【写在前面】
蒙面图像建模 (MIM) 通过恢复损坏的图像patch,在自监督表示学习中展示了令人印象深刻的结果。然而,大多数方法仍然对低级图像像素进行操作,这阻碍了对表示模型的高级语义的利用。在这项研究中,作者提出使用语义丰富的视觉标记器作为掩码预测的重建目标,为将 MIM 从像素级提升到语义级提供了一种系统的方法。具体来说,作者引入向量量化知识蒸馏来训练tokenizer,它将连续的语义空间离散化为紧凑的代码。然后,通过预测mask图像块的原始视觉token来预训练视觉Transformer。此外,作者鼓励模型将patch信息显式聚合到全局图像表示中,这有助于linear probing。图像分类和语义分割的实验表明,本文的方法优于所有比较的 MIM 方法。图像分类和语义分割的实验表明,本文的方法优于所有比较的 MIM 方法。在 ImageNet-1K(224 大小)上,基本大小的 BEIT V2 在微调时达到 85.5% 的 top-1 精度,在线性探测(linear probing)时达到 80.1% 的 top-1 精度。大尺寸 BEIT V2 在 ImageNet-1K(224 大小)微调上获得 87.3% 的 top-1 准确率,在 ADE20K 上获得 56.7% 的 mIoU 用于语义分割。
1. 论文和代码地址

BEIT V2: Masked Image Modeling with Vector-Quantized Visual Tokenizers
论文地址:https://arxiv.org/pdf/2208.06366.pdf
代码地址:https://github.com/microsoft/unilm
2. 动机
蒙面图像建模 (Masked image modeling) 在学习视觉表示方面显示出令人印象深刻的结果,这极大地缓解了视觉 Transformer 的注释饥饿问题。给定一张图像,这些方法通常首先通过屏蔽一些patch来破坏它。以开创性的工作 BEiT 为例,每张图像在预训练期间都有两个视图,即图像块和视觉token。原始图像首先被标记为离散标记。随机采样的图像块在被馈送到视觉Transformer之前被屏蔽。预训练的目标是根据损坏的图像块恢复原始视觉token。在预训练视觉编码器后,可以通过附加轻量级任务层直接在各种下游任务上微调模型。
在 mask-then-predict 框架下,与以往工作的主要区别在于重建目标,例如视觉token、原始像素和手工制作的 HOG 特征。然而,恢复低级监督往往会浪费建模能力来预训练高频细节和短程依赖关系。例如,当mask戴在男人头上的“帽子”时,我们更喜欢模型在给定整个上下文的情况下学习被掩盖的“帽子”的高级概念,而不是在像素级细节上苦苦挣扎。相比之下,语言建模中的掩码词通常被认为具有比像素更多的语义。这促使通过在预训练期间利用语义感知监督来挖掘 MIM 的潜力。
在这项工作中,作者引入了一种自监督的视觉表示模型 BEIT V2,旨在通过学习语义感知的视觉标记器(tokenizer)来改进 BEIT 预训练。具体来说,作者提出了向量量化知识蒸馏(VQ-KD)算法来离散化语义空间。 VQ-KD 编码器首先根据可学习的码本将输入图像转换为离散token。然后解码器学习重建由教师模型编码的语义特征,以离散token为条件。在训练 VQ-KD 后,其编码器用作 BEIT 预训练的视觉标记器,其中离散代码用作监督信号。
