分布式微服务治理
文章目录
-
- 什么是微服务架构
- 为什么要使用微服务
- SpringCloud
-
- 服务注册发现
-
- Eureka
- 服务熔断降级
-
- Hystrix
- 服务网关
-
- GetWay
- 服务调用
-
- OpenFeign
- 服务负载
-
- Ribbon
- 服务配置中心
-
- SpringCloud Config
- 服务开发
-
- SpringBoot
什么是微服务架构
In short, the microservice architectural style is an approach to developing a single application as a suite of small services,
each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API.
These services are built around business capabilities and independently deployable by fully automated deployment machinery.
There is a bare minimum of centralized management of these services, which may be written in different programming languages and use different data storage technologies. ——James Lewis and Martin Fowler (2014)
大意:简而言之,微服务体系结构风格是一种将单个应用程序开发为一套小型服务的方法,每个服务运行在自己的进程中,并与轻量级机制(通常是HTTP资源API)通信。
这些服务是围绕业务功能构建的,可以通过全自动部署机制进行独立部署。对这些服务的集中管理是最低限度的,这些服务可能用不同的编程语言编写,并使用不同的数据存储技术。
微服务是一种架构风格,将服务围绕业务功能拆分,一个应用拆分为一组小型服务,每个服务运行在自己的进程内,也就是可独立部署和升级,服务之间使用轻量级HTTP交互,可以由全自动部署机制独立部署,去中心化,服务自治。服务可以使用不同的语言、不同的存储技术。
为什么要使用微服务
说的微服务就不得不说微服务之前的单体应用,有对比才能看的出微服务对比之前的单体应用到底强在哪?为什么我们要抛弃单体应用?
- 单体应用往往所有的功能打包在一个包里,包含了 DO/DAO,Service,UI等所有逻辑,如果要修改一部分代码就需要全部重新部署,所以改动影响大,风险高。微服务模式弥补了这个缺陷,它将应用合理的拆分,实现敏捷开发和快速部署。
- 单体应用只能通过在负载均衡器后面放置整个应用程序的多个实例来进行水平扩展,如果想要扩展特定的程序,显然是不行的,则需要使用到微服务模式实现。
- 因为单体应用所有的功能全部都达到一个包里面,所以耦合性比较强,对于程序员来说代码维护会收到影响,出现了什么问题也不太方便进行排查。
- 如果没有正确的设计,单体应用的一部分失败可能会级联并导致整个系统崩溃。而这种情况可以使用微服务的熔断、降级的思想来解决。
微服务虽然好处多多,但是缺点就是服务众多,治理成本高,不利于维护系统,项目成本会升高,所以项目架构设计时应综合考量。
建议设计的原则是业务驱动、设计保障、演进式迭代、保守治疗的方式。搞不清楚,有争议的地方先尽量不要拆,如果确实要拆,要经过业务分析后慎重设计,把真正相对独立的部分拆分出来,可以借鉴 DDD 的方式。拆了以后要观察微服务的接口是否稳定,针对业务需求的变更微服务的模块是否可以保持相对稳定,是否可以独立演进。
DDD: Domain-driven design的简称,译为领域驱动设计,是一种通过将实现连接到持续进化的模型来满足复杂需求的软件开发方法。
核心思想:DDD其实是面向对象方法论的一个升华。无外乎是通过划分领域(聚合根、实体、值对象)、领域行为封装到领域对象(充血模式)、内外交互封装到防腐层、职责封装到对应的模块和分层,从而实现了高内聚低耦合。
链接:https://blog.csdn.net/qq_31960623/article/details/119840131
SpringCloud
随着微服务模式的使用,服务之间的调用带来的问题有很多,例如:数据一致性、网络波动、缓存、事务等问题,针对这一系列的问题就要有对应的框架来解决,目前主流一站式微服务解决方案有Spring Cloud、Spring Cloud Alibaba。
Spring Cloud它并不是一个框架,而是很多个框架。它是分布式微服务架构的一站式解决方案,是多种微服务架构落地技术的集合体,俗称微服务全家桶。

服务注册发现
