YOLOv7 | 模型结构与正负样本分配解析
如有错误,恳请指出。
Yolov7的原作者就是Yolov4的原作者。看论文的时候看到比较乱,这里可能会比较杂乱的记录一下我觉得有点启发的东西。对于yolov7的代码,我也没有仔细的看,只是大概的看了下其他博客提到的些细节。所以这里也不会具体的解析代码。
文章目录
- 1. 相关工作
- 2. 网络结构
-
- 2.1 ELAN
- 2.2 SPPCSPC
- 2.3 MP
- 3. 样本分配策略
- 4. 辅助损失
- 5. 实验结果与总结
1. 相关工作
我觉得yolov7论文的 Related work 的前两小节写得指导性很大。
当前目标检测的主要优化方向:更快更强的网络架构;更有效的特征集成方法;更准确的检测方法;更精确的损失函数;更有效的标签分配方法;更有效的训练策略
同时还介绍了下模型的重参数化,可以将其看成是一种集成技术。现在可以将模型的重参数化分成两类:模块级集成(module-level ensemble)和模型级集成(model-level ensemble)。
- 对于模型级重参数化有两种常见的做法,一种是用不同的训练数据训练多个相同的模型,然后对多个训练模型的权重进行平均。另一种是对不同迭代次数下的模型权重进行加权平均。
- 对于模块级重参数化是在训练期间将模块拆分为多个相同或不同的模块分支,并在推理期间将多个分支模块集成为完全等效的模块。然而,并非所有提出的重新参数化模块都能完美地应用于不同的体系结构。
之后的内容,无论是看单独看文章还是单独看源码,其实都比较难直观的了解整个网路的结构,所以还是要借助其他大佬画图做笔记。
2. 网络结构
无论是在源码中还是在文章里,都无法像yolov6那样直观地查看整个yolov7的backbone,neck和head结构。所以这里也只能自行的配合源码来作图。不过,幸运的是,已经有不少大佬画出了结构图。详细解析见参考资料3,4。
- yolov7网络的结构图
先来查看yolov7.yaml的配置,代码作了部分的删减
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [12,16, 19,36, 40,28] # P3/8
- [36,75, 76,55, 72,146] # P4/16
- [142,110, 192,243, 459,401] # P5/32
# yolov7 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 3, 1]], # 0
......
[-1, 1, MP, []],
[-1, 1, Conv, [512, 1, 1]],
[-3, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 42-P5/32
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 50
]
# yolov7 head
head:
[[-1, 1, SPPCSPC, [512]], # 51
......
[-1, 1, Conv, [512, 1, 1]],
[-2, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 101
[75, 1, RepConv, [256, 3, 1]],
[88, 1, RepConv, [512, 3, 1]],
[101, 1, RepConv, [1024, 3, 1]],
[[102,103,104], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
这里可以看见,yolov7对于网络的配置,其实是和yolov5是一致的。也就说,大部分是复用了yolov5项目的代码。从yaml文件中,可以看出,其通过一层层的卷积来构建,但是无法直观的区分每一个积木的形状。
在yolov7的配置网络中,RepConv是将3×3卷积、1×1卷积和Identity连接组合在一个卷积层中。MP是最大池化nn.MaxPool2d,Conv是卷积+bn+激活(SiLU),SPPCSPC是在yolov7中新提出的一个SPP结构作为一个小的特征融合模块。最后使用的IDetect和yolov5中是detect头是完全一样的。原始的yolov7结构没有使用辅助的训练头。
class MP(nn.Module):
def __init__(self, k=2):
super(MP, self).__init__()
self.m = nn.MaxPool2d(kernel_size=k, stride=k)
def forward(self, x):
return self.m(x)
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
对于上面贴出来的网络结构图,Rep就是参数重结构化,实现训练和推理过程解耦(但是yolov7这里用的也不多,甚至不是全系列都用上了,只用了部分版本,有点迷)。值得注意的是,这里提出了几个新模块:ELAN、SPPCSPC、MP结构
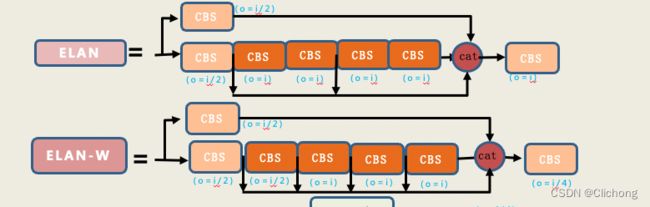
2.1 ELAN
这个东西在论文上花了一小节去讲:

但是在代码中很难直观的体现,因为源码中他不是构建为一个积木,而是由更原始的积木Conv来堆叠(这个整个模型搭建的方法有关,无法改变)。
# ELAN
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 50
# ELAN-W
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 63
其可以表示为:
2.2 SPPCSPC
代码:
class SPPCSPC(nn.Module):
# CSP https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):
super(SPPCSPC, self).__init__()
c_ = int(2 * c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 3, 1)
self.cv4 = Conv(c_, c_, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
self.cv5 = Conv(4 * c_, c_, 1, 1)
self.cv6 = Conv(c_, c_, 3, 1)
self.cv7 = Conv(2 * c_, c2, 1, 1)
def forward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1)))
y2 = self.cv2(x)
return self.cv7(torch.cat((y1, y2), dim=1))
结构图:

2.3 MP
代码:
# MP-1
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 16-P3/8
# MP-2
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3, 51], 1, Concat, [1]],
结构图:

之前下采样我们通常最开始使用maxpooling,之后大家又都选用stride = 2的3*3卷积。这里作者充分发挥:“小孩子才做选择,大人都要”的原则,同时使用了max pooling 和 stride=2的conv。
而这两者的区别只是通道数的变化。
3. 样本分配策略
详细见参考资料1.
