RabbitMQ中延迟队列的全方位解析
前言
工作中有些场景需要用到延迟队列,大概对RabbitMQ延迟队列场景有一些了解,网上大部分的场景应用于:订单超时、定时执行等。
而我需要延迟队列的场景是:有一批机器需要监控这个延迟队列长度,一旦满足就提前预备机器,准备执行任务。通过监控延迟队列,我可以准确、可靠的清楚,接下来的某个时间我一定会执行哪些任务。相较于传统通过API来唤醒设备,提升了稳定性。我只需要关注一点:发布消息。
同时也了解到,大部分使用RabbitMQ实现延迟队列从两个方向入手:
- 死信队列+TTL
- 延迟队列插件
接下来,我将会从这两个方向逐一进行,分析利弊。
阅读本文,你将获得:
- 死信队列的场景化使用
- 队列TTL及消息TTL出现的各种问题解决
- RabbitMQ在docker下插件安装
- 完整的Python实现源代码
死信队列
通过死信队列来解决延迟队列给人的感觉是「曲线救国」的方案,因为在原生RabbitMQ中并不直接支持延迟队列。其原理就是把消息发给一个中间队列,这个中间队列预设了TTL过期时间,并绑定了死信队列和死信交换机,当中间队列的消息过期时,就会发送到死信队列中。届时,死信队列就充当了延迟队列。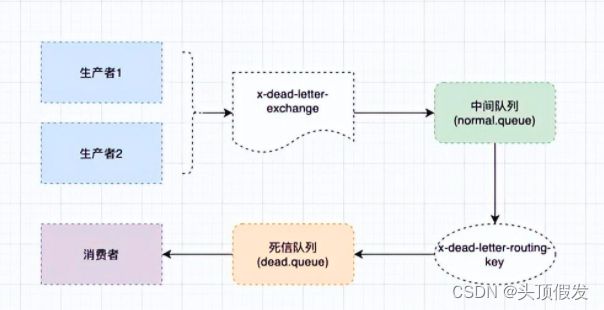
Python代码如下:
# -*- coding: utf-8 -*-
from mq import channel
DEAD_EXCHANGE_NAME = 'dead.exchange'
DEAD_QUEUE_NAME = 'dead.queue'
DEAD_ROUTING_KEY = 'dead.routing.key'
QUEUE_NAME = 'normal.queue'
# 声明死信交换机
channel.exchange.declare(DEAD_EXCHANGE_NAME, exchange_type="direct")
# 声明死信队列
channel.queue.declare(DEAD_QUEUE_NAME, durable=True)
# 死信队列绑定死信交换机和死信路由
channel.queue.bind(
queue=DEAD_QUEUE_NAME,
exchange=DEAD_EXCHANGE_NAME,
routing_key=DEAD_ROUTING_KEY,
)
# 声明正常队列,并绑定死信交换机和死信路由,约束队列TTL为10秒
arguments = {
"x-dead-letter-exchange": DEAD_EXCHANGE_NAME,
"x-dead-letter-routing-key": DEAD_ROUTING_KEY,
"x-message-ttl": 10 * 1000
}
channel.queue.declare(
QUEUE_NAME, durable=True, arguments=arguments
)
接下来,我们将对正常的中间队列发一个测试消息,并且监控死信队列,也就是我们的延迟队列。
# 往正常队列发送一个测试消息
channel.basic.publish("test_message", QUEUE_NAME)
# 监控死信队列(延迟队列)
for idx in range(0, 99):
time.sleep(1)
print("第[{}]次尝试获取...".format(idx + 1))
message = channel.basic.get(DEAD_QUEUE_NAME)
if message:
print("获取到死信消息:{}".format(message.body))
break
第[1]次尝试获取...
第[2]次尝试获取...
第[3]次尝试获取...
...
第[10]次尝试获取...
获取到死信消息:test_message
问题:不同消息不同延迟
通过对队列设置TTL,我们实现了一个基础版的延迟队列功能,但是目前还存在一个问题,由于我们的TTL是预设在队列上的,一旦业务变化,我得需要多个不同的TTL,那与之产生的问题就是我得基于这个模式,新建多个中间队列,每个队列代表不同的TTL,然后不同的延迟消息发往不同的队列。
为解决这个问题,我们可以尝试将TTL的属性挂载到消息上。
channel.basic.publish(
"test_message",
QUEUE_NAME,
properties={"expiration": "3000"}
)
第[1]次尝试获取...
第[2]次尝试获取...
第[3]次尝试获取...
获取到死信消息:test_message
问题:消息TTL超过队列TTL
又发现问题:如果自定义消息TTL==超过==队列TTL,则优先触发最小值。
channel.basic.publish(
"test_message",
QUEUE_NAME,
properties={"expiration": "13000"} # 超过队列TTL
)
第[1]次尝试获取...
第[2]次尝试获取...
第[3]次尝试获取...
...
第[10]次尝试获取...
获取到死信消息:test_message
无TTL队列+消息TTL
索性我们将队列的TTL取消,采用直接对消息的TTL进行控制。
QUEUE_NAME = 'normal.queue.nottl'
# 声明正常队列,并绑定死信交换机和死信路由,约束队列TTL为10秒
arguments = {
"x-dead-letter-exchange": DEAD_EXCHANGE_NAME,
"x-dead-letter-routing-key": DEAD_ROUTING_KEY,
# "x-message-ttl": 10 * 1000
}
channel.queue.declare(
QUEUE_NAME, durable=True, arguments=arguments
)
我们仅需对上文源码中arguments的TTL属性屏蔽,并新命名一个队列。
- 测试三秒延迟消息:
channel.basic.publish(
"test_message",
QUEUE_NAME,
properties={"expiration": "3000"}
)
第[1]次尝试获取...
