FixMiner:挖掘相关的修复模式以实现自动程序修复
FixMiner:挖掘相关的修复模式以实现自动程序修复–翻译记录
Anil Koyuncu1·Kui Liu1·Tegawendé F. Bissyandé1·Dongsun Kim2·
Jacques Klein1·Martin Monperrus3·Yves Le Traon1
Springer Science+Business Media, LLC, part of Springer Nature 2020
摘要
打补丁是软件开发中的常见活动。它通常在源代码基础上执行,以解决bug或添加新功能。在这种情况下,如果bug在项目之间反复出现,可以利用相关的类似补丁来提取通用的修复操作。虽然文献包括利用补丁之间的相似性来指导程序修复的各种方法,但这些方法通常不能产生可处理和可重用的修复模式,作为APR系统的可操作输入。在本文中,我们提出了一种系统的、自动化的方法来挖掘相关的、可操作的修复模式,该方法基于应用于补丁内部原子变化的迭代聚类策略。FixMiner的目标是推断独立的、可重用的补丁模式,这些模式可以在其他补丁生成系统中使用。我们的技术FixMiner利用了Rich Edit Script,这是一种专门的编辑脚本树结构,它捕获了代码更改的ast级上下文。FixMiner对每一轮集群使用Rich Edit Scripts的不同树表示来识别类似的更改。它们是抽象语法树、编辑操作树和代码上下文树。我们已经对从开源项目中收集的数千个软件补丁进行了FixMiner的评估。初步结果表明,我们能够挖掘准确的模式,有效地利用富编辑脚本中的变化信息。我们进一步将挖掘的模式集成到一个自动程序修复原型PARFixMiner中,通过它,我们能够正确地修复Defects4J基准测试的26个bug。除了这一量化性能,我们还表明挖掘的修复模式能够产生具有高概率正确性的补丁:81%的PARFixMiner生成的似是而非的补丁是正确的。
关键词:修复模式·补丁·程序修复·调试·经验软件工程
1.介绍
代码更改模式在软件工程领域有多种用途。它们主要用于标记变化(Pan et al.2009)、对开发者提交的事项进行分类(Tian et al. 2012)或预测变化(Ying et al.2004)。近年来,修复模式在软件维护社区中得到了很大的利用,尤其是在构建补丁生成系统方面,这现在吸引了越来越多的兴趣(Monperrus2018)。自动程序修复(APR)确实获得了令人难以置信的势头,并采用了各种各样的方法(Nguyen et al.2013;是2009年1月;L e G u e s e t L .2012a;Kim等人2013;科克和Hafiz2013;2015年;Mechtaev et al.2015;Long和Rinard2015, 2016;L e e a L 2016a b,2017;C h e e t l .2017;长et al.2017;X u a n e t a l .2017;熊等al.2017;江等al.2018;温等al.2018;华等al.2018;Liu等人2019,b)提出,旨在通过自动生成补丁来减少人工调试工作量。自动程序修复中常见且可靠的策略是根据修复模式(Kim et al.2013)(也称为修复模板(Liu and Zhong2018)或程序转换模式(Hua et al.2018)生成具体的补丁。几个APR系统(Kim et al.2013;这是一个时间,2017;Durieux et al.2017;刘和Zhong2018;H u a等。2018;马丁内斯和Monperrus2018;Liu等人2019,b)在文献中,通过使用通过手工生成或自动挖掘bug修复数据集获得的各种修复模式集来实现这一策略。
在PAR (Kim et .2013)中,作者通过手工检查60,000个开发者补丁来挖掘修复模式。类似地,对于Relifix (Tan和Roychoudhury2015),需要对73个真实的软件回归bug修复进行手动检查,以推断修复模式。然而,手动挖掘是乏味的,容易出错,而且无法扩展。因此,为了克服手动模式推断的局限性,几个研究小组已经开始了自动推断bug修复模式的研究。在Genesis (Long et .2017)中,Longet提出了一种用于补丁生成的自动推断代码转换的方法。创世纪从577个采样转换的空间中推断出108个带有特定代码上下文的代码转换。然而,这项工作将搜索空间限制在以前成功的补丁中,这些补丁只有Java程序的三类缺陷:空指针、越界和与类强制转换相关的缺陷。
Liu和Zhong (Liu and Zhong2018)从Stack Overflow的Q&A文章中提出了SOFix来探索Java程序的修复模式,它基于GumTree (Falleri et al.2014)编辑脚本挖掘模式,并基于修复模式同构构建不同的类别。然后SOFix从每个类别挖掘一个修复模式。然而,作者指出,大多数类别都是多余的,甚至是不相关的,主要是由于两个主要问题:(1)相当一部分代码示例的设计目的不是修复bug;(2)由于底层的GumTree工具依赖于结构位置来提取修改,这些“修改不能呈现理想的语义映射”。他们依靠启发式来手动过滤类别(例如,包含多个修改的类别),然后在SOFIX挖掘修复模式之后,他们必须手动选择有用的模式(例如,由于语义相似而合并一些修复模式)。
Liu et al. (2018a)和Rolim et al.(2018)分别提出从FindBugs和PMD的静态分析违规中挖掘修复模式。这两种方法在推理过程中都利用了类似的方法。Rolim等(2018)依赖于编辑脚本之间的距离:它们之间距离较低的编辑脚本根据定义的相似度阈值分组在一起。另一方面,Liu et al. (2018a)利用深度学习来学习编辑脚本的特征,寻找相似的编辑脚本集群。最终,经验软件工程(2020)25:20 80 - 20241981这两个作品都没有在他们的编辑脚本中考虑代码上下文,而是手动地从补丁的类似编辑脚本的集群中得出修复模式。
另一方面,CapGen (Wen et al.2018)和SimFix (Jiang et al.2018)提出使用代码变更动作的频率。前者用它来驱动补丁选择,后者用它来计算捐助方代码相似度来确定补丁的优先级。然而,在这两种情况下,模式的概念都不是可操作的工件,而是指导补丁生成系统的补充信息。虽然我们同时与SimFix和CapGen共享为补丁生成添加更多上下文信息的想法,但我们的目标是推断出可操作的补丁模式,这些模式是可处理和可重用的,可以作为其他APR系统的输入。
表1概述了在文献中实现的各种自动挖掘策略,以获得不同的修复模式集。一些策略直接作为APR系统的一部分呈现,而其他的是独立的方法。我们通过考虑差异表示格式、上下文信息的使用、模式的可跟踪性(即,在补丁生成系统中它们在多大程度上是独立的和可重用的组件)和挖掘的范围(即,范围是否限于特定的代码更改)来描述不同的策略。总的来说,虽然文献方法可以方便地发现不同的修复模式集,但实际情况是,修复模式的复杂性和挖掘策略的泛化性仍然是为程序修复导出相关模式的一个挑战。
本文:我们建议研究挖掘相关的修复模式的可行性,这些修复模式可以很容易地集成到一个基于模式的自动程序修复系统中。为此,我们提出了一种迭代的、三重的集群策略FixMiner,以自动地从实际开发人员修复中的原子更改中发现相关的修复模式。FixMiner是一种模式挖掘方法,用于为程序修复系统生成修复模式。我们在本文中提出了富编辑脚本的概念,它是编辑脚本的一种专门的树状数据结构,用于捕获代码更改的ast级上下文。为了推断模式,FixMiner利用相同的树,这些树是基于rich Edit scripts为每一轮迭代编码的以下信息计算的:抽象语法树、编辑操作树和代码上下文树。
贡献:我们建议FixMiner模式挖掘工具作为一个独立的、可重用的组件,可以在其他补丁生成系统中使用。
论文内容:我们的贡献是:
-我们介绍了模式推理系统FixMiner的架构,它建立在三次聚类策略的基础上,在该策略中,我们迭代地发现基于不同树表示编码上下文、更改操作和代码标记的类似更改。
-我们通过在43个开源项目的11416个补丁中挖掘修复模式来评估fixminera发现模式的能力。我们进一步将发现的模式与那些可以在程序修复社区使用的数据集中找到的模式联系起来(Just et .2014)。我们评估了FixMiner模式与文献中的模式的兼容性。
-最后,我们通过将其作为自动程序修复系统的一部分来调查挖掘的修复模式的相关性。我们在Defects4J基准测试上的实验结果表明,我们挖掘的模式可以有效地修复26个错误。我们发现FixMiner模式是相关的,因为它们可以生成大部分是正确的补丁。
2.动机
近年来,挖掘、枚举和理解代码更改已经成为软件维护的一个关键挑战。十年前,Pan等人手工编制了一个与bug修复相关的27种代码变更模式的目录(Pan et al.2009)。然而,这样的“bug修复模式”是通用模式(例如,If - rmv:删除If谓词),它代表了经常修复bug的变更类型。最近,由于新的AST差异工具的可用性,研究人员提出了自动挖掘变化模式(Martinez等。2013;奥斯曼等al.2014;Oumarou et al.2015;Lin et al. 2016)。这些模式主要用于分析和理解bug修复的特征。然而,在实践中,推断的模式可能被证明是不相关的和难以处理的。
然而,我们认为挖掘修复模式可以帮助指导补丁生成的突变操作。在这种情况下,需要挖掘可以附加修复语义的真正周期性的更改模式,并提供在实践中可操作的准确的、细粒度的模式,即分离并作为其他流程的输入进行重用。我们的直觉是,相关模式无法在全球范围内挖掘,因为在野外修复的bug由于复杂的变化而受制于嘈杂的细节(Herzig和Zeller2013)。因此,需要将补丁分解为原子单元(连续的代码行形成一个块),并解释代码更改在它们之间的递归性。为了挖掘变化,我们建议依赖于编辑脚本格式,它提供了代码变化的细粒度表示,其中包括不同层次的信息:
-上下文,即被更改的代码元素的AST节点类型(例如,声明语句中的修饰符,不应推广到其他类型的语句);
-变更操作(例如,“先删除再添加”的顺序不应与“先添加再删除”的顺序混淆,因为它在AST等层次模型中可能有不同的含义);
-和代码标记(例如,将调用更改为“Log”。不应该与任何其他API方法相混淆)。我们的想法是迭代地找到上下文中的模式,每个上下文中的更改操作模式,以及这些操作中经常受到影响的文字的模式。我们现在提供背景信息来理解FixMiner的执行以及FixMiner所处理的信息。
2.1 抽象语法树
代码表示是程序分析和验证的重要步骤。抽象语法树(Abstract syntax trees, ast)通常是为程序分析和转换而产生的,它是一种数据结构,提供了一种表示程序结构的有效形式,以便进行语法甚至语义方面的推理。AST的确代表了所有的语法元素的编程语言和关注的规则而不是元素(如括号或分号终止语句在一些流行的语言比如Java或c AST是元素的层次表示递归地分解成每个编程语句他们的部分。因此,树中的每个节点表示在编程语言中出现的一个构造。
形式上,设t为AST, N为t中AST节点的集合。一个AST t有一个根,该根是root(t)∈N的节点。每个节点n∈n(和n?=root (t))有一个亲本,记为parent(n)=p∈n。注意,没有root(t)的父节点。此外,每个节点n有一组子节点(记为children(n)⊂n)。一个标签l(即。, AST节点类型)从一个给定的字母L分配给每个节点(label(n)= L∈L)。最后,每个节点都有一个字符串值v(令牌(n)=v,其中n∈n, v是一个任意字符串),表示相应的原始代码令牌。**考虑图1中Java代码的图2中的AST表示。**我们注意了AST节点与标签匹配的Java语言的结构元素(如MethodDeclaration, IfStatement orStringLiteral),可以与值代表原始标记的代码(例如,一个节点labelledStringLiteralfrom AST相关价值“嗨!”)(图2)。