此外,作者提出通过明确鼓励 CLS token聚合所有patch来预训练全局图像表示。该机制解决了mask图像建模仅预训练patch级表示的问题。结果,在聚合全局表示的帮助下,线性探测的性能得到了提高。

作者在 ImageNet-1k 上对基本和大型视觉 Transformer 进行自监督学习,并在多个下游任务上进行评估,例如图像分类、线性探测和语义分割。如上图所示,BEIT V2 在 ImageNet 微调上大大优于以前的自监督学习算法,例如,在 ViT-B/16 和ViT-L/16。本文的方法在 ImageNet 线性探测上优于所有比较的 MIM 方法,同时在 ADE20k 上实现语义分割的巨大性能提升。
本研究的贡献总结如下:
- 作者引入向量量化知识蒸馏,将掩码图像建模从像素级提升到语义级,以进行自监督表示学习。
- 作者提出了一种补丁聚合策略,该策略在给定补丁级掩码图像建模的情况下强制执行全局表示。
- 作者对下游任务进行了广泛的实验,例如 ImageNet 微调、线性探测和语义分割。实验结果表明,本文的方法显着提高了模型大小、训练步骤和下游任务的性能。
3. 方法
BEIT V2 继承了 BEIT的蒙版图像建模框架。具体来说,给定输入图像,作者使用视觉tokenizer将图像标记为离散的视觉token。然后mask一部分图像块并将其输入视觉Transformer。预训练任务是根据损坏的图像恢复蒙面的视觉标记。在3.2节中,将介绍向量量化知识蒸馏算法,并用它来训练视觉tokenizer。在第 3.3 节中,使用视觉tokenizer进行 BEIT 预训练。此外,作者提出通过构建架构瓶颈来明确鼓励模型预训练全局图像表示。
3.1 图像表示
作者使用视觉Transformer (ViTs) 作为主干网络来获得图像表示。给定输入图像$\boldsymbol{x} \in \mathbb{R}^{H \times W \times C}$,作者将图像 x reshape为$N=H W / P^{2}$个patch$\left\{\boldsymbol{x}_{i}^{p}\right\}_{i=1}^{N}$,其中$\boldsymbol{x}^{p} \in \mathbb{R} ^{N \times\left(P^{2} C\right)}$和 $ (P, P ) $是patch大小。在实验中,作者将每个 224 × 224 的图像分割成一个 14 × 14 的图像块网格,其中每个块是 16 × 16。然后图像块$\left\{\boldsymbol{x}_{i}^{p}\right\}_{i=1}^{N}$被展平并线性投影到 Transformers 的输入嵌入中。对于 N 个图像块,将编码向量表示为$\left\{\boldsymbol{h}_{i}\right\}_{i=1}^{N}$。
3.2 训练Visual Tokenizer
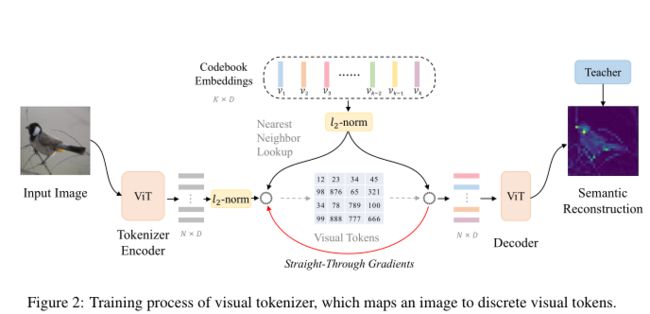
视觉tokenizer将图像映射到一系列离散标记。具体来说,图像 x 被标记为$z=\left[z_{1}, \cdots, z_{N}\right] \in \mathcal{V}^{(H / P) \times(W / P)}$,其中词汇 V(即视觉码本)包含 |V|个离散码。请注意,token的数量与本文工作中图像块的数量相同。作者提出向量量化知识蒸馏(VQ-KD)来训练视觉标记器。如上图所示,VQ-KD 在训练过程中有两个模块,即视觉标记器和解码器。
