linux管道使用_如何在Linux上使用管道

linux管道使用
 Fatmawati Achmad Zaenuri/Shutterstock.com Fatmawati Achmad Zaenuri / Shutterstock.com
Fatmawati Achmad Zaenuri/Shutterstock.com Fatmawati Achmad Zaenuri / Shutterstock.com
Use Linux pipes to choreograph how command-line utilities collaborate. Simplify complex processes and boost your productivity by harnessing a collection of standalone commands and turning them into a single-minded team. We show you how.
使用Linux管道来编排命令行实用程序的协作方式。 通过利用一系列独立命令并将它们变成专心致志的团队,简化复杂的流程并提高生产率。 我们向您展示如何。
管道无处不在 (Pipes Are Everywhere)
Pipes are one of the most useful command-line features that Linux and Unix-like operating systems have. Pipes are used in countless ways. Look at any Linux command line article—on any web site, not just ours—and you’ll see that pipes make an appearance more often than not. I reviewed some of How-To Geek’s Linux articles, and pipes are used in all of them, one way or another.
管道是Linux和类似Unix的操作系统具有的最有用的命令行功能之一。 管道以无数方式使用。 查看任何Linux命令行文章-在任何网站上,而不仅仅是我们的网站上-您都会看到管道经常出现。 我回顾了How-To GeekLinux文章,并在管道中以一种或另一种方式使用管道。
Linux pipes allow you to perform actions that are not supported out-of-the-box by the shell. But because the Linux design philosophy is to have many small utilities that perform their dedicated function very well, and without needless functionality—the “do one thing and do it well” mantra—you can plumb strings of commands together with pipes so that the output of one command becomes the input of another. Each command you pipe in brings its unique talent to the team, and soon you find you’ve assembled a winning squad.
Linux管道允许您执行shell不支持的现成操作。 但是,由于Linux的设计理念是要有许多小型实用程序,它们可以很好地执行其专用功能,并且没有不必要的功能(“做一件事,就做得很好”的口头禅),因此您可以将命令字符串与管道一起垂直以使输出一个命令的输入成为另一命令的输入。 您输入的每个命令都会为团队带来独特的才能,很快您就会发现自己已经组建了一支制胜之队。
一个简单的例子 (A Simple Example)
Suppose we have a directory full of many different types of file. We want to know how many files of a certain type are in that directory. There are other ways to do this, but the object of this exercise is to introduce pipes, so we’re going to do it with pipes.
假设我们有一个目录,其中包含许多不同类型的文件。 我们想知道该目录中有多少种特定类型的文件。 还有其他方法可以执行此操作,但是本练习的目的是引入管道,因此我们将使用管道进行此操作。
We can get a listing of the files easily using ls:
我们可以使用ls轻松获得文件列表:
ls
To separate out the file type of interest, we’ll use grep. We want to find files that have the word “page” in their filename or file extension.
为了分离出感兴趣的文件类型,我们将使用grep 。 我们要查找文件名或文件扩展名中带有“页面”字样的文件。
We will use the shell special character “|” to pipe the output from ls into grep.
我们将使用外壳特殊字符“ | ”将ls的输出通过管道传递到grep 。
ls | grep "page"

grep prints lines that match its search pattern. So this gives us a listing containing only “.page” files.
grep打印出与其搜索模式匹配的行。 因此,这为我们提供了仅包含“ .page”文件的列表。
Even this trivial example displays the functionality of pipes. The output from ls was not sent to the terminal window. It was sent to grep as data for the grep command to work with. The output we see comes from grep, which is the last command in this chain.
即使这个简单的示例也显示了管道的功能。 ls的输出未发送到终端窗口。 它已作为grep命令使用的数据发送到grep 。 我们看到的输出来自grep,这是该链中的最后一条命令。
延伸我们的链条 (Extending Our Chain)
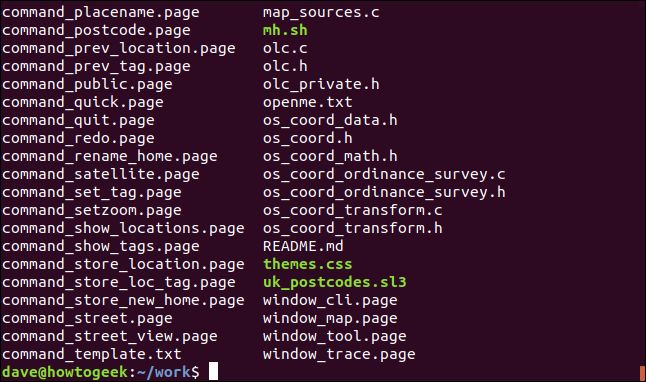
Let’s start extending our chain of piped commands. We can count the “.page” files by adding the wc command. We will use the -l (line count) option with wc. Note we’ve also added the -l (long format) option to ls . We’ll be using this shortly.
让我们开始扩展管道命令链。 我们可以通过添加wc命令来计算“ .page”文件。 我们将在wc使用-l (行数)选项。 注意,我们还向ls添加了-l (长格式)选项。 我们将很快使用它。
ls - | grep "page" | wc -l

