【吃瓜之旅】第一二章吃瓜学习
【吃瓜之旅】本系列是针对datawhale《吃瓜教程-西瓜书和南瓜书》的学习笔记。本次是对西瓜书第一二章的个人学习总结。第一章对机器学习做整体介绍,第二章介绍如何评价机器学习算法。整体来说这两章会融会贯通到整本书,而且难度也不小。确实如文睿大佬所说需要学完后回头再认真看看。目前已经看完了,就在这简单做做总结方便回顾复习。
第一章:绪论
1.1引言
引言通过人类经验对事情预判引入,点明机器学习的目的:利用计算机通过对数据总结“模型”,应用“模型”做判断。
1.2基本术语
这个略,看到后面就明白了。
1.3假设空间
是对一个问题做了全集讨论,比如挑西瓜,有“色泽”、“根蒂”、“巧声”三个指标,每个指标有三个值。然后假设空间为4*4*4+1。每个3+1。多的这个一代表任意都可以,最后加的1代表空集。感叹考虑的真全面。接下来可能有些假设空间冲突,引入版本空间问题。带入到归纳偏好问题中。
1.4归纳偏好
个人理解就是,两个那都觉得挺好的瓜,教你怎么挑。(挑完发现自己白努力了)。治好了我的选择困难。
主要有归纳偏好的原则:“奥卡姆剃刀”,以简单为准。
然后又提出“如何定义简单”这个问题。
接着书里面的骚操作就来了,选了二分类问题证明其实怎么努力其实都可能差不多(数学期望相等)。即“没有免费的午餐”NFL。最后还是到选瓜中,有些瓜看起来一样好,但是其中一个可能并不常见。应该把做归纳偏好的中心放在研究的问题本身上,而不是想怎么挑方法的问题。昨天就和女朋友讲其实有很多很好的女生,但是和她在一起就很放松,很合适自己。
1.5发展历程
历史课。将一些机器学的发展融到一起,像七龙珠,这节是合在一起。后面每一颗都散在各个章节。首先介绍机器学习各个时期的情况。然后介绍代表性工作,学术组织。然后总写机器学习的各种划分。接着对每一种介绍:“从样例中学习”——决策树、“连接主义学习”——BP算法、“统计学习”——SVM、“深度学习”。
1.6应用现状
分支学科应用、交叉学科应用,通过重要组织介绍机器学习的重要性,阐述了数据挖掘中机器学习、数据库是左膀右臂,统计学为数据挖掘提供思想。介绍经典应用:互联网搜索、自动驾驶、竞选核武器、深入理解“人类如何学习”的问题。
1.7阅读材料
介绍了很多机器学习的相关知识。包括入门材料、本书的参考文献、启蒙思想概念学习、学科原则、相关优质会议及刊物。
第二章:模型评估与选择
2.1经验误差与过拟合
介绍泛化能力的概念。
基本评价指标错误率、精度。
过拟合:训练模型过度,但对原本数据集的预测很好。
欠拟合:训练不足,欠练。
由于P≠NP的存在,预测数据不完全相等,过拟合问题会一直存在。
2.2评估方法
为了得到更客观,更接近真实的了解到模型的泛化能力需要有评估方法支撑。
2.2.1留出法
数据集分成训练集和测试集两块。注意要均匀分层保证数据一致性。保证质量一般会将训练集控制在2/3~4/5。
2.2.2交叉验证
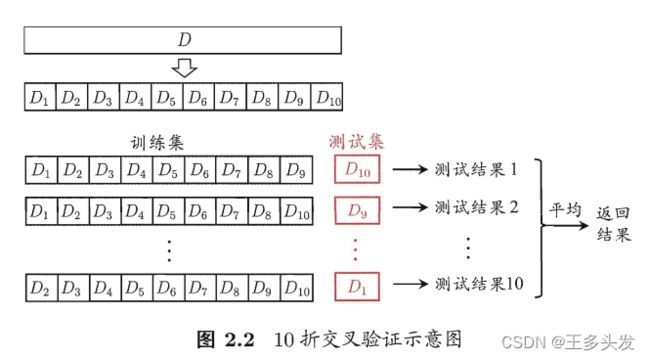
数据切片,例如分为K片,每一片都可以做测试集,剩下的当训练集。最后验证结果(误差率/acc)取均值。
有个留一法,每个元素作为Ki……计算量太大了,因为NFL也未必好。
2.2.3自助法
自己给自己做饭,每天都是炒鸡蛋。
对于数据量较少时比较好的方法,把数据随机抽出后放回数据集。反复抽组成一个和原数据集规模相同,但每次做出来的数据都不同的数据集。大概每次都会留下1/3的数据未被抽到。
2.2.4调参与最终模型
每个参数调节压力会很大,不过调好了对模型有很大帮助。
可以将测试集再区分,分为验证集和测试集。验证集只用来做模型选择和调参。在用测试集训练好模型后,需要用全量数据(测试集+训练集)对模型训练得到最终的模型。
2.3性能度量
对于回归任务:

对于分类任务:
2.3.2 查准率、查全率与F1:
针对“挑出来的多少是好瓜”、“所有好瓜有多少挑出来了”这些问题引出查准率、查全率指标。更进一步刻画模型好坏。
混淆矩阵
 最好的模型时P、R双高。也就是TP=TP+FN=TP+FP 全是好瓜,全部挑出。P=R=1
最好的模型时P、R双高。也就是TP=TP+FN=TP+FP 全是好瓜,全部挑出。P=R=1
引入P-R曲线,一般两个算法形成包含情况,最外层的算法更好。

如果有交叉,引入“平衡点”即看P=R的值谁大,更精确引入F1。
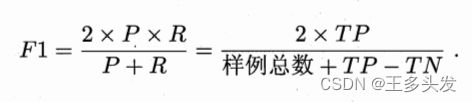

对于查准率和查全率有侧重,引入Fβ。对于多个二分类混淆矩阵,引入宏F1(对P、R做平均)、微F1(对元素做平均)。
2.3.3 ROC与AUC
根据分类中会出现分类阈值,更好的体现模型的泛化能力,观察“期望泛化性能”。引入ROC曲线。ROC横纵坐标为“真正例率(TPR)”和“假证例率(FPR)”

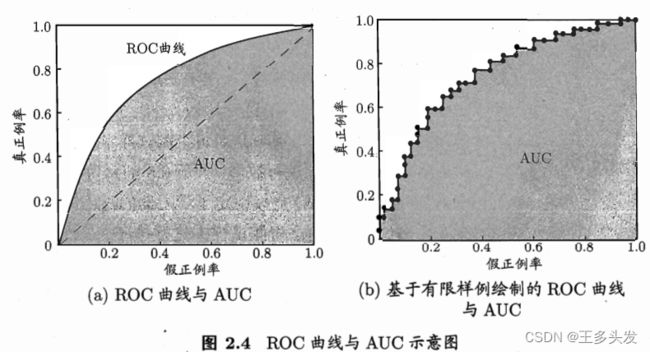
判断模型间ROC好坏,如果包得住选最外层,如果交叉选面积最大。
2.3.4 代价敏感错误率与代价曲线
结合对于NP、NF代价不同产生的评价标准。比如NP扣一分,NF扣10分。
2.4比较检验
研究模型间泛化性能统计意义上的性能优越度量。
……检验不出来
2.5偏差与方差
研究泛化误差的组成:偏差、方差、噪声。