Spring微服务实战第9章 使用Spring Cloud Sleuth和Zipkin进行分布式跟踪
文章目录
- 第9章 使用Spring Cloud Sleuth和Zipkin进行分布式跟踪
-
- 9.1 Spring Cloud Sleuth与关联ID
-
- 9.1.1 将Spring Cloud Sleuth添加到许可证服务和组织服务中
- 9.1.2 剖析Spring Cloud Sleuth跟踪
- 9.2 日志聚合与Spring Cloud Sleuth
-
- 9.2.1 Spring Cloud Sleuth与Papertrail集成实战
- 9.2.2 创建Papertrail账户并配置syslog连接器
- 9.2.3 将Docker输出重定向到Papertrail
- 9.2.4 在Papertrail中搜索Spring Cloud Sleuth的跟踪ID
- 9.2.5 使用Zuul将关联ID添加到HTTP响应
- 9.3 使用Open Zipkin进行分布式跟踪
-
- 9.3.1 添加Spring Cloud Sleuth和Zipkin依赖项
- 9.3.2 配置服务以指向Zipkin
- 9.3.3 安装和配置Zipkin服务器
- 9.3.4 设置跟踪级别
- 9.3.5 使用Zipkin跟踪事务
- 9.3.6 可视化更复杂的事务
- 9.3.7 捕获消息传递跟踪
- 9.3.8 添加自定义跨度
- 9.4 小结
- 源码地址
- 源码地址
第9章 使用Spring Cloud Sleuth和Zipkin进行分布式跟踪
本章主要内容
- 使用Spring Cloud Sleuth将跟踪信息注入服务调用
- 使用日志聚合来查看分布式事务的日志
- 通过日志聚合工具进行查询
- 在跨多个微服务调用时,使用OpenZipkin直观地理解用户的事务
- 使用Spring Cloud Sleuth和Zipkin定制跟踪信息
微服务架构是一种强大的设计范型,可以将复杂的单体软件系统分解为更小、更易于管理的部分。这些可管理的部分可以独立构建和部署。然而,这种灵活性是要付出代价的,那就是复杂性。因为微服务本质上是分布式的,所以要调试问题出现的地方可能会让人抓狂。服务的分布式特性意味着必须在多个服务、物理机器和不同的数据存储之间跟踪一个或多个事务,然后试图拼凑出究竟发生了什么。
本章列出了可能实现分布式调试的几种技术。在这一章中,我们将关注以下内容。
- 使用关联ID将跨多个服务的事务链接在一起。
- 将来自多个服务的日志数据聚合为一个可搜索的源。
- 可视化跨多个服务的用户事务流,并理解事务每个部分的性能特征。
为了完成这3件事,我们将使用以下3种不同的技术。
- Spring Cloud Sleuth——Spring Cloud Sleuth是一个Spring Cloud项目,它将关联ID装备到HTTP调用上,并将生成的跟踪数据提供给OpenZipkin的钩子。Spring Cloud Sleuth通过添加过滤器并与其他Spring组件进行交互,将生成的关联ID传递到所有系统调用。
- Papertrail——Papertrail是一种基于云的服务(基于免费增值),允许开发人员将来自多个源的日志数据聚合到单个可搜索的数据库中。开发人员可以为日志聚合选择的解决方案包括内部部署解决方案、基于云解决方案、开源解决方案和商业解决方案。本章稍后将介绍几种备选方案。
- Zipkin——Zipkin是一种开源数据可视化工具,可以显示跨多个服务的事务流。Zipkin 允许开发人员将事务分解到它的组件块中,并可视化地识别可能存在性能热点的位置。
要开始本章的内容, 我们从最简单的跟踪工具——关联ID开始。
注意
本章的部分内容依赖于第6章中介绍的内容(特别是Zuul的前置过滤器、路由过滤器和后置过滤器)。如果读者还没有读过第6章,建议在阅读这一章之前先读一读。
9.1 Spring Cloud Sleuth与关联ID
在第5章和第6章中,我们介绍了关联ID的概念。关联ID是一个随机生成的、唯一的数字或字符串,它在事务启动时分配给一个事务。当事务流过多个服务时,关联ID从一个服务调用传播到另一个服务调用。在第6章的上下文中,我们使用Zuul过滤器检查了所有传入的HTTP请求,并且在关联ID不存在的情况下注入关联ID。
一旦提供了关联ID,就可以在每个服务上使用自定义的Spring HTTP过滤器,将传入的变量映射到自定义的UserContext对象。有了UserContext对象,现在可以手动地将关联ID添加到日志语句中,或者通过少量工作将关联ID直接添加到Spring的映射诊断上下文(Mapped Diagnostic Context,MDC)中,从而确保将关联ID添加到任何日志语句中。我们还编写了一个Spring拦截器,该拦截器通过向出站调用添加关联ID到HTTP首部中,确保来自服务的所有HTTP调用都会传播关联ID。
对了,我们必须施展Spring和Hystrix的魔法,以确保持有关联ID的父线程的线程上下文被正确地传播到Hystrix。在最后,这些数量众多的基础设施都是为了某些你希望只有在问题发生时才查看的东西而设置的(使用关联ID来跟踪事务中发生了什么)。
幸运的是,Spring Cloud Sleuth能够为开发人员管理这些代码基础设施并处理复杂的工作。通过添加Spring Cloud Sleuth到Spring微服务中,开发人员可以:
- 透明地创建并注入一个关联ID到服务调用中(如果关联ID不存在);
- 管理关联ID到出站服务调用的传播,以便将事务的关联ID自动添加到出站调用中;
- 将关联信息添加到Spring的MDC日志记录,以便生成的关联ID由Spring Boot默认的SL4J和Logback实现自动记录;
- (可选)将服务调用中的跟踪信息发布到Zipkin分布式跟踪平台。
注意
有了Spring Cloud Sleuth,如果使用Spring Boot的日志记录实现,关联ID就会自动添加到微服务的日志语句中。
让我们继续,将Spring Cloud Sleuth添加到许可证服务和组织服务中。
9.1.1 将Spring Cloud Sleuth添加到许可证服务和组织服务中
要在两个服务(许可证和组织)中开始使用Spring Cloud Sleuth,我们需要在两个服务的pom.xml文件中添加一个Maven依赖项:
org.springframework.cloud
spring-cloud-starter-sleuth
这个依赖项会拉取Spring Cloud Sleuth所需的所有核心库。就这样,一旦这个依赖项被拉进来,服务现在就会完成如下功能。
(1)检查每个传入的HTTP服务,并确定调用中是否存在Spring Cloud Sleuth跟踪信息。如果Spring Cloud Sleuth跟踪数据确实存在,则将捕获传递到微服务的跟踪信息,并将跟踪信息提供给服务以进行日志记录和处理。
(2)将Spring Cloud Sleuth跟踪信息添加到Spring MDC,以便微服务创建的每个日志语句都添加到日志中。
(3)将Spring Cloud跟踪信息注入服务发出的每个出站HTTP调用以及Spring消息传递通道的消息中。
9.1.2 剖析Spring Cloud Sleuth跟踪
如果一切创建正确,则在服务应用程序代码中编写的任何日志语句现在都将包含Spring Cloud Sleuth跟踪信息。例如,图9-1展示了如果要在组织服务上执行HTTP GET请求http://localhost:5555/api/organization/v1/organizations/e254f8c-c442-4ebe-
a82a-e2fc1d1ff78a,服务将输出什么结果。