标记器由视觉Transformer编码器和量化器组成。标记器首先将输入图像编码为向量。接下来,向量量化器在码本中查找每个patch表示$h_{i}$的最近邻。让$\left\{\boldsymbol{e}_{1}, \cdots, \boldsymbol{e}_{|\mathcal{\nu}|}\right\}$表示码本嵌入。对于第 i 个图像块,其量化代码由下式获得:
$$ z_{i}=\underset{j}{\arg \min }\left\|\ell_{2}\left(\boldsymbol{h}_{i}\right)-\ell_{2}\left(\boldsymbol{e}_{j}\right)\right\|_{2} $$
其中$\ell_{2}$归一化用于码本查找。上述距离相当于根据余弦相似度找码。
在将图像量化为视觉标记后,作者将l2-normalized codebook embeddings$\left\{\ell_{2}\left(\boldsymbol{e}_{z_{i}}\right)\right\}_{i=1}^{N}$提供给解码器。解码器也是一个多层 Transformer 网络。输出向量$\left\{\boldsymbol{o}_{i}\right\}_{i=1}^{N}$旨在重建教师模型的语义特征,例如 DINO和 CLIP。让$\boldsymbol{t}_{i}$表示第 i 个图像块的教师模型的特征向量。作者最大化解码器输出$o_{i}$和教师指导 $t_{i}$ 之间的余弦相似度。
因为量化过程是不可微分的。如上图所示,为了将梯度反向传播到编码器,梯度直接从解码器输入复制到编码器输出。直观地说,量化器为每个编码器输出查找最近的代码,因此码本嵌入的梯度指示了编码器的有用优化方向。
VQ-KD的训练目标是:
$$ \max \sum_{x \in \mathcal{D}} \sum_{i=1}^{N} \cos \left(\boldsymbol{o}_{i}, \boldsymbol{t}_{i}\right)-\left\|\operatorname{sg}\left[\ell_{2}\left(\boldsymbol{h}_{i}\right)\right]-\ell_{2}\left(\boldsymbol{e}_{z_{i}}\right)\right\|_{2}^{2}-\left\|\ell_{2}\left(\boldsymbol{h}_{i}\right)-\operatorname{sg}\left[\ell_{2}\left(\boldsymbol{e}_{z_{i}}\right)\right]\right\|_{2}^{2}, $$
其中 sg[·] 代表停止梯度算子,它在前向传递中是一个身份,而在后向传递期间具有零梯度,D 代表用于标记器训练的图像数据。
3.3 预训练 BEIT V2
作者遵循 BEIT中的掩蔽图像建模 (MIM) 设置来预训练视觉 Transformer 以进行图像表示。给定输入图像 x,作者逐块选择大约 40% 的图像块进行mask。将mask位置称为 M,然后使用共享的可学习嵌入$e_{[M]}$替换原始图像块嵌入 $e_{i}^{p}$如果 $i \in \mathcal{M}$,$\boldsymbol{x}_{i}^{\mathcal{M}}=\delta(i \in\mathcal{M}) \odot \boldsymbol{e}_{[\mathrm{M}]}+(1-\delta(i \in \mathcal{M})) \odot \boldsymbol{x}_{i}^{p}$,其中 δ(·) 是指示函数。