Pytorch深度学习实践第十三讲 循环神经网络(高级篇)
B站 刘二大人 传送门 循环神经网络(高级篇)
课件链接:https://pan.baidu.com/s/1vZ27gKp8Pl-qICn_p2PaSw
提取码:cxe4
这一节代码较多,思路也比前面复杂一些,先把思路滤清再放代码。代码中有大量注释,视频看得很明白的同学可以直接看代码。还是那句话,搭配视频学习效果最佳。
利用pytorch封装的GRU网络,要训练的是人名和国家对应的数据集,输入是人名,判断人名所属的国家。
先看数据集
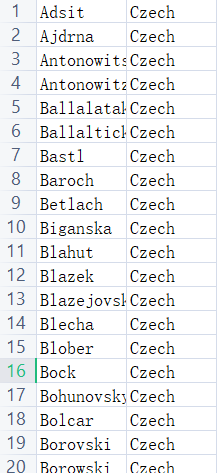
人名字符长短不一,最长的10个字符,所以处理成10维输入张量,都是英文字母刚好可以映射到ASCII上。
例如,
Maclean
-> ['M', 'a', 'c', 'l', 'e', 'a', 'n']
-> [ 77 97 99 108 101 97 110]
-> [ 77 97 99 108 101 97 110 0 0 0]
共有18个国家,设置索引为0-17
看一下下面这个网络。
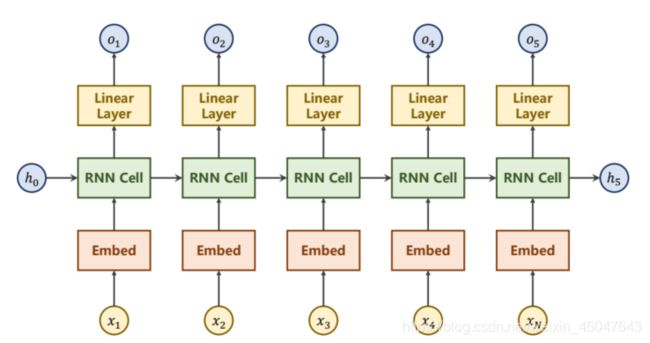
输入之后接一个embedding之后到GRU训练,再之后接一个线性层输出分类概率。和上面网络稍有不同的是改成了下面的双向传播网络,由于是封装函数,直接在参数上设置bidirectional=2即可。
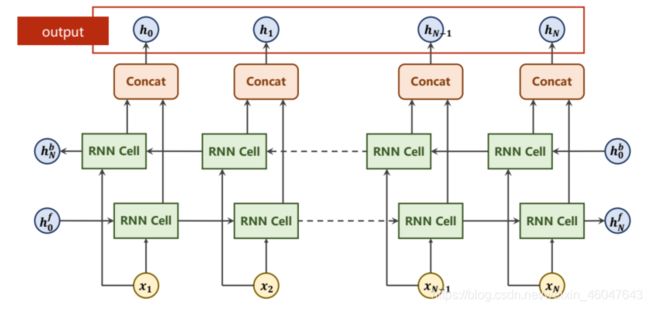
和老师的计时方法不同,老师的代码每训练一轮都要输出时间,我改成了运行结束直接输出时间,另外老师在训练过程中设置的输出太多,我把输出也简化了。
视频中讲到为加速网络的训练需要把输入格式修改一下再作为GRU的输入,
gru_input = torch.nn.utils.rnn.pack_padded_sequence(embedding, seq_lengths)
#让0值不参与运算加快运算速度的方式
#需要提前把输入按有效值长度降序排列 再对输入做嵌入,然后按每个输入len(seq——lengths)取值做为GRU输入
上面这行代码能加快神经网络的运算,就是处理输入的代码量比较大,视频中对处理方式有介绍,另外我在代码里也写了很多注释。
'''
根据名字识别他所在的国家
人名字符长短不一,最长的10个字符,所以处理成10维输入张量,都是英文字母刚好可以映射到ASCII上
Maclean -> ['M', 'a', 'c', 'l', 'e', 'a', 'n'] -> [ 77 97 99 108 101 97 110] -> [ 77 97 99 108 101 97 110 0 0 0]
共有18个国家,设置索引为0-17
训练集和测试集的表格文件都是第一列人名,第二列国家
'''
import torch
import time
import csv
import gzip
from torch.utils.data import DataLoader
import datetime
import matplotlib.pyplot as plt
import numpy as np
# Parameters
HIDDEN_SIZE = 100
BATCH_SIZE = 256
N_LAYER = 2
N_EPOCHS = 100
N_CHARS = 128
USE_GPU = True
class NameDataset(): #处理数据集
def __init__(self, is_train_set=True):
filename = 'data/names_train.csv.gz' if is_train_set else 'data/names_test.csv.gz'
with gzip.open(filename, 'rt') as f: #打开压缩文件并将变量名设为为f
reader = csv.reader(f) #读取表格文件
rows = list(reader)
self.names = [row[0] for row in rows] #取出人名
self.len = len(self.names) #人名数量
self.countries = [row[1] for row in rows]#取出国家名
self.country_list = list(sorted(set(self.countries)))#国家名集合,18个国家名的集合
#countrys是所有国家名,set(countrys)把所有国家明元素设为集合(去除重复项),sorted()函数是将集合排序
#测试了一下,实际list(sorted(set(self.countrys)))==sorted(set(self.countrys))
self.country_dict = self.getCountryDict()#转变成词典
self.country_num = len(self.country_list)#得到国家集合的长度18
def __getitem__(self, index):
return self.names[index], self.country_dict[self.countries[index]]
def __len__(self):
return self.len
def getCountryDict(self):
country_dict = dict() #创建空字典
for idx, country_name in enumerate(self.country_list,0): #取出序号和对应国家名
country_dict[country_name] = idx #把对应的国家名和序号存入字典
return country_dict
def idx2country(self,index): #返回索引对应国家名
