【Java SE】数组的深入理解
 篮球哥温馨提示:编程的同时不要忘记锻炼哦!
篮球哥温馨提示:编程的同时不要忘记锻炼哦!
写代码就像圆周率,没有尽头
目录
1、数组的基本概念
1.1 我们为什么需要数组?
1.2 数组的创建与初始化
1.3 数组的使用
1.4 数组的遍历
2、引用类型数组的深入讲解
2.1 简单了解 JVM 的内存分布
2.2 基本类型变量与引用类型变量的区别
2.3 通过方法更深刻理解引用变量
2.4 数组作为函数返回值
3、二维数组
3.1 二维数组的概念和内存布局
3.2 二维数组的定义和初始化
3.3 二维数组遍历
3.4 不规则的二维数组
1、数组的基本概念
1.1 我们为什么需要数组?
假设说我们要存每个同学的期末考试总成绩,如果我们还不知道数组的话,那我们是不是得新建100个变量,而且赋值和打印也相当的麻烦, 而且我们发现成绩的数据类型都是一样的,所以就会有数组这个概念,数组即是相同类型元素的集合,而且是一块连续的存储空间,每个空间都有编号,也就是我们口中常说的数组下标。而且使用数组,也可以是代码变得更简化,方便的进行排序查找等,现在,我们就来进入数组的学习把:
1.2 数组的创建与初始化
我们这期是由浅到深讲解的,所以在前边有一些不理解的问题,请坚持往后看,会得到解决的。
在Java中对数组的创建并初始化有两种方式,分别是静态初始化和动态初始化:
public static void arrayInit() {
int[] array1 = { 1,2,3,4,5,6,7,8,9,10 }; //静态初始化
int[] array2 = new int[] { 1,2,3,4,5,6,7,8,9,10 }; //静态初始化
}这两种写法有什么不同呢?第一种虽然省去了 new int[ ],但是在编译的时候还是会还原成第二种方式,这两种写法本质上没有区别,都是在JVM栈上开辟一个 array1和array2元素,同时也会在堆上开辟两个一维数组,这两个变量分别存这这两个数组的地址,当然,这里你不懂没关系,后面我们也会画图一一讲解到,你只需要知道,这两种定义并初始化的方式只是写法上的不同就可以了!
那定义了数组但是不初始化呢?
public static void arrayInit() {
int[] array3 = new int[10]; //动态初始化
int[] array4 = null;
}如果是上面这种创建但是不初始化,array3 里面会默认初始化成0,也就是说,如果数组中存储的元素为基本类型,默认值为基本类型对对应的默认值0,像 array4 赋值成 null 这种情况,就可以理解成这个数组没有引用任何对象,这个地方听不懂没关系,往后看就能懂了。
| 类型 | 默认值 |
|---|---|
| byte | 0 |
| short | 0 |
| int | 0 |
| long | 0L |
| float | 0.0f |
| double | 0.0 |
| char | /u0000 |
| boolean | false |
不知道学过C语言的小伙伴还记不记得,C语言数组是可以不完全初始化的,比如说你一个数组5个元素,你只初始化前三个元素,在C语言中后续未初始化的元素会默认补0,但是在Java中你就算完全初始化了,如果你指定了元素个数的话,也会报错,只有在使用 new int[10],动态初始化的时候才能写明数组元素个数,你们也可以下来自己试试。
在Java的数组中,我们有几点需要注意:
- 数组 { } 里面的元素类型一定要跟 [ ] 前面的类型保持一致
- 静态初始化的时候不能指定长度,动态初始化的时候 new int[10]需要指定长度
- 虽然没有指定数组长度,但是编译器在编译的时候会根据 { } 里面的元素个数来确定数组的长度
- 虽然Java数组可以写成跟C语言一样的写法 int array[ ],但不推荐,因为这样语义不明确!
- new int[n] ,[ ]中可以是变量
这里有小伙伴就有个小问题了,如果我定义了但是没有初始化,我能不能在下面重新赋值呢?
public static void arrayInit() {
int[] array3;
array3 = { 1,2,3,4,5 };
}这样是绝对不可以的,虽然你现在可能不是很理解,但我们前面有提过,数组变量 array3 里面放的是地址,这个在下面我们会细讲。这里你知道即可。
那如何正确的在定义之后初始化呢?或者重新赋值呢?