grep is no longer the last command in the chain, so we don’t see its output. The output from grep is fed into the wc command. The output we see in the terminal window is from wc. wc reports that there are 69 “.page” files in the directory.
grep不再是链中的最后一个命令,因此我们看不到它的输出。 grep的输出被送入wc命令。 我们在终端窗口中看到的输出来自wc 。 wc报告目录中有69个“ .page”文件。
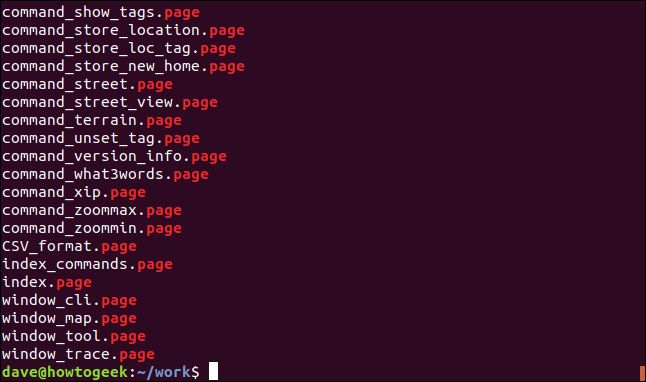
Let’s extend things again. We’ll take the wc command off the command line and replace it with awk. There are nine columns in the output from ls with the -l (long format) option. We’ll use awk to print columns five, three, and nine. These are the size, owner, and name of the file.
让我们再扩展一遍。 我们将从命令行中wc命令,并将其替换为awk 。 ls的输出中有-l (长格式)选项的九列。 我们将使用awk打印第五,第三和九列。 这些是文件的大小,所有者和名称。
ls -l | grep "page" | awk '{print $5 " " $3 " " $9}'

We get a listing of those columns, for each of the matching files.
我们为每个匹配文件获得了这些列的列表。
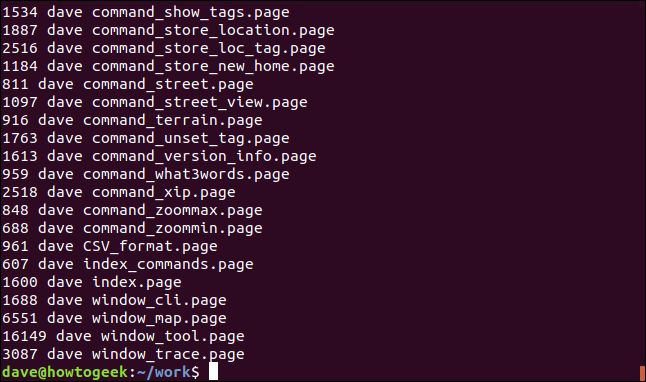
We’ll now pass that output through the sort command. We’ll use the -n (numeric) option to let sort know the first column should be treated as numbers.
现在,我们将通过sort命令传递输出。 我们将使用-n (数字)选项让sort知道第一列应被视为number 。
ls -l | grep "page" | awk '{print $5 " " $3 " " $9}' | sort -n

The output is now sorted in file size order, with our customized selection of three columns.
现在,输出已按文件大小顺序排序,并具有我们自定义的三列选择。
添加另一个命令 (Adding Another Command)
We’ll finish off by adding in the tail command. We’ll tell it to list the last five lines of output only.
我们将通过添加tail命令结束。 我们将告诉它仅列出输出的最后五行。
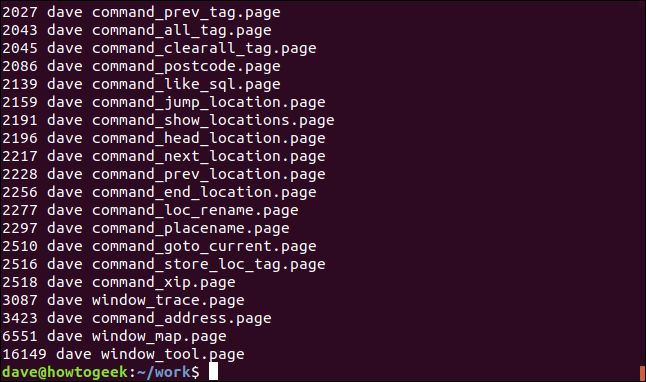
ls -l | grep "page" | awk '{print $5 " " $3 " " $9}' | sort -n | tail -5