在服务注册与发现中,有一个注册中心。当服务器启动的时候,会把当前自己服务器的信息比如服务地址通讯地址等以别名方式注册到注册中心上。另一方消费者服务提供者,以该别名的方式去注册中心上获取到实际的服务通讯地址,然后再实现本地RPC调用。RPC远程调用框架核心设计思想:在于注册中心,因为使用注册中心管理每个服务与服务之间的一个依赖关系。在任何RPC远程框架中,都会有一个注册中心存放服务地址相关信息。
Eureka
参考文章:
- https://www.jianshu.com/p/cb7fa0aa47a8
Eureka is a REST (Representational State Transfer) based service that is primarily used in the AWS cloud for locating services for the purpose of load balancing and failover of middle-tier servers. We call this service, the Eureka Server. Eureka also comes with a Java-based client component,the Eureka Client, which makes interactions with the service much easier. The client also has a built-in load balancer that does basic round-robin load balancing. —https://github.com/Netflix/eureka
大意:Eureka是一个REST (Representational State Transfer)服务,它主要用于AWS云,用于定位服务,以实现中间层服务器的负载平衡和故障转移,我们称此服务为Eureka服务器。Eureka也有一个基于java的客户端组件,Eureka客户端,这使得与服务的交互更加容易,同时客户端也有一个内置的负载平衡器,它执行基本的循环负载均衡。
Eureka采用了CS的设计架构,Eureka Sever作为服务注册功能的服务器,它是服务注册中心。而系统中的其他微服务,使用Eureka的客户端连接到 Eureka Server并维持心跳连接。这样系统的维护人员就可以通过Eureka Server来监控系统中各个微服务是否正常运行。
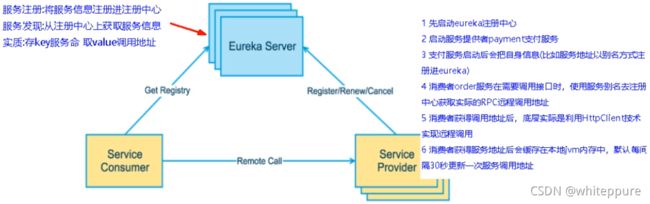
- Eureka Server 提供服务注册服务;各个微服务节点通过配置启动后,会在EurekaServer中进行注册,这样EurekaServer中的服务注册表中将会存储所有可用服务节点的信息,服务节点的信息可以在界面中直观看到。
- Eureka Client 通过注册中心进行访问;它是一个Java客户端,用于简化Eureka Server的交互,客户端同时也具备一个内置的使用轮询负载算法的负载均衡器。在应用启动后,将会向Eureka Server发送心跳默认周期为30秒。如果Eureka Server在多个心跳周期内没有接收到某个节点的心跳,Eureka Server将会从服务注册表中把这个服务节点移除,默认90秒。
- Service Provider:服务提供方,将自身服务注册到Eureka,从而使服务消费方能够找到;
- Service Consumer:服务消费方,从Eureka获取注册服务列表,从而能够消费服务;
Eureka的自我保护机制:
默认情况下,如果Eureka Server在一定时间内(默认90秒)没有接收到某个微服务实例的心跳,Eureka Server将会移除该实例。但是当网络分区故障发生时,微服务与Eureka Server之间无法正常通信,而微服务本身是正常运行的,此时不应该移除这个微服务,所以引入了自我保护机制。
自我保护模式正是一种针对网络异常波动的安全保护措施,使用自我保护模式能使Eureka集群更加的健壮、稳定的运行。
如果在15分钟内超过85%的客户端节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,Eureka Server自动进入自我保护机制:
- Eureka Server不再从注册列表中移除因为长时间没收到心跳而应该过期的服务;
- Eureka Server仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上,保证当前节点依然可用;
- 当网络稳定时,当前Eureka Server新的注册信息会被同步到其它节点中;
简而言之,某时刻某一个微服务不可用了,Eureka不会立刻清理,依旧会对该微服务的信息进行保存。所以Eureka属于AP。
服务熔断降级
由于分布式架构中应用程序依赖关系可能非常多,每个依赖关系在某些时候将不可避免地失败,针对服务调用失败,为了缩小调用失败的影响,引入了服务熔断降级的思想。
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”.