随后,作者在输入前添加一个可学习的 CLS token,即$\left[e_{\mathrm{CLS}},\left\{\boldsymbol{x}_{i}^{\mathcal{M}}\right\}_{i=1}^{N}\right]$,并将它们提供给视觉 Transformer。最终的编码向量表示为$\left\{\boldsymbol{h}_{i}\right\}_{i=0}^{N}$,其中$h_{0}$表示 CLS token。
接下来,使用mask图像建模头根据损坏的图像$x^{\mathcal{M}}$预测mask位置的视觉token。对于每个掩码位置 $\left\{\boldsymbol{h}_{i}: i \in \mathcal{M}\right\}_{i=1}^{N}$,softmax 分类器预测视觉标记$p\left(z^{\prime} \mid x^{\mathcal{M}}\right)=\operatorname{softmax}_{z^{\prime}}\left(\boldsymbol{W}_{c} \boldsymbol{h}_{i}+\boldsymbol{b}_{c}\right)$,其中 $w^{x}$是掩码图像,$\boldsymbol{W}_{c}, \boldsymbol{b}_{c}$是分类器权重。视觉标记由第 3.2 节中训练的tokenizer获得,该标记器为mask图像建模提供监督。最后,MIM 的训练损失可以表示为:
$$ \mathcal{L}_{\mathrm{MIM}}=-\sum_{x \in \mathcal{D}} \sum_{i \in \mathcal{M}} \log p\left(z_{i} \mid x^{\mathcal{M}}\right) $$
其中$z_{i}$表示原始图像的视觉标记,$\mathcal{D}$表示预训练图像。
预训练全局表示
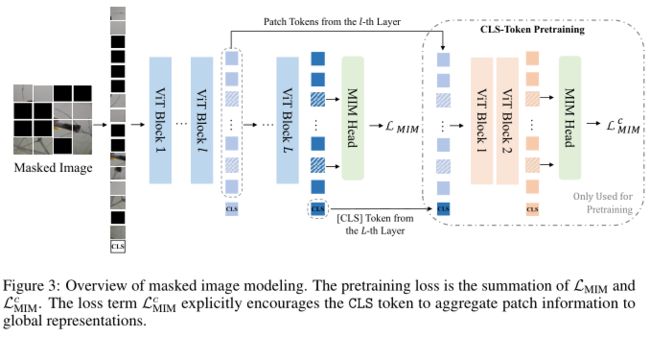
作者显式地预训练 CLS token以进行全局表示。本文的目标是减轻patch级预训练和图像级表示聚合之间的差异。如上图所示,作者构建了一个表示瓶颈来指导 CLS token收集信息。对于 L 层 Transformer,令$\left\{h_{i}^{l}\right\}_{i=1}^{N}$表示第 l 层的输出向量,其中$l=1, \cdots, L$。为了预训练最后一层的 CLS token $h_{\mathrm{CLS}}^{L}$,作者将其与中间第l层的patch向量$\left\{h_{i}^{l}\right\}_{i=1}^{N}$进行concat,即$\boldsymbol{S}=\left[h_{\mathrm{CLS}}^{L}, h_{1}^{l}, \cdots, h_{N}^{l}\right]$。然后将 S 馈送到一个浅层(例如两层)Transformer 解码器并进行mask预测。作者还计算了第 L 层的 MIM 损失。所以最终的训练损失是两项的总和,即第 L 层的原始损失和浅层 Transformer 解码器的 MIM 损失。在本文的实现中,作者还共享两个头部的 MIM softmax 权重。
4.实验