图9-1 Spring Cloud Sleuth为服务编写的每个日志条目添加了4条跟踪信息,这些数据有助于将用户请求的服务调用绑定在一起
Spring Cloud Sleuth将向每个日志条目添加以下4条信息(与图9-1中的数字对应)。
(1)服务的应用程序名称——这是创建日志条目时所在的应用程序的名称。在默认情况下,Spring Cloud Sleuth将应用程序的名称(spring.application.name)作为在跟踪中写入的名称。
(2)跟踪ID(trace ID)——跟踪ID是关联ID的等价术语,它是表示整个事务的唯一编号。
(3)跨度ID(span ID)——跨度ID是表示整个事务中某一部分的唯一ID。参与事务的每个服务都将具有自己的跨度ID。当与Zipkin集成来可视化事务时,跨度ID尤其重要。
(4)是否将跟踪数据发送到Zipkin——在大容量服务中,生成的跟踪数据量可能是海量的,并且不会增加大量的价值。Spring Cloud Sleuth让开发人员确定何时以及如何将事务发送给Zipkin。Spring Cloud Sleuth跟踪块末尾的true/false指示器用于指示是否将跟踪信息发送到Zipkin。
到目前为止,我们只查看了单个服务调用产生的日志数据。让我们来看看通过GEThttp://localhost:5555/api/licensing/v1/organizations/e254f8c-c442-4ebe-
a82a-e2fc1d1ff78a/licenses/f3831f8c-c338-4ebe-a82a-e2fc-1d1ff78a调用许可证服务时会发生什么。记住,许可证服务还必须向组织服务发出调用。图9-2展示了来自两个服务调用的日志记录输出。

图9-2 当一个事务中涉及多个服务时,可以看到它们具有相同的跟踪ID
查看图9-2可以看出许可证服务和组织服务都具有相同的跟踪ID——a9e3e1786b74d302。但是,许可证服务的跨度ID是a9e3e1786b74d302(与事务ID的值相同),而组织服务的跨度ID是3867263ed85ffbf4。
只需添加一些POM的依赖项,我们就已经替换了在第5章和第6章中构建的所有关联ID的基础设施。就我个人而言,在这个世界上,没有什么比用别人的代码代替复杂的、基础设施风格的代码更让我开心的了。
9.2 日志聚合与Spring Cloud Sleuth
在大型的微服务环境中(特别是在云环境中),日志记录数据是调试问题的关键工具。但是,因为基于微服务的应用程序的功能被分解为小型的细粒度的服务,并且单个服务类型可以有多个服务实例,所以尝试绑定来自多个服务的日志数据以解决用户的问题可能非常困难。试图跨多个服务器调试问题的开发人员通常不得不尝试以下操作。
- 登录到多个服务器以检查每个服务器上的日志。这是一项非常费力的任务,尤其是在所涉及的服务具有不同的事务量,导致日志以不同的速率滚动的时候。
- 编写尝试解析日志并标识相关的日志条目的本地查询脚本。由于每个查询可能不同,因此开发人员经常会遇到大量的自定义脚本,用于从日志中查询数据。
- 延长停止服务的进程的恢复,因为开发人员需要备份驻留在服务器上的日志。如果托管服务的服务器彻底崩溃,则日志通常会丢失。
上面列出的每一个问题都是我遇到过的实际问题。在分布式服务器上调试问题是一件很糟糕的工作,并且常常会明显增加识别和解决问题所需的时间。
一种更好的方法是,将所有服务实例的日志实时流到一个集中的聚合点,在那里可以对日志数据进行索引并进行搜索。图9-3在概念层面展示了这种“统一”的日志记录架构是如何工作的。

图9-3 将聚合日志与跨服务日志条目的唯一事务ID结合,更易于管理分布式事务的调试
幸运的是,有多个开源产品和商业产品可以帮助我们实现前面描述的日志记录架构。此外,还存在多个实现模型,可供开发人员在内部部署、本地管理或者基于云的解决方案之间进行选择。表9-1总结了可用于日志记录基础设施的几个选择。
表9-1 与Spring Boot组合使用的日志聚合方案的选项
| 产品名称 | 实现模式 | 备 注 |
|---|---|---|
| Elasticsearch, Logstash, Kibana(ELK) | 开源 商业 通常实施于内部部署 | 通用搜索引擎 可以通过ELK技术栈进行日志聚合 需要最多的手工操作 |
| Graylog | 开源 商业 内部部署 | 设计为在内部安装的开源平台 |
| Splunk | 仅限于商业 内部部署和基于云 | 最古老且最全面的日志管理和聚合工具 最初是内部部署的解决方案, 但后来提供了云服务 |
| Sumo Logic | 免费增值模式 商业 基于云 | 免费增值模式/分层定价模型 仅作为云服务运行 需要用公司的工作账户去注册(不能是Gmail或Yahoo账户) |
| Papertrail | 免费增值模式 商业 基于云 | 免费增值模式/分层定价模型 仅作为云服务运行 |
很难从上面选出哪个是最好的。每个组织都各不相同,并且有不同的需求。
在本章中,我们将以Papertrail为例,介绍如何将Spring Cloud Sleuth支持的日志集成到统一的日志记录平台中。选择Papertrail出于以下3个原因。
(1)它有一个免费增值模式,可以注册一个免费的账户。
(2)它非常容易创建,特别是和Docker这样的容器运行时工作。
(3)它是基于云的。虽然我认为良好的日志基础设施对于微服务应用程序是至关重要的,但我不认为大多数组织都有时间或技术才能去正确地创建和管理一个日志记录平台。
9.2.1 Spring Cloud Sleuth与Papertrail集成实战
在图9-3中,我们看到了一个通用的统一日志架构。现在我们来看看如何使用Spring Cloud Sleuth和Papertrail来实现相同的架构。
为了让Papertrail与我们的环境一起工作,我们必须采取以下措施。
(1)创建一个Papertrail账户并配置一个Papertrail syslog连接器。
(2)定义一个Logspout Docker容器,以从所有Docker容器捕获标准输出。
(3)通过基于来自Spring Cloud Sleuth的关联ID发出查询来测试这一实现。
图9-4展示了这一实现的最终状态,以及Spring Cloud Sleuth和Papertrail如何与解决方案融合。

