分布式深度学习最佳入门(踩坑)指南
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
仅作学术分享,不代表本公众号立场,侵权联系删除
转载于:作者丨Lyon@知乎(已授权)
来源丨https://zhuanlan.zhihu.com/p/294698838
本文主要分为两部分:
1.各框架分布式简介
2.分布式常见问题汇总(踩坑指南)
在各框架分布式简介中,将先从入门的角度介绍各个框架的分布式接口或相关概念以及和单机程序的主要区别、然后在分布式示例部分,通过各个框架github官方仓库中的分布式代码实现(resnet50),简单介绍各框架的分布式训练;最后对分布式深度学习中常见的库如Horovod、Dali做简单的介绍,及安装使用说明。
在分布式常见问题汇总(踩坑指南)中会总结分布式深度学习训练中的常见问题,如:docker及ssh环境问题、nccl多机通信问题等。
这里,安利一下本人近期有幸参与的工作:DLPerf项目,一个公平的多框架性能测评项目。本文中的(踩坑)经验大都来源于此。同时,性能测评过程保留了详细的readme、log日志等,大家可以照着readme轻松复现各个框架的分布式训练过程。
1.各框架分布式简介
1.Pytorch
PyTorch 以其灵活易用,成为几乎所有科研人员的首选框架。但PyTorch 的分布式训练起步较晚,因此还可能不为大家所熟悉。从官方文档上我们可以看到,pytorch的分布式训练,主要是torch.distributed包所提供,主要包含以下组件:
Distributed Data-Parallel Training (DDP)
RPC-Based Distributed Training (RPC)
Collective Communication (c10d)
其中,DDP提供了数据并行相关的分布式训练接口;RPC提供了数据并行之外,其他类型的分布式训练如参数服务器模式、pipeline并行模式,使用的是P2P点对点通信;而c10d是一个用于集合通信的库,作为DDP的组件为其提供服务。由于我们大多数的分布式训练需求,是基于DDP的,故下面内容不涉及RPC相关的训练。
接口
单机多GPU可以使用torch.nn.DataParallel接口或torch.nn.parallel.DistributedDataParallel接口。不过官方更推荐使用DistributedDataParallel(DDP);分布式多机情况下,则只能使用DDP接口。
DistributedDataParallel和 之间的区别DataParallel是:DistributedDataParallel使用multiprocessing,即为每个GPU创建一个进程,而DataParallel使用多线程。通过使用multiprocessing,每个GPU都有其专用的进程,这避免了Python解释器的GIL导致的性能开销。如果您使用DistributedDataParallel,则可以使用 torch.distributed.launch实用程序来启动程序 参考:Use nn.parallel.DistributedDataParallel instead of multiprocessing or nn.DataParallel(https://pytorch.org/docs/master/notes/cuda.html#cuda-nn-ddp-instead)
底层依赖 Pytorch在1.6版本中,可以通过torch.nn.parallel.DistributedDataParallel来实现数据并行的分布式训练,DistributedDateParallel,简称DDP。DDP的上层调用是通过dispatch.py实现的,即dispatch.py是DDP的python入口,它实现了 调用C ++库forward的nn.parallel.DistributedDataParallel模块的初始化步骤和功能;DDP的底层依赖c10d库的ProcessGroup进行通信,可以在ProcessGroup中找到3种开箱即用的实现,即 ProcessGroupGloo,ProcessGroupNCCL和ProcessGroupMPI。
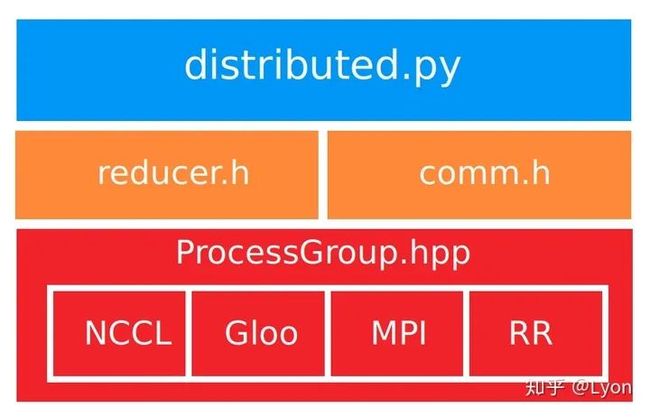
ProcessGroupGloo,ProcessGroupNCCL和ProcessGroupMPI这3种分布式通讯实现分别对应:
Gloo
NCCL
MPI
即本质上,pytorch的分布式多机训练,依赖于以上这3种通信库。
参考:Distributed Data Parallel
https://pytorch.org/docs/master/notes/ddp.html
分布式示例
pytorch官方在github上提供了examples仓库,包含了各种深度学习任务的模型和相关示例代码,这里 我们以Pytorch官方仓库里的ResNet50的分布式训练源码为例,简单讲解下pytorch分布式训练相关方法和参数。
初始化进程组 分布式训练的第一步是需要设置分布式进程组,设置多机通信后端、本机ip端口号、节点总数、本机编号等信息。源码129行:
dist.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
world_size=args.world_size, rank=args.rank)将上述分布式相关参数,传递到torch.distributed.init_process_group并初始化用于训练的进程组;初始化进程组之前,我们首先看下main.py的相关参数设置:相关参数 源码第59行:
parser.add_argument('--world-size', default=-1, type=int,
help='number of nodes for distributed training')
parser.add_argument('--rank', default=-1, type=int,
help='node rank for distributed training')
parser.add_argument('--dist-url', default='tcp://224.66.41.62:23456', type=str,
help='url used to set up distributed training')
parser.add_argument('--dist-backend', default='nccl', type=str,
help='distributed backend')
parser.add_argument('--seed', default=None, type=int,
help='seed for initializing training. ')
parser.add_argument('--gpu', default=None, type=int,
help='GPU id to use.')