- 服务熔断:熔断机制是应对雪崩效应的一种微服务链路保护机制,当链路的某个微服务不可用或者响应时间太长时,将快速的返回设置好的提示信息。
- 服务降级:服务降级一般是指在服务器压力剧增的时候,根据实际业务使用情况以及流量,对一些服务和页面有策略的不处理或者用一种简单的方式进行处理,从而释放服务器资源的资源以保证核心业务的正常高效运行。
服务熔断是应对系统服务雪崩的一种保险措施,给出的一种特殊降级措施。而服务降级则是更加宽泛的概念,主要是对系统整体资源的合理分配以应对压力。服务熔断可看作特殊降级。
Hystrix
Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,以提高分布式系统的弹性。
"断路器”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常,这样就保证了服务调用方的线程不会被长时间、不必要地占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩。
"断路器"思想:https://martinfowler.com/bliki/CircuitBreaker.html
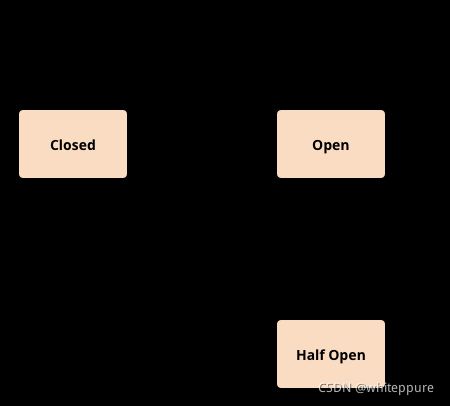
- 熔断打开:请求不再进行调用当前服务,内部定时一般为MTTR(平均故障处理时间),当打开时长达到所设的时长则进入半熔断状态;
- 熔断半开:部分请求根据规则调用当前服务,如果请求成功且符合规则则认为当前服务恢复正常,关闭熔断;
- 熔断关闭:熔断关闭不会对服务进行熔断;
Hystrix工作流程:
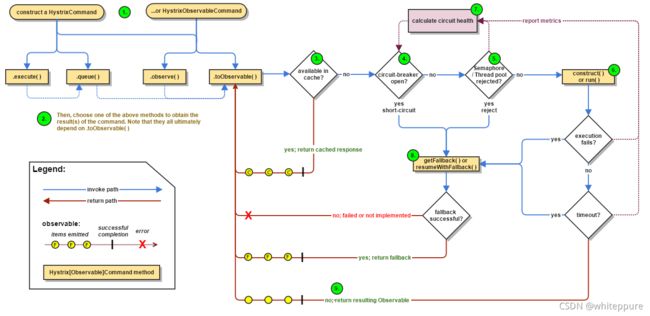
- 创建
HystrixCommand或HystrixObserableCommand对象。 - 命令执行:
- 其中
HystrixCommand实现了下面前两种执行方式:execute:同步执行,从依赖的服务返回一个单一的结果对象或是在发生错误的时候抛出异常。queue:异步执行,直接返回一个Future对象,其中包含了服务执行结束时要返回的单一结果对象。
HystrixObservableCommand实现了后两种执行方式:obseve():返回Observable对象,它代表了操作的多个结果,它是一个Hot Observable,不论“事件源”是否有“订阅者”,都会在创建后对事件进行发布,所以对于Hot Observable的每一个“订阅者”都有可能是从“事件源”的中途开始的,并可能只是看到了整个操作的局部过程。toObservable():同样会返回Observable对象,也代表了操作的多个结果,但它返回的是一个Cold Observable,没有“订间者”的时候并不会发布事件,而是进行等待,直到有“订阅者"之后才发布事件,所以对于Cold Observable 的订阅者,它可以保证从一开始看到整个操作的全部过程。
- 其中
- 判断当前命令的请求缓存功能是被启用的,并且该命令缓存命中,那么缓存的结果会立即以Observable对象的形式返回。
- 检查断路器是否为打开状态。如果断路器是打开的,那么Hystrix不会执行命令,而是转接到fallback处理逻辑(第8步);如果断路器是关闭的,检查是否有可用资源来执行命令(第5步)。
- 判断线程池/请求队列信号量是否占满。如果命令依赖服务的专有线程地和请求队列,或者信号量已经被占满,那么Hystrix也不会执行命令,而是转接到fallback处理理辑(第8步) 。
- Hystrix会根据我们编写的方法来决定采取什么样的方式去请求依赖服务:
HystrixCommand.run():返回一个单一的结果,或者抛出异常。HystrixObservableCommand.construct():返回一个Observable对象来发射多个结果,或通过onError发送错误通知。
- Hystrix会将“成功”、“失败”、“拒绝”、“超时” 等信息报告给断路器,而断路器会维护一组计数器来统计这些数据。断路器会使用这些统计数据来决定是否要将断路器打开,来对某个依赖服务的请求进行"熔断/短路"。