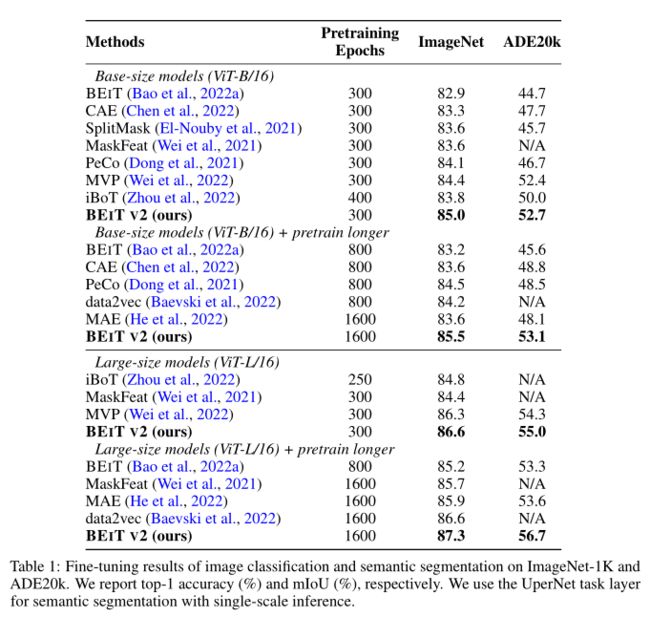
上表报告了 top-1 的微调精度结果。从上表中可以看出,具有 300 个 epoch 预训练计划的基本尺寸 BEIT V2 达到 85.0% 的 top-1 准确率,将 BEIT、CAE、SplitMask 和 PeCo 分别抑制了 2.1%、1.7%、1.4% 和 0.9%。此外,BEIT V2 比 iBoT 高 1.2%,data2vec 高 0.8%。
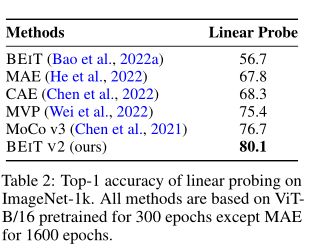
上表展示了线性探测的 top-1 精度。作者将 BEIT V2 与 MIM 方法 BEIT、MAE、CAE、MVP 和对比方法 MoCo v3 进行比较。所有方法都基于 ViT-B/16 并预训练了 300 个 epoch,但 MAE 为 1600 个 epoch。
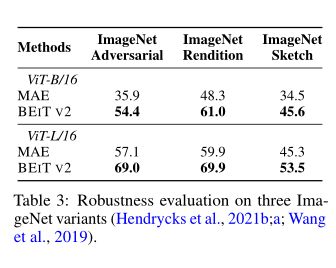
作者评估了 BEIT V2 在各种 ImageNet 验证集上的鲁棒性,在上表中报告了结果。与 MAE相比,BEIT V2 在数据集上取得了巨大的进步,证明了所提出的方法在泛化方面的优越性。
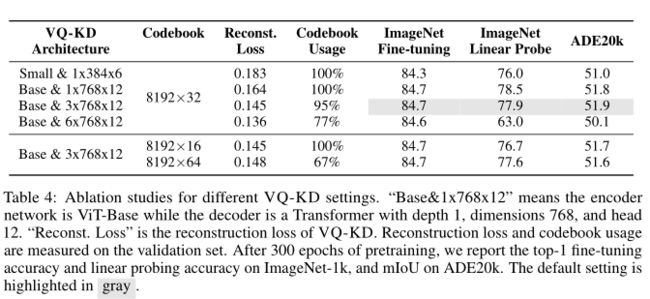
从上表可以看出,VQ-KD 的更深解码器获得了更好的重构,但码本使用率和下游任务性能更低。此外,实验表明减少码本查找的维度可以提高码本的利用率。
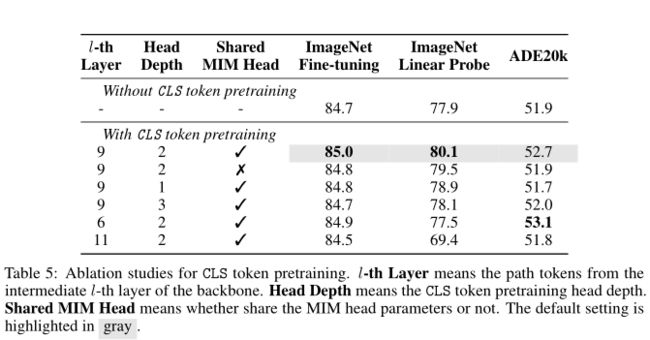
上表展示了关于 CLS token预训练的消融研究。较浅的头部(1/2 层)比较深的头部(3 层)表现更好,这表明较浅的头部(较低的模型容量)比较深的头部(较高的模型容量)更关注输入 CLS token。
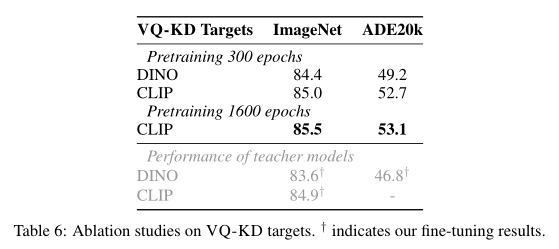
上表展示了VQ-KD target的消融研究。
5. 总结
在本文中,作者提出了向量量化知识蒸馏(VQ-KD)来训练视觉Transformer预训练的视觉标记器。 VQ-KD 离散化连续语义空间,为mask图像建模提供监督,而不是依赖图像像素。语义视觉标记器极大地改进了 BEIT 预训练并显着提高了下游任务的传输性能。此外,引入了 CLS token预训练机制,以明确鼓励模型生成全局图像表示,缩小补丁级预训练和图像级表示聚合之间的差距。
【技术交流】
已建立深度学习公众号——FightingCV,关注于最新论文解读、基础知识巩固、学术科研交流,欢迎大家关注!!!
推荐加入FightingCV交流群,每日会发送论文解析、算法和代码的干货分享,进行学术交流,加群请添加小助手wx:FightngCV666,备注:地区-学校(公司)-名称
面向小白的顶会论文核心代码库:https://github.com/xmu-xiaoma666/External-Attention-pytorch
面向科研小白的YOLO目标检测库:https://github.com/iscyy/yoloair

【赠书活动】
为感谢各位老粉和新粉的支持,FightingCV公众号将在9月10日包邮送出4本《深度学习与目标检测:工具、原理与算法》来帮助大家学习,赠书对象为当日阅读榜和分享榜前两名。想要参与赠书活动的朋友,请添加小助手微信FightngCV666(备注“城市-方向-ID”),方便联系获得邮寄地址。

本文由mdnice多平台发布