八、(机器学习)-Tensorflow-CNN实现Cifar-10图像识别
Tensorflow-CNN原理及实现Cifar10图像识别
说明: 在官方网址有很多的示例代码,但是大多都对数据进行复杂的处理,对于初学者来说还是有很大的困难程度,我在这里使用一些简单的操作来实现图像识别的功能,一些简单易懂的操作会帮助你更好的学习Tensorflow-CNN
1、什么是神经网络
在进行分类和回归任务中,有有很多的机器学习算法可以实现,那么为什么还有使用神经网络呢?在我们使用机器学习的过程中,我们要先明确feature和label,然后将这个数据喂到算法中去训练,最后保存模型,在来预测分类的准确性,但是这就有个问题,我们需要实现确认好特征,每一个特征就是一个维度,特征数目少,我们可能无法精确的分类出来,这就是欠拟合,如何特征数目太多,可能会导致我们在分类的过程中注重某个特征导致分类错误,即过拟合。
举个简单的例子,现在有一堆数据集,让我们分类出西瓜和冬瓜,如果只有两个特征:形状和颜色,可能没法分区来;如果特征的维度有:形状、颜色、瓜瓤颜色、瓜皮的花纹等等,可能很容易分类出来;如果我们的特征是:形状、颜色、瓜瓤颜色、瓜皮花纹、瓜蒂、瓜籽的数量,瓜籽的颜色、瓜籽的大小、瓜籽的分布情况、瓜籽的XXX等等,很有可能会过拟合,譬如有的冬瓜的瓜籽数量和西瓜的类似,模型训练后这类特征的权重较高,就很容易分错。这就导致我们在特征工程上需要花很多时间和精力,才能使模型训练得到一个好的效果。然而神经网络的出现使我们不需要做大量的特征工程,譬如提前设计好特征的内容或者说特征的数量等等,我们可以直接把数据灌进去,让它自己训练,自我“修正”,即可得到一个较好的效果。
2、为什么要使用神经网路
前面说到在图像领域,用传统的神经网络并不合适。我们知道,图像是由一个个像素点构成,每个像素点有三个通道,分别代表RGB颜色,那么,如果一个图像的尺寸是(28,28,1),即代表这个图像的是一个长宽均为28,channel为1的图像(channel也叫depth,此处1代表灰色图像)。如果使用全连接的网络结构,即,网络中的神经与与相邻层上的每个神经元均连接,那就意味着我们的网络有28 * 28 =784个神经元,hidden层采用了15个神经元,那么简单计算一下,我们需要的参数个数(w和b)就有:784*15+15×10+15+10个,这个参数太多了,随便进行一次反向传播计算量都是巨大的,从计算资源和调参的角度都不建议用传统的神经网络。
 3、Cifar10数据集说明
3、Cifar10数据集说明
CIFAR-10是一个更接近普适物体的彩色图像数据集。CIFAR-10 是由Hinton 的学生Alex Krizhevsky 和Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含10 个类别的RGB 彩色图片:飞机( airplane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。
每个图片的尺寸为32 × 32 ,每个类别有6000个图像,数据集中一共有50000 张训练图片和10000 张测试图片。
 在官方网址有很多的示例代码,但是大多都对数据进行复杂的处理,对于初学者来说还是有很大的困难程度,我在这里使用一些简单的操作来实现图像识别的功能,一些简单易懂的操作会帮助你更好的学习Tensorflow-CNN
在官方网址有很多的示例代码,但是大多都对数据进行复杂的处理,对于初学者来说还是有很大的困难程度,我在这里使用一些简单的操作来实现图像识别的功能,一些简单易懂的操作会帮助你更好的学习Tensorflow-CNN
 4、使用Jupyter notebook实现Cifar10图像识别
4、使用Jupyter notebook实现Cifar10图像识别
导包
# 导包
import warnings
warnings.filterwarning('ignore')
import pickle # 官方提供的读取数据的模块
import tensorflow as tf
from sklearn.preprocessiong import OneHotEncoder
数据加载
def unpickle(file):
with open(file, 'rb')as fo:
dict = pickle.load(fo, encoding='ISO-8859-1')
return dict
labels = [] # 存放图片的分类
X_train = [] # 存放图片的数据
for i in range(1, 6):
data = unpickle('./cifar-10-batches-py/data_batch_%d'%(i))
labels.append(data['labels'])
X_train.append(data['data'])
X_train = np.array(X_train) # 将list转换为ndarray
X_train = np.transpose(X_train.reshape(-1, 3, 32, 32), [0, 2, 3, 1]).reshape(-1, 3072)
y_train = np.array(labels).reshape(-1)
X_train = X_train.reshape(-1, 3072)