- 当命令执行失败的时候,Hystrix会进入fallback尝试回退处理,我们通常也称波操作为“服务降级”。而能够引起服务降级处理的情况有下面几种:
- 第4步∶当前命令处于“熔断/短路”状态,断路器是打开的时候。
- 第5步∶当前命令的线程池、请求队列或者信号量被占满的时候。
- 第6步∶
HystrixObsevableCommand.construct()或HytrixCommand.run()抛出异常的时候。
- 当Hystrix命令执行成功之后,它会将处理结果直接返回或是以Observable的形式返回给调用方。
服务网关
参考文章:
- https://blog.csdn.net/rain_web/article/details/102469745
- https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway
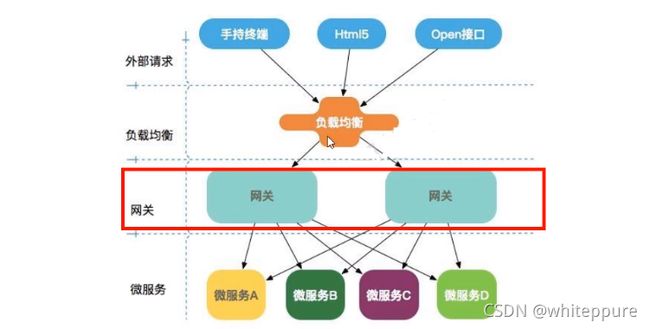
网关的角色是作为一个 API 架构,用来保护、增强和控制对于 API 服务的访问。API 网关是一个处于应用程序或服务(提供 REST API 接口服务)之前的系统,用来管理授权、访问控制和流量限制等,这样 REST API 接口服务就被 API 网关保护起来,对所有的调用者透明。因此,隐藏在 API 网关后面的业务系统就可以专注于创建和管理服务,而不用去处理这些策略性的基础设施。
网关作用:
- 作为所有API接口服务的请求接入点;
- 作为所有后端业务服务的聚合点;
- 实现安全、验证、路由、过滤、流量等策略;
- 对所有API服务和策略进行统一管理;
GetWay
Spring Cloud Gateway是Spring官方基于Spring 5.0,Spring Boot 2.0和Project Reactor等技术开发的网关,Spring Cloud Gateway旨在为微服务架构提供一种简单而有效的统一的API路由管理方式。Spring Cloud Gateway作为Spring Cloud生态系中的网关,目标是替代ZUUL,其不仅提供统一的路由方式,并且基于Filter链的方式提供了网关基本的功能,例如:安全,监控/埋点,和限流等。
核心组件:
- Route - 路由是构建网关的基本模块,它由ID,目标URI,一系列的断言和过滤器组成,如断言为true则匹配该路由;
- Predicate - 断言参考的是Java8的
java.util.function.Predicate,开发人员可以匹配HTTP请求中的所有内容,例如请求头或请求参数,如果请求与断言相匹配则进行路由; - Filter - 过滤指的是Spring框架中GatewayFilter的实例,使用过滤器,可以在请求被路由前或者之后对请求进行修改;
工作流程:
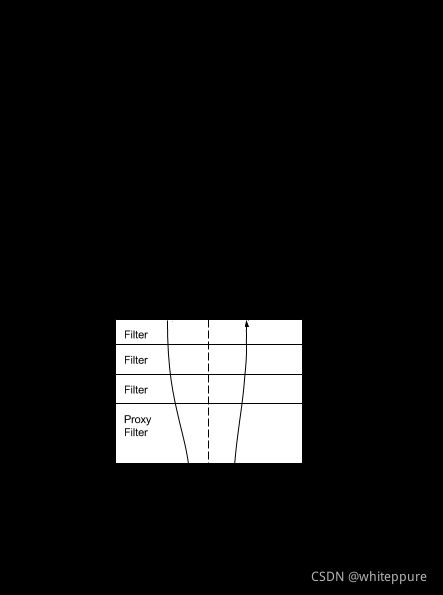
客户端向Spring Cloud Gateway发出请求。然后在Gateway Handler Mapping 中找到与请求相匹配的路由,将其发送到GatewayWeb Handler,Handler再通过指定的过滤器链来将请求发送到我们实际的服务执行业务逻辑,然后返回。
过滤器分为前置过滤器和后置过滤器,可以在发送代理请求之前或之后执行业务逻辑。
- 前置过滤器可以做参数校验、权限校验、流量监控、日志输出、协议转换等;
- 后置过滤器可以做响应内容、响应头的修改,日志的输出,流量监控等。
服务调用
参考文章:
- https://www.jianshu.com/p/a6ad30738140
- https://github.com/OpenFeign/feign
- https://blog.csdn.net/qq_34978129/article/details/111183323
- https://cloud.spring.io/spring-cloud-static
服务调用可以说是微服务中最关键的,如果没有服务调用不会出现熔断降级、也不会出现服务负载、服务注册,分布式的服务治理可以说是围绕服务调用展开的。
常见的服务之间的调用方式有两种:
- RPC远程过程调用:定义数据式,基于原生TCP通信,速度快,效率高。早期的wedservice,现在热门的dubbo,都是RPC的典型代表;