return self.country_list(index)
def getCountrysNum(self): #返回国家数量
return self.country_num
trainset = NameDataset(is_train_set=True)
trainloader = DataLoader(trainset, batch_size=BATCH_SIZE,shuffle=True)
testset = NameDataset(is_train_set=False)
testloader = DataLoader(testset, batch_size=BATCH_SIZE,shuffle=False)
N_COUNTRY = trainset.getCountrysNum() #模型输出大小
def create_tensor(tensor):#判断是否使用GPU 使用的话把tensor搬到GPU上去
if USE_GPU:
device = torch.device("cuda:0")
tensor = tensor.to(device)
return tensor
class RNNClassifier(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size, n_layers=1, bidirectional=True):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size #包括下面的n_layers在GRU模型里使用
self.n_layers = n_layers
self.n_directions = 2 if bidirectional else 1
self.embedding = torch.nn.Embedding(input_size, hidden_size)#input.shape=(seqlen,batch) output.shape=(seqlen,batch,hiddensize)
self.gru = torch.nn.GRU(hidden_size, hidden_size, n_layers, bidirectional=bidirectional)
#输入维度 输出维度 层数 说明单向还是双向
self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size)#双向GRU会输出两个hidden,维度需要✖2,要接一个线性层
def forward(self, input, seq_lengths):
input = input.t() #input shaoe : Batch x Seq -> S x B 用于embedding
batch_size = input.size(1)
hidden =self._init_hidden(batch_size)
embedding = self.embedding(input)
# pack_padded_sequence函数当出入seq_lengths是GPU张量时报错,在这里改成cpu张量就可以,不用GPU直接注释掉下面这一行代码
seq_lengths = seq_lengths.cpu()#改成cpu张量
# pack them up
gru_input = torch.nn.utils.rnn.pack_padded_sequence(embedding, seq_lengths)#让0值不参与运算加快运算速度的方式
#需要提前把输入按有效值长度降序排列 再对输入做嵌入,然后按每个输入len(seq——lengths)取值做为GRU输入
output, hidden = self.gru(gru_input, hidden)#双向传播的话hidden有两个
if self.n_directions ==2:
hidden_cat = torch.cat([hidden[-1], hidden[-2]], dim=1)
else:
hidden_cat = hidden[-1]
fc_output = self.fc(hidden_cat)
return fc_output
def _init_hidden(self,batch_size):
hidden = torch.zeros(self.n_layers * self.n_directions, batch_size, self.hidden_size)
return create_tensor(hidden)
#classifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER)
#对名字的处理需要先把每个名字按字符都变成ASCII码
def name2list(name):#把每个名字按字符都变成ASCII码
arr = [ord(c) for c in name]
return arr, len(arr)
def make_tensors(names, countries): #处理名字ASCII码 重新排序的长度和国家列表
sequences_and_lengths= [name2list(name) for name in names] #把每个名字按字符都变成ASCII码
name_sequences = [sl[0] for sl in sequences_and_lengths] #取出名字列表对应的ACSII码
seq_lengths = torch.LongTensor([sl[1] for sl in sequences_and_lengths]) #取出每个名字对应的长度列表
countries = countries.long()