首先,yolov7也仍然是anchor base的目标检测算法,yolov7将yolov5和YOLOX中的正负样本分配策略进行结合,流程如下:
- yolov5:使用yolov5正负样本分配策略分配正样本。
- YOLOX:计算每个样本对每个GT的Reg+Cla loss(Loss aware)
- YOLOX:使用每个GT的预测样本确定它需要分配到的正样本数(Dynamic k)
- YOLOX:为每个GT取loss最小的前dynamic k个样本作为正样本
- YOLOX:人工去掉同一个样本被分配到多个GT的正样本的情况(全局信息)
其实主要是将simOTA中的第一步“使用中心先验”替换成“yolov5中的策略”。yolov5策略与YOLOX中simOTA策略的融合,相较于只使用yolov5策略,加入了loss aware,利用当前模型的表现,能够再进行一次精筛。而融合策略相较于只使用YOLOX中simOTA,能够提供更精确的先验知识。
yolov6等工作中也都使用了simOTA作为分配策略,可见simOTA确实是能带来很大提升的策略。
- 参考代码:
class ComputeLossOTA:
# Compute losses
def __init__(self, model, autobalance=False):
super(ComputeLossOTA, self).__init__()
device = next(model.parameters()).device # get model device
h = model.hyp # hyperparameters
# Define criteria
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
# Focal loss
g = h['fl_gamma'] # focal loss gamma
if g > 0:
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
det = model.module.model[-1] if is_parallel(model) else model.model[-1] # Detect() module
self.balance = {3: [4.0, 1.0, 0.4]}.get(det.nl, [4.0, 1.0, 0.25, 0.06, .02]) # P3-P7
self.ssi = list(det.stride).index(16) if autobalance else 0 # stride 16 index
self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, model.gr, h, autobalance
for k in 'na', 'nc', 'nl', 'anchors', 'stride':
setattr(self, k, getattr(det, k))
def __call__(self, p, targets, imgs): # predictions, targets, model
device = targets.device
lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
bs, as_, gjs, gis, targets, anchors = self.build_targets(p, targets, imgs)
pre_gen_gains = [torch.tensor(pp.shape, device=device)[[3, 2, 3, 2]] for pp in p]
# Losses
for i, pi in enumerate(p): # layer index, layer predictions
b, a, gj, gi = bs[i], as_[i], gjs[i], gis[i] # image, anchor, gridy, gridx
tobj = torch.zeros_like(pi[..., 0], device=device) # target obj
n = b.shape[0] # number of targets
if n:
ps = pi[b, a, gj, gi] # prediction subset corresponding to targets
# Regression
grid = torch.stack([gi, gj], dim=1)
pxy = ps[:, :2].sigmoid() * 2. - 0.5
#pxy = ps[:, :2].sigmoid() * 3. - 1.
pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
pbox = torch.cat((pxy, pwh), 1) # predicted box
selected_tbox = targets[i][:, 2:6] * pre_gen_gains[i]
selected_tbox[:, :2] -= grid
iou = bbox_iou(pbox.T, selected_tbox, x1y1x2y2=False, CIoU=True) # iou(prediction, target)
lbox += (1.0 - iou).mean() # iou loss
# Objectness
tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * iou.detach().clamp(0).type(tobj.dtype) # iou ratio
# Classification
selected_tcls = targets[i][:, 1].long()
if self.nc > 1: # cls loss (only if multiple classes)
t = torch.full_like(ps[:, 5:], self.cn, device=device) # targets
t[range(n), selected_tcls] = self.cp
lcls += self.BCEcls(ps[:, 5:], t) # BCE
# Append targets to text file
# with open('targets.txt', 'a') as file:
# [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
obji = self.BCEobj(pi[..., 4], tobj)
lobj += obji * self.balance[i] # obj loss
if self.autobalance:
self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
if self.autobalance:
self.balance = [x / self.balance[self.ssi] for x in self.balance]
lbox *= self.hyp['box']
lobj *= self.hyp['obj']
lcls *= self.hyp['cls']
bs = tobj.shape[0] # batch size
loss = lbox + lobj + lcls
return loss * bs, torch.cat((lbox, lobj, lcls, loss)).detach()
def build_targets(self, p, targets, imgs):
#indices, anch = self.find_positive(p, targets)
indices, anch = self.find_3_positive(p, targets)
#indices, anch = self.find_4_positive(p, targets)
#indices, anch = self.find_5_positive(p, targets)
#indices, anch = self.find_9_positive(p, targets)
matching_bs = [[] for pp in p]
matching_as = [[] for pp in p]
matching_gjs = [[] for pp in p]
matching_gis = [[] for pp in p]
matching_targets = [[] for pp in p]
matching_anchs = [[] for pp in p]
nl = len(p)
for batch_idx in range(p[0].shape[0]):
b_idx = targets[:, 0]==batch_idx
this_target = targets[b_idx]
if this_target.shape[0] == 0:
continue
txywh = this_target[:, 2:6] * imgs[batch_idx].shape[1]
txyxy = xywh2xyxy(txywh)
pxyxys = []
p_cls = []
p_obj = []
from_which_layer = []
all_b = []
all_a = []
all_gj = []
all_gi = []
all_anch = []
for i, pi in enumerate(p):
b, a, gj, gi = indices[i]
idx = (b == batch_idx)
b, a, gj, gi = b[idx], a[idx], gj[idx], gi[idx]
all_b.append(b)
all_a.append(a)
all_gj.append(gj)
all_gi.append(gi)
all_anch.append(anch[i][idx])
from_which_layer.append(torch.ones(size=(len(b),)) * i)
fg_pred = pi[b, a, gj, gi]
p_obj.append(fg_pred[:, 4:5])
p_cls.append(fg_pred[:, 5:])
grid = torch.stack([gi, gj], dim=1)
pxy = (fg_pred[:, :2].sigmoid() * 2. - 0.5 + grid) * self.stride[i] #/ 8.