public static void arrayInit() {
int[] array1;
array1 = new int[10];
int[] array2;
array2 = new int[]{ 1,2,3,4,5 };
}像如上代码这样是ok的,本质上其实就是在堆区创建了一个新对象,这个我们还是在后面细讲,这里让你们先见一见,为后面细节学习作铺垫。
1.3 数组的使用
数组是定义好了,我们如何去使用他呢?在前面我们提到过,数组是一块连续的内存空间,都有对应的编号,也就是下标,我们就可以通过下标的方式快速访问数组的任意位置的元素:
public static void main(String[] args) {
int[] array = { 1,2,3,4,5 };
array[2] = 88;
System.out.println(array[2]);
}同时也可以对下标的值进行修改,但是这里我们要注意几点,数组的下标是从 0 开始的,所以最后一个元素下标应该是 n-1,也就是Java中大部分采用的都是左闭右开的,即:[ 0,n )
如果我们下标越界访问了,不用担心,程序会直接剖出下标越界异常,我们根据报错提示去找对应的位置即可。

1.4 数组的遍历
在Java中对数组其实有三种遍历打印的方式,每一种的情况都会讲明优缺点,接着往下看:
for 循环打印:
public class TestDemo {
public static void main(String[] args) {
int[] array = { 1,2,3,4,5 };
for (int i = 0; i < array.length; i++) {
System.out.print(array[i] + " ");
}
System.out.println();
}
}
这种方式是很常规的通过下标遍历访问的方式,对于数组的长度我们可以通过,数组对象.length 来获取数组的长度。
for-each 循环打印:
public class TestDemo {
public static void main(String[] args) {
int[] array = { 1,2,3,4,5 };
for (int a : array) {
System.out.print(a + " ");
}
System.out.println();
}
}这种打印方式呢,在 for 循环里冒号的左边必须是你要打印的数组里元素的类型定义的变量,右边则是你要打印数组的数组名,下面就可以通过你定义的变量进行打印了。for-each是for循环的另一种使用方式,他能在代码上更简洁,也可以避免循环条件和更新语句的书写错误,但是这样也有缺陷,比如说这种方式并不能拿到数组的下标。
Arrays工具类打印
public class TestDemo {
public static void main(String[] args) {
int[] array = { 1,2,3,4,5 };
String ret = Arrays.toString(array); //既然返回的是字符串,我们就用字符串类型来接收
System.out.println(ret);
System.out.println(Arrays.toString(array)); //既然有返回值,那我们也可以直接链式访问
}
}首先我们要介绍下Arrays,他是在 java.util 包下的一个工具类,里面定义了很多对数组的操作方法,而 Arrays.toString 他的作用是把数组转换成字符串并返回,所以严格意义上它并不是遍历数组,只是把数组转化成对应的字符串而已。
以上三种方式各有优缺点,初学者结合实际情况作应用
2、引用类型数组的深入讲解
2.1 简单了解 JVM 的内存分布
Java的程序需要运行在虚拟机上的,如果对于内存中的数据随意存储的话,那以后对内存管理起来将会是很麻烦的一件事,所以JVM也对所使用的内存按照不同的功能进行了划分:

但是我们今天只重点关心堆和虚拟机栈这两块空间,在后续学习中会依次详细介绍这里面的内容:
虚拟机栈:与方法调用相关的一些信息,每个方法在执行的时候都会先创建一个栈帧,栈帧中包含:局部变量,操作数栈,动态链接,返回地址,以及一些其他的信息,保存的都是与方法执行相关的一些信息,比如:局部变量,当方法运行结束了后,栈帧也被销毁,即栈帧中保存的数据也被销毁了
堆:它是JVM管理的最大内存区域,使用 new 创建的对象都是在堆上保存的,堆是随着程序的开始而创建,随着程序的退出而销毁,堆中的数据只要还有在使用,就不会被销毁。
2.2 基本类型变量与引用类型变量的区别
对这个理解特别重要,很关系到你后面进行学习,首先我们要区别这个两个的区别,先说基本类型变量,这种变量中直接存放的是所对应的值,而引用类型创建的变量,一般称为对象的引用,这种变量里存储的是对象所在空间的地址,下面我们用一小段代码,并且画图让大家理解的更清楚:
public class TestDemo {
public static void main(String[] args) {
int a = 10;
int b = 20;
int[] array = { 1,2,3,4,5 };
}
}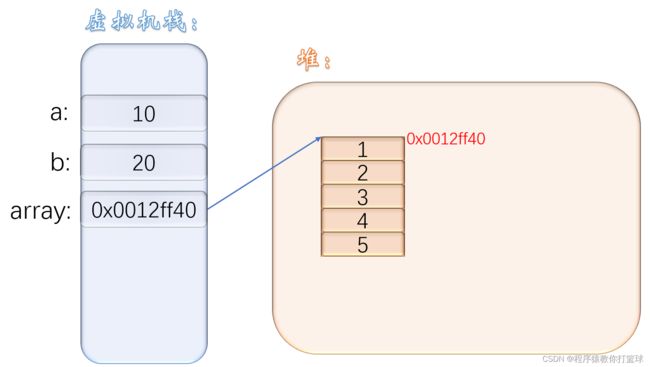
其实看到这张图,相信大家就能很好的理解了,其实我们引用变量并不是存储了对象本身,只是存储了对象的其实地址,那我们的 array 只是存储了在堆中开辟的一维数组的地址!并没有把整个数组都保存在变量中!通过该对象的地址,引用变量就可以去操作这个对象了!