# make tensor of name, BatchSize x SeqLen
seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long() #先做一个 名字数量x最长名字长度的全0tensor
for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_lengths), 0): #取出序列,ACSII码和长度列表
seq_tensor[idx, :seq_len] = torch.LongTensor(seq) #用名字列表的ACSII码填充上面的全0tensor
# sort by length to use pack_padded_sequence
seq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=True)#将seq_lengths按序列长度重新降序排序,返回排序结果和排序序列。
seq_tensor = seq_tensor[perm_idx] #按新序列把ASCII表重新排序
countries = countries[perm_idx] #按新序列把国家列表重新排序
#返回排序后的 ASCII列表 名字长度降序列表 国家名列表
return create_tensor(seq_tensor),create_tensor(seq_lengths),create_tensor(countries)
def trainModel():
total_loss = 0
for i, (names, countries) in enumerate(trainloader, 1):
optimizer.zero_grad()
inputs, seq_lengths, target = make_tensors(names, countries)#取出排序后的 ASCII列表 名字长度列表 国家名列表
output = classifier(inputs, seq_lengths) #把输入和序列放入分类器
loss = criterion(output, target) #计算损失
loss.backward()
optimizer.step()
total_loss += loss.item()
#打印输出结果
#if i % 100 == 0:
# print(f'Epoch {epoch} ')
if i == len(trainset) // BATCH_SIZE :
#print(f'[13374/{len(trainset)}] ', end='')
print(f'loss={total_loss / (i * len(inputs))}')
'''elif i % 10 == 9 :
print(f'[{i * len(inputs)}/{len(trainset)}] ', end='')
print(f'loss={total_loss / (i * len(inputs))}')'''
return total_loss
def testModel():
correct = 0
total = len(testset)
with torch.no_grad():
for i, (names, countries) in enumerate(testloader, 1):
inputs, seq_lengths, target = make_tensors(names, countries) #返回处理后的名字ASCII码 重新排序的长度和国家列表
output = classifier(inputs, seq_lengths) #输出
pred = output.max(dim=1, keepdim=True)[1] #预测
correct += pred.eq(target.view_as(pred)).sum().item() #计算预测对了多少
percent = '%.2f' % (100 * correct / total)
print(f'Test set: Accuracy {correct}/{total} {percent}%')
return correct / total
if __name__ == '__main__':
print("Train for %d epochs..." % N_EPOCHS)
start = time.time()
classifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER)
if USE_GPU:
device = torch.device('cuda:0')
classifier.to(device)
criterion = torch.nn.CrossEntropyLoss() #计算损失
optimizer = torch.optim.Adam(classifier.parameters(), lr = 0.001) #更新
acc_list= []
for epoch in range(1, N_EPOCHS+1):
#训练
print('%d / %d:' % (epoch, N_EPOCHS))
trainModel()
acc = testModel()
acc_list.append(acc)
end = time.time()
print(datetime.timedelta(seconds=(end - start) // 1))
epoch = np.arange(1, len(acc_list) + 1, 1)
acc_list = np.array(acc_list)
plt.plot(epoch, acc_list)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.grid()
plt.show()
下面是运行结果输出,最好结果在训练16次的时候得到。