parser.add_argument('--multiprocessing-distributed', action='store_true',
help='Use multi-processing distributed training to launch '
'N processes per node, which has N GPUs. This is the '
'fastest way to use PyTorch for either single node or '
'multi node data parallel training')--world-size 表示分布式训练中,机器节点总数
--rank 表示节点编号(n台节点即:0,1,2,..,n-1)
--multiprocessing-distributed 是否开启多进程模式(单机、多机都可开启)
--dist-url 本机的ip,端口号,用于多机通信
--dist-backend 多机通信后端,默认使用nccl
创建模型 分布式进程组初始化完成后,需要将模型通过DDP进行包装。
源码153行:https://github.com/pytorch/examples/blob/49ec0bd72b85be55579ae8ceb278c66145f593e1/imagenet/main.py#L153
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu]) 通过DDP接口创建一个多机model实例。
数据切分和DataLoader 准备好模型后,需要准备分布式训练所需的数据集,在分布式训练任务中(数据并行)多机的Dataloader和普通dataloader也有所区别,需要用DistributedSampler包装后再通过torch.utils.data.DataLoader实例化成Dataloader。
源码217行:https://github.com/pytorch/examples/blob/49ec0bd72b85be55579ae8ceb278c66145f593e1/imagenet/main.py#L217
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset) 通过DistributedSampler创建一个wapper,将数据集放入其中,再通过 torch.utils.data.DataLoader 创建可用于多机的Dataloader;
if args.distributed:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
else:
train_sampler = None
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, shuffle=(train_sampler is None),
num_workers=args.workers, pin_memory=True, sampler=train_sampler)其余部分,和正常的单机版训练差异不大,此处就不赘述了。
完整的利用ResNet50训练ImageNet的示例可参考:Pytorch官方仓库(https://github.com/pytorch/examples/tree/49ec0bd72b85be55579ae8ceb278c66145f593e1/imagenet)
分布式训练速度测评及结果,可以参考DLPerf:PyTorch ResNet50 v1.5测评(https://github.com/Oneflow-Inc/DLPerf/tree/master/PyTorch/resnet50v1.5)

2.TensorFlow
TensorFlow是谷歌开源的深度学习框架,它包含各种工具、库和社区资源,是一个比较全面而复杂的深度学习平台,在pytorch之前的很长一段时间,tensorflow占据了深度学习框架领域的主导地位。
在TF1时代,tensorflow的静态图模式效率很高但对用户门槛较高,但模型较为复杂且不方便进行调试;后来,简单且易于上手的pytorch风靡之后;
TF2时代,tensorflow也学习pytorch,集成了keras的api,默认支持动态图模式。不过由于历史包袱的原因,在修改了大量底层代码的同时,也带来了新老版本模型不兼容、各种bug的情况。不过即便如此,tensorflow由于其性能和易于部署的优势,还是在深度学习框架领域占据了半壁江山。
接口
在Tensorflow中,需要通过tf.distribute.Strategy接口来定义分布式策略,并通过这些不同的策略,来进行模型的分布式训练。tf.distribute.Strategy 旨在实现以下目标:
易于使用,支持多种用户(包括研究人员和 ML 工程师等)。
提供开箱即用的良好性能。
轻松切换策略。
从Tensorflow官方文档(https://tensorflow.google.cn/guide/distributed_training)中,我们可以看到主要有以下策略:
MirroredStrategy
TPUStrategy
MultiWorkerMirroredStrategy
CentralStorageStrategy
ParameterServerStrategy
当然,需要注意的是:从单机训练切换到使用这些策略进行分布式训练时,是需要改动代码的(并非无缝一键切换),而且tf提供的模型训练API并不是对这些策略都完全支持,详见官方文档—策略类型(https://tensorflow.google.cn/guide/distributed_training#%E7%AD%96%E7%95%A5%E7%B1%BB%E5%9E%8B):
| 训练 API | MirroredStrategy | TPUStrategy | MultiWorkerMirroredStrategy | CentralStorageStrategy | ParameterServerStrategy |
|---|---|---|---|---|---|
| Keras API | 支持 | 支持 | 实验性支持 | 实验性支持 | 计划于 2.3 后支持 |
| 自定义训练循环 | 支持 | 支持 | 实验性支持 | 实验性支持 | 计划于 2.3 后支持 |
| Estimator API | 有限支持 | 不支持 | 有限支持 | 有限支持 | 有限支持 |
注:实验性支持指不保证该 API 的兼容性。
注:对 Estimator 提供有限支持。基本训练和评估都是实验性的,而未实现高级功能(如基架)。如未涵盖某一用例,建议您使用 Keras 或自定义训练循环。
下面,简单介绍下各个策略的模式:
MirroredStrategy 支持单机多gpu同步的分布式训练,默认使用 NVIDIA NCCL 作为all reduce实现。
TPUStrategy 支持谷歌TPU设备的策略(TPU 是 Google 的专用 ASIC,旨在显著加速机器学习工作负载)
MultiWorkerMirroredStrategy 与 MirroredStrategy 非常相似。它实现了跨多个工作进程的同步分布式训练,而每个工作进程可能有多个 GPU。简单来说,多机分布式通常使用的就是这个策略。该策略支持3种不同的collective communication模式:
CollectiveCommunication.RINGCollectiveCommunication.NCCLCollectiveCommunication.AUTO
RING模式将使用gRPC用于基于环的collective通信;而NCCL模式则是使用基于NVIDIA 的 NCCL来实现;AUTO模式则是在运行时自动选择。
CentralStorageStrategy 执行同步训练,参数变量不会被镜像,而是放在 CPU 上,且运算会复制到所有本地 GPU 。如果只有一个 GPU,则所有变量和运算都将被放在该 GPU 上。
ParameterServerStrategy 在多台机器上进行参数服务器训练,和MultiWorkerMirroredStrategy类似,可用于多机分布式训练。改策略下,一些机器被指定作为工作节点,一些机器被指定为参数服务器,模型的每个变量都会被放在参数服务器上。计算会被复制到所有工作进程的所有 GPU 中。注:该策略仅适用于 Estimator API。
分布式示例
下面,我们以TensorFlow官方仓库里的ResNet50的分布式训练为例,简单讲解下TensorFlow分布式训练相关方法和参数。
分布式策略
在tf中使用分布式训练,首先需要定义分布式策略。我们可以看到在classifier_trainer.py的第301行处,定义了分布式策略strategy。第301行:
if distribution_strategy == "tpu":
# When tpu_address is an empty string, we communicate with local TPUs.
cluster_resolver = tpu_lib.tpu_initialize(tpu_address)
return tf.distribute.experimental.TPUStrategy(cluster_resolver)
if distribution_strategy == "multi_worker_mirrored":
return tf.distribute.experimental.MultiWorkerMirroredStrategy(
communication=_collective_communication(all_reduce_alg))
if distribution_strategy == "one_device":
if num_gpus == 0:
return tf.distribute.OneDeviceStrategy("device:CPU:0")
if num_gpus > 1:
raise ValueError("`OneDeviceStrategy` can not be used for more than "
"one device.")
return tf.distribute.OneDeviceStrategy("device:GPU:0")
if distribution_strategy == "mirrored":
if num_gpus == 0:
devices = ["device:CPU:0"]
else:
devices = ["device:GPU:%d" % i for i in range(num_gpus)]
return tf.distribute.MirroredStrategy(
devices=devices,
cross_device_ops=_mirrored_cross_device_ops(all_reduce_alg, num_packs))
if distribution_strategy == "parameter_server":
return tf.distribute.experimental.ParameterServerStrategy()
raise ValueError(
"Unrecognized Distribution Strategy: %r" % distribution_strategy)分布式策略相关的参数如num_gpus、distribution_strategy等会传递到get_distribution_strategy(),该方法内部(distribution_utils.py第127行https://github.com/tensorflow/models/blob/r2.3.0/official/utils/misc/distribution_utils.py#L127)生成各种策略实例,如:
tf.distribute.experimental.TPUStrategy
tf.distribute.OneDeviceStrategy
tf.distribute.experimental.MultiWorkerMirroredStrategy
tf.distribute.MirroredStrategy
tf.distribute.experimental.ParameterServerStrategy
第127行:
if distribution_strategy == "tpu":
# When tpu_address is an empty string, we communicate with local TPUs.
cluster_resolver = tpu_lib.tpu_initialize(tpu_address)
return tf.distribute.experimental.TPUStrategy(cluster_resolver)
if distribution_strategy == "multi_worker_mirrored":
return tf.distribute.experimental.MultiWorkerMirroredStrategy(
communication=_collective_communication(all_reduce_alg))
if distribution_strategy == "one_device":
if num_gpus == 0:
return tf.distribute.OneDeviceStrategy("device:CPU:0")
if num_gpus > 1:
raise ValueError("`OneDeviceStrategy` can not be used for more than "
"one device.")