This means our command translates to something like “show me the five largest “.page” files in this directory, ordered by size.” Of course, there is no command to accomplish that, but by using pipes, we’ve created our own. We could add this—or any other long command—as an alias or shell function to save all the typing.
这意味着我们的命令将转换为“按大小显示此目录中五个最大的“ .page”文件”。 当然,没有命令可以完成此任务,但是通过使用管道,我们创建了自己的管道。 我们可以添加此命令(或任何其他长命令)作为别名或shell函数,以保存所有键入内容。
Here is the output:
这是输出:
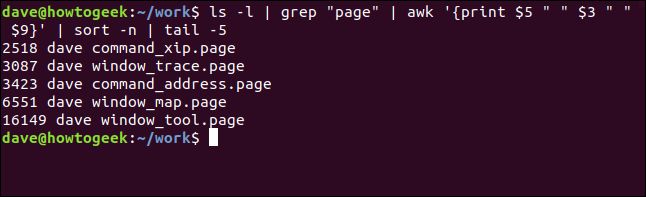
We could reverse the size order by adding the -r (reverse) option to the sort command, and using head instead of tail to pick the lines from the top of the output.
我们可以通过在sort命令中添加-r (reverse)选项来反转大小顺序,并使用head而不是tail来从输出顶部选择行。

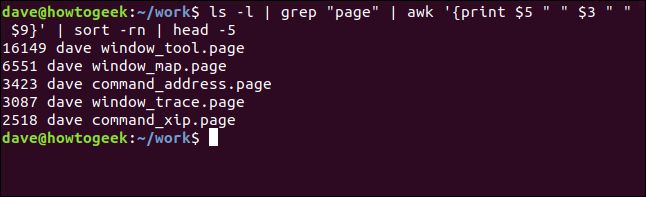
This time the five largest “.page” files are listed from largest to smallest:
这次从最大到最小列出了五个最大的“ .page”文件:
最近的一些例子 (Some Recent Examples)
Here are two interesting examples from recent How-To geek articles.
这是最近的How-To怪胎文章中的两个有趣的示例。
Some commands, such as the xargscommand, are designed to have input piped to them. Here’s a way we can have wc count the words, characters, and lines in multiple files, by piping ls into xargs which then feeds the list of filenames to wc as though they had been passed to wc as command line parameters.
某些命令(例如xargs命令)旨在将输入通过管道传递给它们。 通过这种方式, wc可以通过将ls传递到xargs ,从而将多个文件中的单词,字符和行数统计到xargs ,然后xargs将文件名列表馈送到wc就像它们已经作为命令行参数传递给wc一样。
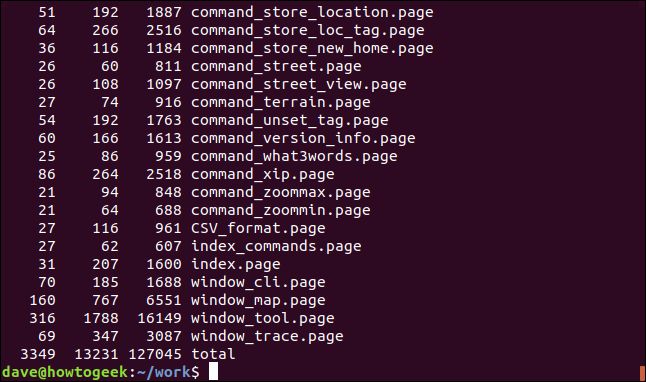
ls *.page | xargs wc

