MySQL索引学习
文章目录
- 一、什么是索引
- 二、索引的结构
-
- 1:B-Tree
-
- m阶B-Tree满足规则
- 示例
- 查询
- 插入
- 删除
- 2:B+Tree
-
- 和B-Tree的不同点
- 为什么B+树适合索引
- 3:hash索引
- 三、索引的类别
-
- 1:聚集(聚簇)和非聚集索引
- 2:唯一索引和主键索引
- 3:全文索引
- 4:组合索引
- 四、使用索引注意事项
-
- 1:索引覆盖
- 2:组合索引顺序
- 3:索引的长度
- 4:排序
- 5:影响
- 6:独立的列
- 五、执行计划简析
-
- 1:key
- 2:rows
- 3:extra
一、什么是索引
索引(在MySQL中也叫做“键(key)”)是一种数据结构,作用是存储引擎用于快速找到记录。一个简单的类比就是,书籍的目录,我们通过目录去快速找到某一个章节的位置。
二、索引的结构
索引是在引擎层实现的。MySQL5.5以后默认使用InnoDB存储引擎,我们建表用的也都基本是InnoDB。
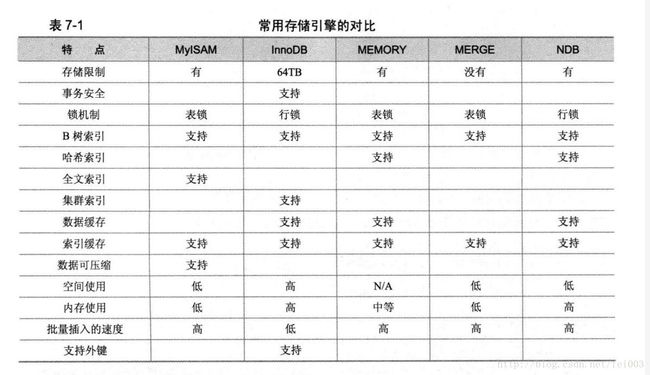
转载自 深入浅出mysql数据库
1:B-Tree
常用的是InnoDB引擎,它的索引结构是B+树,我们从B树说起。B树属于多叉树,又叫平衡多路查找树,是有多个查找路径的。
m阶B-Tree满足规则
(1)m阶的含义为,每个节点最多有m个查找路径,且m>=2,当m=2是时二叉树
(2)如果一个非叶节点有n个子节点,则该节点的关键字数等于n-1
(3)除了根节点外,每个节点的关键字数量为[ceil(m/2)-1,m-1](注ceil()是个向正无穷方向取整的函数,如ceil(1.2)=2)
(4)所有叶子都出现在同一层
(5)所有节点的关键字是按递增次数排列,并遵循左大右小原则
示例
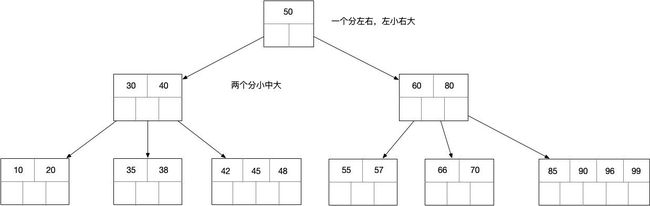
查询
(1)查询35,和根节点比较,小于,找到指向左边的子节点
(2)拿到关键字30和40,30<35<40,所以找到中间节点
(3)拿到35和38,因为35==35,直接但会关键字和指针信息,如果是查询36,返回null
插入
将55,57,66,60,70,85,80,90构建5路查找树
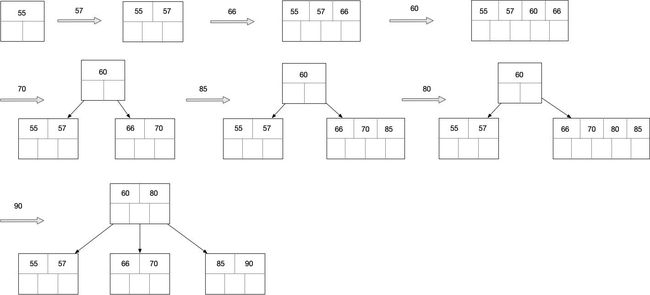
满足规则左小右大,当第一行到第二行时,当前节点已经满足五叉,所以再插入时要做节点的拆分,拆分规则是将中间的元素提出到父节点,左右各单独构成节点。第二行到第三行也是如此。
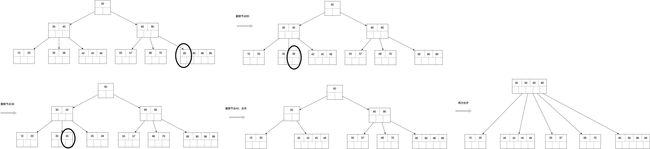
删除
此时结点最多有4个key,最少有2个key,少于2个key向兄弟节点借,能借到的话,父节点下沉,兄弟节点上移,借不到的话就合并
2:B+Tree
和B-Tree的不同点
(1)B+Tree叶子节点保存了父节点的所有关键字和关键字记录的指针,每个叶子节点的关键字从小到大链接
(2)内节点不存储data,只存储key;叶子节点不存储指针。因此所有数据地址必须要到叶子节点才能获取到,所以每次数据查询的次数都一样
示例

为什么B+树适合索引
(1)内部节点取消data部分,每一页可以容纳更多的数据,减少磁盘IO的次数
(2)数据全部存储在叶节点,所有的查找都是从根到叶,每一个数据的查询效率相当。B+树查询效率稳定,B树不固定,和位置有关