图9-4 使用原生Docker功能、Logspout和Papertrail可以快速实现统一的日志记录架构
9.2.2 创建Papertrail账户并配置syslog连接器
我们将从创建一个Papertrail账号开始。要开始使用PaperTrail,应访问https://papertrailapp.com并点击绿色的“Start Logging-Free Plan”按钮。图9-5展示了这个界面。

图9-5 首先,在Papertrail上创建一个账户
Papertrail不需要大量的信息去启动,只需要一个有效的电子邮箱地址即可。填写完账户信息后, 将出现一个界面,用于创建记录数据的第一个系统。图9-6展示了这个界面。
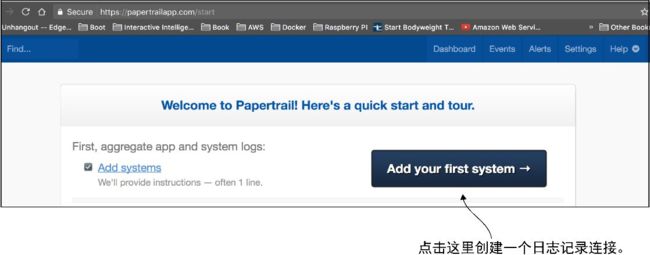
图9-6 接下来,选择如何将日志数据发送到Papertrail
在默认情况下,Papertrail允许开发人员通过Syslog调用向它发送日志数据。Syslog是源于UNIX的日志消息传递格式,它允许通过TCP和UDP发送日志消息。Papertrail将自动定义一个Syslog端口,可以使用它来写入日志消息。在本章的讨论中,我们将使用这个默认端口。图9-7展示了syslog 连接字符串,在点击图9-6所示的“Add your first system”按钮时,它将自动生成。

图9-7 Papertrail使用Syslog作为向它发送数据的机制之一
到目前为止,我们已经设置完Papertrail。接下来,我们必须配置Docker环境,以便将运行服务的每个容器的输出捕获到图9-7中定义的远程syslog端点。
注意
图9-7中的连接字符串是我的账户特有的。读者需要确保自己使用了Papertrail为自己生成的连接字符串,或者通过Papertrail Settings→Log destinations菜单选项来定义一个连接字符串。
9.2.3 将Docker输出重定向到Papertrail
通常情况下,如果在虚拟机中运行每个服务,那么必须配置每个服务的日志记录配置,以便将它的日志信息发送到一个远程syslog端点(如通过Papertrail公开的那个端点)。
幸运的是,Docker让从物理机或虚拟机上运行的Docker容器中捕获所有输出变得非常容易。Docker守护进程通过一个名为docker.sock的Unix套接字来与所有Docker容器进行通信。在Docker所在的服务器上,每个容器都可以连接到docker.sock,并接收由该服务器上运行的所有其他容器生成的所有消息。用最简单的术语来说,docker.sock就像一个管道,容器可以插入其中,并捕获Docker运行时环境中进行的全部活动,这些Docker运行时环境是在Docker守护进程运行的虚拟服务器上的。
我们将使用一个名为Logspout的“Docker化”软件,它会监听docker.sock套接字,然后捕获在Docker运行时生成的任意标准输出消息,并将它们重定向输出到远程syslog(Papertrail)。要建立Logspout容器,必须要向docker-compose.yml文件添加一个条目,它用于启动本章代码示例使用的所有Docker容器。我们需要修改docker/common/docker-compose.yml文件以添加以下条目:
logspout:
image: gliderlabs/logspout
command: syslog://logs5.papertrailapp.com:21218
volumes:
- /var/run/docker.sock:/var/run/docker.sock
注意
在上面的代码片段中,读者需要将
command属性中的值替换为Papertrail提供的值。如果读者使用上述Logspout代码片段,Logspout容器会很乐意将日志条目写入我的Papertrail账户。
现在,当读者启动本章中Docker环境时,所有发送到容器标准输出的数据都将发送到Papertrail。在启动完第9章的Docker示例之后,读者通过登录自己的Papertrail账户,然后点击界面右上角的“Events”按钮,就可以看到数据都发送到Papertrail。
图9-8展示了发送到Papertrail的数据的示例。

图9-8 在定义了Logspout Docker容器的情况下,写入每个容器标准输出的数据将被发送到Papertrail
为什么不使用Docker日志驱动程序
Docker 1.6及更高版本允许开发人员定义其他日志驱动程序,以记录在每个容器中写入的stdout/stderr 消息。其中一个日志记录驱动程序是 syslog 驱动程序,它可用于将消息写入远程syslog监听器。
为什么我会选择Logspout而不是使用标准的 Docker 日志驱动程序?主要原因是灵活性。Logspout提供了定制日志数据发送到日志聚合平台的功能。Logspout提供的功能有以下几个。
- 能够一次将日志数据发送到多个端点。许多公司都希望将自己的日志数据发送到一个日志聚合平台,同时还需要安全监控工具,用于监控生成的日志中的敏感数据。
- 在一个集中的位置过滤哪些容器将发送它们的日志数据。使用Docker驱动程序,开发人员需要在docker-compose.yml文件中为每个容器手动设置日志驱动程序,而Logspout则允许开发人员在集中式配置中定义特定容器甚至特定字符串模式的过滤器。
- 自定义HTTP路由,允许应用程序通过特定的HTTP端点来写入日志信息。这个特性允许开发人员完成一些事情,例如将特定的日志消息写入特定的下游日志聚合平台。举个例子,开发人员可能会将一般的日志消息从stdout/stderr转到Papertrail,与此同时,可能会希望将特定应用程序审核信息发送到内部的Elasticsearch服务器。
- 与syslog以外的协议集成。Logspout可以通过UDP和TCP协议发送消息。此外,Logspout还具有第三方模块,可以将Docker的stdout/stderr整合到Elasticsearch中。
9.2.4 在Papertrail中搜索Spring Cloud Sleuth的跟踪ID
现在,日志正在流向Papertrail,我们可以真正开始感激Spring Cloud Sleuth将跟踪ID添加到所有日志条目中。要查询与单个事务相关的所有日志条目,只需在Papertrail的事件界面的查询框中输入跟踪ID并进行查询即可。图9-9展示了如何使用在9.1.2节中使用的Spring Cloud Sleuth 跟踪ID a9e3e1786b74d302来执行查询。