return tf.distribute.OneDeviceStrategy("device:GPU:0")
if distribution_strategy == "mirrored":
if num_gpus == 0:
devices = ["device:CPU:0"]
else:
devices = ["device:GPU:%d" % i for i in range(num_gpus)]
return tf.distribute.MirroredStrategy(
devices=devices,
cross_device_ops=_mirrored_cross_device_ops(all_reduce_alg, num_packs))
if distribution_strategy == "parameter_server":
return tf.distribute.experimental.ParameterServerStrategy()
raise ValueError(
"Unrecognized Distribution Strategy: %r" % distribution_strategy)之后,在classifier_trainer.py第301行处,将生成的策略传递给变量strategy
数据加载
除了分布式策略外,数据加载也需要进行额外处理。首先,在117行处,使用官方dataset_factory.DatasetBuilder接口构建出用于数据加载的训练集和验证集的builder,然后在第316行处builder根据分布式策略对数据进行切分,生成分布式训练可用数据集。第316行:
datasets = [builder.build(strategy)
if builder else None for builder in builders]之后,通过model.compile(353行)将optimizer等参数编译到keras定义的resnet50-model上;加上训练集dataset、callback(回调函数)等一系列参数后,通过model.fit执行模型训练(386行)。
完整的利用ResNet50训练ImageNet的示例可参考:TensorFlow官方仓库(https://github.com/tensorflow/models/tree/r2.3.0/official/vision/image_classification)
分布式训练速度测评及结果,可以参考DLPerf:【DLPerf】TensorFlow 2.x-ResNet50V1.5测评(https://github.com/Oneflow-Inc/DLPerf/tree/master/TensorFlow/resnet50v1.5)
3.PaddlePaddle
PaddlePaddle是百度开源的深度学习框架,中文名称意为飞桨。你没理解错,就是划水用的那个桨:)

(开个玩笑,paddle并不是让你上班划水,而是划龙舟,众人拾柴火焰高) paddle其支持数据并行和模型并行,作为较早一批的国产深度学习框架,其文档、模型库等也较为完善,paddle框架也支撑了各种深度学习模型在百度各种业务领域及场景下的应用。
接口
Paddle的分布式API大多集中在paddle.fluid下,从Paddle Fluid Release 1.5.1 开始,官方推荐使用fluid下封装的更高级的Fleet API进行分布式训练,Fleet API支持pserver模式和NCCL2模式下的分布式训练。pserver模式即参数服务器模式;NCCL2模式,即集合通信模式(利用NCCL进行通信);通常,在分布式多GPU的环境下,我们使用NCCL模式的分布式训练。
Paddle分布式API中顶层的库(以集合通信为例)主要包括:paddle.fluid、paddle.fluid.incubate.fleet.collective.fleet等,这些顶层库下面又包含了分布式策略、role_maker、分布式optimizer等相关的接口和方法如:
分布式策略相关接口:paddle.fluid.incubate.fleet.collective.DistributedStrategy
role_maker相关接口:paddle.fluid.incubate.fleet.base.role_maker
optimizer相关接口:fluid.optimizer
分布式optimizer封装接口:fleet.distributed_optimizer
RoleMaker是Paddle分布式中的重要概念,用于描述集群节点的角色信息,目前支持:MPISymetricRoleMaker、PaddleCloudRoleMaker、UserDefinedRoleMaker三种模式。
其中MPISymetricRoleMaker会假设每个节点启动两个进程,1worker+1pserver,这种RoleMaker要求用户的集群上有mpi环境;PaddleCloudRoleMaker是一个高级封装,支持使用paddle.distributed.launch或者paddle.distributed.launch_ps启动脚本;UserDefinedRoleMaker允许用户自定义节点的角色信息,IP和端口信息。
参考:Fleet Design Doc https://www.paddlepaddle.org.cn/tutorials/projectdetail/487871
分布式示例
下面,我们以paddle官网的分布式示例demo为例,讲解下在Fleet API下将单机代码改为分布式多机代码,主要的几个步骤:
1.导入分布式依赖的库:
# -*- coding: utf-8 -*-
import os
import numpy as np
import paddle.fluid as fluid
# 区别1: 导入分布式训练库
from paddle.fluid.incubate.fleet.collective import fleet, DistributedStrategy
from paddle.fluid.incubate.fleet.base import role_maker
# 定义网络
def mlp(input_x, input_y, hid_dim=1280, label_dim=2):
fc_1 = fluid.layers.fc(input=input_x, size=hid_dim, act='tanh')
fc_2 = fluid.layers.fc(input=fc_1, size=hid_dim, act='tanh')
prediction = fluid.layers.fc(input=[fc_2], size=label_dim, act='softmax')
cost = fluid.layers.cross_entropy(input=prediction, label=input_y)
avg_cost = fluid.layers.mean(x=cost)
return avg_cost2.数据集处理
分布式下,通常需要用框架提供的api或者手动写代码完成数据集的切分,以使数据能均匀切分到不同的机器节点,从而达到“数据并行”加速训练的目的。由于是示例,下面数据集由numpy生成,省略了这个过程:
# 生成数据集
def gen_data():
return {"x": np.random.random(size=(128, 32)).astype('float32'),
"y": np.random.randint(2, size=(128, 1)).astype('int64')}
input_x = fluid.layers.data(name="x", shape=[32], dtype='float32')
input_y = fluid.layers.data(name="y", shape=[1], dtype='int64')
# 定义损失
cost = mlp(input_x, input_y)
optimizer = fluid.optimizer.SGD(learning_rate=0.01)3.定义训练策略和集群环境定义
# 区别2: 定义训练策略和集群环境定义
dist_strategy = DistributedStrategy()
role = role_maker.PaddleCloudRoleMaker(is_collective=True)
fleet.init(role)
# 获得当前gpu的id号
gpu_id = int(os.getenv("FLAGS_selected_gpus", "0"))
print(gpu_id)
place = fluid.CUDAPlace(gpu_id)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())这里通过dist_strategy = DistributedStrategy()初始化了分布式策略;通过role_maker.PaddleCloudRoleMaker()设置了分布式角色信息。(示例中给出的PaddleCloudRoleMaker()比较方便,无需用户手动设置环境信息。一般的,如果使用role_maker.UserDefinedRoleMaker()时,则需要用户自定义节点的角色信息,IP和端口信息) 通过fleet.init(role)启动了fleet进程;
4.定义分布式optimizer
通常,分布式情况下需要使用框架提供的分布式optimizer接口对原有optimizer进行封装。因为通常在数据并行模式(同步)下,需要将各个机器节点上的梯度发送至master机器节点,进行汇总求和,之后经分布式optimizer处理更新梯度后,将新的模型参数广播至各机器节点。
# 区别3: 对optimizer封装,并调用封装后的minimize方法
optimizer = fleet.distributed_optimizer(optimizer, strategy=DistributedStrategy())
optimizer.minimize(cost, fluid.default_startup_program())
train_prog = fleet.main_program5.训练和模型保存