2.2 代码差分
区分一个程序的两个版本是所有软件演化研究的关键预处理步骤。必须以一种使开发人员易于理解或分析变更的方式捕获演化的部分。开发人员通常能很好地处理基于文本的差异工具**,比如如图3所示的GNU Diff表示添加和删除源代码行的更改。**这种基于文本的差异的主要问题是,它没有提供更改的细粒度表示(即StringLiteral Replacement),因此不适合系统地分析更改。

为了解决代码差异的挑战,最近提出了基于树结构(如AST)的算法。ChangeDistiller和GumTree就是这种算法的例子,它们生成编辑脚本,这些脚本详细描述了要在给定AST的节点上执行的操作(如第2.1节所述),从而生成与新版本代码相对应的另一个AST。特别地,在此工作中,我们基于GumTree的核心算法来准备编辑脚本。编辑脚本是描述以下代码更改操作的编辑操作序列:
-UPDwhere an upd (n, v)action通过将AST节点的旧值替换为新值ev来转换AST。
-INSwhere an ins(n, np,i,l,v)动作插入一个新的节点值和las标签。如果指定了parentnpi,则nis作为np的子节点插入,否则将是根节点。
-DELwhere a del(n)动作从树上移除叶子节点。
-MOV where a mov(n, np,i)动作移动有节点根的子树,使其成为父节点的子树。
编辑操作,嵌入关于节点(即解析程序的整个AST树中的相关节点)、操作符(即UPD、INS、DEL、n dMOV)的信息,描述所执行的操作,以及在更改中涉及的原始标记。
2.3 混乱的代码更改
每个补丁解决一个问题通常被认为是促进维护任务的最佳实践。然而,现实项目中的补丁经常在一个补丁中解决多个问题(Tao和Kim2015;Koyuncu et al.2017)。开发人员经常提交bug修复代码更改,同时提交与修复无关的更改,如功能增强、特性请求、重构或文档。这种补丁被称为纠结补丁(Herzig和Zeller2013)或混合用途的修复提交(Nguyen et .2013)。Nguyen等人发现,用于挖掘档案的所有固定提交中有11%到39%是纠结的(Nguyen et al.2013)。
考虑图4中所示的来自GWT的示例补丁。这个补丁的目的是修复当页面以某种mime类型(例如,application/xhtml+xml)服务时,在某些web浏览器中报告了一个失败的问题。开发人员通过在遇到此类mime类型时显示警告来修复这个问题。然而,除了这个更改之外,提交中还解决了一个打字错误。由于打字错误与修复无关,因此修复提交会出现混乱。因此,在提交时需要单独考虑单个代码块允许模式推断集中于寻找与错误修复操作相关的周期性原子更改。