#pxy = (fg_pred[:, :2].sigmoid() * 3. - 1. + grid) * self.stride[i]
pwh = (fg_pred[:, 2:4].sigmoid() * 2) ** 2 * anch[i][idx] * self.stride[i] #/ 8.
pxywh = torch.cat([pxy, pwh], dim=-1)
pxyxy = xywh2xyxy(pxywh)
pxyxys.append(pxyxy)
pxyxys = torch.cat(pxyxys, dim=0)
if pxyxys.shape[0] == 0:
continue
p_obj = torch.cat(p_obj, dim=0)
p_cls = torch.cat(p_cls, dim=0)
from_which_layer = torch.cat(from_which_layer, dim=0)
all_b = torch.cat(all_b, dim=0)
all_a = torch.cat(all_a, dim=0)
all_gj = torch.cat(all_gj, dim=0)
all_gi = torch.cat(all_gi, dim=0)
all_anch = torch.cat(all_anch, dim=0)
pair_wise_iou = box_iou(txyxy, pxyxys)
pair_wise_iou_loss = -torch.log(pair_wise_iou + 1e-8)
top_k, _ = torch.topk(pair_wise_iou, min(10, pair_wise_iou.shape[1]), dim=1)
dynamic_ks = torch.clamp(top_k.sum(1).int(), min=1)
gt_cls_per_image = (
F.one_hot(this_target[:, 1].to(torch.int64), self.nc)
.float()
.unsqueeze(1)
.repeat(1, pxyxys.shape[0], 1)
)
num_gt = this_target.shape[0]
cls_preds_ = (
p_cls.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
* p_obj.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
)
y = cls_preds_.sqrt_()
pair_wise_cls_loss = F.binary_cross_entropy_with_logits(
torch.log(y/(1-y)) , gt_cls_per_image, reduction="none"
).sum(-1)
del cls_preds_
cost = (
pair_wise_cls_loss
+ 3.0 * pair_wise_iou_loss
)
matching_matrix = torch.zeros_like(cost)
for gt_idx in range(num_gt):
_, pos_idx = torch.topk(
cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False
)
matching_matrix[gt_idx][pos_idx] = 1.0
del top_k, dynamic_ks
anchor_matching_gt = matching_matrix.sum(0)
if (anchor_matching_gt > 1).sum() > 0:
_, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)
matching_matrix[:, anchor_matching_gt > 1] *= 0.0
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0
fg_mask_inboxes = matching_matrix.sum(0) > 0.0
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
from_which_layer = from_which_layer[fg_mask_inboxes]
all_b = all_b[fg_mask_inboxes]
all_a = all_a[fg_mask_inboxes]
all_gj = all_gj[fg_mask_inboxes]
all_gi = all_gi[fg_mask_inboxes]
all_anch = all_anch[fg_mask_inboxes]
this_target = this_target[matched_gt_inds]
for i in range(nl):
layer_idx = from_which_layer == i
matching_bs[i].append(all_b[layer_idx])
matching_as[i].append(all_a[layer_idx])
matching_gjs[i].append(all_gj[layer_idx])
matching_gis[i].append(all_gi[layer_idx])
matching_targets[i].append(this_target[layer_idx])
matching_anchs[i].append(all_anch[layer_idx])
for i in range(nl):
if matching_targets[i] != []:
matching_bs[i] = torch.cat(matching_bs[i], dim=0)
matching_as[i] = torch.cat(matching_as[i], dim=0)
matching_gjs[i] = torch.cat(matching_gjs[i], dim=0)
matching_gis[i] = torch.cat(matching_gis[i], dim=0)
matching_targets[i] = torch.cat(matching_targets[i], dim=0)
matching_anchs[i] = torch.cat(matching_anchs[i], dim=0)
else:
matching_bs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_as[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_gjs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_gis[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_targets[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_anchs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
return matching_bs, matching_as, matching_gjs, matching_gis, matching_targets, matching_anchs
def find_3_positive(self, p, targets):
# Build targets for compute_loss(), input targets(image,class,x,y,w,h)
na, nt = self.na, targets.shape[0] # number of anchors, targets
indices, anch = [], []
gain = torch.ones(7, device=targets.device).long() # normalized to gridspace gain
ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
g = 0.5 # bias
off = torch.tensor([[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g # offsets
for i in range(self.nl):
anchors = self.anchors[i]
gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain
# Match targets to anchors
t = targets * gain
if nt:
# Matches
r = t[:, :, 4:6] / anchors[:, None] # wh ratio
j = torch.max(r, 1. / r).max(2)[0] < self.hyp['anchor_t'] # compare
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
t = t[j] # filter
# Offsets
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1. < g) & (gxy > 1.)).T
l, m = ((gxi % 1. < g) & (gxi > 1.)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