- http调用:http其实是一种网络传输协议,基于TCP,规定了数据传输的格式。现在客户端浏览器与服务器端通信基本都是采用HTTP协议,也可以用来进行远程服务调用。缺点是消息封装臃肿,优势是对服务的提供和调用方没有任何技术限定,自由灵活,更符合为服务理念;
现在热门的Rest风格,就可以通过HTTP协议来实现,如果公司全部采用Java技术栈,那么使用Dubbo作为微服务框架是一个不错的选择;如果公司的技术栈多样化,而且你更青睐Spring家族,那么SpringCloud搭建微服务是不二之选。
OpenFeign
Feign is a declarative web service client. It makes writing web service clients easier. To use Feign create an interface and annotate it. It has pluggable annotation support including Feign annotations and JAX-RS annotations. Feign also supports pluggable encoders and decoders. Spring Cloud adds support for Spring MVC annotations and for using the same HttpMessageConverters used by default in Spring Web. Spring Cloud integrates Ribbon and Eureka, as well as Spring Cloud LoadBalancer to provide a load-balanced http client when using Feign.
大意:Feign是一个声明式WebService客户端。使用Feign能让编写Web Service客户端更加简单。它的使用方法是定义一个服务接口然后在上面添加注解。Feign也支持可拔插式的编码器和解码器。Spring Cloud对Feign进行了封装,使其支持了Spring MVC标准注解和HttpMessageConverters。Feign可以与Eureka和Ribbon组合使用以支持负载均衡。
Feign和OpenFeign:
- Feign是Spring Cloud组件中的一个轻量级RESTful的HTTP服务客户端Feign内置了Ribbon,用来做客户端负载均衡,去调用服务注册中心的服务。Feign的使用方式是:使用Feign的注解定义接口,调用这个接口,就可以调用服务注册中心的服务;
- OpenFeign是Spring Cloud在Feign的基础上支持了SpringMVC的注解,如@RequesMapping等等。OpenFeign的@Feignclient可以解析SpringMVc的@RequestMapping注解下的接口,并通过动态代理的方式产生实现类,实现类中做负载均衡并调用其他服务;
通过使用OpenFeign可以使代码变得更加简洁,减轻程序员负担:
// 伪代码
@Component
// 括号中,为在注册中心注册的服务名称
@FeignClient("CLOUD-PAYMENT-SERVICE")
public interface PaymentFeignService {
@GetMapping("/payment/get/{id}")
CommonResult getPayment(@PathVariable("id") Long id);
@PostMapping("/payment/timeout")
String feignTimeoutTest();
}
openFeign工作原理:
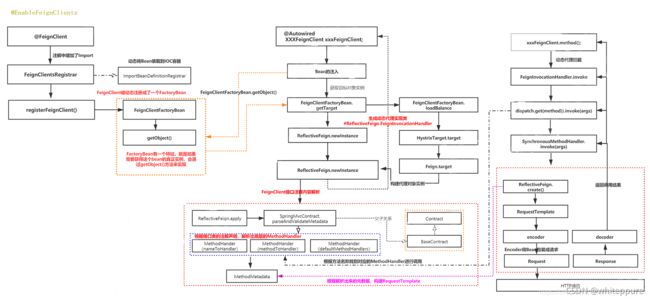
- 使用注解
@FeignClient注册FactoryBean到IOC容器, 最终产生了一个虚假的实现类代理; - 使用Feign调用接口的地方,最终拿到的都是一个假的代理实现类;
- 所有发生在代理实现类上的调用,都被转交给Feign框架,翻译成HTTP的形式发送出去,并得到返回结果,再翻译回接口定义的返回值形式;