3.方法
fixminer旨在从软件存储库中的bug修复补丁中的原子更改中发现相关的修复模式。为此,我们挖掘类似所涉及的上下文、操作和编程令牌的代码更改。图5展示了FixMiner方法的概述。
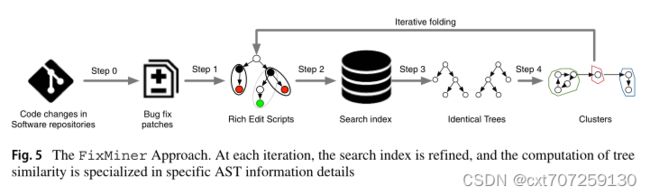
3.1 综述
在步骤0中,作为初始步骤,我们从项目变更跟踪系统中收集相关的bug修复补丁(参见定义1)。然后,在第1步中,我们计算一个Rich Edit Script表示(参见第3.3节),以描述根据上下文、执行的操作和涉及的标记的代码更改。因此,我们考虑富编辑脚本(cf。定义2)携带的信息要么是受影响的AST节点类型,要么是执行的修复操作,要么是受影响的程序标记。FixMiner以迭代的方式工作,在每次模式挖掘迭代中考虑单个专门的树表示,以发现相似的变化:首先,识别**影响相同代码上下文的变化(即在相同的抽象语法树上);**然后在这些确定的更改中,使用相同操作(即相同的操作序列)的更改被重新分组;最后,在每个组中,会挖掘影响相同令牌集的更改。因此,在FixMiner中,我们执行了一个三重策略,在模式挖掘迭代中执行以下步骤:
-步骤2:我们建立一个搜索索引(参见定义3)来识别必须进行比较的富编辑脚本。
-步骤3:我们通过计算富编辑脚本的两个表示之间的距离来检测相同的树(参见定义4)。
-步骤4:我们将相同的树重组成簇(参见定义5)。
最初的模式挖掘迭代使用在步骤1中计算的Rich Edit Scripts作为输入,接下来的轮使用在步骤4中产生的相同树的集群作为输入。
在接下来的章节中,我们将介绍步骤1-4的细节,考虑到一个bug修复补丁的数据集是可用的。
3.2 步骤0 -补丁收集
定义1(补丁)一个程序补丁是一个程序到另一个程序的转换,通常是为了修复一个缺陷。设P是一组程序,一个补丁用一对(P, P ?)表示,其中P, P ?∈P分别为应用补丁前和应用补丁后的程序。具体地说,补丁实现了源代码文件中代码块的更改。
为了识别软件库项目中的bug修复补丁,我们建立在Jira问题跟踪软件中实现的bug链接策略之上。我们使用了类似于Fischer等人(2003)和Thomas等人(2013)提出的方法,以便将提交链接到相关的bug报告。具体来说,我们抓取给定项目的bug报告,并使用两步搜索策略来评估链接:(1)我们检查项目提交日志来识别bug报告id,并将相应的bug报告与提交相关联;然后(ii)我们检查那些确实被认为是这样的错误报告(例如,标记为“bug”),并且被进一步标记为已解决(例如,标记为“RESOL VED”或“FIXED”),并完成(例如,状态为“CLOSED”)。
通过考虑通过一次提交修复的bug报告,我们进一步管理补丁集。这提供了更多的保证,即所选择的提交确实可以一次性修复错误(即,错误不需要补充补丁(Park et al.2012))。最终,我们只考虑对源代码文件所做的更改:对配置、文档或测试文件的更改被排除在外。
3.3 步骤1 -Rich Edit Script计算
定义2(Rich Edit Script) A Rich Edit Script r∈RE表示一个补丁作为一个专门的变化树。这棵树描述了在补丁应用之前与代码块关联的给定AST上进行哪些操作,以将其转换为另一个AST,与补丁应用之后的代码块关联:即r:P→P。树中的每个节点都是受补丁影响的AST节点。rich Edit Script中的每个节点都有三种不同类型的信息:Shape、Action和Token。
在开源变更跟踪系统中收集的bug修复补丁根据添加和删除源代码行以GNU diff格式表示,如图6所示。这种表示方式不适用于更改的细粒度分析。

为了准确地反映已经执行的变化,已经提出了几种基于树结构的算法(如AST) (bile2005;鲍里克和Augsten2011;Chawathe et al.1996;桥本Mori2008;Duley et al.2012;Fluri et al.2007;Falleri et al.2014)。ChangeDistiller (Fluri et al.2007)和GumTree (Falleri et al.2014)等先进的例子饮片算法产生编辑脚本,详细的操作的节点上执行一个给定的AST为了产生另一个AST对应于新版本的代码。特别地,在这项工作中,我们选择了GumTree AST差异工具,最近在计算编辑脚本的文献中看到了势头。据称,GumTree以一种快速、可伸缩和准确的方式构建给定补丁的两个相关AST表示(bug和修复版本)之间的AST编辑操作序列(又称编辑脚本)。
考虑如图7所示的由GumTree为Defects4J的Closure-93 bug补丁计算的编辑脚本示例。这个补丁的预期行为是修复由于java.lang.String对象的错误方法引用(lastIndexOf而不是indexOf)而导致indexOfDot的错误变量声明。GumTree编辑脚本将更改总结为对AST节点简单名称(即非关键字的标识符)的更新操作,该操作修改了标识符标签(从indexOf到lastIndexOf)。

尽管GumTree编辑脚本在细粒度的层面上准确地描述了bug修复操作,但是很多描述补丁预期行为的上下文信息都缺失了。信息方法调用,方法名(以),变量声明的片段,将方法调用的值赋给indexOfDot,以及类型信息(int indexOfDot - c f。图7)这是隐含在变量声明语句都失踪GumTree编辑脚本。由于上下文信息丢失,生成的编辑脚本无法传达代码更改的完整语法和语义含义。
为了解决这个限制,我们建议通过保留更多上下文信息来丰富gumtree生成的编辑脚本。为此,我们构造了编辑脚本的专门树结构,它捕获了代码更改的ast级上下文。我们将这种特殊的树结构称为rich Edit Script。一个丰富的编辑脚本计算如下:
给定一个补丁,我们首先使用GumTree计算一组编辑操作(编辑脚本),该集合包含由补丁更改的每一组连续代码行(块)的编辑操作。为了捕获更改的上下文,我们在新的AST(最小)子树下重新组织编辑操作,构建AST层次结构。对于编辑脚本中的每个编辑操作,我们从原始AST树中提取一个最小子树,它以GumTree编辑操作作为叶节点,并以以下预定义节点类型之一作为根节点:TypeDeclaration, FieldDeclaration, MethodDeclaration, SwitchCase, CatchClause, ConstructorInvocation, SuperConstructorInvocation或任何Statement节点。其目的是将上下文的范围限制在包含语句中,而不是回溯到编译单元(参见图2)。我们限制父遍历的范围主要有两个原因:第一,模式挖掘必须关注与更改相关的程序上下文;第二,程序修复方法(FixMiner就是为这些方法而构建的),通常目标是语句级的故障定位和补丁生成。
考虑图8所示的AST差异树。从这个差异树中,GumTree生成编辑操作的叶节点(灰色)作为最终的编辑脚本。要构建rich Edit Script,我们遵循以下步骤:
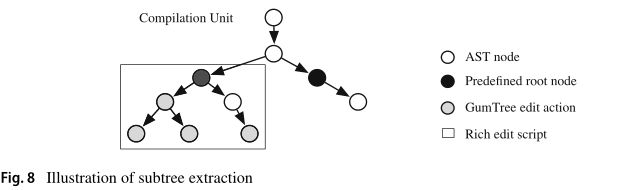
i)对于每个gumtree生成的编辑动作,我们将其重新映射到程序AST中的相关节点;
ii)然后,从gumtree编辑动作节点开始,从下到上遍历解析程序的AST树,直到到达预定义的根nodetype节点。
iii)对于到达的每个预定义的根节点,我们从发现的预定义根节点之间提取AST子树,向下到映射到gumtree编辑操作的叶子节点。
iv)最后,我们将这些提取出来的AST子树创建一个有序序列,并将其存储为rich Edit Script
具体地说,对于我们的运行例子,考虑如图6所示的Closure-93的情况。富编辑脚本的构建首先是生成补丁的GumTree编辑脚本(见图7)。patch由单个块组成,因此我们希望提取单个AST子树,如图9所示。为了提取这个AST子树,首先,我们在AST的4号位置标识编辑操作“SimpleName”的节点

然后,从这个节点开始,向后遍历AST树,直到到达位于第1位置的节点“VariableDeclarationStatement”。我们提取AST子树,通过创建一个新树,将“VariableDeclarationStatement”设置为新树的根节点,并在位置2、3处添加中间节点,直到我们到达编辑操作“UPD SimpleName”在位置4处的对应节点。我们创建一个序列,并将提取的AST子树添加到该序列中。
富编辑脚本是树形数据结构。它们被用来表示变化。为了为其他APR系统提供可处理和可重用的模式作为输入,我们基于控制正确的Rich Edit Script形成的语法规则定义了以下字符串表示法(参见语法1)。

图10显示了计算的Rich Edit Script。第一行表示根节点(没有虚线)。“UPD”表示节点的操作类型,VariableDeclarationStatement对应ast节点的节点类型,令牌之间“@@”和“@TO@”包含相应的代码标记在改变之前,而令牌之间“@TO@”和“@A T”对应于新代码标记的变化。三条虚线(- - -)表示一个子节点。直接子节点包含三个破折号,而它们的子节点添加另外三个破折号(- - - - - -),以保持父子关系。

编辑操作节点携带以下三种类型的信息:AST节点类型(Shape)、修复操作(action)、补丁中的原始令牌(Token)。对于这三种信息类型中的每一种,我们分别从Rich Edit Script创建树表示,分别命名为ShapeTree、ActionTree和TokenTree,每一种都携带分别由其名称表示的信息类型。图11、12和13分别显示了为Closure-93生成的ShapeTree、ActionTree和TokenTree。