图9-9 跟踪ID可用于筛选与单个事务相关的所有日志条目
统一日志记录和对平凡的赞美
不要低估拥有一个统一的日志架构和服务关联策略的重要性。这似乎是一项平凡的任务,但在我撰写这一章的时候,我使用了类似于Papertrail的日志聚合工具为我正在开发的一个项目跟踪3个不同服务之间的竞态条件。事实表明,这个竞态条件已经存在了一年多时间了,但处于竞态条件下的服务一直运行良好,直到我们增加了一点儿负载并加入另一个参与者才导致问题出现。
我们用了1.5周的时间进行日志查询,并遍历了几十个独特场景的跟踪输出之后才发现了这个问题。如果没有聚合的日志记录平台,我们也就不会发现这个问题。这次经历再次肯定了以下几件事。
(1)确保在服务开发的早期定义和实现日志策略——一旦项目开展起来,实现日志基础设施会是一项冗长的、有时很困难的工作并且还会耗费大量时间。
(2)日志记录是微服务基础设施的一个关键部分——在实现你自己的日志记录方案或是尝试实现内部部署的日志记录方案之前,一定要再三考虑清楚。花在基于云的日志记录平台上的钱是值得的。
(3)学习日志记录工具——几乎每个日志平台都有一个查询语言来查询合并的日志。日志是信息和度量的一个极其重要的来源。它们本质上是另一种类型的数据库,花在学习查询上的时间将会带来巨大的回报。
9.2.5 使用Zuul将关联ID添加到HTTP响应
如果读者检查使用Spring Cloud Sleuth进行服务调用所返回的HTTP响应,永远不会看到在调用中使用的跟踪ID在HTTP响应首部中返回。通过查阅Spring Cloud Sleuth的文档,就会得知Spring Cloud Sleuth团队认为返回的跟踪数据可能是一个潜在的安全问题(尽管他们没有明确列出理由)。
然而,我发现,在调试问题时,在HTTP响应中返回关联ID或跟踪ID是非常重要的。Spring Cloud Sleuth允许开发人员使用其跟踪ID和跨度ID“装饰”HTTP响应信息。然而,这种做法涉及编写3个类并注入两个定制的Spring bean。如果读者想采取这种方法,可以查阅Spring Cloud Sleuth文档。一个更简单的解决方案是编写一个将在HTTP响应中注入跟踪ID的Zuul后置过滤器。
在第6章介绍Zuul API网关时,我们看到了如何构建一个Zuul后置响应过滤器,将生成的用于服务的关联ID添加到调用者返回的HTTP响应中。我们现在要修改这个过滤器以添加Spring Cloud Sleuth首部。
要创建Zuul响应过滤器,需要将JAR依赖项spring-cloud-starter-sleuth添加到Zuul服务器的pom.xml文件中。spring-cloud-starter-sleuth依赖项用于告诉Spring Cloud Sleuth,希望Zuul参与Spring Cloud跟踪。在本章稍后介绍Zipkin时,读者会看到Zuul服务将成为所有服务调用中的第一个调用。
对于第9章,这个文件可以在zuulsvr/pom.xml中找到。代码清单9-1展示了这些依赖项。
代码清单9-1 将Spring Cloud Sleuth添加到Zuul
org.springframework.cloud
spring-cloud-starter-sleuth ⇽--- 向Zuul添加spring-cloud-starter-sleuth会让在Zuul中调用的每个服务生成一个跟踪ID
添加完新的依赖项,实际的Zuul后置过滤器就很容易实现了。代码清单9-2展示了用于构建Zuul过滤器的源代码。该代码在zuulsvr/src/main/java/com/thoughtmechanix/zuulsvr/filters/ ResponseFilter.java中。
代码清单9-2 通过Zuul后置过滤器添加Spring Cloud Sleuth的跟踪ID
package com.thoughtmechanix.zuulsvr.filters;
// 为了简洁,省略了其他import语句
import org.springframework.cloud.sleuth.Tracer;
@Component
public class ResponseFilter extends ZuulFilter {
private static final int FILTER_ORDER=1;
private static final boolean SHOULD_FILTER=true;
private static final Logger logger = LoggerFactory.getLogger(ResponseFilter.class);
@Autowired ⇽--- Tracer类是访问跟踪ID和跨度ID信息的入口点
Tracer tracer;
@Override
public String filterType() {return "post";}
@Override
public int filterOrder() {return FILTER_ORDER;}
@Override
public boolean shouldFilter() {return SHOULD_FILTER;}
@Override
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
ctx.getResponse().addHeader("tmx-correlation-id",
➥ tracer.getCurrentSpan().traceIdString()); ⇽--- 添加新HTTP响应首部tmx-correlation-id,它包含Spring Cloud Sleuth的跟踪ID
return null;
}
}
因为Zuul现在已经启用了Spring Cloud Sleuth,所以可以通过自动装配Tracer类到ResponseFilter从ResponseFilter中访问跟踪信息。Tracer类可用于访问正在执行的当前Spring Cloud Sleuth跟踪信息。tracer.getCurrentSpan().traceIdString()方法以字符串的形式检索当前正在进行的事务的跟踪ID。
将跟踪ID添加到通过Zuul的传出HTTP响应是很简单的。这一步骤通过调用以下代码来完成:
RequestContext ctx = RequestContext.getCurrentContext();
ctx.getResponse().addHeader("tmx-correlation-id",
➥ tracer.getCurrentSpan().traceIdString());
有了这段代码,如果通过Zuul网关调用了一个EagleEye微服务,那么应该会得到一个名为tmx-correlation-id的HTTP响应首部。图9-10展示了调用GET http://localhost:5555/api/licensing/v1/organizations/e254f8c-c442-4ebe-a82a-
e2fc1d1ff7-8a/licenses/f3831f8c-c338-4ebe-a82a-e2fc1d1ff78a的结果。
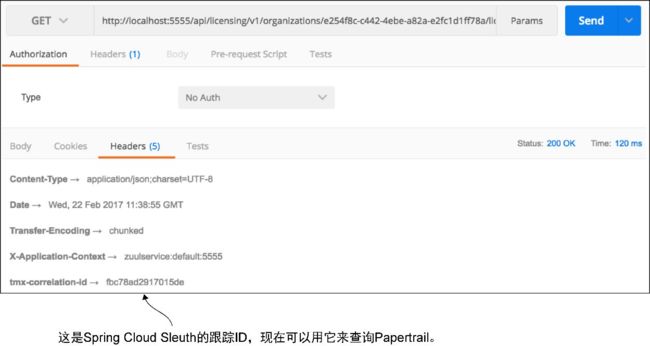
图9-10 随着Spring Cloud Sleuth的跟踪ID的返回,可以轻松地向Papertrail查询日志
9.3 使用Open Zipkin进行分布式跟踪
具有关联ID的统一日志记录平台是一个强大的调试工具。但是,在本章的剩余部分中,我们将不再关注如何跟踪日志条目,而是关注如何跨不同微服务可视化事务流。一张干净简洁的图片比一百万条日志条目有用。
分布式跟踪涉及提供一张可视化的图片,说明事务如何流经不同的微服务。分布式跟踪工具还将对单个微服务响应时间作出粗略的估计。但是,分布式跟踪工具不应该与成熟的应用程序性能管理(Application Performance Management,APM)包混淆。这些包可以为服务中的实际代码提供开箱即用的低级性能数据,除了提供响应时间,它还能提供其他性能数据,如内存利用率、CPU利用率和I/O利用率。
这就是Spring Cloud Sleuth和OpenZipkin(也称为Zipkin)项目的亮点。Zipkin是一个分布式跟踪平台,可用于跟踪跨多个服务调用的事务。Zipkin允许开发人员以图形方式查看事务占用的时间量,并分解在调用中涉及的每个微服务所用的时间。在微服务架构中,Zipkin是识别性能问题的宝贵工具。
建立Spring Cloud Sleuth和Zipkin涉及4项操作:
- 将Spring Cloud Sleuth和Zipkin JAR文件添加到捕获跟踪数据的服务中;
- 在每个服务中配置Spring属性以指向收集跟踪数据的Zipkin服务器;
- 安装和配置Zipkin服务器以收集数据;
- 定义每个客户端所使用的采样策略,便于向Zipkin发送跟踪信息。
9.3.1 添加Spring Cloud Sleuth和Zipkin依赖项
到目前为止,我们已经将两个Maven依赖项包含到Zuul服务、许可证服务以及组织服务中。这些JAR文件是 spring-cloud-starter-sleuth和spring-cloud-sleuth-core依赖项。spring-cloud-starter-sleuth依赖项用于包含在服务中启用Spring Cloud Sleuth所需的基本Spring Cloud Sleuth库。当开发人员必须要以编程方式与Spring Cloud Sleuth进行交互时,就需要使用 spring-cloud-sleuth-core依赖项(本章后面将再次使用它)。
要与Zipkin集成,需要添加第二个Maven依赖项,名为spring-cloud-sleuth-zipkin。代码清单9-3展示了添加spring-cloud-sleuth-zipkin依赖项后,在Zuul、许可证以及组织服务中应该存在的Maven条目。