# 转换目标值概率
one_hot = OneHotEncoder()
y_train = one_hot.fit_transform(y_train.reshape(-1, 1)).toarray()
# 测试数据加载
test = unpickle('./cifar-10-batches-py/test_batch')
X_test = test['data']
X_test = np.transpose(X_test.reshape(-1, 3, 32, 32), [0, 2, 3, 1]).reshape(-1, 3027)
y_test = one_hot.transform(np.array(test['labels']).reshape(-1, 1)).toarray()
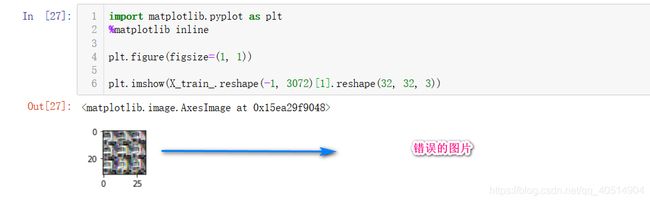
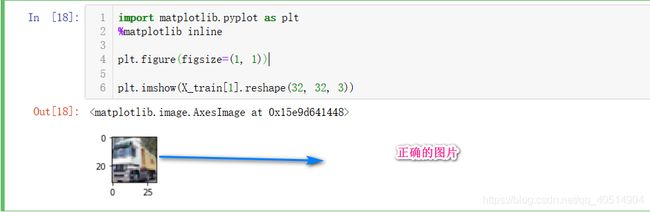
注意:X_train = np.transpose(X_train.reshape(-1, 3, 32, 32), [0, 2, 3, 1]).reshape(-1, 3027) X_train 的第一维度为样本的数量,第二维度为RGB通道,第三维度为图片样本的宽,第四维度为图片样本的长。 所以需要利用transpose进行维度之间的转换,否则画出的图像将是错误的。
 构建神经网络
构建神经网络
# 定义占位符
X = tf.placeholder(dtype = tf.float32, shape = [None, 3072])
y = tf.placeholder(dtype = tf.float32, shaoe = [None, 10])
kp = tf.placeholder(dtype = tf.float32)
# 定义变量
def gen_v(shape, std = 5e-2):
return tf.Variable(tf.truncated_normal(shape = shape, stddev = std))
def conv(input_, filter_, b):
conv = tf.nn.conv2d(input_, filter_, strides = [1, 1, 1, 1], padding='SAME') + b # 卷积
conv = tf.layers.batch_normalization(conv, training=True) # 归一化
conv = tf.nn.relu(conv) # 激活
return tn.nn.max_pool(conv, [1, 3, 3, 1], [1, 2, 2, 1], 'SAME') # 池化
# 形状改变,4维
def net_work(X, kp):
input_ = tf.reshape(X, shape = [-1, 32, 32, 3])
# 第一层
filter1 = gen_v(shape = [3, 3, 3, 64]) # 定义卷积核
b1 = gen_v(shape=[64])
pool1 = conv(input_, filter1, b1)
# 第二层
filter2 = gen_v([3, 3, 64, 128])
b2 = gen_v(shape = [128])
pool2 = conv(pool1, filter2, b2)
# 第三层
filter3 = gen_v([3, 3, 128, 256])
b3 = gen_v([256])
pool3 = conv(pool2, filter3, b3)
# 第一次全连接层
dense = tf.reshape(pool3, shape = [-1, 4*4*256])
fcl_w = gen_v(shape = [4*4*256, 1024])
fcl_b = gen_v(shape = [1024])
bn_fc_1 = tf.layers.batch_normalization(tf.matmul(dense, fcl_w) + fcl_b, training = True)
relu_fu_1 = tf.nn.relu(bn_fc_1)
# 期望 fc1.shape = [-1, 1024]
# 抛弃
'''
每次选择部分的特征,类似套袋,防止过拟合
keep_prob:每次选择的数据所占全部数据的比例
rate:每次不选择的数据所占全部数据的比例
'''
dp = tf.nn.dropout(relu_fu_1, keep_prob = kp)
# 输出层
out_w = gen_v(shape = [1024, 10])
out_b = gen_v(shape = [10])
out = tf.matmul(dp, out_w) + out_b
return out
损失函数准确率&最优化
tf.equal()、tf.cast()的使用 equal() 判断x,y对象是否相等 cast() 将bool'型结果转化为0, 1 reduce_mean() 计算准确率



out = net_work(X, kp) # 次数X和kp都是用占位符,之后进行数据的输入