3.4 步骤2 -搜索索引构建
定义3(搜索索引)为了减少匹配相似补丁的努力,使用搜索索引(SI)来限制比较空间。每个折叠fold({Shape,Action,Token})分别定义了一个搜索索引:SIShape,SIAction和SIToken。每个都被定义为SI∗:Q∗→2RE,它是一个特定于每个折叠的查询集,并且∗∈{Shape, Action, Token}.
假设Rich Edit Scripts是为一个补丁中的每个块计算的,那么它们就分布在不同的补丁中。对这些富编辑脚本进行直接的两两比较会导致比较空间的组合爆炸。为了减少比较空间,并能够快速识别Rich Edit Scripts进行比较,我们构建了搜索索引。搜索索引是一组比较子空间,它是通过将Rich Edit Scripts与标准进行分组而创建的,这些标准依赖于为不同迭代所使用的树表示(Shape、Action、Token)所嵌入的信息。搜索索引构建如下:
“Shape”搜索索引。构造过程将第1步生成的rich Edit scripts的ShapeTree表示作为输入,并根据AST节点类型对它们的树结构进行分组。具体来说,具有相同根节点(例如,IfStatement, MethodDeclaration, ReturnStatement)和相同深度的富编辑脚本被分组在一起。对于每个组,我们通过列举组成员的成对组合来创建一个比较空间。最终,“Shape”搜索索引是通过存储每个组的标识符(表示为根节点/深度(例如,IfStatement/2, IfStatement/3, MethodDeclaration/4)和一个指向其比较空间(即其成员的成对组合)的指针来构建的。
“Action”搜索索引。构建过程遵循与“Shape”搜索索引相同的原则,不同之处是重组基于ShapeTrees的聚类输出。因此,输入由富编辑脚本的ActionTree表示形成,每个比较空间的组标识符生成为node/depth/ShapeTreeClusterId(例如,其中ShapeTreeClusterId表示基于ShapeTree信息生成的集群的id(步骤3-4)。具体来说,这意味着“Action”搜索索引建立在具有相同形状的树组上。
“Token”搜索索引。构造过程遵循与“Action”搜索索引相同的原则,使用ActionTrees的聚类输出。因此,输入由rich Edit Scripts的TokenTree表示形成,每个比较空间的组标识符生成为node/depth/Shape TreeClusterId/ActionTreeClusterId(例如,其中ActionTreeClusterId表示根据ActionTree信息生成的集群id(步骤3-4)。
3.5 第三步-树比较
定义4(一对相同的树)设a=(ri,rj)∈Ridentical是一对Rich Edit Script专用树表示,如果d(ri,rj)=0,其中ri,rj∈RE, d是距离函数。Ridentical是RE×RE的一个子集。
树比较的目的是为给定的折叠找到Rich Edit Scripts的相同树表示。有几种直接的方法可以检查两个富编辑脚本是否相同。例如,可以使用语法相等。然而,我们的目标是使FixMiner成为一个灵活和可扩展的框架,未来的研究可以对定义类似树的阈值进行调优。因此,我们提出了一种比较Rich Edit Scripts的通用方法,考虑到每种专门树表示的信息多样性。为此,我们分别计算富编辑脚本的三种表示形式的树编辑距离。树编辑距离定义为将一棵树转换为另一棵树的编辑操作序列。当编辑距离为零时(即不需要将一棵树转换为另一棵树的操作),树被认为是相同的。在算法1中,我们定义了比较富编辑脚本的步骤。
该算法首先从折叠对应的搜索索引SI中检索标识符。标识符是指向比较子空间的指针,该子空间包含用于比较的Rich Edit Scripts的树表示的成对组合(参见第3.4节)。具体地说,我们从缓存中恢复给定pair的Rich Edit Scripts,以及它们对应的专门的根据折叠的树表示:在第一次迭代中,我们只考虑表示为ShapeTrees的树,而在第二次迭代中,我们关注于ActionTrees,在第三次迭代中,我们关注tokenentrees。我们用两种不同的方法计算恢复树之间的编辑距离。

-在前两个迭代(即,Shape和Action)中,我们再次利用了GumTree的编辑脚本算法(Falleri,第3节)。我们通过简单地在恢复树上调用GumTree作为输入来计算编辑距离,因为rich edit Scripts确实是AST子树,与GumTree兼容。具体地说,GumTree将两个AST树作为输入,并生成一个编辑操作序列(也就是编辑脚本),将一个树转换为另一个树,其中编辑脚本的大小表示两棵树之间的编辑距离。
-对于第三次迭代(即Token),由于树中的相关信息是文本,我们使用了文本距离算法(Jaro-Winkler (Jaro1989;Winkler1990)计算从树中提取的两个标记之间的编辑距离。我们使用了对Apache Commons Text library4的Jaro-Winkler编辑距离的实现,它计算了两个字符串dw的Jaro-Winkler编辑距离,如方程1中定义的那样。该方程由两部分组成;Jaro的原始算法(jsim)和Winkler的扩展(wsim)。Jaro相似度是每个文件中匹配字符c和转置字符t的百分比的加权和。Winkler增加了匹配初始字符的度量,通过使用前缀比例p(默认设置为0.1),这为从开始匹配的字符串提供了更有利的评级,设置了前缀长度l。该算法产生的相似度评分(wsim)在0.0到1.0之间,其中0.0是最不可能的,1.0是正匹配。最后,将相似性得分转换为距离(dw)。

作为比较的最后一步,我们检查两树的编辑距离和标记的双零对相同的距离,因为距离零意味着不需要操作将一棵树到另一个地方,或第三折(k e n)树中的令牌都是一样的。最后,我们存储并保存在每次迭代中产生的一组相同树对,这将在步骤4中使用。
3.6 第四步-模式推断
定义5(Pattern)设g是一个图,其中节点是RE的元素,边由Ridentical定义。
g由一组连通子图SG(例如,富编辑脚本的专门树表示的集群)组成,其中sgi和sgj是不相交的∀sgi, sgj∈SG。如果sgi∈SG至少有两个节点(即存在循环树),则sgi定义一个模式。
最后,为了推断模式,我们求助于Rich Edit Scripts的专门树表示的聚类。首先,我们首先检索在步骤3中为每次迭代生成的一组相同树对。根据算法2,我们根据折叠(例如,ShapeTrees, ActionTrees, tokenentrees)提取相应的专门的树表示,因为这些树只在一个给定的折叠中是相同的。为了找到一组彼此相同的树(即集群),我们利用图。具体地说,我们在图中实现了一个基于连通分量(即子图)识别理论的聚类过程(Skiena1997)。我们从树对列表中创建一个无向图,其中图的节点是树,而边表示相关的树(即相同的树对)。从这个图中,我们将集群识别为子图,其中每个子图包含一组树,这些树彼此之间是相同的,但与其他图是不相交的。
一个集群包含一个Rich Edit Scripts列表,该列表根据折叠共享一个公共的专门的树表示。最后,当一个集群至少有两个成员时,它被限定为模式。