代码清单9-3 客户端的Spring Cloud Sleuth和Zipkin依赖项
org.springframework.cloud
spring-cloud-starter-sleuth
org.springframework.cloud
spring-cloud-sleuth-zipkin
9.3.2 配置服务以指向Zipkin
有了JAR文件,接下来就需要配置想要与Zipkin进行通信的每一项服务。这项任务可以通过设置一个Spring属性spring.zipkin.baseUrl来完成,该属性定义了用于与Zipkin通信的URL,它设置在每个服务的application.yml属性文件中。
注意
spring.zipkin.baseUrl也可以作为Spring Cloud Config中的属性进行外部化。
在每个服务的application.yml文件中,将该值设置为http://localhost:9411。但是,在运行时,我使用在每个服务的Docker配置文件(docker/common/docker-compose.yml)上传递的ZIPKIN_URI(http://zipkin:9411)变量来覆盖这个值。
Zipkin、RabbitMQ与Kafka
Zipkin确实有能力通过RabbitMQ或Kafka将其跟踪数据发送到Zipkin服务器。从功能的角度来看,不管使用HTTP、RabbitMQ还是Kafka,Zipkin的行为没有任何差异。通过使用HTTP跟踪,Zipkin使用异步线程发送性能数据。另外,使用RabbitMQ或Kafka来收集跟踪数据的主要优势是,如果Zipkin服务器关闭,任何发送给Zipkin的跟踪信息都将“排队”,直到Zipkin能够收集到数据。
Spring Cloud Sleuth通过RabbitMQ和Kafka向Zipkin发送数据的配置在Spring Cloud Sleuth文档中有介绍,因此本章将不再赘述。
9.3.3 安装和配置Zipkin服务器
要使用Zipkin,首先需要按照本书多次所做的那样建立一个Spring Boot项目(本章的项目名为 zipkinsvr)。接下来,需要向zipkinsvr/pom.xml文件添加两个JAR依赖项。代码清单9-4展示了这两个JAR依赖项。
代码清单9-4 Zipkin服务所需的JAR依赖项
io.zipkin.java
zipkin-server ⇽--- 这个依赖项包含用于创建Zipkin服务器所需的核心类
io.zipkin.java
zipkin-autoconfigure-ui ⇽--- 这个依赖项包含用于运行Zipkin服务器的UI部分所需的核心类
选择@EnableZipkinServer还是@EnableZipkinStreamServer
关于上述JAR依赖项,有一件事需要注意,那就是它们不是基于Spring Cloud的依赖项。虽然Zipkin是一个基于Spring Boot的项目,但是
@EnableZipkinServer并不是一个Spring Cloud注解,它是Zipkin项目的一部分。这通常会让Spring Cloud Sleuth和Zipkin的新手混淆,因为Spring Cloud团队确实编写了@EnableZipkinStreamServer注解作为Spring Cloud Sleuth的一部分,它简化了Zipkin与RabbitMQ和Kafka的使用。我选择使用
@EnableZipkinServer是因为对本章来说它创建简单。使用@EnableZipkinStreamServer需要创建和配置正在跟踪的服务以发布消息到RabbitMQ或Kafka,此外,还需要设置和配置Zipkin服务器来监听RabbitMQ或Kafka,以此来跟踪数据。@EnableZipkinStreamServer注解的优点是,即使Zipkin服务器不可用,也可以继续收集跟踪数据。这是因为跟踪消息将在消息队列中累积跟踪数据,直到Zipkin服务器可用于处理消息记录。如果使用了@EnableZipkinServer注解,而Zipkin服务器不可用,那么服务发送给Zipkin的跟踪数据将会丢失。
在定义完JAR依赖项之后,现在需要将@EnableZipkinServer注解添加到Zipkin服务引导类中。这个类位于zipkinsvr/src/main/java/com/thoughtmechanix/zipkinsvr/ZipkinServerApplication.java中。代码清单9-5展示了引导类的代码。
代码清单9-5 构建Zipkin服务器引导类
package com.thoughtmechanix.zipkinsvr;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import zipkin.server.EnableZipkinServer;
@SpringBootApplication
@EnableZipkinServer ⇽--- @EnableZipkinServer 允许快速启动Zipkin作为Spring Boot项目
public class ZipkinServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinServerApplication.class, args);
}
}
在代码清单9-5中要注意的关键点是@EnableZipkinServer注解的使用。这个注解能够启动这个Spring Boot服务作为一个Zipkin服务器。此时,读者可以构建、编译和启动Zipkin服务器,作为本章的Docker容器之一。
运行Zipkin服务器只需要很少的配置。在运行Zipkin服务器时,唯一需要配置的东西,就是Zipkin存储来自服务的跟踪数据的后端数据存储。Zipkin支持4种不同的后端数据存储。这些数据存储是:
(1)内存数据;
(2)MySQL;
(3)Cassandra;
(4)Elasticsearch。
在默认情况下,Zipkin使用内存数据存储来存储跟踪数据。Zipkin团队建议不要在生产系统中使用内存数据库。内存数据库只能容纳有限的数据,并且在Zipkin服务器关闭或丢失时,数据就会丢失。
注意
对于本书来讲,我们将使用
Zipkin的内存数据存储。配置Zipkin中使用的各个数据存储超出了本书的范围,但是,如果读者对这个主题感兴趣,可以在Zipkin GitHub存储库中查阅更多信息。
9.3.4 设置跟踪级别
到目前为止,我们已经配置了要与Zipkin服务器通信的客户端,并且已经配置完Zipkin服务器准备运行。在开始使用Zipkin之前,我们还需要再做一件事情,那就是定义每个服务应该向Zipkin写入数据的频率。
在默认情况下,Zipkin只会将所有事务的10%写入Zipkin服务器。可以通过在每一个向Zipkin发送数据的服务上设置一个Spring属性来控制事务采样。这个属性叫spring.sleuth.sampler.percentage,它的值介于0和1之间。
- 值为0表示Spring Cloud Sleuth不会发送任何事务数据。
- 值为0.5表示Spring Cloud Sleuth将发送所有事务的50%。
对于本章来讲,我们将为所有服务发送跟踪信息。要做到这一点,我们可以设置spring.sleuth.sampler.percentage的值,也可以使用AlwaysSampler替换Spring Cloud Sleuth中使用的默认Sampler类。AlwaysSampler可以作为Spring Bean注入应用程序中。例如,许可证服务在licensing-service/src/main/java/com/thoughtmechanix/licenses/Application.java 中将AlwaysSampler定义为Spring Bean。
@Bean
public Sampler defaultSampler() { return new AlwaysSampler();}
Zuul服务、许可证服务和组织服务都定义了AlwaysSampler,因此在本章中,所有的事务都会被Zipkin跟踪。
9.3.5 使用Zipkin跟踪事务
让我们以一个场景来开始这一节。假设你是EagleEye 应用程序的一名开发人员,并且你在这周处于待命状态。你从客户那里收到一张工单,他抱怨说EagleEye应用程序的某一部分现在运行缓慢。你怀疑是许可证服务导致的,但问题是,为什么它会运行缓慢呢?问题究竟出在了哪里呢?许可证服务依赖于组织服务,而这两个服务都对不同的数据库进行调用。究竟是哪个服务表现不佳?此外,你知道这些服务正在不断被迭代更新,因此有人可能添加了一个新的服务调用。了解参与用户事务的所有服务以及它们的性能时间对于支持分布式架构(如微服务架构)是至关重要的。
接下来,你将开始使用Zipkin来观察来自组织服务的两个事务(它们由Zipkin服务进行跟踪)。组织服务是一个简单的服务,它只对单个数据库进行调用。你所要做的就是使用POSTMAN向组织服务发送两个调用(对http://localhost:5555/api/organization/v1/organizations/e254f8c-c442-4ebe-
a82a-e2fc1d1ff78a发起GET请求)。组织服务调用将流经Zuul API网关,然后再将调用定向到下游组织服务实例。
调用了两次组织服务之后,转到http://localhost:9411,看看Zipkin已经捕获的跟踪结果。从界面左上角的下拉框中选择“organizationservice”,然后点击“Find traces”按钮。图9-11展示了操作后的Zipkin查询界面。

