在 8 月 13 日的 TDengine 开发者大会上,TDengine 计算引擎架构师廖浩均带来题为《TDengine 3.0——全新计算查询引擎的设计》的主题演讲,详细阐述了 TDengine 3.0 计算查询引擎技术的优化与升级。本文根据此演讲整理而成。
点击【这里】查看完整演讲视频
3.0 中的查询引擎在 2.0 版本的基础上进行了重写,在承袭 2.0 查询引擎既有优势和技术特性的基础上,在工程实现和整体架构设计上有了极大的改善和提升。
总体来讲,TDengine 3.0 大幅增强了对 SQL 语义的支持、完善了 SQL 查询语法;强化了整体执行框架及 SQL 查询的调度能力;提供更好的执行任务隔离机制,对于错误具备更好的容忍度;提供支持存算分离架构的能力。它主要包含以下几个方面的特点:
1.支持标准 SQL 查询语法
- 全新的 SQL 解析器、计划生成及优化器,引入伪列 (_wstart/_wend/_qstart/_qend/_rowts) 等语法概念和新的(分组)关键词,全面增强查询语法。
- 消除 2.x 版本中对时序数据查询施加的诸多限制,可以像使用关系对象数据库查询引擎一样使用 SQL 查询语法。
- 支持标签/普通列的运算,标量函数和矢量函数的嵌套、任意字段(列)的分组/排序/聚合、无限制的多级子查询。
2.支持存算分离架构
- 支持存算分离的体系架构,支持集群内计算节点动态、快速、弹性部署。
- 查询引擎能够将查询按需调度到计算节点,有效降低存储节点(Vnode)计算资源的压力。
- 原生的流批一体化查询处理
- TDengine 3.0 原生支持流计算和交互式查询。流计算引擎也使用 SQL 语言作为交互途径,因此,流计算引擎直接使用查询框架的 SQL 解析处理、执行计划生成、查询执行算子、用户应用交互等诸多方面的能力。
3.更优秀的鲁棒性和韧性设计
- 为避免用户错误导致的主服务宕机,用户定义函数的执行服务(UDFD)与 TDengine 的主进程进行隔离,UDFD 可以在崩溃以后自动被重新拉起。
- 对于 SQL 查询转化为调度器的查询任务(Job),Job 在被分解以后会按层级调度执行,并且同层次任务相互独立执行,单个任务失败以后可以重新拉起进行处理。
- 对于不同分层的任务(Task),失败任务可以从下游任务的结果缓存(Sink Node)中再次请求数据并尝试重新执行。
4.更好的执行可观测性
- 将查询计划、执行开销、查询中 Task 的动态执行状态等相关信息通过命令行交互界面(CLI)呈现给用户,助力用户定位查询执行的瓶颈,并进行针对性的优化处理。
- 提供 Explain 指令,用户可以通过 Explain 获得查询执行的计划、各算子执行开销等信息,为用户层面 SQL 改写和优化性能提供支持。
- 通过心跳信息,将服务端执行状态推送到调度器,并反馈给用户,让用户更好确定查询执行的状态。
5.支持数据集快照查询
- 全面内置版本化的查询支持能力,可以为事件驱动流计算引擎提供指定版本和时间范围的历史数据追溯查询。
- 为双(多)活集群提供数据同步版本化读取能力。
查询引擎架构设计

上图是 TDengine 3.0 的查询引擎架构,左边的 Query Wrapper 运行在 Vnode 和 Qnode 上,它里面包含了一个执行器,其中的 Index 模块是处理 Vnode 中存储的标签数据的索引。执行器本身并不处理与调度器的交互行为,Query Wrapper 负责处理执行 Task 动作并将结果缓存在 Sink Node;此外,执行器会调用 function 模块和 ScalarFunc 模块进行计算处理,并在必要的情况下通过 function 模块调用 UDF 服务。
