轻量级CNN网络高效设计准则-ShuffleNet v2学习记录
原文地址:
《ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design 》
ShuffleNetV2 是由国产旷视科技团队在 2018 年提出的,发表在了 ECCV。这篇文章非常硬核,实验非常全面。一些网络模型如MobileNet_v1, v2,ShuffleNet v1, Xception采用了分组卷积,深度可分离卷积等操作,这些操作在一定程度上大大减少了FLOPs,但FLOPs并不是一个直接衡量模型速度或者大小的指标,它只是通过理论上的计算量来衡量模型,然而在实际设备上,由于各种各样的优化计算操作,导致计算量并不能准确地衡量模型的速度
亮点:
- 计算量复杂度不能只看FLOPs指标;
- 提出了4条设计高效网络的准则(guidelines) ;
- 在shufflenet v1的block上提出了新的block设计。
1. 只用FLOPs存在的问题:
以往在移动端上的CNN设计在考虑计算节省时都直接致力于优化整体网络计算所需的FLOPs。但实际上一个网络模型的训练或推理过程FLOPs等计算只是其时间的一部分,其它像内存读写/外部数据IO操作等都会占不小比例的时间。为实际生产考虑,我们不应只限于去片面追求理论FLOPs的减少,更应该去看所设计的网络实际部署在不同类型芯片上时具有的实际时间消耗。
在ShuffleNet v2这篇paper中,作者们重点分析了影响在GPU/ARM两种平台上CNN网络计算性能的几个主要指标,并提出了一些移动端CNN网络设计的指导准则,最终将这些指导准则应用于ShuffleNet v1网络的改良就行成了ShuffleNet v2。在分类与目标检测等通用任务时与其它流利移动端网络相比,它都取得了不俗的性能。在500MFLOPs,ShuffleNet v2比MobileNet v2快58%,比ShuffleNet v1快63%,比Xception快25%。
目前的轻量级模型主要根据间接的指标FLOPs来设计,而直接的指标如速度(speed),在相同FLOPs的速度也会不一样。如下图中的(c)(d):

在 MobileNet,ShuffleNetV1中经常使用FLOPs,其是衡量模型运算或者复杂度的一个间接的指标,并不是直接的指标。在直接使用过程中我们都是通过 Speed 看推理速度。所以在影响模型推理速度的众多因素中间,我们不能光看 FLOPs,还要考虑其他因素例如内存访问时间成本 MAC (memory access cost)。此外,并行等级 degree of parallelism 也是需要考虑的。相同的 FLOPs 在不同的平台上计算时间也是不同的。
如下图:Conv等计算密集型操作占了其时间的绝大多数,但其它像Elemwise、Data IO、Shuffle等内存读写密集型操作也占了相当比例的时间,因此像以往那样一味以FLOPs来作为指导准则来设计CNN网络是不完备的。
将卷积部分认为是FLOPs操作。虽然这部分消耗的时间最多,但其他操作包括数据IO,数据混洗和逐元素操作(AddTensor,ReLU等)也占用了相当多的时间。(GPU 为一块 GeForce GTX 1080Ti,卷积库是CUDNN 7.0; ARM 结构为 高通骁龙 810 芯片)