图9-11 可以在Zipkin的查询界面选择想要跟踪的服务以及一些基本的查询过滤器
现在,如果读者查看图9-11中的屏幕截图,就会发现Zipkin捕获了两个事务,每个事务都被分解为一个或多个跨度(span)。在Zipkin中,一个跨度代表一个特定的服务或调用,Zipkin会捕获每一个跨度的计时信息。图9-11中的每一个事务都包含3个跨度:两个跨度在Zuul网关中,还有一个是组织服务。记住,Zuul网关不会盲目地转发HTTP调用。它接收传入的HTTP调用并终止这个调用,然后构建一个新的到目标服务的调用(在本例中是组织服务)。原始调用的终止是因为Zuul要添加前置过滤器、路由过滤器以及后置过滤器到进入该网关的每一个调用。这就是我们在Zuul服务中看到两个跨度的原因。
通过Zuul对组织服务的两次调用分别用了3.204 s和77.2365 ms。因为查询的是组织服务调用(而不是Zuul网关调用),从图9-11中可以看到组织服务在总事务时间中占了92%和72%。
让我们深入了解运行时间最长的调用(3.204 s)的细节。读者可以通过点击事务并深入了解细节来查看更多详细信息。图9-12展示了点击了解更多细节后的详细信息。

图9-12 可以使用Zipkin查看事务中每个跨度所用的时间
在图9-12中可以看到,从Zuul角度来看,整个事务大约需要3.204 s。然而,Zuul发出的组织服务调用耗费了整个调用过程3.204 s中的2.967 s。图中展示的每个跨度都可以深入到更多的细节。点击组织服务跨度,并查看可以从这个调用中看到哪些额外的细节。图9-13展示了这个调用的细节。
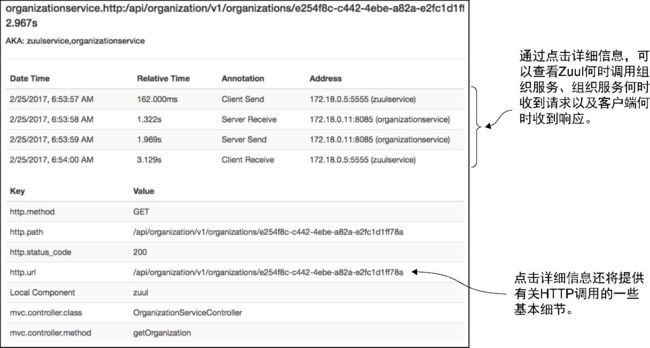
图9-13 点击单个跨度会获得更多关于调用时间和HTTP调用细节的详细信息
图9-13中最有价值的信息之一是客户端(Zuul)何时调用组织服务、组织服务何时接收到调用以及组织服务何时作出响应等分解信息。这种类型的计时信息在检测和识别网络延迟问题方面是非常宝贵的。
9.3.6 可视化更复杂的事务
如果想要确切了解服务调用之间存在哪些服务依赖关系,该怎么办?我们可以通过Zuul调用许可证服务,然后向Zipkin查询许可证服务的跟踪。这项工作可以通过对许可证服务的http://localhost:5555/api/licensing/v1/organizations/e254f8c-c442-4ebe-a82a
-e2fc1d1ff78a/licenses/f3831f8c-c338-4ebe-a82a-e2fc1d1ff78a端点进行GET调用来完成。
图9-14展示了调用许可证服务的详细跟踪。

