Embedding,另一层是position的Embedding。GPT的位置编码采用自学习位置编码,不同于Transformer的使用sin、cos函数来表示位置信息的固定位置编码,自学习位置编码将位置信息映射到一个向量,使输入序列位置中的每一个都对应一个位置编码。将两个输出的结果进行相加,得到的结果就是该层输出的结果。
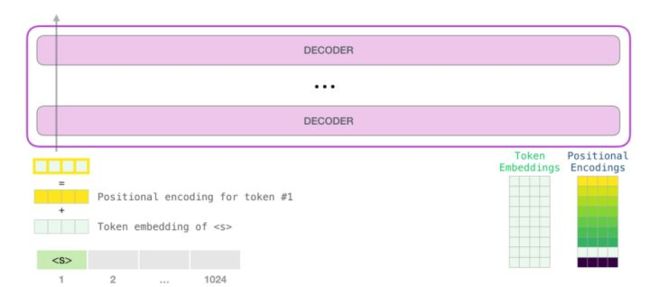
实现代码:
def get_position_ids(seq_len):
position_ids = tf.cast(tf.range(seq_len), tf.int32)[tf.newaxis, :]
return position_ids
class Embedding(layers.Layer):
def __init__(self, vocab_size, seq_len, d_model, rate=0.1):
super(Embedding, self).__init__()
# token嵌入层
self.token_embedding = layers.Embedding(vocab_size, d_model)
# position嵌入层
self.position_embedding = layers.Embedding(seq_len, d_model)
# dropout层
self.dropout = layers.Dropout(rate)
# layer标准化层
self.ln = layers.LayerNormalization(epsilon=1e-6)
def __call__(self, x, training, *args, **kwargs):
# shape:(batch_size, seq_len)=>(batch_size, seq_len, d_model)
token_embedding_output = self.token_embedding(x)
position_ids = get_position_ids(tf.shape(x)[1])
# 使用自学习位置编码
# shape:(1, seq_len)=>(1, seq_len, d_model)
position_embedding_output = self.position_embedding(position_ids)
# 利用python广播机制
output = token_embedding_output + position_embedding_output
output = self.dropout(output, training=training)
output = self.ln(output)
# shape:(batch_size, seq_len, d_model)
return output
Decoder解码器层
GPT使用的Transformer的解码器层,将多个Encoder进行堆叠构成GPT的主体结构。GPT的解码器层使用带掩码的自注意力层,这些解码器模块和 transformer 原始论文中的解码器模块相比,除了去除了第二个自注意力层之外,并无很大不同。
实现代码:
def scaled_dot_product_attention(v, k, q, mask):
# q*kT
matmul_qk = tf.matmul(q, k, transpose_b=True)
# 使用dk进行缩放,dk=k_dim
dk = tf.shape(k)[-1]
scaled_attention = matmul_qk / tf.sqrt(tf.cast(dk, tf.float32))
# 添加掩码
# 如果序列中后面是被PAD填充的怎么办?因为PAD只是为了并行化计算而填补的部分,它不应该含有任何信息。
# 所以我们需要加上一个Mask,Mask的形状为[batch, 1, 1, seq_len],补零的地方为1,其余为0。
# 乘上-1e9之后,数值上没有PAD的列均为0,PAD的列为一个很大的负数。
# 这样,经过softmax之后,被Mask的地方就近似等于0了,再乘上V的时候,就不会注意(或者说融合)PAD的信息了。
if mask is not None:
scaled_attention += (mask * -1e9)
# 获取attention weights矩阵
attention_weights = tf.nn.softmax(scaled_attention, axis=-1)
# 获取attention矩阵
attention = tf.matmul(attention_weights, v)
return attention, attention_weights
class MultiHeadAttention(layers.Layer):
def __init__(self, num_heads, d_model):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
self.k_dim = d_model // num_heads
self.q_dense = layers.Dense(d_model)
self.k_dense = layers.Dense(d_model)
self.v_dense = layers.Dense(d_model)
self.dense = layers.Dense(d_model)
def split_heads(self, x, num_heads):
batch_size = tf.shape(x)[0]
x = tf.reshape(x, (batch_size, -1, num_heads, self.k_dim))
return tf.transpose(x, perm=[0, 2, 1, 3])
def __call__(self, v, k, q, mask, *args, **kwargs):
# 全连接
# shape:(batch_size, seq_len, d_model)=>(batch_size, seq_len, d_model)
x_q = self.q_dense(q)
x_k = self.k_dense(k)
x_v = self.v_dense(v)
# 分离出多个头
# shape:(batch_size, seq_len, d_model)=>(batch_size, num_heads, seq_len, k_dim)
q = self.split_heads(x_q, self.num_heads)
k = self.split_heads(x_k, self.num_heads)
v = self.split_heads(x_v, self.num_heads)
# 计算缩放点积注意力
# shape:(batch_size, num_heads, seq_len, k_dim)=>(batch_size, num_heads, seq_len, k_dim)
attn, attn_score = scaled_dot_product_attention(v, k, q, mask)
# shape:(batch_size, num_heads, seq_len, k_dim)=>(batch_size, seq_len, num_heads, k_dim)
attn = tf.transpose(attn, perm=[0, 2, 1, 3])
# shape:(batch_size, seq_len, num_heads, k_dim)=>(batch_size, seq_len, d_model)
attn = tf.reshape(attn, (tf.shape(q)[0], -1, self.d_model))
# 全连接
# shape:(batch_size, seq_len, d_model)=>(batch_size, seq_len, d_model)
attn = self.dense(attn)
return attn, attn_score
class FeedForwardNetwork(tf.keras.layers.Layer):
def __init__(self, d_model, d_ff):
super(FeedForwardNetwork, self).__init__()
self.dense1 = tf.keras.layers.Dense(d_ff, activation="gelu")
