「Python数据分析系列」2.快速掌握Python编程基础

来源 | Data Science from Scratch, Second Edition
作者 | Joel Grus
译者 | cloverErna
校对 | gongyouliu
编辑 | auroral-L
全文共8776字,预计阅读时间50分钟。
第二章 快速掌握Python编程基础
2.1 Python之禅
2.2 获取Python
2.3 虚拟环境
2.4 空白格式
2.5 模块
2.6 函数
2.7 字符串
2.8 异常
2.9 列表
2.10 元组
2.11 字典
2.12 计数器
2.13 集合
2.14 控制流
2.15 真和假
2.16 排序
2.17 列表解析
2.18 自动化测试和断言
2.19 面向对象编程
2.20 迭代器和生成器
2.21 随机性
2.22 正则表达式
2.23 函数式编程
2.24 zip和参数拆分
2.25 args和kwargs
2.26 类型注释
2.27 欢迎来到DataSciencester
2.28 进一步探索
难以置信,25年来Python始终广受追捧。
——迈克尔 • 佩林
DataSciencester 的所有新员工都需要接受入职培训,其中最有趣的部分是 Python 的速成课程。
本章不是全面的 Python 教程,而是旨在突出对我们来说最重要的部分(其中一部分通常不是 Python 培训教程的重点)。如果之前从未使用过 Python,那么你可能先需要学习一点入门课程来了解它。
2.1Python之禅
Python 对其设计原则有一些禅宗意味的描述,你可以在 python 解释器中输入“import this”查看。
其中讨论最多的一句如下所示:
应该提供一种——且最好只提供一种——明显的解决方案。
按照这种“明显”的方式编写的代码(对新手来说可能并不明显)通常被称为“Python 风格”。虽然这不是一本专门介绍 Python 的书,但我们偶尔会对比用 Python 风格和非 Python 风格的方式来做相同的事情。当然,我们通常会支持用 Python 风格的方式解决问题。
其他几句则涉及美学:
美优于丑,明确优于隐晦,简单优于复杂。
这些思想将代码中体现。
2.2 获取Python
注意
由于相关安装指南的内容可能会发生变化,而印刷好的纸书不能及时更新,有关如何安装 Python 的最新说明可以在本书的 GitHub repo中找到。
如果书中的安装指南不适合你,请在下面查看。
你可以从 Python 网站下载 Python,但如果你没安装 Python,建议安装 Anaconda 版,该版已包含了数据科学工作中所需的大多数库。
我编写本书第 1 版时,Python 2.7 仍是大多数数据科学家的首选版本。因此,本书的第 1 版是基于 Python 2.7 写的。
然而,在过去几年中,绝大多数人已开始使用 Python 3。最近的 Python 版本有许多功能,可以更容易地编写干净的代码,我们将充分利用仅在 Python 3.6 或更高版本中才有的功能优势。这意味着应该安装 Python 3.6 或更高版本。(此外,许多有用的库即将结束对 Python 2.7 的支持,这是升级版本的另一个原因。)
2.3 虚拟环境
下一章开始使用 matplotlib 库生成图表。这个库不属于 Python 的核心,因此需要自己安装。每个数据科学项目都要依赖一些外部库,有时甚至不同的项目需要不同版本的库。如果你只安装单个 Python,这些库就会发生冲突并导致各种问题。
标准的解决方案是使用虚拟环境(virtual environment),这些是沙盒化的 Python 环境,它们维护自己的 Python 库版本(根据设置环境的方式,还可以管理 Python 的版本)。
本节将解释如何设置 Anaconda 的工作环境,因此建议你安装 Anaconda Python 版。如果不使用 Anaconda,可以使用内置的 venv 模块或安装 virtualenv 模块。在这种情况下,你应该遵循其指南。
要创建(Anaconda)虚拟环境,只需执行以下操作:

按照提示操作,你将拥有一个名为“dsfs”的虚拟环境,其中包含以下说明:

如上所示,然后使用以下命令激活环境:
![]()
现在,命令提示符中应该变为显示环境激活状态。在我的 MacBook 上,表现如下所示:
![]()
只要此环境处于活动状态,安装的任何库都将仅安装在 dsfs 环境中。在看完本书后,你应该为自己的后续项目创建环境。
现在你已拥有了自己的虚拟环境,首先安装 IPython,它是一个功能齐全的 Python shell:
![]()
注意
Anaconda 带有自己的库管理器 conda,但也可以使用 Python 的标准包管理器 pip,这也是我们要用的。
本书的其余部分将假设你已创建并激活了这样的 Python 3.6 虚拟环境(随便用什么名称都可以),后面章节中学习的内容会依赖于前面章节中安装的库。
一条铁律:在虚拟环境中工作,而不是使用“base”环境(Python 基础环境)。
2.4 空白格式
许多语言使用大括号来分隔代码块。Python 使用缩进:

这使得 Python 代码非常易读,但也意味着你必须非常小心缩进格式。
警告
程序员经常会争论缩进是使用 Tab 还是空格。对于许多语言而言,这并不重要,但 Python 会认为 Tab 和空格是不同的缩进,如果混合使用则会使代码无法运行。编写 Python 时,应始终使用空格,而不是 Tab。(如果在编辑器中编写代码,则可以对其进行配置,使得 Tab 键只插入空格。)
Python 会忽略方括号和圆括号内的空格,这对冗长的计算很有帮助:
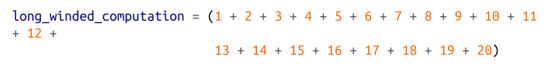
并使代码更易读:

你也可以使用反斜杠来表示语句继续到下一行,尽管我们几乎不这么做:

空白格式的一个后果是,很难将代码复制并粘贴到 Python shell 中。比如,如果尝试粘贴代码:

在粘贴到 Python shell 后,会收到以下提示:
![]()
这是因为解释器认为空行表示 for 循环部分的结束。
IPython 有一个名为 %paste 的魔幻函数,可正确粘贴剪贴板的内容,包括空白。仅这一点,就是使用 IPython 的好理由。
2.5模块
Python 默认情况下不会加载某些特性(features)。这些特征包括语言本身的部分特性以及你自己下载的第三方包的特性。为了使用这些特性,你需要导入包含这些特性的模块。
一种方法是简单地导入模块本身:

在这里,re 是包含用于处理正则表达式的函数和常量的模块。通过 import 导入模块后,必须在这些函数前面加上 re. 才能访问它们。
如果代码中已有不同的 re,则可以使用别名:

如果模块名称很长或者要打很多字,也可以这样做。例如,使用 matplotlib 可视化数据时,标准转换如下所示:

如果你需要模块中的一些特定值,则可以显式导入它们并可以不受限制地使用它们:

如果你的习惯不好,可以将模块的全部内容导入命名空间,这可能会无意中覆盖已定义的变量:

但是,只要你不想将事情弄糟,就别这么做。
2.6 函数
函数是一种通过输入零个或者多个输入,返回相应输出的规则。在 Python 中,通常使用 def 定义函数:

Python 函数是第一类函数,这意味着可以将它们赋给别的变量,或将它们像其他参数一样传递给其他函数:

创建简短的匿名函数或 lambda 也很容易:
![]()
可以将 lambda 赋给变量,尽管大多数人会告诉你应该用 def:

函数的参数可以定义默认值,当使用非默认值参数时需要显式输入参数:

按名称指定参数有时很有用:

我们将创建很多很多函数。
2.7 字符串
字符串可以用单引号或双引号分隔(但引号必须对应匹配):

Python 使用反斜杠为特殊字符编码。例如:

如果要将反斜杠作为反斜杠本身使用(可能在 Windows 系统中的目录名称或正则表达式中遇到),则可以使用 r"" 创建原始字符串:

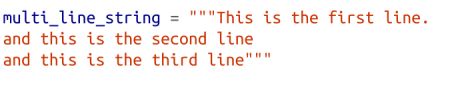
可以使用三重引号创建多行字符串:
f-string 是 Python 3.6 中的一个新的处理字符串方式,它提供了一种将值替换为字符串的简单方法。如果我们分别给出了名字和姓氏:

要将它们组合成一个全名,有多种方法可以构造这样的 fullname 字符串:


但 f-string 的方式更易于操作:

本书倾向于使用这种方法。
2.8 异常
当程序运行有问题时,Python 会报异常。未处理的异常会导致程序崩溃。可以使用 try 和 except 处理:

虽然在许多语言中异常被认为是不好的情况,但在 Python 中,不必因为使用这些技巧而感到难堪,有时这么做可以使代码更清晰。
2.9 列表
Python 中最基本的数据结构是列表,它是一个有序的集合(与其他语言中被称为数组的概念类似,但具有一些附加功能):

可以使用方括号获取或设置列表的第 n 个元素的值:

还可以使用方括号来对列表进行切片操作。切片 i:j 表示从 i(包括)到 j(不包括)的所有元素。如果在切片的开头留空,你将从列表的开头开始切片;如果末尾留空,你将切到列表的结尾:

字符串和其他“序列”类型的数据可以用类似的方法切割。
切片可以通过第三个参数来表示其步幅,步幅可以是负数:
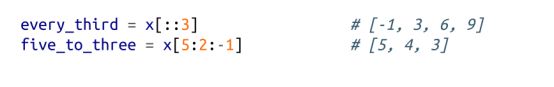
Python 用运算符 in 来检查某值是否存在于列表中:

这种检查每次都会遍历整个列表的元素,这意味着除非列表长度很短(或者你不在乎检查需要多长时间),否则就不应该进行这样的检查。
将列表连接在一起很容易。如果要修改列表,可以使用 extend 从其他集合中添加元素:

如果你不想修改 x,可以使用列表加法:
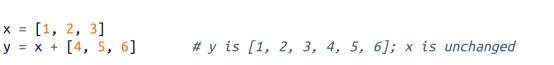
更常见的做法是,一次在列表中只添加一个元素:

当你知道它们包含多少个元素时,可以方便地提取列表值:

但当等号两边的元素个数不同时,就会报出 ValueError。
一种常见的习惯用法是使用下划线来表示要丢弃的值:

2.10 元组
元组是列表的堂兄弟。对列表做的任何不涉及修改的操作都可以对元组进行。可以用圆括号(或什么都不用)而不是方括号来指定一个元组:

元组是从函数返回多个值的便捷方式:

元组(和列表)也可用于多重赋值(multiple assignment):

2.11 字典
另一个基本数据结构是字典,它将值与键相关联,并允许快速检索给定键所对应的值:

可以使用方括号查找键的值:
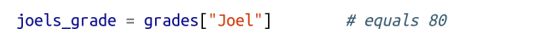
但是如果找的键不在字典中,则会报出 KeyError:

可以用 in 确认键是否存在于字典中:
![]()
这种查找方式即使对于大型字典也很快。
字典有一个 get 方法,当查找一个不在字典中的键时,它返回一个默认值(而不是报出异常):

可以使用相同的方括号指定键/值对:

如第 1 章所述,可以使用字典来表示结构化数据:

后面会有一个更棒的实现方式。
除了查特定的键,字典允许我们查里面所有的键与值:

字典键必须是“可散列的”,尤其是不能使用列表作为键。如果你需要一个多维的键,则应该使用一个元组或找出一种方法将键转换成一个字符串。
defaultdict
假设你需要计算某个文档中的单词数目。一种显而易见的方法是创建一个字典,其中键是单词,值是出现的次数。当检查每个单词时,如果它已在字典中,则增加其计数;如果不在字典中,则将其添加到字典中:

也可以遵循“与其瞻前顾后,不如果断行动”的原则,在查找缺失键的时候,果断处理异常:
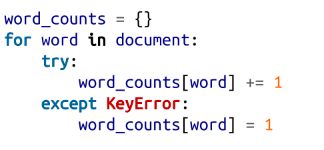
第三种方法是使用 get,它可以优雅地处理缺失键:

上述三种方法都略显笨拙,这就是为什么 defaultdict 很有用。defaultdict 类似于标准的字典,除了当你尝试查找它不包含的键时,它首先使用你在创建它时提供的无参数函数为其添加值。为了使用 defaultdict,你必须从 collections 中导入它们:

该方法也可用于 list 或 dict,甚至是你自己的函数:

当我们使用字典“收集”某些键的对应结果,并且不希望每次都检查键是否存在时,这是非常有用的方法。
2.12 计数器
计数器将一个值序列转换为类似于 defaultdict(int) 的键映射到计数的对象:

这为我们解决单词计数问题提供了一种非常简单的方法:
# 回忆一下,文档是一个单词的列表

Counter 实例有通常很有用的 most_common 方法:
# 打印10个最常见的词及其计数

2.13 集合
集合是另一种很有用的数据结构,它表示一组不同元素的集合。可以在大括号中列出其元素来定义集合:
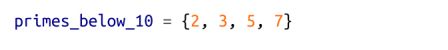
但是,空集不能这样定义,因为 {} 已意味着“空字典”。因此,需要使用 set() 定义空集:

我们使用集的主要原因有两个。一是集上有一种非常快速的操作:in。如果我们有一个包含大量元素的对象,要对其元素进行测试,那么集比列表更合适:
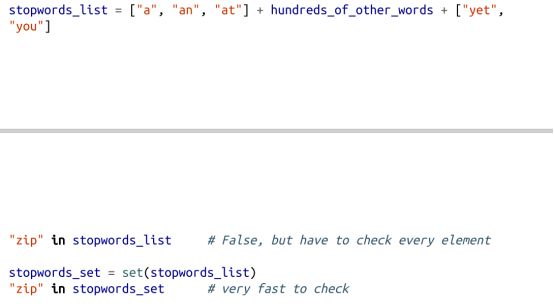
二是易于在对象中找到所有不同的元素:

我们使用集合的频率远低于字典和列表。
2.14 控制流
与大多数编程语言一样,可以使用 if 执行有条件的操作:

也可以在一行中写下 if-then-else 三元组,我们偶尔会这样做:
![]()
Python 也有 while 循环:

但 for 和 in 是更常规的方式:

如果你需要更复杂的逻辑表达式,可以使用 continue 和 break:

这段代码会打印 0、1、2 和 4。
2.15 真和假
Python 中的布尔值除了首字母是大写的,其他用法与大多数其他语言一样:

Python 使用 None 来表示不存在的值。它类似于其他语言的 null:

Python 在需要布尔值的地方都可以使用任何表达式。以下都表示“假”:

基本上其他所有值被视为“真”。这样你可以轻松使用 if 语句来对空列表、空字符串、空字典等进行检查。如果你不经意间做了这件事情,它有时也会导致棘手的 bug:

另一种较短(但可能更令人困惑)的做法如下所示:
![]()
当第一个值为“真”时返回第二个值,而当第一个值不为“真”时则返回第一个值。类似地,如果 x 的取值可能是一个数或可能是 None,那么
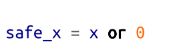
绝对是一个数,然而:

可能更具可读性。
Python 有一个 all 函数,它的取值是列表,并在每个元素都是“真”的时候返回 True;还有一个 any 函数,当至少有一个元素是“真”时,它返回 True:

2.16 排序
每个 Python 列表都有一个 sort 方法可以对其排序。如果不想搞乱列表,则可以使用 sorted 函数,它会返回一个新列表:
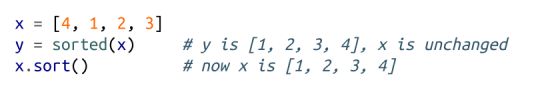
默认情况下,sort(和 sorted)基于元素之间的朴素比较,将列表元素从小到大排序。
如果希望元素从大到小排序,则可以指定 reverse=True 参数。除了比较元素本身,还可以通过key参数指定函数,来对函数的结果排序:
# 对元素的绝对值从大到小排序

2.17 列表解析
有时,你可能希望在只保留列表的部分特定元素或更改其中一些元素,或同时做这两种变动的情况下,将列表转换为另一个列表。这样操作的 Python 技巧叫作列表解析(list comprehension):

也可以类似地将列表转换为字典或集合:

如果你不需要原列表中的值,则通常使用下划线作为变量:
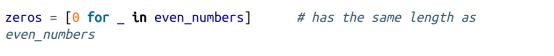
列表解析可以包括多个 for 循环:

后面的 for 语句可以使用前面 for 循环的结果:

我们将大量使用列表解析。
2.18 自动化测试和断言
作为数据科学家,我们会编写大量代码。如何才能确信我们的代码是正确的呢?一种方法是使用类型(稍后讨论),另一种方法是自动化测试。
用于编写和运行测试的框架有很多,但在本书中,我们将限制自己使用 assert 语句,当指定的条件不是“真”时,就会导致代码报出 AssertionError:

正如在第二种情况中所看到的,如果断言失败,你可以选择添加要打印的消息。
断言 1 + 1 = 2 并不是特别有趣。更有趣的是断言编写的函数正在按照预期计算:

本书将以这种方式使用 assert。它是一个很好的实践,我们强烈建议你在自己的代码中多使用它。(如果你看一下本书在 GitHub 上的代码,就会发现它包含了比书中印刷的多得多的 assert 语句。这有助于确保我们为你编写的代码完全正确。)
另一种不太常用的方式是断言函数的输入:

我们偶尔会这样做,但更多时候会使用 assert 来检查代码是否正确。
2.19 面向对象编程
与许多语言一样,Python 允许定义类,以封装数据和函数,并对其进行操作。我们有时会用类来使代码更清晰、更简单。构建一个带有大量注释的示例来解释它们可能是最简单的。
我们将构建一个表示“计数器”的类,这个类用于在门口统计有多少人出现于“数据科学高级主题”会议中。
它有一个计数的结果,可以被单击以增加计数,允许 read_count,并可以重置为零。(在现实生活中,有一种计数器会从 9999 归零至 0000,但我们不会为此烦恼。)
要定义类,请使用关键字 class 和满足帕斯卡命名法(PascalCase)的名称:

一个类包含零个或多个成员(member)函数。按照惯例,每个函数的第一个参数 self 引用特定的类实例。
通常,类有一个名为 __init__ 的构造函数。它包括你构建类实例所需的所有参数,并执行你需要的所有初始设置:

虽然构造函数有一个有趣的名称,但我们只使用类名来构造计数器实例:

请注意,__init__ 方法名称以双下划线开头和结尾。这些“神奇”方法有时被称为“dunder”方法(即 doubleUNDERscore 的简写)并代表“特殊”行为。
注意
名称以下划线开头的类方法——按惯例——可以认为是“私有”的,且类的用户不应该直接调用它们。但是,Python 不会阻止用户直接调用它们。
另一个类似的方法是 __repr__,它生成类实例中的字符串表示:

最后需要实现类的公共(public)API:

完成类的定义后,用 assert 为我们的计数器编写一些测试用例:
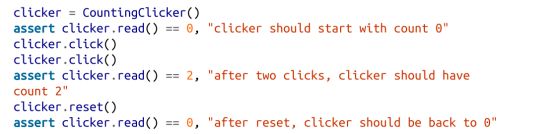
编写这样的测试用例有助于确保代码按其设计的方式工作,并且当我们对其进行更改后它仍会正常工作。
我们偶尔也会创建从父类继承(inherit)其某些功能的子类(subclass)。例如,可以使用 Counting Clicker 作为基类创建一个不可重置的点击器,并重写 reset 方法,使其不执行任何操作:


2.20 迭代器和生成器
列表的一个好处是可以通过索引检索特定元素,但你并不总是需要这个功能!十亿个数的列表会占用大量内存。如果你一次只想要一个元素,那么没必要让它们占满内存。如果你只需要前几个元素,那么产生全部的十亿个数就很浪费。
通常只需使用 for 和 in 迭代数据集即可。在这种情况下,我们可以创建生成器(generator),它可以像列表一样迭代,但根据需要延迟(lazily)生成它们的值。
创建生成器的一种方法是使用函数和 yield 运算符:

下面的循环每次消耗一个 yield 值,直到消耗完:

(事实上,range 函数本身就是延迟的,因此这样做没什么意义。)
使用生成器,你甚至可以创建一个无限序列:

尽管你可能不应该在没有使用某种 break 逻辑的情况下进行这种迭代。
TIP
延迟的另一面是你只能对生成器迭代一次。如果需要多次迭代,则需要每次重新创建生成器,或使用列表。如果生成值的代价很高,则使用列表或许更好。
创建生成器的第二种方法是使用包含在圆括号中的 for 语句解析:
![]()
这种“生成器解析”在你(使用 for 或 next)迭代它之前不做任何工作。可以使用它来构建精细的数据处理管道:

通常,当我们迭代列表或生成器时,不仅需要值,还需要它们的索引。对于这种常见情况,Python 提供了一个 enumerate 函数,它将值转换为 (index, value) 对:
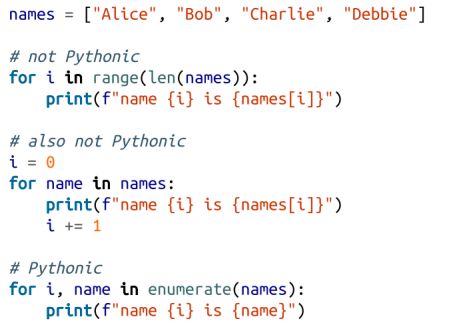
我们会经常使用这种技巧。
2.21 随机性
当我们学习数据科学时,经常需要生成随机数。可以使用 random 模块生成随机数:

如果你想获得可重现的结果,random 可以根据 random.seed 设置的内部状态生成伪随机(即确定性)数:

我们有时会使用 random.randrange,它接受一个或两个参数,并返回从相应 range 中随机选择的一个元素:

还有一些其他的方便方法。例如,random.shuffle 可以随机重新排序列表中的元素:

如果你需要从列表中随机取一个元素,则可以使用 random.choice:

如果需要不放回地随机选择元素样本(即没有重复),则可以使用 random.sample:

如果需要放回地随机选择元素样本(即允许重复),则可以多次调用 random.choice:

2.22 正则表达式
正则表达式提供了一种搜索文本的方法。它们非常有用,但也相当复杂——因此有很多专门介绍正则表达式的书。在后面涉及正则表达式的地方,我们会详细讲解,这里只给出在 Python 中如何使用它们的几个示例:

一件需要注意的重要事情是 re.match 检查字符串的开头是否与正则表达式匹配,而 re.search 检查字符串的任何部分是否与正则表达式匹配。在某些时候如果不能区分这两个功能,就会造成不好的结果。
官方文档中有更详细的说明。
2.23 函数式编程
本书的第 1 版在此板块介绍了 Python 的 partial、map、reduce 和 filter 函数。在启蒙之旅中,我意识到最好避开使用这些函数。本书已用列表解析、for 循环和其他更符合 Python 风格的结构取代了它们。
2.24zip和参数拆分
当需要将两个或多个列表链接(zip)在一起时,使用 zip 函数可以将多个可迭代对象转换为一个以对应元素构成的元组为元素的可迭代对象:

如果列表的长度不同,则 zip 会在第一个列表结束后立即停止。
你还可以使用一种特殊的技巧“解压(unzip)”列表:

星号(*)执行参数拆分(argument unpacking),它使用 pairs 作为独立参数传给 zip。结果和调用下面的函数一样:
![]()
可以将参数拆分与任何函数一起使用:

参数拆分并不是特别常用,但当我们用到它时,就会发现这是一个巧妙的技巧。
2.25args和kwargs
假设我们想要创建一个高阶函数,它将某个函数 f 作为输入,对于任何输入,都返回 f 值的两倍的新函数:

这个函数在下面的情况中可以实现:


但是,它不适用于带有多个参数的函数:

我们需要的是一种可以采用任意参数的函数的方法。可以通过参数拆分和一些小技巧来做到这一点:

也就是说,当我们定义这样的函数时,args 是其未命名参数的元组,而 kwargs 是其已命名参数的字典。反过来,则可以使用列表(或元组)和字典为函数提供参数:

你可以用类似的方式,使用这种有趣的技巧。我们只会用它来创建可以接受任意参数的高阶函数:

一般来说,如果你明确知道函数需要什么类型的参数,那么你的代码会更加正确且更具可读性。因此,只有当我们没有其他选择时,才会使用 args 和 kwargs。
2.26 类型注释
Python 是一种动态类型(dynamically typed)语言。这意味着,只要我们以有效的方式使用对象,Python 通常不关心对象类型:

而在静态类型(statically typed)语言中,我们的函数和对象将需要指定的类型:

实际上,Python 的近几个版本(差不多)具备这样的功能。前一版的add函数,带有 int 类型注释就是有效的 Python 3.6 写法!
但是,这些类型注释实际上并没有做什么贡献。你仍可以使用带注释的 add 函数来添加字符串,并且对 add(10, "five") 的调用仍会引发完全相同的 TypeError。
也就是说,在 Python 代码中使用类型注释仍(至少)有四个不错的理由:
❤类型是一种重要的文档形式。在一本通过代码教你理论和数学概念的书中,这是非常正确的。比较以下两个函数定义 :