图9-14 查看许可证服务调用如何从Zuul流向许可证服务然后流向组织服务的跟踪详情
在图9-14中,可以看到对许可证服务的调用涉及4个离散的HTTP调用。首先是对Zuul网关的调用,然后从Zuul网关到许可证服务,接下来许可证服务通过Zuul调用组织服务。
9.3.7 捕获消息传递跟踪
Spring Cloud Sleuth和Zipkin不仅会跟踪HTTP调用,Spring Cloud Sleuth还会向Zipkin发送在服务中注册的入站或出站消息通道上的跟踪数据。
消息传递可能会在应用程序内引发它自己的性能和延迟问题。这句话的意思是,服务可能无法快速处理队列中的消息,或者可能存在网络延迟问题。在构建基于微服务的应用程序时,我遇到了所有这些情况。
通过使用Spring Cloud Sleuth和Zipkin,开发人员可以确定何时从队列发布消息以及何时收到消息。除此之外,开发人员还可以查看在队列中接收到消息并进行处理时发生了什么行为。
正如读者在第8章中记得的,每次添加、更新或删除一条组织记录时,就会生成一条Kafka消息并通过Spring Cloud Stream发布。许可证服务接收消息,并更新用于缓存数据的Redis键值存储。
现在,我们将删除组织记录,并观察由Spring Cloud Sleuth和Zipkin跟踪的事务。读者可以通过POSTMAN向组织服务发出DELETE http://local-host:5555/api/organization/v1/organizations/e254f8c-c442-
4ebe-a82a-e2fc1d1ff78a请求。
记住,在本章前面,我们了解了如何将跟踪ID添加为HTTP响应首部。我们添加了一个名为tmx-correlation-id的新HTTP响应首部。在我的调用中,这个tmx-correlation-id返回值是5e14cae0d90dc8d4。读者可以通过在Zipkin查询界面右上角的搜索框中输入调用所返回的跟踪ID,来向Zipkin搜索这个特定的跟踪ID。图9-15展示了可以在哪里输入跟踪ID。

图9-15 通过在HTTP响应tmx-correlation-id字段中返回的跟踪ID,可以轻松找到要查找的事务
有了跟踪ID就可以向Zipkin查询特定的事务,并可以查看到删除消息发布到输出消息通道。此消息通道output 用于发布消息到名为orgChangeTopic的主题。图9-16展示了output消息通道及其在Zipkin跟踪中的表现。

图9-16 Spring Cloud Sleuth将自动跟踪Spring消息通道上消息的发布和接收
通过查询Zipkin并搜索收到的消息可以看到许可证服务收到消息。遗憾的是,Spring Cloud Sleuth不会将已发布消息的跟踪ID传播给消息的消费者。相反,它会生成一个新的跟踪ID。但是,我们可以向Zipkin服务器查询所有许可证服务的事务,并通过最新消息对事务进行排序。图9-17展示了这个查询的结果。