(3)通过增加顺序访问指针提高区间查询效率。
3:hash索引
用的相对较少,在memory引擎中支持,简单的介绍一下
hash索引基于哈希表键值对实现,哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。如果哈希码相同,索引会以链表的方式存放多个记录指针到一个哈希条目中。
优势是用于等值匹配。
三、索引的类别
1:聚集(聚簇)和非聚集索引
聚集索引是和数据存放的物理位置顺序相同的,例子:字典中的按拼音查找,拼音的顺序就是后面字的顺序,表中的聚集索引只能有一个,因为只有一种顺序
非聚集索引是和数据存放的物理位置顺序不同的,例子:字典的按笔画或偏旁查找,和后面字的顺序不同
2:唯一索引和主键索引
唯一索引列的值必须唯一,不允许重复,允许有空值,就是我们常用的UNIQUE KEY
主键索引是特殊的唯一索引,不允许有空值,就是我们常用的 PRIMARY KEY,在innodb引擎里面,主键就是聚集索引。
回表:如果通过主键索引去查找,它的叶子节点存的是整行的数据。通过非主键索引去查找,得到id的值,再去主键的索引在搜索一次,这个过程叫回表
3:全文索引
FULLTEXT索引用于全文搜索。只有InnoDB和 MyISAM存储引擎支持 FULLTEXT索引和仅适用于 CHAR, VARCHAR和 TEXT列。
4:组合索引
将几个索引组合使用,生效的条件是最左匹配原则,即最左优先,在检索数据时从组合索引的最左边开始匹配。
四、使用索引注意事项
参考和我们组做的慢SQL优化,得出以下注意事项
1:索引覆盖
查询的数据只要从索引中就能够获得,不用再从数据表中读取,即查询和条件中的所有的数据被所使用的索引覆盖,就是不需要回表了。MySQL只能用B-tree索引来做覆盖索引
2:组合索引顺序
在建立组合索引时,区分度大的列需要前置,减少后面的扫描行数。
3:索引的长度
对于很长字符列,可以索引开始的部分字符,这样可以大大节约索引空间,从而提高索引的效率。判断方法是增加长度区分度不明显上升
4:排序
当where语句中已经使用了索引的话,order by中的列不会使用索引,尽量减少使用排序操作,尽量不要包含多个列的排序,如果需要最好给这些列创建符合索引
5:影响
在优化索引时,不能只考虑一个sql的优化,需要全盘去考虑,要尽量的满足大部分的sql也能命中索引,避免索引浪费。
6:独立的列
查询条件不能是表达式或函数,会导致索引失效
五、执行计划简析
分析索引需要用到,在select语句之前加上explain extended关键字
![]()
几个关键的信息
1:key
显示MySQL实际用那个索引来查找,没有使用索引该列为null
2:rows
预计扫描的行数,可以和总行数对比,或者感觉太多,多半是有问题
3:extra
扩展信息
Using filesort:mysql 会对结果使用一个外部索引排序,而不是按索引次序从表里读取行。此时mysql会根据联接类型浏览所有符合条件的记录,并保存排序关键字和行指针,然后排序关键字并按顺序检索行信息。这种情况下一般也是要考虑使用索引来优化的。
Using temporary:mysql需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想到用索引来优化。