服务负载
负载均衡,英文名称为Load Balance,其含义就是指将工作任务进行平衡、分摊到多个操作单元上进行运行,例如FTP服务器、Web服务器、企业核心应用服务器和其它主要任务服务器等,从而协同完成工作任务。
当前服务与服务之间进行相互调用时,在分布式架构下应用都是集群部署,所以这个时候就需要进行服务负载,即将收到的请求分摊到对应的服务器上,从而达到系统的高可用。
常见负载均衡算法:
- 随机分配:随机选择一台服务器来分配任务。它保证了请求的分散性达到了均衡的目的。同时它是没有状态的不需要维持上次的选择状态和均衡因子。但是随着任务量的增大,它的效果趋向轮询后也会具有轮询算法的部分缺点;
- 轮询分配:将任务分配给此时具有最小连接数的节点,因此它是动态负载均衡算法。一个节点收到一个任务后连接数就会加1,当节点故障时就将节点权值设置为0,不再给节点分配任务;
- 最小连接分配:将任务分配给此时具有最小连接数的节点,因此它是动态负载均衡算法。一个节点收到一个任务后连接数就会加1,当节点故障时就将节点权值设置为0,不再给节点分配任务;
- hash分配:对请求中的关键信息进行hash计算,hash值相同的请求分配到同一台服务器,具体原理可查看HashMap分配原理;
- 根据性能分配:根据服务器的响应时间来进行任务分配,优先将新任务分配给响应最快的服务器;
Ribbon
Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端负载均衡的工具,是一个内置软件负载平衡器的进程间通信(远程过程调用)库。主要功能是提供客户端的软件负载均衡算法和服务调用。Ribbon客户端组件提供一系列完善的配置项,如连接超时、重试等。
本地负载与服务端负载:
- Nginx是服务器负载均衡,客户端所有请求都会交给nginx,然后由nginx实现转发请求。即负载均衡是由服务端实现的;
- Ribbon是本地负载均衡,在调用微服务接口时候,会在注册中心上获取注册信息服务列表之后缓存到JVM本地,从而在本地实现RPC远程服务调用技术;
Ribbon其实是一个软负载均衡的客户端组件,它可以和其他所需请求的客户端结合使用,例如与Eureka结合:
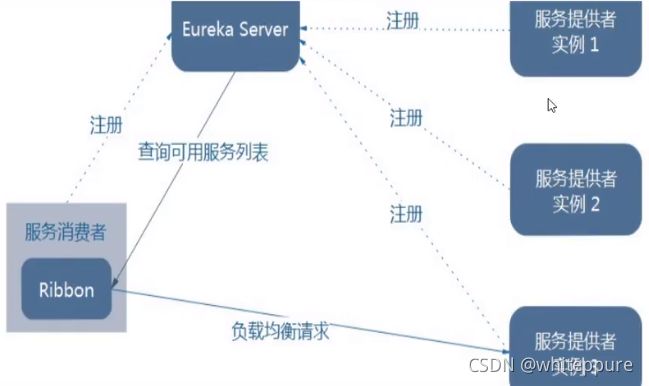
消费方和服务方在注册中心注册服务,当消费方发起请求时,Ribbon会去注册中心寻找请求的服务名,即服务方集群,Ribbon默认负载算法会根据接口第几次请求 % 服务器集群总数量算出实际消费方服务器的位置,每次服务重启动后rest接口计数从1开始。
模拟Ribbon默认负载均衡算法:
public interface ILoadBalance {
ServiceInstance instance(List instances);
}
@Component
public class MyLoadBalance implements ILoadBalance{
/**
* 轮询索引
*/
private final AtomicInteger index = new AtomicInteger(0);
/**
* 负载均衡算法:rest接口第几次请求数 % 服务器集群总数量 = 实际调用服务器位置下标,每次服务重启动后rest接口计数从1开始。
* @param instances 服务器集群数量
* @return 实际服务器的下标
*/
@Override
public ServiceInstance instance(List instances) {
return instances.get(incrementAndGet() % instances.size());
}
public final int incrementAndGet() {
int current = 0;
int next = 0;
do {
current = index.get();
// 当最大数量超过 Integer.MAX_VALUE 归0
next = current >= 2147483647 ? 0 : current + 1;
}while (!index.compareAndSet(current,next));
return next;
}
}
@Resource