The total numbers of words, characters, and lines are listed at the bottom of the terminal window.
终端窗口底部列出了单词,字符和行的总数。
Here’s a way to get a sorted list of the unique file extensions in the current directory, with a count of each type.
这是一种获取当前目录中唯一文件扩展名的排序列表的方法,每种类型都有一个计数。
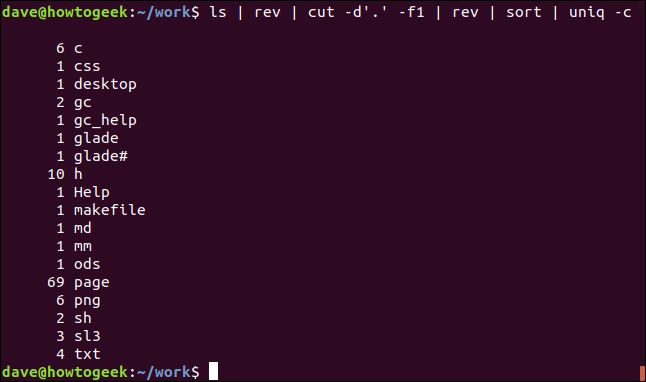
ls | rev | cut -d'.' -f1 | rev | sort | uniq -c

There’s a lot going on here.
这里有很多事情。
ls: Lists the files in the directory
ls :列出目录中的文件
rev: Reverses the text in the filenames.
rev :反转文件名中的文本。
cut: Cuts the string at the first occurrence of the specified delimiter “.”. Text after this is discarded.
cut :在指定分隔符“。”首次出现时剪切字符串。 此后的文本将被丢弃。
rev: Reverses the remaining text, which is the filename extension.
rev :反转剩余的文本,即文件扩展名。
sort: Sorts the list alphabetically.
sort :按字母顺序对列表进行排序。
uniq: Counts the number of each unique entry in the list.
uniq :计算列表中每个唯一条目的数量。
The output shows the list of file extensions, sorted alphabetically with a count of each unique type.
输出显示文件扩展名列表,并按字母顺序对每种唯一类型的计数进行排序。
命名管道 (Named Pipes)
There’s another type of pipe available to us, called named pipes. The pipes in the previous examples are created on-the-fly by the shell when it processes the command line. The pipes are created, used, and then discarded. They are transient and leave no trace of themselves. They exist only for as long as the command using them is running.
我们还有另一种类型的管道,称为命名管道。 前面示例中的管道是由Shell在处理命令行时即时创建的。 创建,使用并丢弃管道。 它们是短暂的,不会留下任何痕迹。 它们仅在使用它们的命令运行时存在。
Named pipes appear as persistent objects in the filesystem, so you can see them using ls. They’re persistent because they will survive a reboot of the computer—although any unread data in them at that time will be discarded.
命名管道在文件系统中显示为持久对象,因此您可以使用ls查看它们。 它们之所以具有持久性,是因为它们可以在计算机重新启动后幸存下来-尽管此时它们中的所有未读数据都将被丢弃。
Named pipes were used a lot at one time to allow different processes to send and receive data, but I haven’t seen them used that way for a long time. No doubt there are people out there still using them to great effect, but I’ve not encountered any recently. But for completeness’ sake, or just to satisfy your curiosity, here’s how you can use them.
一次使用了很多命名管道,以允许不同的进程发送和接收数据,但是很长一段时间以来我都没有看到它们使用这种方式。 毫无疑问,仍然有人在使用它们来产生巨大的效果,但是我最近还没有遇到过。 但是为了完整起见,或者只是为了满足您的好奇心,下面介绍了如何使用它们。
Named pipes are created with the mkfifo command. This command will create a named pipe called “geek-pipe” in the current directory.
命名管道是使用mkfifo命令创建的。 此命令将在当前目录中创建一个名为“ geek-pipe”的命名管道。
mkfifo geek-pipe

We can see the details of the named pipe if we use the ls command with the -l (long format) option:
如果将ls命令与-l (长格式)选项一起使用,则可以看到命名管道的详细信息:
ls -l geek-pipe

The first character of the listing is a “p”, meaning it is a pipe. If it was a “d”, it would mean the file system object is a directory, and a dash “-” would mean it is a regular file.
列表的第一个字符是“ p”,表示它是一个管道。 如果它是“ d”,则表示文件系统对象是目录,而破折号“-”则表示它是常规文件。
使用命名管道 (Using the Named Pipe)
Let’s use our pipe. The unnamed pipes we used in our previous examples passed the data immediately from the sending command to the receiving command. Data sent through a named pipe will stay in the pipe until it is read. The data is actually held in memory, so the size of the named pipe will not vary in ls listings whether there is data in it or not.
让我们使用我们的管道。 我们在前面的示例中使用的未命名管道将数据立即从发送命令传递到接收命令。 通过命名管道发送的数据将保留在管道中,直到被读取。 数据实际上保存在内存中,因此无论管道中是否有数据,命名管道的大小在ls列表中都不会改变。
We’re going to use two terminal windows for this example. I’ll use the label:
在此示例中,我们将使用两个终端窗口。 我将使用标签:
# Terminal-1
in one terminal window and
在一个终端窗口中
# Terminal-2
in the other, so you can differentiate between them. The hash “#” tells the shell that what follows is a comment, and to ignore it.
另外,您可以区分它们。 井号“#”告诉外壳程序其后是注释,并忽略它。
Let’s take the entirety of our previous example and redirect that into the named pipe. So we’re using both unnamed and named pipes in one command:
让我们来看完整前面的示例,然后将其重定向到命名管道中。 因此,我们在一个命令中同时使用了未命名管道和已命名管道:
ls | rev | cut -d'.' -f1 | rev | sort | uniq -c > geek-pipe