经过上面几步处理后,就可以开始分布式训练了,训练的大体过程和单机类似:
# 获得当前gpu的id号
gpu_id = int(os.getenv("FLAGS_selected_gpus", "0"))
print(gpu_id)
place = fluid.CUDAPlace(gpu_id)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
step = 100
for i in range(step):
cost_val = exe.run(program=train_prog, feed=gen_data(), fetch_list=[cost.name])
print("step%d cost=%f" % (i, cost_val[0]))
# 区别4: 模型保存
model_path = "./"
if os.path.exists(model_path):
fleet.save_persistables(exe, model_path)基于paddle.fluid接口,利用ResNet50网络训练ImageNet的示例可参考:PaddlePaddle官方仓库(https://github.com/PaddlePaddle/models/tree/release/1.8/PaddleCV/image_classification)
分布式训练速度测评及结果,可以参考DLPerf:PaddlePaddle-ResNet50V1.5测评(https://github.com/Oneflow-Inc/DLPerf/tree/master/PaddlePaddle/resnet50v1.5)
基于Paddle分布式Fleet API,将单机的训练代码改造成分布式,可以参考:多机多卡训练(https://www.paddlepaddle.org.cn/tutorials/projectdetail/479613)
4.MXNet
MXNet(https://github.com/apache/incubator-mxnet/)是一个相对(pytorch、tensorflow)小众、轻量级且性能优异的深度学习框架,除了常见的python接口外,还提供了 R、Julia、C++、Scala、Matlab等接口,也是比较早就提供了对分布式深度学习任务的支持,可通过ps-lite,Horovod和BytePS等方式支持多GPU和分布式训练。
概念
Worker Server Scheduler MXNet支持数据并行和单机情况下的模型并行,尚未支持分布式多机情况下的模型并行。在MXNet的分布式训练中有3个比较重要的角色:
Worker
Server
Scheduler
worker,server,scheduler三者共同协作,完成模型的分布式训练过程。其中,worker是分布式训练的执行单元,在分布式训练处理每个batch前,worker会从server处拉取最新的权重,其次worker还可以在每个batch训练结束后将梯度发送至server处;server顾名思义是服务器单元,用于存储模型参数并和各个worker进行通信;scheduler的作用是建立集群,管理节点和端口监听。
MXNet中还用到了key-value store(KVStore)即键值存储的概念。在分布式训练过程中,一个或多个server通过KVStore存储了worker训练过程中产生的参数,其中模型网络中,每个参数数组分配一个key,而value则存储了其权重,worker通过pull和push来更新参数的权重。在编译MXNet时,需添加build flag:USE_DIST_KVSTORE=1 以使MXNet支持分布式训练。
KVStore
KVStore服务器支持两种工作模式:
1.聚合梯度但不应用更新
2.聚合梯度且更新权重
模式1表示server仅聚合各个worker的梯度,但是并不应用更新梯度;模式2表示聚合各worker的梯度且应用这些梯度进行权重更新。创建gluon.Trainer时,可以通过参数update_on_kvstore=False或True来分别开启这两种工作模式。
NCCL+CUDA支持
为了在NVIDIA显卡设备上获得更好的性能,需要在源码构建MXNet时添加CUDA支持,build时需要添加USE_CUDA构建项;同样,为了使用NVIDIA集合通信库NCCL,需要添加USE_NCCL构建项
参考:
https://mxnet.cdn.apache.org/versions/1.7.0/api/faq/distributed_traininghttps://mxnet.apache.org/get_started/build_from_source
分布式示例
下面,我们以MXNet官方仓库里的ResNet50分布式训练为例,简单讲解下MXNet分布式训练相关方法和参数。初始化horovod 在此仓库的实现中,分布式训练是通过train_horovod.py 完成。训练前,需要先初始化horovod,初始化后可以通过hvd.size()、hvd.rank()、hvd.local_rank()等查看horovod协调的计算资源。源码141行:
# Horovod: initialize Horovod
hvd.init()
num_workers = hvd.size()
rank = hvd.rank()
local_rank = hvd.local_rank()num_workers,即当前节点上horovod工作进程数量,通常等于GPU数量;
rank = hvd.rank(),是一个全局GPU资源列表;
local_rank = hvd.local_rank()是当前节点上的GPU资源列表;
譬如有4台节点,每台节点上4块GPU,则num_workers的范围为0~15,local_rank为0~3
同步模型参数
分布式的模型创建和多机类似,区别在于,使用horovod时,需要通过hvd.broadcast_parameters 将当前节点模型参数“广播”出去,即将模型权重同步至各个节点。源码374行:
# Fetch and broadcast parameters
params = model.collect_params()
if params is not None:
hvd.broadcast_parameters(params, root_rank=0)切分数据集
分布式训练时,和单机训练一样,都是通过gluon.data.DataLoader来完成数据加载,区别在于分布式情况下,需要提前用SplitSampler来对train_data、val_data的数据进行切分。源码241行:https://github.com/dmlc/gluon-cv/blob/f9a8a284b8222794bc842453e2bebe5746516048/scripts/classification/imagenet/train_horovod.py#L241
train_sampler = SplitSampler(len(train_set), num_parts=num_workers, part_index=rank)
train_data = gluon.data.DataLoader(train_set, batch_size=batch_size,# shuffle=True,
last_batch='discard', num_workers=data_nthreads,
sampler=train_sampler)分布式Trainer
分布式训练时,需要使用hvd.DistributedTrainer创建trainer,此trainer是gluon.Trainer的子类 源码389行:(https://github.com/dmlc/gluon-cv/blob/f9a8a284b8222794bc842453e2bebe5746516048/scripts/classification/imagenet/train_horovod.py#L389)
# Horovod: create DistributedTrainer, a subclass of gluon.Trainer
trainer = hvd.DistributedTrainer(params, opt)
if args.resume_states != '':
trainer.load_states(args.resume_states)后面的代码就和单机训练差不多了,此处不再赘述。MXNet训练ResNet50的完整代码示例可参考:gluon官方仓库(https://github.com/dmlc/gluon-cv/blob/f9a8a284b8222794bc842453e2bebe5746516048/scripts/classification/imagenet/train_horovod.py),仓库里也提供了正常(非分布式)情况下的imagenet训练代码:train_imagenet.py,可以用于和分布式训练代码train_horovod.py做比较;
分布式训练速度测评及结果,可以参考DLPerf:MXNet ResNet50 测评(https://github.com/Oneflow-Inc/DLPerf/tree/master/MxNet/Classification/RN50v1b)
5.OneFlow
看过上述框架中的分布式代码示例,是不是觉得很复杂?或许你也会疑惑。
为什么单机版的代码/api不能应用到多机?
为什么还要手动管理数据集切分、分布式optimizer、参数更新这些脏活累活?
难道没有一种框架屏蔽掉单机和分布式代码的差异,让我们愉快地写代码?

答案是:YES
不吹不黑的说一句,OneFlow确实就是这样的框架,满足你对分布式训练的所有需求:
单机/分布式下,共用一套接口(是真的共用,而不是外面一套,内部却有其各自的实现)
单机/分布式下,无需操心数据切分;
单机/分布式下,无需操心optimizer梯度更新、参数状态同步等问题;
单机/分布式下,性能最强(对GPU利用率最高),训练速度最快;
那么问题来了: 1.为什么能做到单机/分布式如此简单?

2.OneFlow分布式这么容易用,运行效率怎么样?

1.为什么能做到单机/分布式如此简单?