每个折叠的模式定义如下:
Shape patterns
第一个迭代尝试在与开发人员补丁相关的ShapeTrees中找到模式。我们将它们称为形状模式,因为它们代表了根据节点类型在树结构中更改代码的形状。因此,它们本身不是固定模式,而是反复发生更改的上下文。
Action patterns
第二个迭代考虑与每个形状模式相关的样本,并试图从它们的actiontree中识别重复出现的修复操作。此步骤产生与程序修复相关的模式,因为它们引用了重复的代码更改操作。这种模式确实可以与文献中进行的解剖研究相匹配(Sobreira et al.2018)。我们将行动模式称为寻求的修复模式。尽管如此,值得注意的是,与可以一般应用于任何匹配代码上下文的文献修复模式相比,我们的Action模式是专门映射到代码形状(即形状模式)的,因此适用于特定的代码上下文。这将把突变限制在相关的代码上下文中,从而产生更可能的精确修复操作。
Token patterns
第三次迭代最终考虑与每个操作模式相关的示例,并试图识别与可用标记相关的更具体的模式。这种特定于标记的模式,包括特定的标记,不适合在文献中基于模式的自动程序修复系统中实现。然而,我们讨论了它们在派生附属进化的背景下的使用(参见第5.2节)。
4.实验评价
现在,我们将详细介绍我们为FixMiner所做的实验。值得注意的是,我们讨论了数据集,并介绍了实现细节。然后,我们概述了挖掘步骤的统计数据,最后列举了用于评估FixMiner的研究问题。
4.1 数据集
我们收集代码更改从ApacheCommons 44大型和流行的开源项目,JBoss,春天和Wildfly社区以下选择标准:我们专注于项目(1)用Java编写的,与公开的bug报告(2),(3)有至少20的至少一个源代码文件版本;最后,为了减少选择偏差,(4)我们从广泛的类别中选择项目——中间件、数据库、数据仓库、公用事业、基础设施。这一过程类似于Bench4bl (Lee et .2018)。表2详细说明了我们在每个项目中考虑的bug修复补丁的数量。最终,我们的数据集包括11 416个补丁。
4.2 实现选择
我们回想一下,我们在FixMiner工作流中做了以下参数选择:
-“Shape”搜索索引只考虑深度大于1的富编辑脚本(即AST子树应该至少包括一个父节点和一个子节点)。
- Rich Edit Scripts的比较是为了检索相同的树(例如,树编辑距离为0)。
4.3统计资料
FixMiner是一种模式挖掘方法,用于为程序修复系统生成修复模式。它的评价(参看第5节)将集中于评价产出模式的相关性。
尽管如此,我们还是提供了关于挖掘过程的统计数据,为讨论FixMiner设计选择的含义提供了基础。
搜索指数
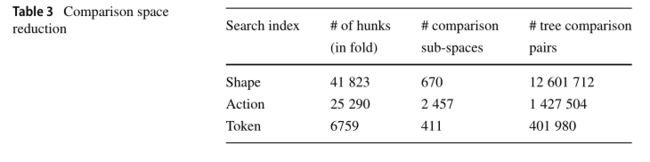
**FixMiner通过比较大块(即连续的代码行组)来挖掘修复模式。**我们的数据库中的11416个补丁最终与41823个大块头相关联。对这些数据块进行直接的两两比较将导致874 560 753个树比较计算。比较空间的组合爆炸可以通过构建搜索索引来克服,如前面第3.4节所述。表3显示了在FixMiner迭代中为每个折叠构建的搜索索引的详细信息。从要比较的874+百万对树(即C241823)中,构建Shape索引(实现对树结构的标准,以关注可比树)导致670个相关比较子空间,总共只产生1200 +百万对树比较。这表示比较空间减少了98%。类似地,Action索引和Token索引分别减少了88%和72%的相关比较空间。
集群
我们通过考虑树的重复来推断模式:聚类过程只将它们之间相同的树对组合在一起。表4概述了针对不同迭代产生的集群统计信息:形状模式(表示代码上下文)是最多样化的。操作模式(表示适合作为程序修复系统的输入的修复模式)实际上数量较少。

最后,令牌模式(可能是特定于代码基的)显著减少。我们回顾一下,我们考虑所有可能的集群,只要它包含至少2个元素。然而,一个从业者可能决定只选择大的集群(例如,基于一个阈值)。
因为FixMiner认为代码块是构建富编辑脚本的单元,一个给定的模式可能代表一个重复的上下文(例如,形状模式)或改变(例如,动作或令牌模式),这只是补丁的一部分(例如,这个补丁包含其他的改变模式)或这是一个完整的补丁(例如,整个补丁就是由这个变化模式组成的)。表5提供了部分模式和完整模式的统计信息。这些数字表示不相交的模式集,这些模式集可以被标识为总是完整的或总是部分的。对于一个给定的补丁,模式可能是完整的,但对于另一个补丁,模式可能是部分的。总的来说,统计数据表明,在我们的超过4万个代码块的数据集中,只有少数(例如,分别为278和7120块)分别与始终是全块或始终是偏块的模式相关联。在其余情况下,模式与代码块相关联,这些代码块可能单独形成补丁,也可能与其他代码纠缠在一起。这表明FixMiner能够处理模式挖掘期间的复杂变化。

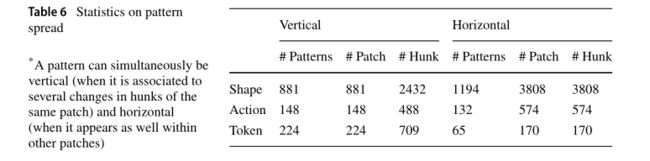
同样,我们也研究了这些模式是如何在补丁间传播的。事实上,可以找到一个模式,因为一个给定的补丁在几个代码块中做了相同的更改。我们把这种模式称为垂直模式。相反,可以找到模式,因为相同的代码更改分布在几个补丁中。我们把这种模式称为水平模式。表6显示了形状和动作模式的垂直和水平模式以相似的比例出现。然而,令牌模式垂直的明显多于水平的(65对224)。这与Linux中附属进化的研究是一致的,这些研究强调了大补丁一次在几个位置进行重复的变化(padiolau et al.2008) (i。e。,通过垂直的补丁应用间接进化)。
4.4 研究问题
评估实验的目的是调查FixMiner挖掘的模式的有效性。为此,我们重点关注以下研究问题(RQs):
RQ-1 FixMiner的自动patch聚类是否与人工解剖一致?
RQ-2 FixMiner推断的模式是否与已知的修复模式兼容?
RQ-3 挖掘的模式对自动程序修复有效吗?
5. 结果
5.1 RQ-1 FixMiner的自动patch聚类是否与人工解剖一致?
客观性
我们建议评估由FixMiner产生的集群的相关性,以判断它们是否代表了从业者会将其视为与补丁行为相关的周期性变化的模式。在前一节中,统计数据显示有几个变化是周期性的,并映射到FixMiner的集群。在这个RQ中,我们验证它们是否与从业者的观点相关。例如,如果FixMiner没有利用AST信息,那么删除空白行将被视为一种经常性的更改(因此是一种模式);然而,从业者并不认为这是相关的。
草案/协议
我们考虑一个oracle数据集,其中包含由人类标记的带有更改模式的补丁。然后,我们将每个补丁与FixMiner在我们的联合研究数据集中挖掘的相关集群相关联。通过这种方式,我们可以确保聚类不会过度适应人类标记的oracle数据集。最后,我们检查与给定FixMiner集群相关联的每组补丁(来自oracle数据集)是否由具有相同标签(来自oracle)的补丁组成。
oracle
在我们的实验中,我们利用Sobreira et. al(2018)提供的Defects4J (Just et al. 2014)的手动解剖。
这个oracle数据集将Defects4J数据集中395个bug的开发者补丁与26个修复模式标签(其中一个是“未分类”)关联起来。
结果
表7提供了描述FixMiner模式比例的统计信息,这些模式可以关联到Defects4J补丁中的变更模式。

多样性
我们检查可以在我们的研究数据集和Defects4J中找到的模式的数量。与我们的研究数据集相比,在绝对数量上,Defects4J补丁包括一组有限的变更模式(例如,~ 7%=214/2947)。
一致性
我们通过评估与FixMiner集群相关联的所有Defects4J补丁是否确实共享一个公共的剖析模式标签来检查FixMiner模式挖掘的一致性。我们发现,Shape、Action和Token的聚类结果分别为78%=166/214、73%=27/37和92%=12/13。
一致性。fiaminer可以生成匹配人类标记的补丁的模式。因此,这些模式在很大程度上与手工解剖一致。
粒度
人体解剖为给定的补丁提供修复模式标签。尽管如此,标签与补丁中的任何变化都没有特别关联。FixMiner为代码块生成模式。因此,虽然FixMiner将给定的块链接到单个模式,但分析数据将多个模式关联到一个给定的补丁。我们研究了与人类提供的模式相关的粒度级别。具体地说,FixMiner的几个模式实际上可以(基于相应的Defects4J补丁)关联到单个人体解剖模式。考虑表8中的示例案例。两个补丁都包含在IfStatement下嵌套的InfixExpression。第一个FixMiner模式指示应该对子节点InfixExpression执行更改操作(即更新操作符)。另一方面,第二个模式暗示了父InfixExpression中的更改操作。因此,FixMiner模式最终是细粒度的,并将示例补丁关联到两个不同的模式,每个模式都指向要更新的精确节点,而手动分解将它们置于相同的粗粒度修复模式下。