第[2]次尝试获取...
第[3]次尝试获取...
获取到死信消息:test_message
- 测试十三秒延迟消息:
channel.basic.publish(
"test_message",
QUEUE_NAME,
properties={"expiration": "13000"}
)
第[1]次尝试获取...
第[2]次尝试获取...
第[3]次尝试获取...
...
第[13]次尝试获取...
获取到死信消息:test_message
问题:队列优先级
你以为这就结束了吗?又又又发现新的问题,先上代码:
channel.basic.publish(
"test_message_3000",
QUEUE_NAME,
properties={"expiration": "3000"}
)
channel.basic.publish(
"test_message_5000",
QUEUE_NAME,
properties={"expiration": "5000"}
)
# 监控死信队列(延迟队列)
for idx in range(0, 99):
time.sleep(1)
print("第[{}]次尝试获取...".format(idx + 1))
message = channel.basic.get(DEAD_QUEUE_NAME)
if message:
print("获取到死信消息:{}".format(message.body))
channel.basic.ack(delivery_tag=message.delivery_tag)
# break
我们同时发布两条消息,一条3秒到达,一条5秒到达。查看接收情况:
第[1]次尝试获取...
第[2]次尝试获取...
第[3]次尝试获取...
获取到死信消息:test_message_3000
第[4]次尝试获取...
第[5]次尝试获取...
获取到死信消息:test_message_5000
完美达到我们的目的,但是问题暴露在,一旦发送消息的顺序发生改变,也就是大的延迟在前,小延迟在后。
第[1]次尝试获取...
第[2]次尝试获取...
第[3]次尝试获取...
第[4]次尝试获取...
第[5]次尝试获取...
获取到死信消息:test_message_5000
第[6]次尝试获取...
获取到死信消息:test_message_3000
原因在于,不同TTL的消息发给队列,队列如果想要知道哪条消息优先弹出,就需要扫描整个队列。而目前的策略是先发的消息在顶端,监控TTL也是顶端的这条消息,所以会导致后发的消息不管TTL是多少,都会卡在后面。
延迟队列插件
安装延迟队列插件
在官方文档的社区插件页面有一个延迟队列插件解决眼下的问题。
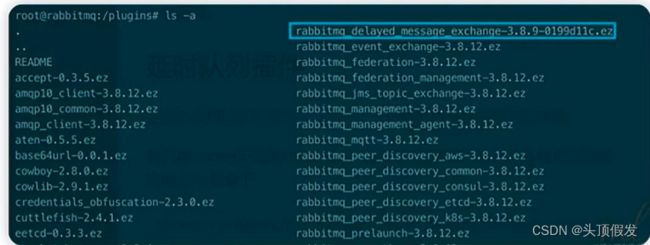
我们是docker安装的RabbitMQ,所以我们需要将下载的插件拷贝到容器内plugins目录下
docker cp /Users/miclon/Downloads/rabbitmq_delayed_message_exchange-3.8.9-0199d11c.ez rabbitmq:/plugins
不妨进容器看看有没有放进去
> docker exec -it rabbitmq /bin/bash
> cd plugins
> ls -a
接着在容器中启动这个插件:
> rabbitmq-plugins enable rabbitmq_delayed_message_exchangeEnabling plugins on node rabbit@rabbitmq:
rabbitmq_delayed_message_exchange
The following plugins have been configured:
rabbitmq_delayed_message_exchange
rabbitmq_management
rabbitmq_management_agent
rabbitmq_prometheus
rabbitmq_web_dispatch
Applying plugin configuration to rabbit@rabbitmq...
The following plugins have been enabled:
rabbitmq_delayed_message_exchange
started 1 plugins.紧接着,我们退出容器后重启RabbitMQ服务。
> docker restart rabbitmq 刷新web管理端即可看到:
延迟队列实现
from mq import channel
DELAYED_EXCHANGE_NAME = 'delayed.exchange'
DELAYED_QUEUE_NAME = 'delayed.queue'
DELAYED_ROUTING_KEY = 'delayed.routing.key'
# 声明延迟交换机
arguments = {"x-delayed-type": "direct"}
channel.exchange.declare(DELAYED_EXCHANGE_NAME,
exchange_type="x-delayed-message",
durable=True,
arguments=arguments)
# 声明延迟队列
channel.queue.declare(DELAYED_QUEUE_NAME, durable=True)
# 延迟队列绑定延迟交换机和延迟路由
channel.queue.bind(
queue=DELAYED_QUEUE_NAME,
exchange=DELAYED_EXCHANGE_NAME,
routing_key=DELAYED_ROUTING_KEY,
)
少了原来死信队列的中间队列,代码里也少了很多。
相较于之前,我们在发送消息的时候需要携带 headers ,并且需要指定 x-delay 的值,这个参数表示消息延时的时间(毫秒)。
channel.basic.publish(
"test_message_5000",
DELAYED_ROUTING_KEY,
DELAYED_EXCHANGE_NAME,
properties={'headers': {"x-delay": 5000}}
)
channel.basic.publish(
"test_message_3000",
DELAYED_ROUTING_KEY,
DELAYED_EXCHANGE_NAME,
properties={'headers': {"x-delay": 3000}}
)输出结果:
第[1]次尝试获取...
第[2]次尝试获取...
第[3]次尝试获取...
获取到死信消息:test_message_3000
第[4]次尝试获取...
第[5]次尝试获取...
获取到死信消息:test_message_5000
总结
rabbitmq_delayed_message_exchange