实际上,oneflow中天然支持分布式(数据并行、模型并行、流水并行),使用oneflow进行分布式训练完全不需要修改已有代码,也不需要安装horovod、dali、nccl、openmpi等一系列的支撑库,因为oneflow独特的底层架构设计,使得其在单机和分布式情况下,已经达到其他框架各种优化后的上限。
oneflow对分布式的天然支持来源于其底层设计:抛弃了传统的master/worker架构,而是一种去中心化的流式架构,而这种架构带来的优势也比较明显:1.采用去中心化的流式架构,而非 maste/worker 架构,最大程度优化节点网络通信效率 2.极简配置,由单一节点的训练程序转变为分布式训练程序,只需要几行配置代码
更多oneflow底层设计、actor机制等请参考:OneFlow官方文档—分布式训练(https://docs.oneflow.org/basics_topics/distributed_train.html) ;OneFlow官方文档—系统设计(https://docs.oneflow.org/basics_topics/essentials_of_oneflow.html)
2.OneFlow分布式这么容易用,运行效率怎么样?
我们为了比较各大深度学习框架在单机、分布式情况下,对主流模型的训练速度,特意发起了一个性能评测项目——DLPerf(https://github.com/Oneflow-Inc/DLPerf),项目目前在保证软硬件一致的情况下,对各大主流框架在主流模型上做了训练性能测试(CV领域经典模型ResNet50;NLP领域Bert)。同时,我们有一帮小伙伴对cuda kernel等方面做了极致的性能优化,最终的测试结果表明,综合情况下OneFlow不仅单机单卡速度最快,单机多卡、多机多卡时也最快,加速比最高。
关于DLPerf评测的详细数据和信息,请看报告:dlperf_benchmark_test_report_v1 (https://github.com/Oneflow-Inc/DLPerf/blob/master/reports/dlperf_benchmark_test_report_v1_cn.md)关于OneFlow为什么能做到最快,性能优化的绝招,请看知乎文章:OneFlow是如何做到世界最快深度学习框架的(https://zhuanlan.zhihu.com/p/271740706)
概念
由于OneFlow独特的底层设计,其并没有为分布式任务设立单独的接口/方法。由于其天然支持分布式,所以也没有单独的概念用于描述分布式,如果必须有,那就是去中心化的Actor、以及SBP机制,更详细的概念描述,请参考:OneFlow系统设计(https://docs.oneflow.org/basics_topics/essentials_of_oneflow.html)和OneFlow概念清单(https://docs.oneflow.org/basics_topics/concept_explanation.html)
分布式示例
在对比多个框架的分布式用法后,我们发现OneFlow的分布式最简单易用,因为其设计的出发点就是追求分布式性能及易用性。所以,在OneFlow中,无论是单机单卡、单机多卡、还是多机多卡,都是一套统一的代码(无需额外的分布式接口、无需修改原有的模型训练相关代码)。
对于上层用户,使用oneflow进行分布式进行却异常简单,实际上,在oneflow中无需改动原有代码,只需要简单的几行配置,即可完美支持分布式训练,下面我们看一下示例。
单机
只需要在开头,加入单机需使用的GPU数即可。如:
# 单机单卡
flow.config.gpu_device_num(1)
# 单机8卡
flow.config.gpu_device_num(8)分布式
分布式几乎和单机配置一样,无需操心多机情况下的数据切分,optimizer设置、权重同步等问题,只需额外增加3行代码用于配置多机的ip信息、通信端口号即可:
#每个节点的 gpu 使用数目
flow.config.gpu_device_num(8)
# 通信节点ip
nodes = [{"addr":"192.168.1.12"}, {"addr":"192.168.1.11"}]
flow.env.machine(nodes)
#通信端口
flow.env.ctrl_port(9988)以下,是完整的分布式训练代码示例:
# see : http://docs.oneflow.org/basics_topics/distributed_train.html#_5
import oneflow as flow
import oneflow.typing as tp
BATCH_SIZE = 100
def mlp(data):
initializer = flow.truncated_normal(0.1)
reshape = flow.reshape(data, [data.shape[0], -1])
hidden = flow.layers.dense(
reshape,
512,
activation=flow.nn.relu,
kernel_initializer=initializer,
name="hidden",
)
return flow.layers.dense(
hidden, 10, kernel_initializer=initializer, name="output-weight"
)
def config_distributed():
print("distributed config")
# 每个节点的gpu使用数目
flow.config.gpu_device_num(8)
# 通信端口
flow.env.ctrl_port(9988)
# 节点配置
nodes = [{"addr": "192.168.1.12"}, {"addr": "192.168.1.11"}]
flow.env.machine(nodes)
@flow.global_function(type="train")
def train_job(
images: tp.Numpy.Placeholder((BATCH_SIZE, 1, 28, 28), dtype=flow.float),
labels: tp.Numpy.Placeholder((BATCH_SIZE,), dtype=flow.int32),
) -> tp.Numpy:
logits = mlp(images)
loss = flow.nn.sparse_softmax_cross_entropy_with_logits(
labels, logits, name="softmax_loss"
)
lr_scheduler = flow.optimizer.PiecewiseConstantScheduler([], [0.1])
flow.optimizer.SGD(lr_scheduler, momentum=0).minimize(loss)
return loss
if __name__ == "__main__":
config_distributed()
flow.config.enable_debug_mode(True)
check_point = flow.train.CheckPoint()
check_point.init()
(train_images, train_labels), (test_images, test_labels) = flow.data.load_mnist(
BATCH_SIZE, BATCH_SIZE
)
for epoch in range(1):
for i, (images, labels) in enumerate(zip(train_images, train_labels)):
loss = train_job(images, labels)
if i % 20 == 0:
print(loss.mean())完整的利用ResNet50训练ImageNet的示例可参考:OneFlow官方Benchmark仓库(https://github.com/Oneflow-Inc/OneFlow-Benchmark/tree/637bb9cdb4cc1582f13bcc171acbc8a8089d9435/Classification/cnns)
分布式训练速度测评及结果,可以参考DLPerf:【DLPerf】OneFlow Benchmark评测(https://github.com/Oneflow-Inc/DLPerf/tree/master/OneFlow)
6.分布式训练常用库