t = t.repeat((5, 1, 1))[j]
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
else:
t = targets[0]
offsets = 0
# Define
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy
gwh = t[:, 4:6] # grid wh
gij = (gxy - offsets).long()
gi, gj = gij.T # grid xy indices
# Append
a = t[:, 6].long() # anchor indices
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
anch.append(anchors[a]) # anchors
return indices, anch
4. 辅助损失
论文中,将负责最终输出的Head为lead Head,将用于辅助训练的Head称为auxiliary Head。在代码上,aux head的assigner和lead head的assigner仅存在很少的不同
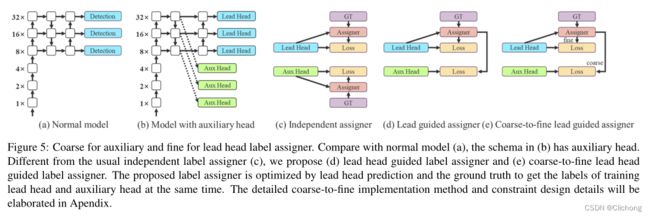
一些细节:其loss函数和不带辅助头相同,加权系数不能过大(aux head loss 和lead head loss 按照0.25:1的比例),否则会导致lead head出来的结果精度变低。匹配策略和上面的不带辅助头(只有lead head)只有很少不同,其中辅助头:
- lead head中每个网格与gt如果匹配上,附加周边两个网格,而aux head附加4个网格(如上面导数第二幅图,匹配到浅黄+橘黄共5个网格),这里在代码中是通过控制偏置g来实现的。(除此之外的两个函数是完全一样)
# find_3_positive
g = 0.5 # bias
# find_5_positive
g = 1.0 # bias
- 如果使用了辅助头损失中,lead head中将top20个样本iou求和取整,而aux head同样是中取top20。但是如果不使用辅助头损失, head中将取top10个样本iou求和取整
# ComputeLossOTA:build_targets
top_k, _ = torch.topk(pair_wise_iou, min(10, pair_wise_iou.shape[1]), dim=1)
dynamic_ks = torch.clamp(top_k.sum(1).int(), min=1)
......
# ComputeLossAuxOTA
# build_targets
top_k, _ = torch.topk(pair_wise_iou, min(20, pair_wise_iou.shape[1]), dim=1)
dynamic_ks = torch.clamp(top_k.sum(1).int(), min=1)
# build_targets2
top_k, _ = torch.topk(pair_wise_iou, min(20, pair_wise_iou.shape[1]), dim=1)
dynamic_ks = torch.clamp(top_k.sum(1).int(), min=1)
- 在loss融合方面,aux head loss 和lead head loss 按照0.25:1的比例进行融合。
lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
...
for i in range(self.nl): # layer index, layer predictions
...
if n:
...
# Regression
lbox += (1.0 - iou).mean() # iou loss
# Objectness
tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * iou.detach().clamp(0).type(tobj.dtype) # iou ratio
# Classification
if self.nc > 1: # cls loss (only if multiple classes)
t = torch.full_like(ps[:, 5:], self.cn, device=device) # targets
t[range(n), selected_tcls] = self.cp
lcls += self.BCEcls(ps[:, 5:], t) # BCE
...
if n_aux:
...
# Regression
lbox += 0.25 * (1.0 - iou_aux).mean() # iou loss
# Objectness
tobj_aux[b_aux, a_aux, gj_aux, gi_aux] = (1.0 - self.gr) + self.gr * iou_aux.detach().clamp(0).type(tobj_aux.dtype) # iou ratio
# Classification
if self.nc > 1: # cls loss (only if multiple classes)
t_aux = torch.full_like(ps_aux[:, 5:], self.cn, device=device) # targets
t_aux[range(n_aux), selected_tcls_aux] = self.cp
lcls += 0.25 * self.BCEcls(ps_aux[:, 5:], t_aux) # BCE
obji = self.BCEobj(pi[..., 4], tobj)
obji_aux = self.BCEobj(pi_aux[..., 4], tobj_aux)
lobj += obji * self.balance[i] + 0.25 * obji_aux * self.balance[i] # obj loss
- aux head更关注于recall,而lead head从aux head中精准筛选出样本。
这里有个例子,按照yolov7中的这个正负样本分配方式,那么针对图5中,蓝色点代表着gt所处的位置,实线组成的网格代表着特征图grid,虚线代表着一个grid分成了4个象限以进行正负样本分配。
如果一个gt位于蓝点位置,那么在lead head中,黄色grid将成为正样本。在aux head中,黄色+橙色grid将成为正样本。

ps:在定义损失的时候,yolov7构建了3个大类。分被是普通的yolov5的损失计算ComputeLoss,带SimOTA匹配的损失计算ComputeLossOTA,还有带辅助头和SimOTA匹配的损失计算ComputeLossAuxOTA。
- 具体的带辅助头+SimOTA匹配策略的全部代码:
class ComputeLossAuxOTA:
# Compute losses
def __init__(self, model, autobalance=False):
super(ComputeLossAuxOTA, self).__init__()
device = next(model.parameters()).device # get model device
h = model.hyp # hyperparameters
# Define criteria
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
# Focal loss
g = h['fl_gamma'] # focal loss gamma
if g > 0:
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
det = model.module.model[-1] if is_parallel(model) else model.model[-1] # Detect() module
self.balance = {3: [4.0, 1.0, 0.4]}.get(det.nl, [4.0, 1.0, 0.25, 0.06, .02]) # P3-P7
self.ssi = list(det.stride).index(16) if autobalance else 0 # stride 16 index
self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, model.gr, h, autobalance
for k in 'na', 'nc', 'nl', 'anchors', 'stride':
setattr(self, k, getattr(det, k))
def __call__(self, p, targets, imgs): # predictions, targets, model
device = targets.device
lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
bs_aux, as_aux_, gjs_aux, gis_aux, targets_aux, anchors_aux = self.build_targets2(p[:self.nl], targets, imgs)
bs, as_, gjs, gis, targets, anchors = self.build_targets(p[:self.nl], targets, imgs)
pre_gen_gains_aux = [torch.tensor(pp.shape, device=device)[[3, 2, 3, 2]] for pp in p[:self.nl]]