第二个信息丰富得多,因此希望你也这样做。(此时我已习惯于输入提示,而很难阅读无类型注释的 Python 代码。)
❤ 有一些外部工具(最受欢迎的是 mypy)来读取代码,检查类型注释,并在运行代码之前提示类型错误。例如,如果你在包含 add("hi ", "there") 的文件上运行 mypy,它就会警告你:

与 assert 测试一样,这是在你运行代码之前查找代码错误的好方法。书中的叙述不涉及这种类型检查,但在这之前我会运行一段这样的程序,以确保书本身的正确性。
❤考虑代码中的类型,迫使你设计更清晰的函数和接口:

在这里的函数中,其 operation 参数可以是 string、int、float 或 bool。这个功能很可能很脆弱且难以使用,但类型被指明后,它变得更加清晰。这迫使我们以不那么笨重的方式来设计,用户因此会非常感谢我们。
❤注明类型后,编辑器能帮助你实现自动补全函数(见图 2-1)等操作,并对类型错误有所反馈。
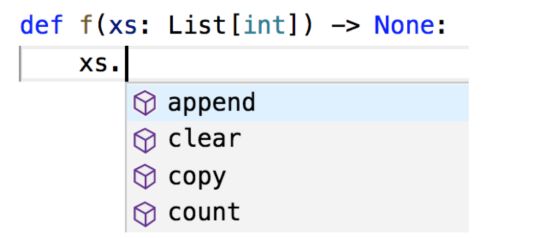
图 2-1:VSCode 样例,但你的编辑器也可以做同样的事情
有些人坚持认为,类型提示对大型项目可能有价值,对小型项目却不划算。然而,由于类型提示几乎无须花费额外的时间去输入,同时编辑器的提示能节省时间,因此,我认为即使对于小型项目,类型提示实际上也有助于更快地编写代码。
出于这些原因,本书余下的所有代码都将使用类型注释。希望通过使用类型注释来推动读者保持这样的习惯。但我怀疑在读完本书后读者会改变主意。
如何编写类型注释
可以看到,对于 int、bool 以及 float 这样的内置类型,只需使用类型本身作为注释即可。但如果你有一个列表该怎么办呢?
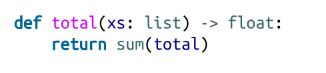
这样做是正确的,但类型不够具体。我们真的希望 xs 是一个以浮点数为元素的列表,而不是(比如说)一个以字符串为元素的列表。
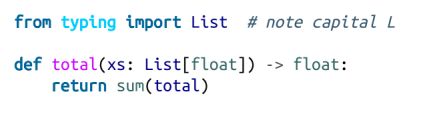
typing 模块提供了许多参数化类型,我们可以用它来做到这一点:
目前,我们只为函数的参数和返回值指定了类型注释。对于变量,常用类型如下所示:

但是,有时它并不明显:


在这种情况下,我们将提供内联类型提示:
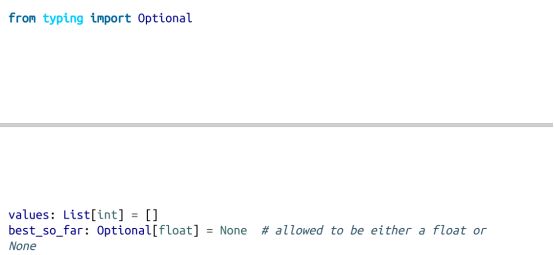
typing 模块包含许多其他类型,我们只使用其中的一部分:

最后,由于 Python 有一级函数,因此它们还需要一种类型来表示。下面是一个精心设计的例子:

因为类型注释只是 Python 对象,所以我们将它们分配给变量以使其更容易引用:

读完本书后,你会非常熟悉读写类型注释,我们希望你能在自己的代码中使用它们。
2.27 欢迎来到DataSciencester
这些就是新员工培训的全部内容。对了,还有不要盗用东西。
2.28 进一步探索
Python 教程比比皆是,官方教程是一个不错的选择。
如果你决定使用 IPython,官方 IPython 教程将会帮你入门,试试吧。
mypy 文档将为你提供关于 Python 类型注释和类型检查的更多信息。