作者观点:使用FLOPs作为计算复杂度的唯一指标是不充分的。
2.基本概念
什么是FLOPs?
FLOPS(S大写): 指每秒浮点运算次数,可以理解为计算的速度。是衡量硬件性能的一个指标。(硬件)
FLOPs(s小写) :指浮点运算数即网络中的乘法和加法操作的数量,理解为计算量。可以用来衡量算法/模型的复杂度。(模型) 在论文中常用GFLOPs(1 GFLOPs = 10^9 FLOPs)
轻量级架构设计速度与精度的权衡--组卷积与深度可分离卷积的使用
分组卷积 Group Convolution:
将feature map拆分成几组,分别进行卷积,最后再将卷积结果的feature map 合并. 最早在AlexNet中出现。因为当时GPU内存有限,逼迫将feature map拆分到两个GPU上分别卷积再融合。
深度卷积 Depth-wise convolution:
对每一个通道进行各自的卷积,输出相同的通道数,再用进行跨通道的标准1*1卷积来融合信息。
作用:极大减少了参数,但是速度(Speed)是直接指标,但不同设备不好比较, 故以往常用 FLOPs(乘或加的次数)来度量复杂度。但FLOP是一种间接指标,它不能直接作为评判的标准。
一些指标
MAC(内存访问成本)
计算机在进行计算时候要加载到缓存中,然后再计算,这个加载过程是需要时间的。其中,分组卷积(group convolution)是对MAC消耗比较多的操作。
并行度
在相同的FLOPs下,具有高并行度的模型可能比具有低并行度的另一个模型快得多。如果网络的并行度较高,那么速度就会有显著的提升。
计算平台
不同的运行平台,得到的FLOPs也不相同。有的平台会对操作进行优化,比如:cudnn加强了对3×3conv计算的优化。
通过以上的分析,作者认为高效网络架构的设计应该考虑两个基本原则:
- 使用直接度量方式如速度代替FLOPs。
- 要在目标计算平台上计算,不然结果不具有代表性。
3. 4条设计高效网络的准则
G1:输入与输出具有相同channel时内存消耗最小
对于空间大小为 h,w的特征图,输入和输出通道数分别为c1和c2,使用1x1卷积, 则FLOPs为B = h x w x c1 x c2。而MAC = hw(c1 + c2 ) + c1 x c2。这里hwc1为输入特征图内存访问成本,hwc2为输出特征图内存访问时间成本,c1xc2x1x1为卷积核内存访问时间成本。根据均值不等式,仅当c1=c2时,MAC取最小值。
实验证明如下图:c1与c2不同比率时在GPU和ARM上推理速度的差别,网络是由10个block堆叠组成,每个block包含2个1×1卷积层,第一个卷积层的输入输出通道分别是c1和c2,第二个卷积层相反(c2,c1)。4行结果分别表示不同的c1:c2比例,但是每种比例的FLOPs都是相同的。可以看出当c1和c2比例越接近时,速度越快,尤其是在c1:c2比例为1:1时速度最快。这与G1所提出的当c1和c2相等时MAC达到最小值相所对应。

G2:过多的分组卷积操作会增大MAC,从而使模型速度变慢
分组卷积在一方面,使得在相同FLOPs下,分组数越大,在通道上的密集卷积就会越稀疏,模型精度也会增加,在另一方面,更多的分组数导致MAC增加。使用分组卷积的FLOPs表达式为B=hwc1c2/g(参数量减少为原来的1/g)。 可以看出在B(FLOPs)不变时,当 Group Conv 的 groups 增大时,MAC 也会增大。

实验指出:g越小,速度越快。因此,作者建议应根据目标平台和任务仔细选择分组数。虽然组卷积能增加模型的准确度,但是作者认为盲目使用较大的分组数是不明智的,因为这将会使得计算成本增加,带来的缺点大于其准确度增加带来的优点。

G3:网络碎片化会降低并行化的程度
当网络设计的碎片化程度越高时,推理速度越慢。很多论文中设计的网络,分支特别多,例如 Inception,网络结构太复杂(分支和基本单元过多)会降低网络的并行程度,模型速度越慢。这里碎片化的程度可以理解为分支的程度,碎片(Fragmentation)是指多分支上,每条分支上的小卷积或pooling等(如外面的一次大的卷积操作,被拆分到每个分支上分别进行小的卷积操作)。这个分支可以是串联也可以是并联。虽然碎片化的结构可以提升准确率,但是会降低模型的效率。碎片化的结构对于 GPU 这种并行能力强的设备是很不友好的。并且在分支多的情况下还涉及 kernel 的起步和同步的问题。为了研究fragment对模型速度的影响,作者做了第三个实验。具体地,每个模型由block组成,每个block由1到卷积组成,分别将它们重复10次,得到的结果如右图表格所示,其中, 2-fragment-series表示一个block中有2个卷积层串行,也就是简单的叠加; 4-fragment-parallel表示一个block中有4个卷积层并行,类似Inception的整体设计。 可以看出在相同FLOPs的情况下,单卷积层(1-fragment)的速度最快。