self.dense2 = tf.keras.layers.Dense(d_model)
def __call__(self, x):
output = self.dense1(x)
output = self.dense2(output)
return output
class Decoder(layers.Layer):
def __init__(self, num_heads, d_model, d_ff, rate=0.1):
super(Decoder, self).__init__()
# 多头注意力层
self.mha = MultiHeadAttention(num_heads, d_model)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.ln1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
# 前馈网络层
self.ffn = FeedForwardNetwork(d_model, d_ff)
self.dropout2 = tf.keras.layers.Dropout(rate)
self.ln2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
def __call__(self, x, look_ahead_mask, training, *args, **kwargs):
mha_output, _ = self.mha(x, x, x, look_ahead_mask)
dropout_output1 = self.dropout1(mha_output, training=training)
ln_output1 = self.ln1(x + dropout_output1)
# (batch_size, seq_len, d_model)=>(batch_size, seq_len, d_model)
ffn_output = self.ffn(ln_output1)
dropout_output2 = self.dropout2(ffn_output, training=training)
ln_output2 = self.ln2(ln_output1 + dropout_output2)
return ln_output2
GPT模型
GPT-1模型的结构:
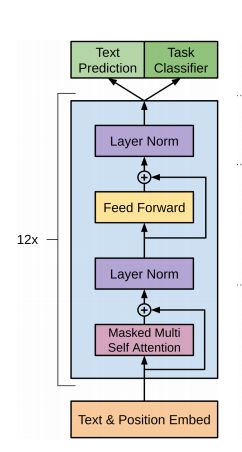
实现代码:
class GPT(tf.keras.Model):
def __init__(self, vocab_size, num_heads, d_model, d_ff, rate=0.1):
super(GPT, self).__init__()
# 嵌入层
self.embedding = Embedding(vocab_size, d_model, rate)
# 解码器层
self.decoders = [Decoder(num_heads, d_model, d_ff, rate) for _ in range(14)]
# 输出层
# 视具体任务而定,这里为一个二分类任务的输出层
self.flatten = layers.Flatten()
self.dense = layers.Dense(2)
def __call__(self, x, look_ahead_mask, training, *args, **kwargs):
output = self.embedding(x, training=training)
for decoder in self.decoders:
output = decoder(output, look_ahead_mask, training=training)
output = self.flatten(output)
output = self.dense(output)
return output
GPT-2模型的结构:
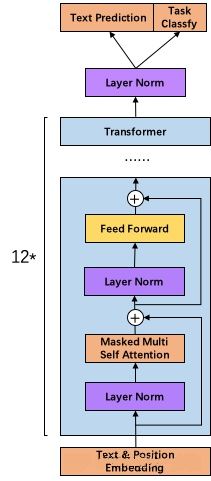
与GPT-1的主要区别就是Layer Norm放到了Feed Forward和Multi Attention前,并且最后一个Decoder输出后还有一层Layer Norm。
实现代码:
class Decoder(layers.Layer):
def __init__(self, num_heads, d_model, d_ff, rate=0.1):
super(Decoder, self).__init__()
# 多头注意力层
self.mha = MultiHeadAttention(num_heads, d_model)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.ln1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
# 前馈网络层
self.ffn = FeedForwardNetwork(d_model, d_ff)
self.dropout2 = tf.keras.layers.Dropout(rate)
self.ln2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
def __call__(self, x, look_ahead_mask, training, *args, **kwargs):
# shape:(batch_size, seq_len, d_model)=>(batch_size, seq_len, d_model)
ln_output1 = self.ln1(x)
dropout_output1 = self.dropout1(ln_output1, training=training)
mha_output, _ = self.mha(x + dropout_output1, x + dropout_output1, x + dropout_output1, look_ahead_mask)
# shape:(batch_size, seq_len, d_model)=>(batch_size, seq_len, d_model)
ln_output2 = self.ln2(mha_output)
dropout_output2 = self.dropout2(ln_output2, training=training)
ffn_output = self.ffn(mha_output + dropout_output2)
return ffn_output
class GPT(tf.keras.Model):
def __init__(self, vocab_size, num_heads, d_model, d_ff, rate=0.1):
super(GPT, self).__init__()
# 嵌入层
self.embedding = Embedding(vocab_size, d_model, rate)
# 解码器层
self.decoders = [Decoder(num_heads, d_model, d_ff, rate) for _ in range(48)]
# layer标准化层
self.layer_normalization = layers.LayerNormalization(epsilon=1e-6)
# 输出层
# 视具体任务而定,这里为一个二分类任务的输出层
self.flatten = layers.Flatten()
self.dense = layers.Dense(2)
def __call__(self, x, look_ahead_mask, training, *args, **kwargs):
output = self.embedding(x, training=training)
for decoder in self.decoders:
output = decoder(output, look_ahead_mask, training=training)
output = self.layer_normalization(output)
output = self.flatten(output)
output = self.dense(output)
return output