通常,算法开发者使用深度学习框架开发出模型的训练/预测任务是单机版的,即只能在单机单卡、单机多卡条件下正常工作。当需要分布式训练时,我们通常需要进行如下三个层面的工作:
数据层面
多机通讯层面
代码层面
在数据层面,我们可以使用DALI(非必须)来加速数据预处理过程;在多机通讯层面,需要安装和使用nccl、openmpi、gloo等作为底层的集合通信库;在代码层面,我们需要使用框架提供的分布式API或者使用Horovod来对单机版(单机单卡/多卡)代码进行改造,以使其支持分布式任务。
下面,我们对这些常用库进行简单的介绍和安装说明
6.1 DALI
DALI(https://developer.nvidia.com/DALI)是NVIDIA提供的库,有较为先进的内存管理技术,可以构建基于CPU/GPU的高效数据加载pipeline,使得数据预处理速度大大提高。
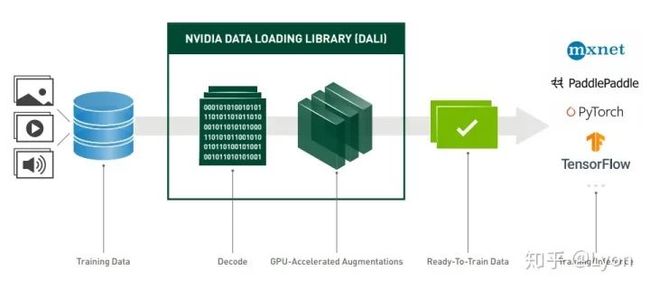
通常,对于数据集规模较大(如imagenet等)的任务,或数据预处理成为瓶颈的任务,使用DALI后加速效果明显。不过在使用DALI基于GPU对图片进行解码/预处理时,通常需要占用较高的GPU显存。
安装
# CUDA 10
pip install --extra-index-url https://developer.download.nvidia.com/compute/redist nvidia-dali-cuda100
# CUDA 11
pip install --extra-index-url https://developer.download.nvidia.com/compute/redist nvidia-dali-cuda110使用
DALI提供了多框架支持、可基于CPU/GPU构建自己的数据加载pipeline,相关学习资源和使用方式参考:
DALI Home
https://developer.nvidia.com/DALI
Fast AI Data Preprocessing with NVIDIA DALI
https://developer.nvidia.com/blog/fast-ai-data-preprocessing-with-nvidia-dali/
DALI Developer Guide
https://docs.nvidia.com/deeplearning/dali/user-guide/docs/index.html
Getting Started
https://docs.nvidia.com/deeplearning/dali/user-guide/docs/examples/getting%20started.html
nvidia-dali-speeding-up-pytorch
https://towardsdatascience.com/nvidia-dali-speeding-up-pytorch-876c80182440
6.2 NCCL
NCCL是英伟达基于NCIDIA-GPU的一套开源的集合通信库,如其官网描述:NVIDIA集合通信库(NCCL)实现了针对NVIDIA GPU性能优化的多GPU和多节点集合通信原语。NCCL提供了诸如all-gather, all-reduce, broadcast, reduce, reduce-scatter等实现,这些实现优化后可以通过PCIe和NVLink等高速互联,从而实现高带宽和低延迟。因为NCCL则是NVIDIA基于自身硬件定制的,能做到更有针对性且更方便优化,故在英伟达硬件上,NCCL的效果往往比其它的通信库更好。
在大多数情况下,NCCL(https://developer.nvidia.com/nccl)作为底层的集合通信库为分布式深度学习框架提供了多机通讯能力、我们只要安装即可,在分布式深度学习相关的任务或代码中通常感知不到其存在。除深度学习框架以外、Horovod通常也依赖nccl作为底层的集合通信库。
更多关于NCCL和集合通信相关的介绍,请参考上一篇文章:【深度学习】— 分布式训练常用技术简介(https://zhuanlan.zhihu.com/p/276122469)
安装
需要从NVIDIA-NCCL官网下载并安装和操作系统、CUDA版本适配的NCCL。如Ubuntu16.04、CUDA10.2版本可以通过如下命令安装NCCL:
sudo dpkg -i nccl-repo-ubuntu1604-2.7.3-ga-cuda10.2_1-1_amd64.deb
sudo apt update
sudo apt install libnccl2=2.7.3-1+cuda10.2 libnccl-dev=2.7.3-1+cuda10.2使用
通常,我们在深度学习任务中无需手动使用NCCL。但是,可以通过设定相应变量来查看/更改NCCL的设定,如打印NCCL相关的日志信息:
export NCCL_DEBUG=INFO
export NCCL_DEBUG=WARN指定NCCL使用enp开头类型的网卡进行通信:
export NCCL_SOCKET_IFNAME=enp更多NCCL相关的环境变量设置,请参考:
NCCL官方文档——故障排除
https://docs.nvidia.com/deeplearning/nccl/archives/nccl_273/user-guide/docs/troubleshooting.html
NCCL官方文档——环境变量
https://docs.nvidia.com/deeplearning/nccl/archives/nccl_273/user-guide/docs/env.html
6.3 Horovod
在文章的前半部分也说过:
我们需要使用框架提供的分布式API或者使用Horovod来对单机版(单机单卡/多卡)代码进行改造,以使其支持分布式任务。
刚刚在上面提到的各个框架,他们都提供了原生的接口解决分布式环境下的通信问题。在上一篇文章中我们也介绍了,各个框架底层采用的通信库几乎都是NCCL、Open MPI 等少数几种。但是各个框架对于通信的利用水平可能层次不齐,某些情况下,因为框架自身的设计和代码实现的问题,使得底层集合通信库(如nccl)的能力无法充分发挥。
Horovod作为第三方库,就是想为各个分布式框架解决此问题,因为其易用和高效,可以说,Horovod(https://github.com/horovod/horovod)已经是最流行的用于支持分布式深度学习任务的开源项目。其支持多种深度学习框架如:pytorch,tensorflow,mxnet等,其底层机器间通讯依赖nccl、mpi、gloo等集合通信库,所以安装前通常需要先安装好nccl、openmpi,且至少安装了一种深度学习框架,譬如mxnet。
安装
通常,安装horovod需要经过如下步骤:
1.安装NCCL
2.安装nv_peer_memory(https://github.com/Mellanox/nv_peer_memory)以提供GPUDirect RDMA支持
3.安装Open MPI或者其他MPI实现
4.安装horovod
详细的安装说明参考Horovod官方项目readme(https://github.com/horovod/horovod/blob/master/docs/gpus.rst),下面假设各种依赖已经安装完成,可以通过下面命令安装支持MXNet的horovod:
HOROVOD_WITH_MXNET=1 HOROVOD_GPU_OPERATIONS=NCCL HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_GPU_BROADCAST=NCCL使用
上面MXNet的分布式示例中,我们简单介绍了horovod分布式训练的一些概念,下面,我们以pytorch为例,介绍一下使用horovod将单机代码改造为分布式代码时更通用的一些步骤:
1.初始化horovod
通过hvd.init()来初始化horovod主进程。
import torch
import horovod.torch as hvd
# Initialize Horovod
hvd.init()2.将horovod进程和gpu绑定
通常,一个gpu绑定到1个horovod进程,此进程称为一个worker。
# Pin GPU to be used to process local rank (one GPU per process)
torch.cuda.set_device(hvd.local_rank())3.切分数据集
在同步数据并行的分布式训练时,需要感觉gpu数量对数据集进行切分。
# Define dataset...
train_dataset = ...