实验证明,只有一条支路时,运行速度最快。因此,在网络结构中支路数可以提到精度,但也会降低运行速度,从而影响实时性。
G4:不可忽略元素级的操作
Element-wise包括Add/Relu/short-cut/depthwise convolution等操作。Element-wise操作在GPU上占的时间是相当多的,它们都有比较小的FLOPs,却有比较大的MAC。实验发现如果将ResNet中残差单元中的ReLU和shortcut移除的话,速度有20%的提升。

四点总结:
- G1卷积层使用相同的输入输出通道数。
- G2注意到使用大的分组数所带来的坏处。
- G3减少分支以及所包含的基本单元。
- G4减少Element-wise操作。
4. ShuffleNet v2的block结构
讨论其他网络:
- ShuffleNet-V1 严重依赖分组卷积,违背了G2。
- Bottleneck结构违背了G1;
- MobileNet-V2 采用了反转bottleneck(违背了G1),且用到了Depth-wise、以及在feature map上采用relu这些trick,违背了G4;
- 自动搜索生成的网络结构(如NasNet)有很高的碎片,违背了G3。
回顾ShuffleNet v1:
两个创新点:
- pointwise group convolution
- channel shuffle
原因:
- 逐点卷积占了很大的计算量———> PW Gconv
- 不同组之间特征通信问题 ———> channel shuffle

ShuffleNet v1存在的一些问题:
- PW Gconv增加了MAC违背了G2
- 瓶颈结构违背了G1与多分支违背了G3
- Add操作是元素级加法操作也不可取违反了G4



ShuffleNet v2的改进:
下图中a 和 b 分别对应ShuffleNetV1中stride=1和stride=2的情况,c和d分别对应ShuffleNetV2中 stride=1和stride=2的情况。针对c类型的block,首先对于每个block单元,将输入特征矩阵的通道c 拆分为两个分支c - c‘和c’,即对应着channel split。作者在论文中说了c ′=c/2。针对G3,我们减少碎片化程度,所以在左边分支不做事情,右边的分支三个卷积输入输出通道数都是一样的,满足了 G1。两个1×1卷积不再使用Group conv,这也是为了满足G2。 在卷积之后,两个分支是通过Concat进行通道拼接,这也就使得block前后通道数保持不变,也满足G1。然后在 block 中后进行channel shuffle。在c中不再有Add操作,ReLU和DW Conv也只在一个分支中存在(a 中 Add 之后的 ReLU 放到了 c 中最后一个 1 × 1卷积之后,处理的元素数目少了一半),尽可能减少了Element-wise 操作。然后最后的 Concat,Channel Shuffle 以及接下来的 Channel Split 其实可以合并为一次 Element-wise 操作,变相减少了 Element-wise 操作,符合 G4。针对 d 类型的 block,即下采样的情况,就没有了 channel split 操作,最后 Concat 之后输出特征矩阵的 channel 就翻倍了。并且将 b 中一个分支的 3 × 3平均池化变为了 3 × 3的 DW conv,本来平均池化就是分通道做的,并且可以看成是权重全是 1/9 的 DW Conv,这里换为了 DW Conv 增加了更多的可能。然后再新增了一个 1 × 1卷积。注意 DW 卷积之后是只有 BN 没有 ReLU 的。

channel split的作用:
第一,划分一半到右分支,意味着右边计算量减少,从而可以提高channel数,提高网络capacity。
第二,左分支相当于一种特征重用(feature reuse), 跟DenseNet和CondenseNet一样的思想。
下图(a)为DenseNet的从source layer到target layer连接的权重的大小,可见target层前1-3层的信息对当前层帮助较大,而越远的连接比较多余。图(b)为ShuffleNet v2的情况,因为shuffle操作会导致每次会有一半的channel到下一层。因此,作者认为shufflenet跟densenet一样的利用到了feature reuse,所以有效。