Nothing much will appear to happen. You may notice that you don’t get returned to the command prompt though, so something is going on.
似乎什么都不会发生。 您可能会注意到,虽然您没有返回到命令提示符,所以正在发生某些事情。
In the other terminal window, issue this command:
在另一个终端窗口中,发出以下命令:
cat < geek-pipe

We’re redirecting the contents of the named pipe into cat, so that cat will display that content in the second terminal window. Here’s the output:
我们将命名管道的内容重定向到cat ,以便cat将在第二个终端窗口中显示该内容。 这是输出:
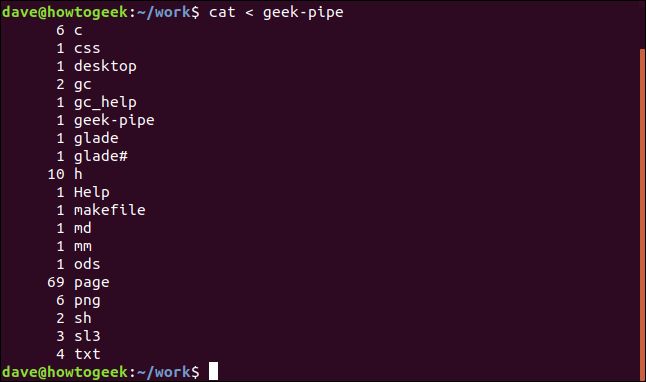
And you’ll see that you have been returned to the command prompt in the first terminal window.
并且您会看到您已经回到第一个终端窗口中的命令提示符。

So, what just happened.
因此,发生了什么事。
- We redirected some output into the named pipe. 我们将一些输出重定向到命名管道。
- The first terminal window did not return to the command prompt. 第一个终端窗口没有返回到命令提示符。
- The data remained in the pipe until it was read from the pipe in the second terminal. 数据保留在管道中,直到从第二个终端的管道中读取数据为止。
- We were returned to the command prompt in the first terminal window. 我们回到了第一个终端窗口中的命令提示符。
You may be thinking that you could run the command in the first terminal window as a background task by adding an & to the end of the command. And you’d be right. In that case, we would have been returned to the command prompt immediately.
您可能会认为可以通过在命令的末尾添加&来将第一个终端窗口中的命令作为后台任务运行。 而且你会是对的。 在这种情况下,我们将立即返回到命令提示符。
The point of not using background processing was to highlight that a named pipe is a blocking process. Putting something into a named pipe only opens one end of the pipe. The other end isn’t opened until the reading program extracts the data. The kernel suspends the process in the first terminal window until the data is read from the other end of the pipe.
不使用后台处理的目的是要突出显示命名管道是一个阻塞过程。 将东西放到命名管道中只会打开管道的一端。 直到读取程序提取数据后,另一端才打开。 内核在第一个终端窗口中挂起该进程,直到从管道的另一端读取数据为止。
管道的力量 (The Power of Pipes)
Nowadays, named pipes are something of a novelty act.
如今,命名管道已成为一种新颖的行为。
Plain old Linux pipes, on the other hand, are one of the most useful tools you can have in your terminal window toolkit. The Linux command line starts to come alive for you, and you get a whole new power-up when you can orchestrate a collection of commands to produce one cohesive performance.
另一方面,普通的老式Linux管道是您可以在终端窗口工具箱中拥有的最有用的工具之一。 Linux命令行开始为您启用,并且当您可以组织一组命令以产生一种内聚的性能时,您将获得全新的启动。
Parting hint: It is best to write your piped commands by adding one command at a time and getting that portion to work, then piping in the next command.
分步提示:最好编写一次管道命令,方法是一次添加一个命令并使该部分起作用,然后通过管道传递下一个命令。
翻译自: https://www.howtogeek.com/438882/how-to-use-pipes-on-linux/
linux管道使用