图9-17 寻找接收到Kafka消息的许可证服务调用
既然已经找到目标许可证服务的事务,我们就可以深入了解这个事务。图9-18展示了这次深入探查的结果。

图9-18 使用Zipkin可以看到组织服务发布的Kafka消息
到目前为止,我们已经使用Zipkin来跟踪服务中的HTTP和消息传递调用。但是,如果要对未由Zipkin 检测的第三方服务执行跟踪,那该怎么办呢?例如,如果想要获取对Redis或PostgresSQL调用的特定跟踪和计时信息,该怎么办呢?幸运的是,Spring Cloud Sleuth和Zipkin允许开发人员为事务添加自定义跨度,以便跟踪与这些第三方调用相关的执行时间。
9.3.8 添加自定义跨度
在Zipkin中添加自定义跨度是非常容易的。我们可以从向许可证服务添加一个自定义跨度开始,这样就可以跟踪从Redis中提取数据所需的时间。然后,我们将向组织服务添加自定义跨度,以查看从组织数据库中检索数据需要多长时间。
为了将一个自定义跨度添加到许可证服务对Redis的调用中,我们需要修改licensing- service/src/main/java/com/thoughtmechanix/licenses/clients/OrganizationRestTemplateClient.java中的OrganizationRestTemplateClient类的checkRedisCache()方法。代码清单9-6展示了这段代码。
代码清单9-6 对从Redis读取许可证数据的调用添加监测代码
import org.springframework.cloud.sleuth.Tracer;
// 为了简洁,省略了其余的import语句
@Component
public class OrganizationRestTemplateClient {
@Autowired
RestTemplate restTemplate;
@Autowired
Tracer tracer; ⇽--- Tracer类用于以编程方式访问Spring Cloud Sleuth跟踪信息
@Autowired
OrganizationRedisRepository orgRedisRepo;
private static final Logger logger =
➥ LoggerFactory.getLogger(OrganizationRestTemplateClient.class);
private Organization checkRedisCache(String organizationId) {
Span newSpan = tracer.createSpan("readLicensingDataFromRedis"); ⇽--- 创建一个新的自定义跨度,其名为readLicensingDataFromRedis
try {
return orgRedisRepo.findOrganization(organizationId);
}
catch (Exception ex){
logger.error("Error encountered while
➥ trying to retrieve organization {} check Redis Cache. Exception {}",
➥ organizationId, ex);
return null;
}
finally { ⇽--- 使用Finally块关闭跨度
newSpan.tag("peer.service", "redis"); ⇽--- 可以将标签信息添加到跨度中。在这个类中,我们提供了将要被Zipkin捕获的服务的名称
newSpan.logEvent(org.springframework.cloud.sleuth.Span.CLIENT_RECV); ⇽--- 记录一个事件,告诉Spring Cloud Sleuth它应该捕获调用完成的时间
tracer.close(newSpan); ⇽--- 关闭跟踪。如果不调用close()方法,则会在日志中得到错误消息,指示跨度已被打开却尚未被关闭
}
}
// 为了简洁,省略了类的其余部分
}
代码清单9-6中的代码创建了一个名为readLicensingDataFromRedis的自定义跨度。接下来,我们将同样添加一个名为getOrgDbCall的自定义跨度到组织服务中,以监控从Postgres数据库中检索组织数据需要多长时间。对组织服务数据库的调用跟踪可以在organization-service/src/main/java/com/thoughtmechanix/organization/
services/OrganizationService.java中的OrganizationService类中看到。其中,getOrg()方法包含自定义跟踪。代码清单9-7展示了组织服务的getOrg()方法的源代码。
代码清单9-7 添加了监测代码的getOrg()方法
package com.thoughtmechanix.organization.services;
// 为了简洁,省略了import语句
@Service
public class OrganizationService {
@Autowired
private OrganizationRepository orgRepository;
@Autowired
private Tracer tracer;
@Autowired
SimpleSourceBean simpleSourceBean;
private static final Logger logger =
➥ LoggerFactory.getLogger(OrganizationService.class);
public Organization getOrg (String organizationId) {
Span newSpan = tracer.createSpan("getOrgDBCall");
logger.debug("In the organizationService.getOrg() call");
try {
return orgRepository.findById(organizationId);
} finally {
newSpan.tag("peer.service", "postgres");
newSpan.logEvent(org.springframework.cloud.sleuth.Span.CLIENT_RECV);
tracer.close(newSpan);
}
}
// 为了简洁,省略了其余的代码
}
有了这两个自定义跨度,我们就可以重启服务,然后访问GET http://localhost:5555/api/licensing/v1/organizations/e254f8c-c442-
4ebe-a82a-e2fc1d1ff78a/licenses/f3831f8c-c338-4ebe-a82a-e2fc1d1ff78a端点。如果在Zipkin中查看事务,应该看到增加了两个额外的跨度。图9-19展示了在调用许可证服务端点来检索许可证信息时添加的额外的自定义跨度。

图9-19 定义了自定义跨度之后,它们将出现在事务跟踪中
从图9-19中,我们可以看到与Redis和数据库查询相关的附加跟踪和计时信息。由图9-19可知,对Redis的调用用了1.099 ms。由于调用没有在Redis缓存中找到记录,所以对Postgres数据库的SQL调用用了4.784 ms。
9.4 小结
- Spring Cloud Sleuth可以无缝地将跟踪信息(关联ID)添加到微服务调用中。
- 关联ID可用于在多个服务之间链接日志条目。可以使用关联ID查看在单个事务中涉及的所有服务的事务行为。
- 虽然关联ID功能强大,但需要将此概念与日志聚合平台结合使用,以便从多个来源获取日志,然后搜索和查询它们的内容。
- 虽然存在多个内部部署的日志聚合平台,但基于云的服务可以让开发人员在不必拥有大量基础设施的情况下,对日志进行管理。此外,它们还可以在应用程序日志记录量增长时轻松扩大。
- 可以将Docker容器与日志聚合平台集成,来捕获正在写入容器stdout/stderr的所有日志记录数据。在本章中,我们将Docker容器、Logspout以及在线云日志记录供应商Papertrail集成,以捕获和查询日志。
- 虽然统一的日志记录平台很重要,但通过微服务来可视化地跟踪事务的能力也是一个有价值的工具。
- Zipkin可以让开发人员在对服务进行调用时查看服务之间存在的依赖关系。
- Spring Cloud Sleuth与Zipkin集成,Zipkin可以让开发人员以图形方式查看事务流程,并了解用户事务中涉及的每个微服务的性能特征。
- 在启用Spring Cloud Sleuth的服务中,Spring Cloud Sleuth将自动捕获HTTP 调用以及入站和出站消息通道的跟踪数据。
- Spring Cloud Sleuth将每个服务调用映射到一个跨度的概念。可以使用Zipkin来查看一个跨度的性能。
- Spring Cloud Sleuth和Zipkin还允许开发人员自定义跨度,以便了解基于非Spring的资源(如Postgres或Redis等数据库服务器)的性能。
源码地址
https://github.com/WaterMoonMirror/spmia-chapter9
,但基于云的服务可以让开发人员在不必拥有大量基础设施的情况下,对日志进行管理。此外,它们还可以在应用程序日志记录量增长时轻松扩大。
- 可以将Docker容器与日志聚合平台集成,来捕获正在写入容器stdout/stderr的所有日志记录数据。在本章中,我们将Docker容器、Logspout以及在线云日志记录供应商Papertrail集成,以捕获和查询日志。
- 虽然统一的日志记录平台很重要,但通过微服务来可视化地跟踪事务的能力也是一个有价值的工具。
- Zipkin可以让开发人员在对服务进行调用时查看服务之间存在的依赖关系。
- Spring Cloud Sleuth与Zipkin集成,Zipkin可以让开发人员以图形方式查看事务流程,并了解用户事务中涉及的每个微服务的性能特征。
- 在启用Spring Cloud Sleuth的服务中,Spring Cloud Sleuth将自动捕获HTTP 调用以及入站和出站消息通道的跟踪数据。
- Spring Cloud Sleuth将每个服务调用映射到一个跨度的概念。可以使用Zipkin来查看一个跨度的性能。
- Spring Cloud Sleuth和Zipkin还允许开发人员自定义跨度,以便了解基于非Spring的资源(如Postgres或Redis等数据库服务器)的性能。
源码地址
https://github.com/WaterMoonMirror/spmia-chapter9