pre_gen_gains = [torch.tensor(pp.shape, device=device)[[3, 2, 3, 2]] for pp in p[:self.nl]]
# Losses
for i in range(self.nl): # layer index, layer predictions
pi = p[i]
pi_aux = p[i+self.nl]
b, a, gj, gi = bs[i], as_[i], gjs[i], gis[i] # image, anchor, gridy, gridx
b_aux, a_aux, gj_aux, gi_aux = bs_aux[i], as_aux_[i], gjs_aux[i], gis_aux[i] # image, anchor, gridy, gridx
tobj = torch.zeros_like(pi[..., 0], device=device) # target obj
tobj_aux = torch.zeros_like(pi_aux[..., 0], device=device) # target obj
n = b.shape[0] # number of targets
if n:
ps = pi[b, a, gj, gi] # prediction subset corresponding to targets
# Regression
grid = torch.stack([gi, gj], dim=1)
pxy = ps[:, :2].sigmoid() * 2. - 0.5
pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
pbox = torch.cat((pxy, pwh), 1) # predicted box
selected_tbox = targets[i][:, 2:6] * pre_gen_gains[i]
selected_tbox[:, :2] -= grid
iou = bbox_iou(pbox.T, selected_tbox, x1y1x2y2=False, CIoU=True) # iou(prediction, target)
lbox += (1.0 - iou).mean() # iou loss
# Objectness
tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * iou.detach().clamp(0).type(tobj.dtype) # iou ratio
# Classification
selected_tcls = targets[i][:, 1].long()
if self.nc > 1: # cls loss (only if multiple classes)
t = torch.full_like(ps[:, 5:], self.cn, device=device) # targets
t[range(n), selected_tcls] = self.cp
lcls += self.BCEcls(ps[:, 5:], t) # BCE
# Append targets to text file
# with open('targets.txt', 'a') as file:
# [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
n_aux = b_aux.shape[0] # number of targets
if n_aux:
ps_aux = pi_aux[b_aux, a_aux, gj_aux, gi_aux] # prediction subset corresponding to targets
grid_aux = torch.stack([gi_aux, gj_aux], dim=1)
pxy_aux = ps_aux[:, :2].sigmoid() * 2. - 0.5
#pxy_aux = ps_aux[:, :2].sigmoid() * 3. - 1.
pwh_aux = (ps_aux[:, 2:4].sigmoid() * 2) ** 2 * anchors_aux[i]
pbox_aux = torch.cat((pxy_aux, pwh_aux), 1) # predicted box
selected_tbox_aux = targets_aux[i][:, 2:6] * pre_gen_gains_aux[i]
selected_tbox_aux[:, :2] -= grid_aux
iou_aux = bbox_iou(pbox_aux.T, selected_tbox_aux, x1y1x2y2=False, CIoU=True) # iou(prediction, target)
lbox += 0.25 * (1.0 - iou_aux).mean() # iou loss
# Objectness
tobj_aux[b_aux, a_aux, gj_aux, gi_aux] = (1.0 - self.gr) + self.gr * iou_aux.detach().clamp(0).type(tobj_aux.dtype) # iou ratio
# Classification
selected_tcls_aux = targets_aux[i][:, 1].long()
if self.nc > 1: # cls loss (only if multiple classes)
t_aux = torch.full_like(ps_aux[:, 5:], self.cn, device=device) # targets
t_aux[range(n_aux), selected_tcls_aux] = self.cp
lcls += 0.25 * self.BCEcls(ps_aux[:, 5:], t_aux) # BCE
obji = self.BCEobj(pi[..., 4], tobj)
obji_aux = self.BCEobj(pi_aux[..., 4], tobj_aux)
lobj += obji * self.balance[i] + 0.25 * obji_aux * self.balance[i] # obj loss
if self.autobalance:
self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
if self.autobalance:
self.balance = [x / self.balance[self.ssi] for x in self.balance]
lbox *= self.hyp['box']
lobj *= self.hyp['obj']
lcls *= self.hyp['cls']
bs = tobj.shape[0] # batch size
loss = lbox + lobj + lcls
return loss * bs, torch.cat((lbox, lobj, lcls, loss)).detach()
def build_targets(self, p, targets, imgs):
indices, anch = self.find_3_positive(p, targets)
matching_bs = [[] for pp in p]
matching_as = [[] for pp in p]
matching_gjs = [[] for pp in p]
matching_gis = [[] for pp in p]
matching_targets = [[] for pp in p]
matching_anchs = [[] for pp in p]
nl = len(p)
for batch_idx in range(p[0].shape[0]):
b_idx = targets[:, 0]==batch_idx
this_target = targets[b_idx]
if this_target.shape[0] == 0:
continue
txywh = this_target[:, 2:6] * imgs[batch_idx].shape[1]
txyxy = xywh2xyxy(txywh)
pxyxys = []
p_cls = []
p_obj = []
from_which_layer = []
all_b = []
all_a = []
all_gj = []
all_gi = []
all_anch = []
for i, pi in enumerate(p):
b, a, gj, gi = indices[i]
idx = (b == batch_idx)
b, a, gj, gi = b[idx], a[idx], gj[idx], gi[idx]
all_b.append(b)
all_a.append(a)
all_gj.append(gj)
all_gi.append(gi)
all_anch.append(anch[i][idx])
from_which_layer.append(torch.ones(size=(len(b),)) * i)
fg_pred = pi[b, a, gj, gi]
p_obj.append(fg_pred[:, 4:5])
p_cls.append(fg_pred[:, 5:])
grid = torch.stack([gi, gj], dim=1)
pxy = (fg_pred[:, :2].sigmoid() * 2. - 0.5 + grid) * self.stride[i] #/ 8.