# Partition dataset among workers using DistributedSampler
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset, num_replicas=hvd.size(), rank=hvd.rank())
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)4.构建分布式optimizer
将原有的optimizer通过hvd.DistributedOptimizer进行包装、以使得新的optimizer可以在分布式环境下应用梯度更新。
# Build model...
model = ...
model.cuda()
optimizer = optim.SGD(model.parameters())
# Add Horovod Distributed Optimizer
optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters())5.广播模型参数
多机上的模型权重,通常通过_allreduce_、_allgather _等方式在root_rank=0的主节点所在机器上汇合,汇合后需要将主节点上的模型权重信息广播至各台机器,以同步模型。
# Broadcast parameters from rank 0 to all other processes.
hvd.broadcast_parameters(model.state_dict(), root_rank=0)更完整的使用说明,请参考horovod官方文档(https://github.com/horovod/horovod/blob/master/docs/pytorch.rst)
2.分布式常见问题汇总(踩坑指南)
通过以上的介绍,相信你已经具备了进行分布式训练的能力,在刚参与 DLPerf 时,我也是这样想的,直到多次跪倒在实际训练中。分布式训练本身也是各复杂工程,遇到的问题不难,但是可能因为第一次遇见而耽误进度很久。为了避免大家重蹈我的覆辙,特总结了一些经验教训,欢迎参考和补充。
2.1 精确到commit
通常,github上的代码和框架版本是脱节的,用最新版的框架往往运行之前的github项目代码时会各种报错;反之亦然。原因很简单:首先,各个框架存在不同版本;其次,项目代码也在不断维护和更新。
我们需要复现一个项目,首先需要熟读项目的readme,然后精确地匹配到对应的commit,保证代码版本和框架版本相匹配,才能将由于代码/框架版本不匹配导致各种问题的概率降至最低。
2.2 使用具体到版本的库/依赖
在安装python依赖库时,有时官方没有提供requirement.txt,这时可能运行时会各种报错(缺少各种库和依赖);当你发现官方提供了requirement.txt时,通常直接pip install -r requirement.txt即可,少数情况下还是会有各种坑,譬如requirement.txt没有指定库的具体版本,但是pip install时往往安装的是最新版的库,而最新版方法/api有更新,所以项目跑起来,还是会各种报错...这时,最坏的可能是:手动一个版本一个版本的试,直到安装上版本相匹配的库为止~
2.2 多机问题
多机情况下常见的问题主要有:
horovod/mpi多机运行失败
docker环境下ssh连通问题
多机没连通/长时间卡住没反应
多机下速度提升不明显,加速比低的问题
下面,我们将总结一下遇到这些问题的常见原因,以及归纳一下通常的解决方式。
2.2.1 horovod/mpi多机运行失败
通常,通过horovod/mpi运行分布式深度学习任务前,需要提前在节点之间配置ssh免密登录,保证用于通信的端口可以互相连通。如:
# export PORT=10001
horovodrun -np ${gpu_num} \
-H ${node_ip} -p ${PORT} \
--start-timeout 600 \
python3 train.py ${CMD} 2>&1 | tee ${log_file}
# 或者:
mpirun --allow-run-as-root -oversubscribe -np ${gpu_num} -H ${node_ip} \
-bind-to none -map-by slot \
-x LD_LIBRARY_PATH -x PATH \
-mca pml ob1 -mca btl ^openib \
-mca plm_rsh_args "-p ${PORT} -q -o StrictHostKeyChecking=no" \
-mca btl_tcp_if_include ib0 \
python3 train.py ${CMD} 2>&1 | tee ${log_file}需要保证节点间ssh可以通过默认22端口或者指定端口如:10001互相连通。如:ssh vs002或ssh vs002 \-p 10001
2.2.2 docker容器连通问题
如果是在docker容器中进行多机训练,需要保证docker容器间可以通过指定端口互相ssh免密登录。(如:在10.11.0.2节点的docker容器内可以通过ssh [email protected] -p 10001可以直接登录10.11.0.3节点的docker容器)
而在docker容器启动时,有两种网络方式:
docker的host模式
docker的bridge模式
docker的host模式
host模式,需要通过docker run时添加参数 --net=host 指定,该模式下表示容器和物理机共用端口(没有隔离),需要修改容器内ssh服务的通信端口号(vim /etc/ssh/sshd_config),用于docker容器多机通讯,具体方式见:README—SSH配置(https://github.com/Oneflow-Inc/DLPerf/tree/master/NVIDIADeepLearningExamples/TensorFlow/Classification/ConvNets/resnet50v1.5#ssh%E9%85%8D%E7%BD%AE%E5%8F%AF%E9%80%89)
docker的bridge模式
即docker的默认模式。该模式下,容器内部和物理机的端口是隔离的,可以通过docker run时增加参数如:-p 9000:9000进行端口映射,表明物理机9000端口映射到容器内9000端口,docker容器多机时即可指定9000端口进行通信。
两种方式都可以,只要保证docker容器间能通过指定端口互相ssh免密登录即可。
2.2.3 多机没连通/长时间卡住没反应
通信库没有正确安装
存在虚拟网卡,nccl需指定网卡类型
通信端口被占用
通信库没有正确安装
通常是没有正确地安装多机依赖的通信库(openmpi、nccl)所导致。譬如paddle、tensorflow2.x等框架依赖nccl,则需要在每个机器节点上安装版本一致的nccl,多机训练时,可以通过export NCCL_DEBUG=INFO来查看nccl的日志输出。
openmpi安装
官网:https://www.open-mpi.org/software/ompi/v4.0/
wget https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-4.0.0.tar.gz
gunzip -c openmpi-4.0.0.tar.gz | tar xf -
cd openmpi-4.0.0
sudo ./configure --prefix=/usr/local/openmpi --with-cuda=/usr/local/cuda-10.2 --enable-orterun-prefix-by-default
sudo make && make installmake时,若报错numa相关的.so找不到:
sudo apt-get install libnuma-dev添加到环境变量
vim ~/.bashrc
export PATH=$PATH:/usr/local/openmpi/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/openmpi/lib
source ~/.bashrchorovod安装
官网:https://github.com/horovod/horovod
HOROVOD_GPU_OPERATIONS=NCCL python -m pip install --no-cache-dir horovod存在虚拟网卡,nccl需指定网卡类型 有时,nccl已经正常安装,且节点间可以正常ssh免密登录,且都能互相ping通,不过还是遭遇多机训练长时间卡住的问题,可能是虚拟网卡的问题,当存在虚拟网卡时,如果不指定nccl变量,则多机通信时可能会走虚拟网卡,而导致多机不通的问题。 如下图:

NCCL WARN Connect to fe80::a480:7fff:fecf:1ed9%13<45166> failed : Network is unreachable表明多机下遭遇了网络不能连通的问题。具体地,是经过网卡:fe80::a480:7fff:fecf...通信时不能连通。
我们排查时,通过在发送端ping一个较大的数据包(如ping -s 10240 10.11.0.4),接收端通过bwm-ng命令查看每个网卡的流量波动情况(找出ping相应ip时,各个网卡的流量情况),发现可以正常连通,且流量走的是enp类型的网卡。
通过ifconfig查看当前节点中的所有网卡类型:
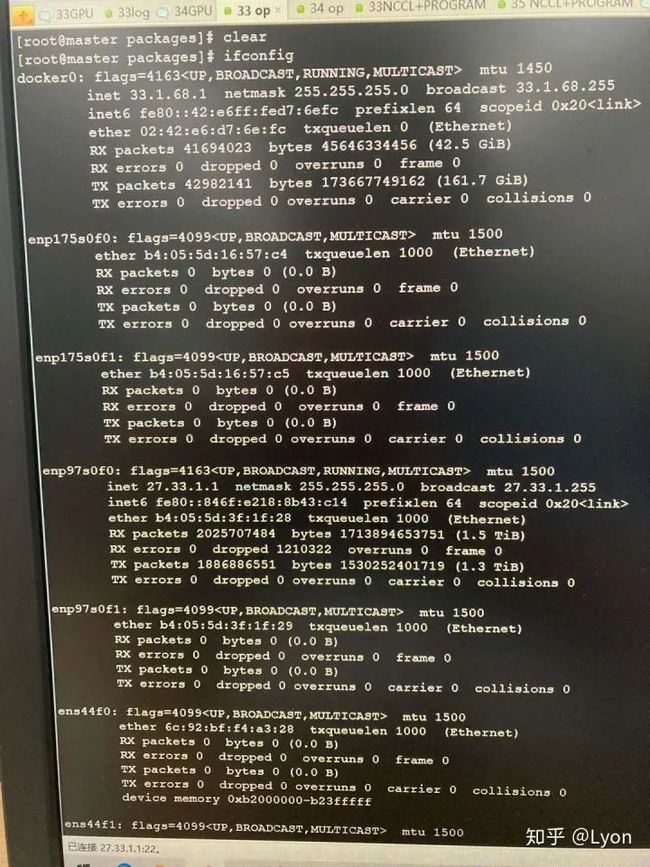
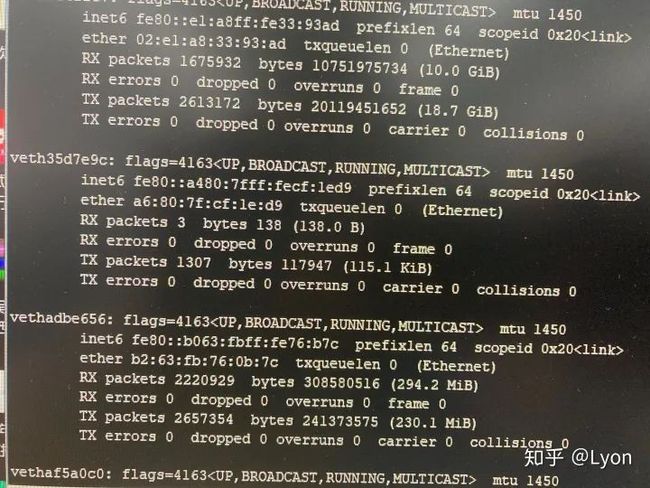
可以发现有很多enp开头的网卡,也有很多veth开头的虚拟网卡,而nccl日志输出中的:fe80::a480:7fff:fecf:1ed9是veth虚拟网卡。
通过查看nccl官网文档发现,我们可以通过指定nccl变量来设定nccl通信使用的网卡类型:
export NCCL_SOCKET_IFNAME=enp2.2.4 加速比低
IB驱动安装
如果服务器之间支持IB(InfiniBand)网络,则可以安装IB驱动,使得多机情况下各个节点间的通信速率明显提升,从而加速框架在多机环境下的训练,提升加速比。可以从NVIDIA官网下载适合操作系统及相应版本的IB驱动包,然后进入源码包路径,并安装:
cd MLNX_OFED_LINUX-4.9-0.1.7.0-ubuntu18.04-x86_64 && ./mlnxofedinstall --user-space-only --without-fw-update --all --force完成后,可以通过ibstat命令检查驱动是否安装成功。更详细的IB驱动安装,请参考:mellanox官方文档(https://community.mellanox.com/s/article/howto-install-mlnx-ofed-driver)
horovod/mpi参数设置
通常使用horovod只需要设定较少的参数,典型的参数:-np表示总共使用的gpu数量;-H表示所有机器节点及各个节点上使用的gpu数量。例如,一个集群包含4台机器(server1~4),每台机器上有4块gpu,则典型的horovod运行命令如下:
horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py更多命令和使用方法,参考Horovod官方仓库(https://github.com/horovod/horovod)。
使用mpi运行分布式任务时(如openmpi),通常可以控制的参数更多、粒度更细,如:
mpirun -oversubscribe -np ${gpu_num} -H ${nodes} \
-bind-to none -map-by numa \
-x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH \
-mca pml ob1 -mca btl ^openib \
-mca plm_rsh_args "-p 22 -q -o StrictHostKeyChecking=no" \
-mca btl_tcp_if_include ib0 \
python3 ${WORKSPACE}/run_pretraining.py更多参数及使用说明,参考openmpi官网(https://www.open-mpi.org/)。
没有使用dali
有时,不使用dali时数据加载/预处理会成为瓶颈,即gpu总是很快完成训练,“空闲”在那里等待cpu对数据进行加载/预处理,此时使用dali可以明显加速此过程。
数据读取线程数设置不合理
通常,在深度学习任务中,框架提供了参数如--num_thread来设定数据加载/处理的线程数,线程数的设定影响了数据加载/处理的速度,进而影响了训练的速度。程数过低时,数据加载/预处理会成为瓶颈,训练速度收到影响变的很慢;线程数过高时,线程间同步/切换的开销过大,同样会影响训练速度;故通常需要根据经验值合理设定数据加载线程数。
2.4 查看GPU拓扑
在分布式深度学习任务中,除了深度学习框架、集合通信库、代码层面的等软件层面,硬件层面的如cpu、gpu显存、内存容量、网卡速率、gpu拓扑等对训练速度也是很有影响。譬如,我们可以通过nvidia-smi topo -m命令查看某机器上的gpu拓扑:

可以看出,此台机器包含8块GPU(GPU0~7),mlx5_0是Mellanox ConnectX-4 PCIe网卡设备(10/25/40/50千兆以太网适配器,另外该公司是IBA芯片的主要厂商)。图的上半部分表示GPU间的连接方式,如gpu1和gpu0通过NV1互联,gpu4和gpu1通过SYS互联;图的下半部分为连接方式的具体说明,如NV表示通过nvlink互联,PIX通过至多一个PCIe网桥互联。
在图的下半部分,理论上GPU间的连接速度从上到下依次加快,最底层的NV表示通过nvlink互联,速度最快;最上层SYS表示通过pcie以及穿过NUMA节点间的SMP互联(即走了PCie又走了QPI总线),速度最慢。
NV表示通过NVIDIA-nvlink互联,速度最快;
PIX表示GPU间至多通过一个PCIe网桥连接;
PHB表示通过PCIe和PCIe主网桥连接(通常PCIe 主网桥是存在于cpu之中,所以PHB可以理解为通过PCIe和cpu相连);
NODE表示通过PCIe以及NUMA节点内PCIe主网桥之间的互连(通常NUMA节点内,包含多个cpu节点,每个cpu节点都包含一个PCIe主网桥,所以NODE可以理解为在一个NUMA节点内,通过PCIe和多个CPU相连);
SYS表示通过PCIe以及NUMA节点之间的SMP互连(例如,QPI/UPI),这个可以理解为通过PCIe,且跨过多个NUMA节点及其内部的SMP(多个cpu节点)进行互联。
X表示gpu节点自身;
关于NUMA,SMP等服务器结构的简单介绍可参考:服务器体系(SMP, NUMA, MPP)与共享存储器架构(UMA和NUMA)
https://blog.csdn.net/gatieme/article/details/52098615
最后,再强烈安利一下DLPerf项目(https://github.com/Oneflow-Inc/DLPerf),该项目在相同软硬件条件下,对各个框架在单机单卡、单机多卡、多机多卡条件下进行了模型训练的性能测试。测试覆盖了CV、NLP领域经典模型,保证了模型对齐、参数对齐、相同数据集(以各自框架要求的为准),测试结果精准反应了各个框架在模型训练任务中的速度(吞吐率)、以及多机条件下的表现(加速比)。
好消息!
小白学视觉知识星球
开始面向外开放啦

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~