private RestTemplate restTemplate;
@Resource
private DiscoveryClient discoveryClient;
@Resource
private ILoadBalance iLoadBalance;
@GetMapping("/myLoadBalance")
public String myLoadBalanceTest() {
List instances = discoveryClient.getInstances("CLOUD-PAYMENT-SERVICE");
ServiceInstance instance = iLoadBalance.instance(instances);
URI uri = instance.getUri();
String finalUri = String.format("%s/%s", uri, PaymentConstant.PAYMENT_GETPORT_API);
log.info("自定义负载均衡,请求地址:{}", finalUri);
return restTemplate.getForObject(finalUri, String.class);
}
服务配置中心
在分布式微服务意味着要将单体应用中的业务拆分成一个个子服务,每个服务的粒度相对较小,因此系统中会出现大量的服务。由于每个服务都需要必要的配置信息才能运行,所以一套集中式的、动态的配置管理设施是必不可少的。
配置中心应运而生。配置中心,顾名思义,就是来统一管理项目中所有配置的系统。对于单机版,我们称之为配置文件;对于分布式集群系统,我们称之为配置中心。
配置中心作用:
- 统一管理不同环境、不同集群的配置;
- 将配置与应用分离、解耦合;
- 版本发布管理;
SpringCloud Config
参考文章:
- https://www.springcloud.cc/spring-cloud-config.html
- https://cloud.spring.io/spring-cloud-static/spring-cloud-config
SpringCloud Config为微服务架构中的微服务提供集中化的外部配置支持,配置服务器为各个不同微服务应用的所有环境提供了一个中心化的外部配置。
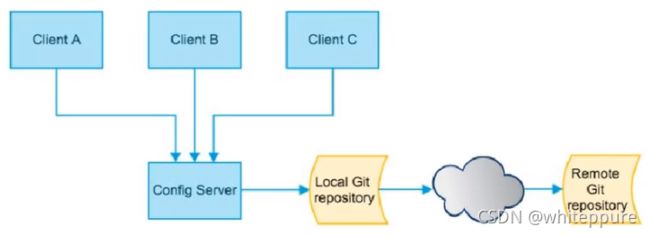
SpringCloud Config是配置中心的一种,它分为服务端和客户端两部分:
- 服务端也称为分布式配置中心,它是一个独立的微服务应用,用来连接配置服务器并为客户端提供获取配置信息,加密/解密信息等访问接口;Config-Server端集中式存储/管理配置文件,并对外提供接口方便Config-Client访问,接口使用HTTP的方式对外提供访问;
- 客户端则是通过指定的配置中心来管理应用资源,以及与业务相关的配置内容,并在启动的时候从配置中心获取和加载配置信息配置服务器默认采用git来存储配置信息,这样就有助于对环境配置进行版本管理,并且可以通过git客户端工具来方便的管理和访问配置内容;
使用SpringCloud Config非常简单,需要在服务端和客户端分别进行改造:
- 引入依赖就不说了,首先将分布式中系统中的配置放到git或svn上,在服务端配置文件里配置好git或svn用户名密码、配置文件所在的分支及配置文件的目录,再将服务端启动类加上
@EnableConfigServer注解,就大功告成了; - 放在git或svn上的配置文件名称要符合规则,才能通过配置中心访问得到该文件。一些常用的配置文件规则,其中,label:分支、profiles:环境(dev/test/prod)、application:服务名:
## http://127.0.0.1:3344/master/config-dev.yml 1. /{label}/{application}-{profile}.yml ## http://127.0.0.1:3344/config-dev.yml 2. /{application}-{profile}.yml ## http://127.0.0.1:3344/config/dev/master 3. /{application}/{profile}[/{label}] - 在客户端也要引入依赖和进行相关配置:配置中心地址、分支名称、配置文件名称、环境,需要注意的是要将客户端模块下的
application.yml文件改为bootstrap.yml,再将主启动类加上@EnableEurekaClient注解;当配置客户端启动时,它绑定到配置服务器(通过spring.cloud.config.uri引导配置属性),并使用远程属性源初始化Spring Environment。
这种行为的最终结果是,所有想要使用Config Server的客户端应用程序都需要bootstrap.yml或一个环境变量applicaiton.yml是用户级的资源配置项,而bootstrap.yml是系统级的,优先级更加高,在加载配置时优先加载bootstrap.yml
当将SpringCloud Config客户端服务端都配置好之后,修改配置时会发现修改的配置文件不能实时生效;针对这个问题,可以将服务重启或者调用actuator的刷新接口使其生效,使用之前需要引入actuator的依赖:
# 使用SpringCloud Config修改完配置后,调用刷新接口使客户端配置生效
curl -X POST "http://localhost:3355/actuator/refresh"
为了避免手动的调用刷新接口,可以使用SpringCloud Bus配合SpringCloud Config实现配置的动态刷新。
服务开发
长期以来 Java 的开发一直让人所诟病:项目开发复杂度极其高、项目的维护非常困难;即便使用了大量的开发框架,发现我们的开发也没少多少。为了解决让开发更佳简单,项目更容易管理,SpringBoot诞生了。
Spring Boot是一个广泛用来构建Java微服务的框架,它基于Spring依赖注入框架来进行工作。
SpringBoot
官网地址:https://spring.io/projects/spring-boot
SpringBoot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。
该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。SpringBoot提供了一种新的编程范式,可以更加快速便捷地开发Spring项目,在开发过程当中可以专注于应用程序本身的功能开发,而无需在Spring配置上花太大的工夫。
SpringBoot 基于 Sring4 进行设计,继承了原有 Spring 框架的优秀基因。
SpringBoot 准确的说并不是一个框架,而是一些类库的集合。
maven 或者 gradle 项目导入相应依赖即可使用 SpringBoot,而无需自行管理这些类库的版本。
特点:
- 独立运行的
Spring项目:
SpringBoot可以以 jar 包的形式独立运行,运行一个SpringBoot项目只需通过java–jar xx.jar来运行。 - 内嵌
Servlet容器:
SpringBoot可选择内嵌Tomcat、Jetty或者Undertow,这样我们无须以war包形式部署项目。 - 提供
starter简化Maven配置:
Spring提供了一系列的starterpom 来简化Maven的依赖加载,例如,当你使用了spring-boot-starter-web时,会自动加入依赖包。 - 自动配置
Spring:
SpringBoot会根据在类路径中的 jar 包、类,为 jar 包里的类自动配置 Bean,这样会极大地减少我们要使用的配置。当然,SpringBoot只是考虑了大多数的开发场景,并不是所有的场景,若在实际开发中我们需要自动配置Bean,而SpringBoot没有提供支持,则可以自定义自动配置。 - 准生产的应用监控:
SpringBoot提供基于http、ssh、telnet对运行时的项目进行监控。 - 无代码生成和 xml 配置:
SpringBoot的神奇的不是借助于代码生成来实现的,而是通过条件注解来实现的,这是Spring 4.x提供的新特性。Spring 4.x提倡使用 Java 配置和注解配置组合,而SpringBoot不需要任何 xml 配置即可实现Spring的所有配置。