中间的模块是由 Query Wrapper 和 libtaos.so 所共享的,里面包含的是 function(系统中其他所有函数的定义模块)和 ScalarFunc(标量函数以及过滤的模块)。需要注意的是,在 function 模块中还包含了一个 UDFD 的计算模块,它是用户定义程序的执行服务端,运行在一个独立的进程空间。
最右边的模块是运行在用户进程空间中的驱动 libtaos.so,Driver 是 libtaos.so 里的一个驱动,它负责串联各个模块来完成查询的操作,Parser 用来调用分词器与语法分析器进行语法分析,生成语法树(AST),Catalog 负责从 Mnode 和 Vnode 中获取各种元数据,Planner 负责将 AST 和 元数据信息转化为逻辑执行计划、物理执行计划、并进行执行计划重写,最后生成分层查询计划,Command 负责执行本地化查询操作。
相比于 2.0,3.0 在模块化和工程化上做了较多的优化,主要可以归结为以下几方面:
- 客户端不参与计算,计算过程在服务端完成
- UDF 在独立的进程空间中运行,与主服务进程隔离
- Qnode-aware 的自适应查询任务调度策略
- Index-aware 的标签过滤机制
- 节点间/算子间采用标准的列格式(columnar data)数据进行数据传递
- 进行计算的节点会通过心跳将查询执行信息返回给调度器
- 重写查询框架,形成了高内聚、低耦合的框架模块
时序数据查询处理流程
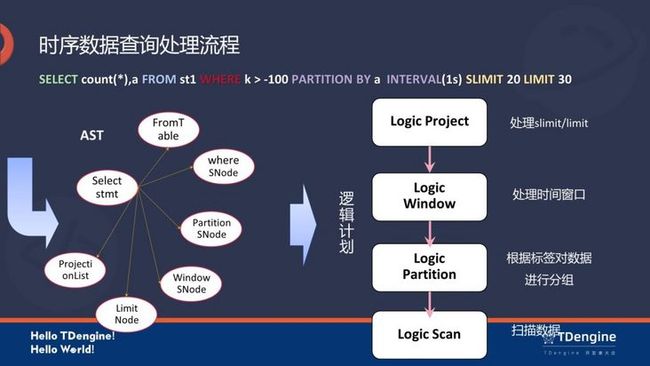
首先,Parser 会把图上的 SQL 语句转成一个抽象语法树,之后会依托于 Catalog 节点拉取相应的元数据,然后将信息传递到 planner,生成如图上所示的逻辑计划。之后在逻辑计划层面会生成四个 node,自底向上分别是 Scan、Partition、Window、Project,它们分别对应 SQL 语句里不同的几个关键词。
逻辑计划传递下去,最后会在 planner 中生成一个物理计划。上图所示的红色虚线以下部分(Partial Agg)是对物理计划的执行,包括 VgID:#1 和VgTD:#2 两个子任务;虚线上层是一个Global Merge,是最后的一个聚合阶段,Partial 聚合结果经过 merge sort 后再次进行全局聚合,形成结果以后送到计算节点本地的 sink node 进行缓存,等待 scheduler 来拉取最后的计算结果。
在之前逻辑计划中的 Logic partition 在物理计划中却看不到了,其实 Partition 分组逻辑是被下沉到了 TableScan 完成,这是一个优化操作。按照标签分组机制,同一个表中数据一定同一分组,我们在 TableScan Node 中建立表分组的映射关系即可,再将数据块打上 GroupID 就完成了分组操作,不需要对每一条数据进行扫描。
物理计划的具体实现在 TDengine 系统执行的日志里面可以看到,感兴趣的同学可以去看看,系统中的物理计划采用 JSON 形式的文本呈现。
在实际操作中,物理计划最终会传递到调度器中执行,调度器工作的元素就是 Task 和 Job,每个SQL 查询是一个 Job,每个 Job 由若干个 Task 构成,每个 Task 包含了其执行的节点信息、任务 ID、需要执行的物理计划等信息,不同的 Task 会形成一个层级化的树形结构。
物理计划传递到调度器后,虚线下面的两个 Partial Agg 会被转化成 Subplan #1(level 1) 和 Subplan #2(level 1),这两个执行计划会分别发送到不同的 Vnode 进行执行。虚线上层也是一个 Task [Subplan #0(level 0)],等下层两个 Task 执行完成或至少返回第一条记录时,调度器就会拉起上一层 level 0 的 Task 进行执行,它是层级化的执行方式。