#pxy = (fg_pred[:, :2].sigmoid() * 3. - 1. + grid) * self.stride[i]
pwh = (fg_pred[:, 2:4].sigmoid() * 2) ** 2 * anch[i][idx] * self.stride[i] #/ 8.
pxywh = torch.cat([pxy, pwh], dim=-1)
pxyxy = xywh2xyxy(pxywh)
pxyxys.append(pxyxy)
pxyxys = torch.cat(pxyxys, dim=0)
if pxyxys.shape[0] == 0:
continue
p_obj = torch.cat(p_obj, dim=0)
p_cls = torch.cat(p_cls, dim=0)
from_which_layer = torch.cat(from_which_layer, dim=0)
all_b = torch.cat(all_b, dim=0)
all_a = torch.cat(all_a, dim=0)
all_gj = torch.cat(all_gj, dim=0)
all_gi = torch.cat(all_gi, dim=0)
all_anch = torch.cat(all_anch, dim=0)
pair_wise_iou = box_iou(txyxy, pxyxys)
pair_wise_iou_loss = -torch.log(pair_wise_iou + 1e-8)
top_k, _ = torch.topk(pair_wise_iou, min(20, pair_wise_iou.shape[1]), dim=1)
dynamic_ks = torch.clamp(top_k.sum(1).int(), min=1)
gt_cls_per_image = (
F.one_hot(this_target[:, 1].to(torch.int64), self.nc)
.float()
.unsqueeze(1)
.repeat(1, pxyxys.shape[0], 1)
)
num_gt = this_target.shape[0]
cls_preds_ = (
p_cls.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
* p_obj.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
)
y = cls_preds_.sqrt_()
pair_wise_cls_loss = F.binary_cross_entropy_with_logits(
torch.log(y/(1-y)) , gt_cls_per_image, reduction="none"
).sum(-1)
del cls_preds_
cost = (
pair_wise_cls_loss
+ 3.0 * pair_wise_iou_loss
)
matching_matrix = torch.zeros_like(cost)
for gt_idx in range(num_gt):
_, pos_idx = torch.topk(
cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False
)
matching_matrix[gt_idx][pos_idx] = 1.0
del top_k, dynamic_ks
anchor_matching_gt = matching_matrix.sum(0)
if (anchor_matching_gt > 1).sum() > 0:
_, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)
matching_matrix[:, anchor_matching_gt > 1] *= 0.0
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0
fg_mask_inboxes = matching_matrix.sum(0) > 0.0
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
from_which_layer = from_which_layer[fg_mask_inboxes]
all_b = all_b[fg_mask_inboxes]
all_a = all_a[fg_mask_inboxes]
all_gj = all_gj[fg_mask_inboxes]
all_gi = all_gi[fg_mask_inboxes]
all_anch = all_anch[fg_mask_inboxes]
this_target = this_target[matched_gt_inds]
for i in range(nl):
layer_idx = from_which_layer == i
matching_bs[i].append(all_b[layer_idx])
matching_as[i].append(all_a[layer_idx])
matching_gjs[i].append(all_gj[layer_idx])
matching_gis[i].append(all_gi[layer_idx])
matching_targets[i].append(this_target[layer_idx])
matching_anchs[i].append(all_anch[layer_idx])
for i in range(nl):
if matching_targets[i] != []:
matching_bs[i] = torch.cat(matching_bs[i], dim=0)
matching_as[i] = torch.cat(matching_as[i], dim=0)
matching_gjs[i] = torch.cat(matching_gjs[i], dim=0)
matching_gis[i] = torch.cat(matching_gis[i], dim=0)
matching_targets[i] = torch.cat(matching_targets[i], dim=0)
matching_anchs[i] = torch.cat(matching_anchs[i], dim=0)
else:
matching_bs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_as[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_gjs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_gis[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_targets[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_anchs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
return matching_bs, matching_as, matching_gjs, matching_gis, matching_targets, matching_anchs
def build_targets2(self, p, targets, imgs):
indices, anch = self.find_5_positive(p, targets)
matching_bs = [[] for pp in p]
matching_as = [[] for pp in p]
matching_gjs = [[] for pp in p]
matching_gis = [[] for pp in p]
matching_targets = [[] for pp in p]
matching_anchs = [[] for pp in p]
nl = len(p)
for batch_idx in range(p[0].shape[0]):
b_idx = targets[:, 0]==batch_idx
this_target = targets[b_idx]
if this_target.shape[0] == 0:
continue
txywh = this_target[:, 2:6] * imgs[batch_idx].shape[1]
txyxy = xywh2xyxy(txywh)
pxyxys = []
p_cls = []
p_obj = []
from_which_layer = []
all_b = []
all_a = []
all_gj = []
all_gi = []
all_anch = []
for i, pi in enumerate(p):
b, a, gj, gi = indices[i]
idx = (b == batch_idx)
b, a, gj, gi = b[idx], a[idx], gj[idx], gi[idx]
all_b.append(b)
all_a.append(a)
all_gj.append(gj)
all_gi.append(gi)
all_anch.append(anch[i][idx])
from_which_layer.append(torch.ones(size=(len(b),)) * i)
fg_pred = pi[b, a, gj, gi]
p_obj.append(fg_pred[:, 4:5])
p_cls.append(fg_pred[:, 5:])
grid = torch.stack([gi, gj], dim=1)
pxy = (fg_pred[:, :2].sigmoid() * 2. - 0.5 + grid) * self.stride[i] #/ 8.