我们已经研究了FixMiner模式和解剖标签之间的差异,并发现了几个粒度上的不匹配类似于前面的例子:condBlockRetAdd(条件块添加返回语句)来自手动解剖与FixMiner的14个细粒度的形状模式相关:这表明该模式的修复潜力可以根据代码上下文进一步细化。类似地,expLogicMod(逻辑表达式修改)与FixMiner的两个单独的动作模式(见表8)相关联:这表明可以进一步专门化这种修复模式的应用,以减少修复搜索空间和误报。总的来说,我们发现总共有37个解剖修复模式,3个解剖修复模式和1个解剖修复模式分别细化为FixMiner 's Shape、Action和Token几种模式。
手工的更加粗粒度。
除了评估基于人工构建的oracle标签数据集的FixMiner模式的一致性外,我们还进一步建议调查模式在语义方面的相关性,这些语义可以与更改的意图相关联。为此,我们将与补丁相关的bug报告作为代理来描述代码更改的意图。我们希望通过语法相似的补丁来解决共享文本相似性的bug报告。这一假设推动了基于信息检索的bug定位的整个研究方向(Lee et al.2018)。
图14提供了与每个集群相关联的补丁相对应的bug报告(文本)相似性值的两两分布。为了清晰地展示,我们将重点放在前20个集群上(就规模而言)。我们使用TF-IDF将每个bug报告表示为一个向量,并利用余弦相似度计算向量之间的相似度得分。所表示的箱形图显示了所有成对的bug报告相似值,包括异常值。尽管对于Shape和Action模式,所有集群的相似性都接近于0,但我们注意到Action模式的异常值较少。这表明bug报告之间的相似性相对增加了。正如所料,错误报告之间的相似性是Token模式中最高的。

两两的bug报告相似性的分布。注意:红线表示所有bug报告的平均相似度,蓝线表示集群内bug报告的平均相似度
5.2 RQ-2 FixMiner推断的模式是否与已知的修复模式兼容?
客观性
假设FixMiner的目标是自动生成可被自动化程序系统使用的修复模式,我们建议评估生成的模式是否与文献中的模式兼容。
草案/协议
我们考虑了文献APR系统所使用的模式集合,并将它们与FixMiner的模式进行比较。具体地说,我们系统地尝试将FixMiner的模式与文献中的模式进行映射。为此,我们依赖于Liu等人(2019)提出的修复模式的综合分类法:如果一个给定的FixMiner模式可以映射到分类法中的一种变化类型,那么该模式就被标记为与文献中的模式兼容。
回想一下,正如前面所描述的,APR工具使用的修复模式以FixMiner的动作模式的形式抽象变化(章节3-步骤4)。在缺少指定模式的公共语言的情况下,比较是手动执行的。为了进行比较,我们没有在文献模式和FixMiner产生的模式之间进行精确的映射,因为FixMiner产生的修复模式具有更多的上下文信息。我们更倾向于考虑FixMiner模式产生的上下文信息是否与文献模式的上下文匹配。我们在第6节讨论了对有效性的相关威胁。考虑到评估是手工的,因此耗时,我们将比较限制在FixMiner产生的前50个模式(即动作模式)。
预言
我们以Liu等人(2019)列举的模式为基础,他们系统地审查了文献中Java APR系统使用的修复模式。他们总结了35个GNU格式的修复模式,我们在与FixMiner模式进行比较时引用了它们。
结果
总的来说,在11个研究的APR系统使用的35个固定模式中,有16个模式也包含在FixMiner在挖掘我们的研究数据集时生成的固定模式(即行动模式)中。我们记得这些模式通常是由研究人员手动推断和指定的APR工具。Table9说明与文献中使用的一些模式相关联的FixMiner修复模式示例。

我们注意到FixMiner识别的修复模式是特定的(例如,对于FP4: Insert Missed Statement,相应的FixMiner的修复模式指定了必须插入哪种类型的语句)。表10说明了与文献中模式兼容的FixMiner模式的比例。在这个比较中,我们选择FixMiner产生的前50个修复模式,并在APR系统中使用的修复模式中验证它们的存在。

- 7种模式与从bug修复补丁中手工挖掘的修复模式兼容(即PAR中的修复模式(Kim et al.2013))
-
- 1到8种模式与研究人员预定义的修复模式兼容,分别用于ssFix (Xin和Reiss2017)、ELIXIR (Saha等,2017)、S3 (Le等,2017)、NEPfix (Durieux等,2017)和SketchFix (Hua等,2018)
-
- 7模式兼容从历史bug修复修复模式挖掘HDRepair (Le et al.2016a), 9模式兼容修复模式挖掘从StackOverflow SOFix(刘和Zhong2018),和1修复模式兼容1修复模式由创世纪(长et al.2017)重点挖掘修复bug模式三种。
-
- 12个和8个模式分别与CapGen (Wen et .2018)和SimFix (Jiang et .2018)使用的模式兼容,它们以类似于bug修复的实证研究的统计方式提取模式(Martinez和Monperrus2015;Liu et al. 2018b)。
-
- 6种模式与A V A TAR中使用的修复模式兼容(Liu et .2019),这是在一项从FindBugs(Hovemeyer和Pugh 2004)静态分析违规中推断修复模式的研究中提出的(Liu et .2018a)。
RQ2 FiaMiner有效地生成了与基于模式的程序修复文献中使用的35种模式中的16种模式兼容的操作模式。
对令牌模式的手动(但系统的)评估
动作和令牌模式是与代码更改相关的两种模式。在上面的评估场景中,我们只考虑了Action模式,因为它们最适合与文献模式进行比较。现在,我们将重点放在令牌模式上,以评估我们关于令牌模式对派生附属演进有用性的假设是否有效(参见第3节-第4步)。为此,我们考虑由FixMiner产生的各种令牌集群,并手动验证周期性变化(即模式)是否相关(即,人类可以解释这些变化的意图是否相同)。最终,如果验证了模式,它应该是呈现为通用/语义补丁(padiolau et al.2008;Andersen和Lawall2010)用SmPL.6写成。

在表11中,我们列出了一些我们发现相关的补丁。在调查的前50个令牌模式中,12个模式对应一个修饰符更改,4个模式针对日志方法的更改,1个模式是关于固定中加操作符(例如,>→>=)。其余的情况主要集中在完成代码最终阻塞逻辑的实现的更改(例如,为打开的文件丢失对closeAll的调用),异常处理的更改,对传递给方法调用的错误参数的更新,以及错误的方法调用。正如前面提到的,这些模式主要是垂直分布的(即在给定补丁的几个代码块中反复出现更改),并且这些模式的语义行为是特定于项目性质的。
总的来说,我们对前50个令牌模式的手工调查证实,与特定令牌相关的许多周期性变化确实是相关的。我们甚至发现了几例副支进化变化被重新组合成一个模式,如图15所示的对应模式示例所示。在本例中,我们使用SmPL规范语言来说明模式,该语言设计用于指定附带演进。这一发现表明,FixMiner可以被用于系统地挖掘以令牌模式形式出现的附属演进,令牌模式可以自动重写为SmPL格式的语义补丁。然而,这一努力超出了本文的范围,并将在未来的工作中进行调查。
5.3 RQ-3 挖掘的模式对自动程序修复有效吗?
客观性
我们建议评估由FixMiner产生的修复模式对自动程序修复是否有效。
草案/协议
我们实现了一个原型APR系统,该系统使用FixMiner挖掘的修复模式,通过遵循PAR的原则(Kim et .2013)为bug生成补丁,在本文的剩余部分被称为PARFixMiner。PAR中模板是通过对示例bug修复的手工调查来设计的,而在PARFixMiner中,用于修复的模板是基于FixMiner挖掘的修复模式来设计的。图16概述了PARFixMiner的工作流。