时序数据查询处理的整个流程
时序数据查询处理的整体流程如上图所示,其中计算节点的选择主要有以下几点策略:
- 部分聚合计算的计算节点由于聚合计算下推,要求在保存有数据的 Vnode 上进行,以减小数据在集群中传输带来的开销;
- 对于全局聚合,可以在集群中所有可用节点中任意选取,为了减小数据在集群中传输的开销,一般会选择进行局部聚合(Partial Agg) 的节点进行全局聚合;
- 如果在集群中存在 Qnode(计算节点),调度器会优先将后续阶段的计算调度到计算节点上进行计算。
时序数据查询优化策略
排序消除
排序是查询过程中,I/O 和 CPU 开销都非常高的操作。如果查询结果要求按照 timestamp 排序(升序或降序)输出,由于时序数据在 TDengine 中就是按照时间序列存储,所以排序的操作可用直接消除,只需要将 TableScan 指定为升序/降序扫描返回结果即可。
排序优化
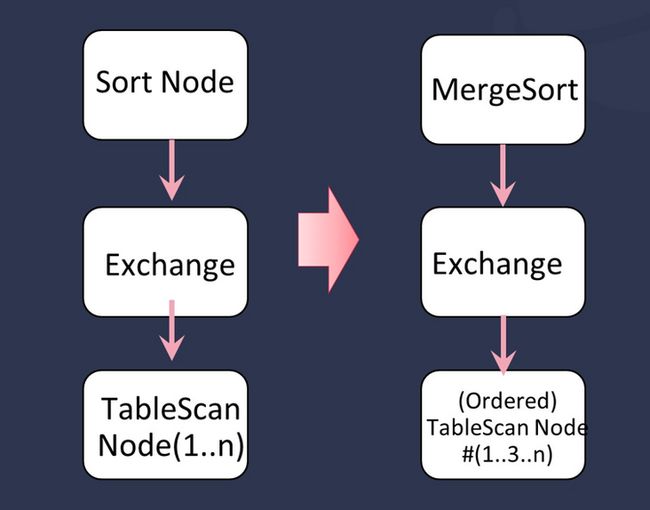
操作逻辑如上图所示。对于分布式的结果排序输出,排序操作充分利用时序数据有序性,如果我们使用归并排序替代完全排序,就能避免在标准外存排序过程中触发的 IO 操作。这一操作主要在超级表查询的场景中使用较多。
数据替代
从这一条优化策略开始,需要给大家补充一下关于 SMA 的背景知识。SMA 是 Small Materialized Aggregates 的简称。对于每个落盘的数据块(Block)都会生成一个对应的 SMA 信息,其中包含了每列数据的最大值、最小值、NULL 数量信息。这些信息针对数值型列都存在,必要时可以替代数据参与计算。相对于具体的数据来说,SMA 占据的磁盘空间非常小,因此能够极大地提升某些种类的查询性能。
基于 SMA 的优化策略之一就是数据替代。针对每个函数,TDengine 定义了其需要的数据范围,上表是一些聚合函数的数据计算需求列表。在 SQL 解析阶段,如果确认其最终的数据需求是 Small Materialized Aggregates (SMA),最终只会读取 SMA 进行计算。但并非任何情况下都可以使用 SMA,对于所有标量函数,一旦在查询请求里面出现,SMA 是不参与到计算里面来的。
在使用 SMA 时,查询优化器会告诉执行节点,只需要去读取每个 block 的 SMA 信息就行,在整个查询过程中,执行器不会再去读取任何一条具体的数据,所以它的流程非常快。
数据扫描优化
TDengine 中定义了数据顺序敏感型函数,在 SQL 语句中使用该类型的函数会触发优化器使用特定的数据文件扫描策略。在 SQL 语句 SELECT last(ts),count(*) FROM foo_table_name 中,Last 函数返回最后一个非 NULL 值,所以逆序扫描能够更快获得结果。而 count 函数对于扫描的顺序并不敏感,因此,优化器会指令 TableScanNode 采用逆序扫描策略。
动态裁剪 Block

对于某些查询函数,例如:last/first/top/bottom 查询,可以使用中间结果来动态裁剪读取的 block 的信息。
在执行过程之中,根据中间计算的结果及当前结果可以确定,下一个需要扫描的 block 是否需要真正地读取。依然以 last 为例 SELECT last(ts) FROM foo_table_name,在每次需要读取下一个 Database 时,首先使用 ts=100 过滤每个数据块,如果数据块包含的时间范围晚于 ts=100, 才会读取该数据块数据并进行计算,大于 ts=100 的就自动跳过,这就实现了动态裁剪 Block 的功能。