#pxy = (fg_pred[:, :2].sigmoid() * 3. - 1. + grid) * self.stride[i]
pwh = (fg_pred[:, 2:4].sigmoid() * 2) ** 2 * anch[i][idx] * self.stride[i] #/ 8.
pxywh = torch.cat([pxy, pwh], dim=-1)
pxyxy = xywh2xyxy(pxywh)
pxyxys.append(pxyxy)
pxyxys = torch.cat(pxyxys, dim=0)
if pxyxys.shape[0] == 0:
continue
p_obj = torch.cat(p_obj, dim=0)
p_cls = torch.cat(p_cls, dim=0)
from_which_layer = torch.cat(from_which_layer, dim=0)
all_b = torch.cat(all_b, dim=0)
all_a = torch.cat(all_a, dim=0)
all_gj = torch.cat(all_gj, dim=0)
all_gi = torch.cat(all_gi, dim=0)
all_anch = torch.cat(all_anch, dim=0)
pair_wise_iou = box_iou(txyxy, pxyxys)
pair_wise_iou_loss = -torch.log(pair_wise_iou + 1e-8)
top_k, _ = torch.topk(pair_wise_iou, min(20, pair_wise_iou.shape[1]), dim=1)
dynamic_ks = torch.clamp(top_k.sum(1).int(), min=1)
gt_cls_per_image = (
F.one_hot(this_target[:, 1].to(torch.int64), self.nc)
.float()
.unsqueeze(1)
.repeat(1, pxyxys.shape[0], 1)
)
num_gt = this_target.shape[0]
cls_preds_ = (
p_cls.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
* p_obj.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
)
y = cls_preds_.sqrt_()
pair_wise_cls_loss = F.binary_cross_entropy_with_logits(
torch.log(y/(1-y)) , gt_cls_per_image, reduction="none"
).sum(-1)
del cls_preds_
cost = (
pair_wise_cls_loss
+ 3.0 * pair_wise_iou_loss
)
matching_matrix = torch.zeros_like(cost)
for gt_idx in range(num_gt):
_, pos_idx = torch.topk(
cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False
)
matching_matrix[gt_idx][pos_idx] = 1.0
del top_k, dynamic_ks
anchor_matching_gt = matching_matrix.sum(0)
if (anchor_matching_gt > 1).sum() > 0:
_, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)
matching_matrix[:, anchor_matching_gt > 1] *= 0.0
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0
fg_mask_inboxes = matching_matrix.sum(0) > 0.0
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
from_which_layer = from_which_layer[fg_mask_inboxes]
all_b = all_b[fg_mask_inboxes]
all_a = all_a[fg_mask_inboxes]
all_gj = all_gj[fg_mask_inboxes]
all_gi = all_gi[fg_mask_inboxes]
all_anch = all_anch[fg_mask_inboxes]
this_target = this_target[matched_gt_inds]
for i in range(nl):
layer_idx = from_which_layer == i
matching_bs[i].append(all_b[layer_idx])
matching_as[i].append(all_a[layer_idx])
matching_gjs[i].append(all_gj[layer_idx])
matching_gis[i].append(all_gi[layer_idx])
matching_targets[i].append(this_target[layer_idx])
matching_anchs[i].append(all_anch[layer_idx])
for i in range(nl):
if matching_targets[i] != []:
matching_bs[i] = torch.cat(matching_bs[i], dim=0)
matching_as[i] = torch.cat(matching_as[i], dim=0)
matching_gjs[i] = torch.cat(matching_gjs[i], dim=0)
matching_gis[i] = torch.cat(matching_gis[i], dim=0)
matching_targets[i] = torch.cat(matching_targets[i], dim=0)
matching_anchs[i] = torch.cat(matching_anchs[i], dim=0)
else:
matching_bs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_as[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_gjs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_gis[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_targets[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_anchs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
return matching_bs, matching_as, matching_gjs, matching_gis, matching_targets, matching_anchs
def find_5_positive(self, p, targets):
# Build targets for compute_loss(), input targets(image,class,x,y,w,h)
na, nt = self.na, targets.shape[0] # number of anchors, targets
indices, anch = [], []
gain = torch.ones(7, device=targets.device).long() # normalized to gridspace gain
ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
g = 1.0 # bias
off = torch.tensor([[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g # offsets