故障定位
PARFixMiner使用基于频谱的故障定位。我们使用GZoltar7(Campos et al.2012)动态测试框架,并利用Ochiai (Abreu et al.2007)基于通过和失败测试用例的执行覆盖率信息来预测有缺陷的语句。这种设置广泛应用于维修行业(Martinez和Monperrus2016;熊等al.2017;鑫和Reiss2017;允许对PARFixMiner与最新技术进行比较评估。
模式匹配和补丁生成
一旦基于频谱的故障定位(或基于ir的故障定位)过程生成一个可疑代码位置列表,PARFixMiner尝试为列表中的每个语句选择修复模式。修复模式的选择是通过匹配可疑代码位置的上下文信息和fixminer挖掘的修复模式来进行的。具体地说,首先,我们解析可疑的语句,并遍历其AST的每个节点,从它的第一个子节点到最后一个叶子节点,并形成AST子树来表示其上下文。然后,我们尝试将AST子树的上下文(即形状)(来自可疑语句)匹配到修复模式的形状。
如果找到匹配的修复模式,我们将继续生成一个补丁候选。一些修复模式需要提供代码(例如,从有bug的程序中提取的源代码)来生成带有修复模式的补丁候选。这些也经常被称为固定成分的一部分。回想一下,为了与修复工具集成,我们利用了FixMiner Action模式,它不包含任何代码标记信息:它们有“漏洞”。因此,我们从包含可疑语句的文件中本地搜索捐赠方代码。我们从适用于修复模式和可疑语句(即变量的数据类型、表达式类型等与上下文匹配)的语句中选择相关的donor代码,以减少donor代码的搜索空间,进一步限制生成无意义的候选补丁。例如,图17中的修复模式只能匹配到一个具有方法调用表达式的可疑返回语句:因此,将用另一个方法名替换其方法名(即donor code)来修补可疑返回语句。通过从可疑文件中识别具有相同返回类型和参数的可疑语句的所有方法名来搜索捐赠方代码。最后,根据匹配的修复模式中指示的操作,将带有已识别的捐赠方代码的可疑语句进行突变,从而生成一个补丁候选。我们生成的补丁数量与已识别的捐赠者代码片段的数量一样多。补丁是按照AST中匹配的顺序连续生成的。

注意:我们提醒读者,在本研究中,我们不执行特定的补丁优先级策略。通过使用宽度优先策略(即从左到右和从上到下),从包含可疑语句的本地文件的AST树中遍历本地文件的AST的每个节点,从它的第一个子节点到最后一个叶子节点,我们从AST树中搜索提供者代码。对于一个给定的修复模式,如果有多个捐赠方代码选项,将根据AST树(包含可疑语句的本地文件)中捐赠方代码的位置生成候选补丁(每个补丁都有特定的捐赠方代码)。
模式验证
一旦生成候选补丁,它将被应用到有bug的程序中,并将根据测试套件进行验证。如果它能使bug程序成功通过所有测试用例,那么候选补丁将被视为一个可信的补丁,PARFixMiner将停止尝试针对该bug的其他补丁候选补丁。否则,将重复模式匹配和补丁生成步骤,直到处理完整个可疑代码位置列表。具体来说,我们只考虑为每个bug生成的第一个貌似合理的补丁来评估其正确性。对于PARFixMiner生成的所有可能的补丁,我们进一步手动检查这些补丁和Defects4J中提供的oracle补丁之间的等价性。如果它们在语义上与开发者提供的补丁相似,我们认为它们是正确的补丁,否则仍然是可信的。
在表中,“Bugs”列表示defects s4j基准测试中的Bugs总数,“LOC”列表示数千行代码的数量,“Tests”列表示每个项目的测试用例总数

预言
我们使用了Defects4J8(Just et .2014)数据集,该数据集被广泛用作针对java的APR研究的基准(Martinez和Monperrus2016;L e e a L .2016a;Chen等人al.2017;马丁内斯et al.2017)。该数据集包含357个bug及其相应的开发人员修复和测试用例覆盖这些bug。表12详细说明了基准测试的统计信息。
结果
总的来说,我们实现了FixMiner挖掘的31个修复模式(即动作模式),只关注前50个集群(就规模而言)。
我们将PARFixMiner的性能与13个最先进的APR工具进行比较,这些工具也使用了Defects4J基准来评估它们的修复性能。表13说明了根据可信数字(即。,它通过了所有的测试用例)并且正确(例如。,最终手工验证其语义类似于开发人员提供的修复)补丁。请注意,尽管HDRepair手稿中有23个错误产生了“正确的”修复(其中一个正确的修复在13个错误中排名第一),但作者仅将6个错误标记为“验证ok”(参见第9页)。我们在比较中考虑了这6个缺陷。
总的来说,我们发现parfixminer通过生成正确的补丁,成功修复了来自Defects4J基准测试的26个bug。到目前为止,这一性能仅被与parfixminer同时开发的SimFix (Jiang et .2018)超越。
尽管如此,虽然这些工具比parfixminer生成了更多正确的补丁,但它们也生成了更多看似合理的补丁,然而这些补丁并不正确。为了比较评估不同的工具,我们使用Precision**度量§,即生成的补丁的正确性概率。P(%)定义为首先生成正确修复(即在任何其他可信补丁之前)的bug数量与首先生成可信(但不正确)补丁的bug数量之比。例如,81%的parfixminer的貌似合理的补丁实际上是正确的,而63%和60%的ELIXIR和SimFix的貌似正确的补丁是正确的。到目前为止,只有CapGen (Wen et .2018)在生成斑块时取得了类似的表现,其正确的概率略高(84%)。CapGen的高性能证实了他们的直觉,即我们在thrich Edit Script中提供的上下文感知,对于提高补丁的正确性是必不可少的。
table14列举了文献中目前已修复的128个bug(既正确又合理)。
其中89个可以通过至少一个APR工具正确修复。PARFixMiner为26个bug生成正确的补丁。在使用版本的defects s4j基准测试中,有267个bug还没有被文献中的任何工具修复,这对于自动程序修复研究来说仍然是一个巨大的挑战。最后,我们发现,由于它的自动挖掘模式,PARFixMineris能够修复6(6)个错误,这些错误没有被任何先进的APR工具修复(参见图18)。