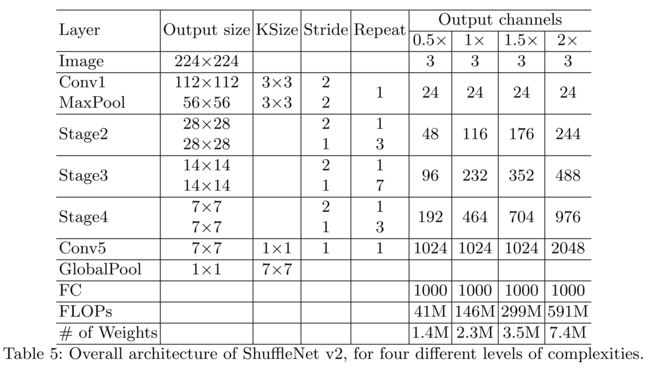
5. ShuffleNet v2的网络结构
ShuffleNetV2 和 ShuffleNetV1 框架基本都是一样的,唯一的不同在于多了一个 Conv5 这个 1 × 1 卷积层。对于每个 stage 的第一个 block,stride 都是 2 ,输出 channel 是需要进行翻倍的。此外对于 stage2 的第一个 block,他的两个分支中输出的 channel 并不等于输入的 channel,而是直接设置为指定输出 channel 的一半,比如对于 1x 版本,每个分支的 channel 应该是 58 而不是 24。
为什么要加conv5呢?炼丹,不加准确率保证不了,不然比起v1版本减去那么多的 groups,速度是上去了准确率是万万不能下去的,怎么办呢?再加一层卷积试试吧。
实验对比: FLOPs 差不多,但是 ShuffleNetV2 的正确率和速度都很不错。

ShuffleNet-V2 不仅高效,还高精度。论文中指出导致的原因有:
- 每个构建块都很高效,从而能利用更多的feature maps 和 更大的网络容量
- 特征重用(feature reuse)
- 因为通道分割,从而有一半的特征直接传到下一个模块中。
- 这和DenseNet 以及CondenseNet 思想相近。
- DenseNet分析feature reuse模式发现,越相近的模块,它们的传来的shortcut特征的重要性越大。 CondenseNet也支持类似的观点。
- ShuffleNet-V2也是符合这样的观点,特征重用信息随着两个模块间的距离呈指数衰减。
G1准则(相同通道宽度)从VGG、Resnet后大家几乎都默认遵循了, 而G2准则(组卷积问题)很多网络在违背着。主要是组卷积能够提高准确率,但很有意思的是,用了组卷积速度会慢很多,
而组卷积为什么会变好? “Alex认为group conv的方式能够增加filter之间的对角相关性,而且能够减少训练参数,不容易过拟合,这类似于正则的效果。”
至于G3准则(碎片操作),文中主要还是对 自主搜索网络结构 方面的工作(如NasNet 进行批判)。这或许可以在自主搜索网络结构方面加上相应的损失函数,从而让搜索出的网络结构除了高准确率外,还具备高效的能力。
违背G4准则(Element-wise操作)是必不可免的。毕竟基于优秀网络上的改进,很多是增加一些Element-wise操作,从而获得准确率的提升。 但ShuffleNetV2告诉了我们,Element-wise操作可以简化(如relu的移位)。
且如果让网络变得精简的话,这可能会让网络获得意想不到的提升,比如WRN就打败了很多花里胡哨。
论文还提到特征重用(Feature reuse), 用上了特征重用的方法后效果会提升(Densenet、DPN、残差金字塔之类等等)。之后需要多了解这方面的论文和方法。
参考文献:
轻量级神经网络:ShuffleNetV2解读
[论文总结] ShuffleNet V2
深度学习之图像分类(十四)--ShuffleNetV2 网络结构
仅为学习记录,侵删!