for i in range(self.nl):
anchors = self.anchors[i]
gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain
# Match targets to anchors
t = targets * gain
if nt:
# Matches
r = t[:, :, 4:6] / anchors[:, None] # wh ratio
j = torch.max(r, 1. / r).max(2)[0] < self.hyp['anchor_t'] # compare
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
t = t[j] # filter
# Offsets
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1. < g) & (gxy > 1.)).T
l, m = ((gxi % 1. < g) & (gxi > 1.)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
t = t.repeat((5, 1, 1))[j]
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
else:
t = targets[0]
offsets = 0
# Define
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy
gwh = t[:, 4:6] # grid wh
gij = (gxy - offsets).long()
gi, gj = gij.T # grid xy indices
# Append
a = t[:, 6].long() # anchor indices
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
anch.append(anchors[a]) # anchors
return indices, anch
def find_3_positive(self, p, targets):
# Build targets for compute_loss(), input targets(image,class,x,y,w,h)
na, nt = self.na, targets.shape[0] # number of anchors, targets
indices, anch = [], []
gain = torch.ones(7, device=targets.device).long() # normalized to gridspace gain
ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
g = 0.5 # bias
off = torch.tensor([[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g # offsets
for i in range(self.nl):
anchors = self.anchors[i]
gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain
# Match targets to anchors
t = targets * gain
if nt:
# Matches
r = t[:, :, 4:6] / anchors[:, None] # wh ratio
j = torch.max(r, 1. / r).max(2)[0] < self.hyp['anchor_t'] # compare
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
t = t[j] # filter
# Offsets
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1. < g) & (gxy > 1.)).T
l, m = ((gxi % 1. < g) & (gxi > 1.)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
t = t.repeat((5, 1, 1))[j]
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
else:
t = targets[0]
offsets = 0
# Define
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy
gwh = t[:, 4:6] # grid wh
gij = (gxy - offsets).long()
gi, gj = gij.T # grid xy indices
# Append
a = t[:, 6].long() # anchor indices
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
anch.append(anchors[a]) # anchors
return indices, anch
5. 实验结果与总结
贴的源码有点多,导致篇幅有点过长。最后对yolov7做一个总结。
总的来说,在模型的结构上,yolov7的模型搭建延续了yolov5的手法,提出了ELAN的一个新颖concat结构和一个新颖的MP降维结构。同时,在部分版本中使用上了Rep结构(将3x3卷积,1x1卷积,残差链接)拓扑组合在一起。
对于正负样本的匹配上,使用了yoloX的SimOTA匹配方法,与yolov5的匹配方法进行融合。也就是simOTA中的第一步“使用中心先验”替换成“yolov5中的策略”,提供了更加精确的先验知识。同时还额外使用了辅助头(不过在源码上其实并没有主动的去使用辅助头,也就是说其提供了相应的代码但没有去使用,可能是提升的点并不多0.3)
# Start training
......
compute_loss_ota = ComputeLossOTA(model) # init loss class
compute_loss = ComputeLoss(model) # init loss class
但是无论是yolov6还是yolov7都使用了SimOTA的匹配方法,足以说明SimOTA的正负样本匹配策略是先进的。辅助头在宏观上也提供了一个额外的思路,就是在中间过程也可以进行一个损失计算,作为一个辅助的损失。这个辅助损失在结构计算上完全与正常的检测头计算损失相同,只是分配的权重不一样就可以了,这个权重比也可以作为是一个超参数调节(但是不知道为什么在源码中并没有主动用上这个辅助头,还是说可能是我看错了)
而yolov6和yolov7也不约而同的都看上了参数重结构化的思路,也就是RepConv。说明这种训练过程和验证过程解耦的思路,可以改变网络的拓扑结构,从而加快推理速度,实现更快更强的目标检测算法。不过yolov7中说直接使用会影响效果,但yolov6整个结构都使用了RepConv,反而提升了整体效果6个点以上,具体听谁的这有点说不准。
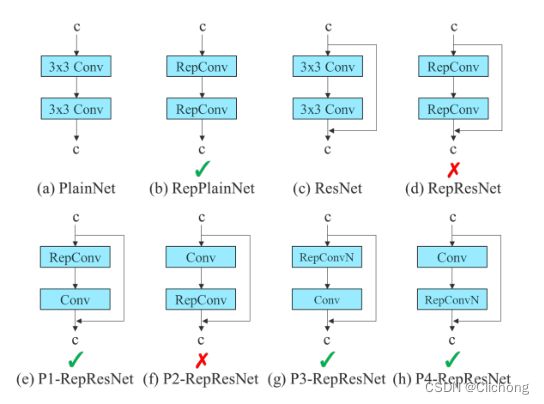
但是,不管怎样,参数重结构化这东西肯定是个好东西。
对于训练策略上,由于yolov7也是复用了yolov5的源码,所以训练策略基本也是那一套。什么Warmup,Multi-scale,AMP混合精度,余弦退火学习率策略,EMA等等这类东西,在训练策略上我认为没那个框架比yolov5使用得更全面了。这些训练策略在介绍yolov3-spp和yolov5的时候就已经介绍完了,有兴趣的朋友可以看看:
1. 目标检测YOLOv5技巧汇总专栏
2. 目标检测YOLOv3技巧汇总专栏
最后的最后,看看yolov7的实验结果来感受强悍,确实是当前最快的检测算法了。
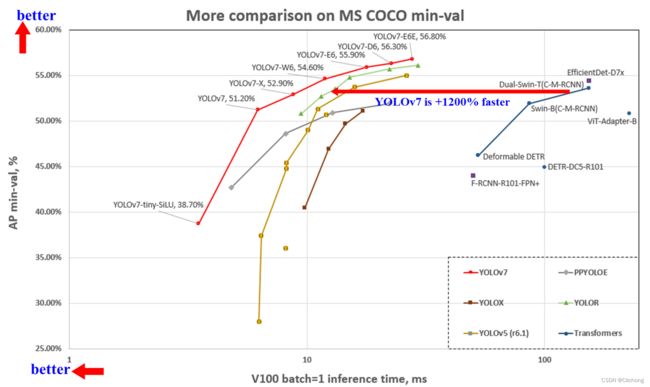
之后有机会再跑跑实验感受感受。
参考资料:
1. YOLOv7正负样本分配详解
2. 卷起来了!YOLOv7来了,史上最强YOLO!
3. 目标检测算法——YOLOV7——详解
4. 深入浅出 Yolo 系列之 Yolov7 基础网络结构详解
5. 目标检测YOLOv5技巧汇总专栏
6. 目标检测YOLOv3技巧汇总专栏