# 使用交叉熵
loss = tf.reduce_mean(tf.nn.softmax_corss_entroy_with_logits_v2(labels = y, logits = out))
# 准确率
y_ = tf.nn.softmax(out)
equal = tf.equal(tf.argmax(y, axis = -1), tf.argmax(y_, axis = 1))
accuracy = tf.reduce_mean(tf.cast(euqal, tf.float32))
# 最优化
opt = tf.train.AdamOptimizer(learning_rate = 0.01).minimize(loss)
opt
开始训练
saver = tf.train.Saver()
# 从总数据中获取一批数据
index = 0
def next_batch(X, y):
global index
batch_X = X[index*128:(index + 1)*128]
batch_y = y[index*128:(index + 1)*128]
index += 1
if index == 390:
index = 0
return batch_X, batch_y
EPOCHES = 100
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(EPOCHES):
batch_X, batch_y = next_batch(X_train , y_train)
opt_, loss_ = score_train = sess.run([opt, loss, accuracy], feed_dict = {X:batch_X, y:batch_y, kp:0.5})
print('iter count:%d, mini_batch loss:%0.4f,train accuracy:%0.4f'%(i+1, loss_, score_train))
if score_train > 0.6: # 当训练准确率达到0.6时保存模型
saver.save(sess, './model/estimator', i+1)
saver.save(sess, './model/estimator', i+1) # 如果都小于0.6,则保存最后一个模型
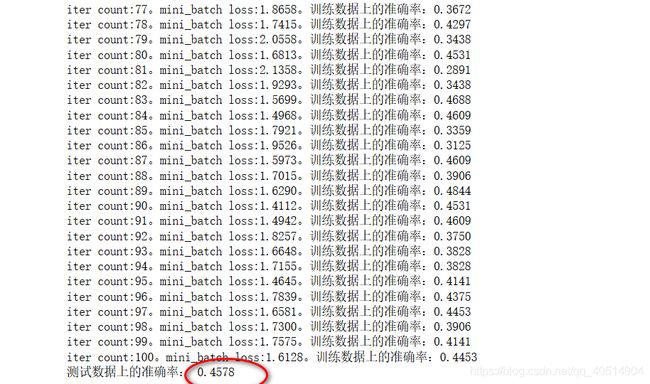
score_test = sess.run(accuracy, feed_dict = {X:X_test, y:y_test, kp:1.0}) # 判断测试数据的acc
print('test accuracy:%0.4f', score_test)
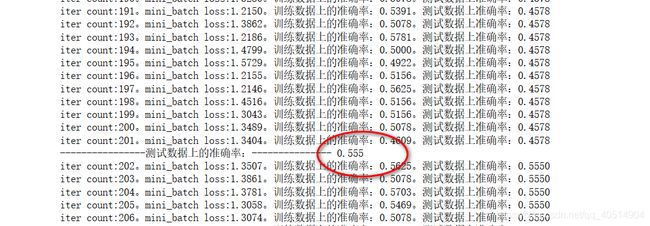
通过结果可以看出,通过100次的训练和测试的数据都接近0.5 但是acc还是很低,所以我们继续使用之前的模型继续来训练
在之前sess的基础上,继续训练
# 这次我们训练1100遍
EPOCHES = 1100
with tf.Session() as sess:
saver.restore(sess, './model/estimator-100')
for i in range(100, EPOCHES):
batch_X, batch_y = next_batch(X_train , y_train)
opt_, loss_, score_train = sess.run([opt, loss, accuracy], feed_dict = {X:batch_X, y:batch_y, kp:0.5})
print('iter count:%d, mini_batch loss:%0.4f, train accuracy:%0.4f'%(i+1, loss_, score_train))
if score_train > 0.6:
saver.save(sess, './model/estimator', i+1)
if (i%100==0) and (i!+100): # 每隔100次判断一次test的acc
score_test = sess.run(accuracy, feed_dict = {X:X_test, y:y_test, kp:1.0})
print('---------test accuracy--------', score_test)
saver.save(sess, './model/estimator', i+1)
可以看到,我们这次的训练直接从上一个模型的基础上进行训练
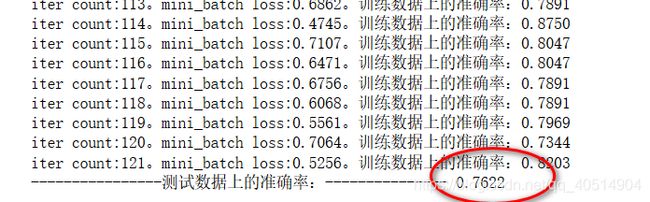
经过1100次的训练,可以看到我们的 三 层 神经网络的acc已经达到了一个客观的值,接近0.8 比较[官方](http://www.cs.toronto.edu/~kriz/cifar.html)的代码来看,我们使用的代码简单,使得刚接触CNN的同学容易去理解,而且最终的acc也是一个不错的值,如果使用更过的时间去训练我们的模型, acc可能会达到 0.9, 如果想要更高的acc,我们就需要去选择其他的模型,如残差网络,之后会继续更新博客,争取选择不同的模型获得一个更好的成绩。

github_进阶案例1
github_进阶案例2
望您:
“情深不寿,强极则辱,谦谦君子,温润如玉”。