6.讨论和有效性的威胁
运行时性能
运行时性能为了用fixminer运行实验,我们利用了一个包含24个Intel Xeon E5-2680 v3内核和2个内核的计算系统。每核GHz和3TB RAM。富编辑脚本的构建花费了大约17分钟。富编辑脚本缓存在内存中,以减少计算相同树时对磁盘的访问。然而,我们记录到,比较1 108 060对树大约需要18分钟。
对外部有效性的威胁
我们的bug修复数据集的选择带来了一些外部有效性的威胁,我们通过考虑已知的项目和之前研究中使用的启发式来限制这些威胁。我们还尽最大努力将提交与开发人员标记的bug报告链接起来。如果考虑到错误的严格和正式定义,可能会包括一些误报。
建构效度的威胁
当检查ofFixMiner的模式与文献APR系统使用的模式的兼容性时出现。事实上,为了进行比较,我们不进行元素应该相同的精确映射,因为文献模式可能比fixminer生成的模式更抽象。例如,修改方法名称(例如:, FP10.1)是突变方法调用表达式(即FP10)的子固定模式,它是关于用另一个合适的方法名替换方法调用表达式的方法名(Liu et .2019)。可以匹配此修复模式在方法调用表达式下包含方法名的任何语句。然而,在本文中,由fixminerer生成的类似修复模式具有更多的上下文信息。因此,我们考虑上下文信息来检查ofFixMiner的模式与文献APR系统使用的模式的兼容性。例如,图17所示的修复模式是用return - statement中另一个合适的方法名修改一个方法调用表达式的错误方法名。由于上下文信息指的是areturnstatement,图17所示的修复模式被认为与突变返回语句(即。、FP12)。然而,映射是保守的,因为我们认为aFixMiner模式匹配来自文献的模式,只要它能适合文献模式。
7 相关工作
自动化程序修复
补丁生成是软件维护中的关键任务之一,因为它既耗时又繁琐。如果这个任务是自动化的,那么开发人员维护的成本和时间将大大减少。为了解决这个问题,许多自动化技术已经被提出用于程序修复(Monperrus2018)。利用遗传规划的GenProg (Le Goues et al.2012b)是程序修复方面的开创性工作。它依赖于插入、替换或删除代码元素的突变操作符。虽然这些突变可以创建数量有限的变体,但GenProg可以自动修复几个bug(在他们的评估中,测试用例通过了105个真正的程序bug中的55个),尽管其中大多数后来被发现是错误的补丁。PACHIKA (Dallmeier et al.2009)利用对象行为模型。SYDIT(孟et al.2011)和LASE(孟et al.2013)自动从程序更改中提取编辑脚本。Kim等人(Kim et al.2013)指出,在程序修复中也应考虑补丁的可接受性。自动生成的补丁通常具有无意义的结构和逻辑,即使这些补丁可以修复关于程序行为的程序错误(例如,w.r.t.测试用例)。为了解决这个问题,他们提出了PAR,它利用了手工制作的修复模式。类似地,Long和Rinard提出了Prophet (Long and Rinard2016)和Genesis (Long et .2017),它们通过利用从存储库的变更历史中提取的修复模式来生成补丁。最近,几种方法(Bhatia和Singh2016;G u p t a e t a l .2017)利用深度学习已经被提出学习修复bug。即使是最近的针对bug报告的APR方法也依赖于修复模板来生成补丁。iFixR (Koyuncu et al.2019)是建立在TBar (Liu et al.2019)模板之上的一个例子。总的来说,我们注意到社区正在朝着基于修复模式或模板实现修复策略的方向发展。因此,我们的工作在这个方向上是至关重要的,因为它提供了一个可伸缩的、准确的和可操作的工具来挖掘相关的模式,以便自动程序修复。
代码差分
代码差异是软件工程中一个重要的研究和实践问题。尽管人类开发人员通常在手工任务中使用文本行级别粒度(Myers1986)的差异,但通常不适合用于更改和相关语义的自动化分析。AST差异研究工作在过去十年中受益于研究团体对一般树木差异进行的广泛调查(bile2005;C h a w a t h e t a l .1996;Chilowicz等人2009年;A l - E r A m t A l .2005)。ChangeDistiller (Fluri et al.2007)和GumTree (Falleri et al. 2014)构成了当前最先进的Java AST差异。在这项工作中,我们选择了GumTree作为计算编辑脚本的基础工具,因为它的结果已经经过了人类的验证,并且它已经被证明是更精确和细粒度的编辑脚本。尽管如此,我们进一步增强了编辑脚本,生成了一个跟踪上下文信息的算法。我们的方法与Huang等人(2018)最近发表的一篇文章相呼应:他们的CLDIFF工具同样丰富了由GumTree生成的AST,从而能够生成简洁的代码差异。然而,在我们实验的时候,这种工具是不可用的。因此,为了满足修复模式挖掘方法的输入需求,我们实现了entrich Edit Script,通过保留更多上下文信息来丰富gumtree生成的编辑脚本。
改变模式
文献包括大量关于挖掘变化模式的工作。
基于挖掘的方法近年来,有几种方法建立在挖掘模式或利用模板的思想之上。Fluri等人基于ChangeDistiller AST差异计算的编辑脚本,使用分层聚类在三个Java应用程序中发现未知的变更类型(Fluri等。2008)。然而,他们限制自己只考虑实现他们之前确定的41种基本变更类型的变更(Fluri和Gall2006)。Kreutzer等人开发了C3,在聚类算法的帮助下,可以自动检测代码库中类似代码变化的组(Kreutzer等。2016)。Martinez和Monperrus(2015)评估了错误修复类型和自动程序修复之间的关系。他们基于ChangeDistiller的细粒度抽象语法树差异,对人类bug修复的本质进行了广泛的大规模实证调查。实验表明,与随机搜索相比,挖掘模型更能有效地驱动搜索。然而,他们的模型仍然处于较高的级别,并且可能不携带任何可被其他基于模板的apr使用的可操作的模式。然而,我们的工作也以系统化和自动化“挖掘可操作的修复模式”为目标,以提供基于模式的程序修复工具。
一个示例应用程序与Livshits和Zimmermann(2005)的工作有关,他们通过在两个Java项目上使用关联规则挖掘发现了特定于应用程序的修复模板。最近,Hanam等人(2016)开发了BugAID技术,用于发现JavaScript中最普遍的修复模板。他们使用AST差分和无监督学习算法。我们的目标与他们的类似,即关注具有不同模式抽象级别的Java程序。FixMiner建立在三次集群策略的基础上,在这种策略中,我们迭代地发现保留周围代码上下文的周期性更改。
关于代码变更冗余的研究
许多实证研究已经证实,代码更改在软件代码库中反复执行(Kim和Notkin2009;K i m等。2006;Molderez et al.2017;杨等,2017)。相同的更改之所以普遍,是因为同一bug的多次出现需要相同的更改。类似地,经验软件工程(2020)25:20 80 - 20242015,当一个API发展时,或者当迁移到一个新的库/框架时,所有调用代码都必须通过相同的附带变化进行调整(padiolau等,2008)。最后,代码重构或例程代码清理可能导致类似的更改。在一项手工调查中,Pan等人(2009)确定了27个Java软件的可提取修复模板。在其他发现中,他们观察到如果条件的变化是最经常应用于修复bug。然而,他们的研究并没有讨论大多数细菌是否与If-condition有关。这一点很重要,因为它澄清了执行if相关更改的上下文。最近,Nguyen等人(2010)通过经验发现,17-45%的bug修复是重复的。我们在本文中的重点是提供工具支持的自动化方法来推断数据集中的变化模式,以驱动修复模式来指导APR突变。此外,我们的模式比之前的作品(如Pan et al.(2009)和Nguyen et al.(2010))中的模式更具有普遍性。
与我们的工作同时,Jiang等人提出了SimFix (Jiang et al.2018), Wen等人提出了SimFix。CapGen(2018)实现了类似的想法,即利用上下文信息来塑造程序修复空间的代码冗余。然而,在infixminerer中,模式挖掘阶段是独立于补丁生成阶段的,生成的模式是可处理的,并且可以作为其他APR系统的输入进行重用。
通用和语义补丁推理
理想情况下,FixMineris是一个旨在找到一个通用补丁的工具,该补丁可以被自动程序修复所利用,以正确地更新一组有缺陷的代码片段。这一问题最近通过spdiff(Andersen and Lawall2010;Andersen等。2012),主要研究泛型和语义补丁的推理。然而,众所周知,这种方法的可扩展性很差,并且在生成可被Coccinelle匹配和转换引擎使用的即时语义补丁方面存在限制(Brunel et al.2009)。然而,有许多先前的工作试图检测和总结程序更改。Chawathe等人的一项开创性工作描述了一种基于有序树及其更新版本检测结构化信息变化的方法(Chawathe等人,1996年)。我们的目标是利用最小成本编辑脚本的概念,得出一个紧凑的变更描述,该脚本已在最近的ChangeDistiller和GumTree工具中使用。然而,编辑操作的表示,要么经常对特定的代码更改进行过拟合,要么非常松散地抽象更改,以至于无法很容易地实例化。Neamtiu et al.(2005)提出了一种基于语法树结构匹配的方法来识别C程序元素的变化、增加和删除。两棵结构相同但节点不同的树被认为代表匹配的程序片段。Kim等人(2007)后来提出了一种方法来推断捕捉许多变化的“变化规则”。它们通常表示与程序头文件(方法头文件、类名、包名等)相关的更改。Weissgerber等人(2006)也提出了一种技术来识别在Java程序中执行的更改中可能的重构。总之,这些通用的补丁推理方法解决了在实践中如何利用模式的挑战。我们的工作朝着这个方向进行,为不同的目的提供不同类型的模式:基于形状的模式减少了代码匹配的上下文;行动模式对应于修复社区中使用的修复模式;令牌模式用于推断附带演进。
8. 总结
我们已经介绍了fixminer,这是一种系统的、自动化的方法,可以挖掘相关的、可操作的修复模式,以实现自动程序修复。该方法基于迭代和三次聚类策略,在每一轮中形成代表循环模式的相同树的聚类。我们评估挖掘的模式与文献中的模式的一致性。我们通过自动化修复管道的实现进一步说明,我们的方法挖掘的模式与在Defects4J基准测试中为26个错误生成正确的补丁有关。这些正确的补丁对应于该工具生成的所有可信补丁的81%。