基于 SMA 的预过滤
在进行 Last 查询时,SMA 会被用来做预过滤,其中保存了与之对应的数据块的四项统计信息:最大值、最小值、和 NULL 的数量。所有的针对数据的过滤条件首先应用在 SMA 之上,SMA 满足过滤条件以后,再读取数据块,然后再次进行针对数据的过滤。
以 SELECT last(ts),count(*) FROM foo_table_name WHERE k > 20 为例,这里面有一个过滤条件是 K 大于 20,如果其中存储着关于 K 那一列的最大值、最小值信息,就可以以此为条件进行过滤,如果其中的 MAX 值都小于 20,那么这个 block 也会在 TableScanNode 里面读取真实数据之前就丢弃。
Interval SMA
时序数据库(Time Series Database,TSDB)一个重要的应用场景就是为看板(Dash Board)提供定时的查询(Standing Query, 应用或程序按照固定频率发出的查询)支持,看板应用以固定的频率向应用及时序数据库发出查询执行,并在可接受的时间范围内要求获得查询结果。
针对 Standing Query 的执行需求,为了提升响应速度,节约重复计算带来的资源开销。在 TDengine 3.0 中提供了使用流计算引擎的异步 interval SMA(将针对时间窗口的聚合查询转化为投影查询,因为计算结果已经通过流计算引擎计算完成并写回到 TDengine)。
事实上,上述优化并不是 3.0 查询计算引擎里包含的所有优化策略,只是涉及到了几个较为经典的查询场景。关于查询引擎的优化是非常琐碎的,有些优化策略只针对一种场景,甚至如果改写一下语句顺序可能就不生效了。如果大家还想了解更多的查询引擎优化策略,可以去 GitHub 上查阅 3.0 的代码,或者直接下载进行体验。
结语
接下来,关于 TDengine 查询引擎的优化,大致分为以下几点:
- 标量计算库采用 SIMD 进行优化:采用 SIMD 指令加速标量计算的执行速度
- 支持多种脚本语言的 UDF/UDAF:3.0 现在支持 C 语言定义的 UDF/UDAF, 后续将支持脚本语言定义的 UDF/UDAF,提供更便捷的使用体验
- 支持高精度数值类型和二进制类型数据:高精度 Decimal 类型和 binary(1MB)类型数据的存储、读取和查询
- 完善查询优化器:查询优化器针对更多的查询场景和用例提供高效率的优化,降低 SQL 执行的复杂程度
- 支持多源数据的联邦查询:支持使用外部数据源的联邦查询,通过定义连接器,将其他的数据平台作为查询的基础数据源
- 提供更丰富的时序相关计算及分析函数和 SQL 查询语法:部分聚合函数将支持 CASE/WHEN、CTE 语法、SQL Hint,以及针对数据分析应用的需求,并提供更多的内置 SQL 函数
除此之外,后续我们还将完善查询内存控制和任务执行/调度策略,在现有的随机分配任务的基础上,基于 Qnode 的运行负载状况,调度查询任务的执行;提供更好的内存控制策略,降低百万/千万级别表查询过程中元数据追踪带来的内存抖动;针对查询范围进行横向的数据查询范围切分,在同一个 vnode 中并行拉起多个查询执行同一个查询处理。
总而言之,后面我们还有更多的工作要进行,会继续优化 TDengine 3.0 查询引擎的性能,也欢迎更多的 TDengine 关注者和支持者交流应用体验,帮助我们进步。
想了解更多 TDengine Database的具体细节,欢迎大家在GitHub上查看相关源代码。