2.3 通过方法更深刻理解引用变量
有了上面的认识,我们就要来理解下面这两个方法的作用了,相信你看完会有更深刻的认识:

是不是结果可能跟你想得有点不一样呢?不用担心,我们来一个个分析下:
首先我们执行的是 func1 我们知道 array 变量中存的是一个对象的地址,那么通过传参给 func1 的 arr1,首先要建立栈帧,把 array 存的地址拷贝到 arr1 当中,这样一来就相当于 arr1 也指向了那个变量,但是我们又 new 了一个对象,并把新对象的地址赋值给了 arr1,相当于 arr1 原来存放的地址已经被替换了,也就说 arr1 指向了一个新的对象,因为只是把 array 存的地址拷贝给了 arr1 所以执行完 func1 这个方法之后,array 并不会受任何影响,当方法结束,arr2 变量销毁,因为arr2 销毁之后没有变量接着引用在 func1 中 new 的新对象,所以此时新的对象就被 JVM 回收了!
当我们执行完 func1 时,就是我们说的结果,所以 array 的值不受任何影响!
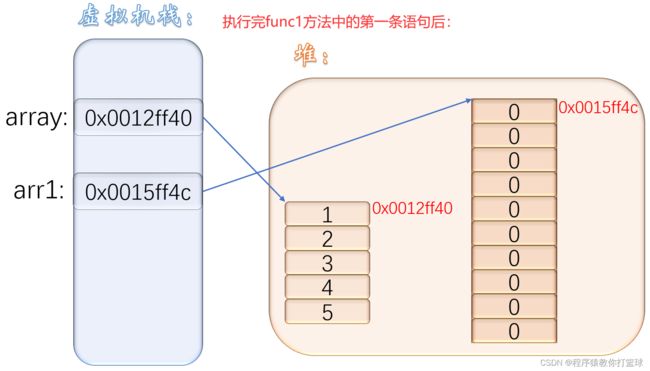
我们接着再来看执行 func2 之后的结果,首先前半部分与 func1 一样,都是传递的 array 指向对象的地址,但是 func2 里面语句是直接对 arr2 中对象的地址进行下标访问,修改了 [1] 下标处的值,因为本质 array 和 arr2 引用的都是同一个对象,当 arr2 修改了对象的值,所以当函数结束后接着打印 array 指向对象的值肯定也被修改了!方法结束,arr2 被销毁,但是 arr2 指向的对象仍然被 array 指向着,所以JVM不会回收此时的对象!

看到这,你肯定有了更深刻的理解,前面有疑问的地方肯定得到了解决,所谓的 "引用" 本质上只是存了一个地址,Java将数组设定成引用类型,这样后续进行数组传参,其实只是将数组的地址传入到形参当中,这样就可以避免对整个数组的拷贝!
在我们目前认识中,如果对象没有被引用,则会自动回收,所以不用考虑内存泄漏的问题
2.4 数组作为函数返回值
假设这里我们有一个题,需要实现一个方法,这个方法需要获取斐波那契数列的前 n 项,需要返回一个数组回来,本质其实就是返回数组的地址,如何实现呢?
public static int[] fib(int n) {
if (n <= 0) {
return null;
}
int[] array = new int[n];
array[0] = array[1] = 1;
for (int i = 2; i < n; i++) {
array[i] = array[i - 1] + array[i - 2];
}
return array;
}
public static void main(String[] args) {
int[] array = fib(8);
System.out.println(Arrays.toString(array));
}当然这个方法如果 n 为1 就会越界,这个下来可以自己优化下,来到这里我们就来介绍下Arrays这个工具类里面的一些方法了: 像一些将数组转换成字符串,数组二分查找,数组排序等等,可以下来查阅下帮助手册,这里我就不细说了,交给大家自己去扩展了,如果以后用到,我会进行说明。
3、二维数组
3.1 二维数组的概念和内存布局
这里我们一定要有一个概念,二维数组是一个特殊的一维数组,如何理解呢?用文字来说,二维数组的每个元素是一维数组,也就是说,二维数组的每个元素里面放的是一维数组的地址!
相信听完上面的话,大家可能不是很理解,那我们就定义一个二维数组,并画图:
public static void main(String[] args) {
int[][] array = { {1,2,3}, {4,5,6} };
} 这里就很清晰明了了,图中也能看到,二维数组本质就是一个一维数组,只不过这个一维数组的每个元素存的是地址而已!
这里就很清晰明了了,图中也能看到,二维数组本质就是一个一维数组,只不过这个一维数组的每个元素存的是地址而已!
3.2 二维数组的定义和初始化
当然,二维数组和一维数组一样,同样的三种定义方式:
int[][] array1 = { {1,2,3}, {4,5,6} }; //两行三列的二维数组
int[][] array2 = new int[][]{ {1,2,3}, {4,5,6} };
int[][] array3 = new int[2][3];如果只是单纯的 int[][] array; 这样数组里面没有任何引用对象,并不能直接使用未引用对象的数组,如果不引用最好置null
3.3 二维数组遍历
for 循环打印:
public class TestDemo {
public static void main(String[] args) {
int[][] array1 = { {1,2,3}, {4,5,6} }; //两行三列的二维数组
for (int i = 0; i < array1.length; i++) {
for (int j = 0; j < array1[i].length; j++) {
System.out.print(array1[i][j] + " ");
}
System.out.println();
}
System.out.println();
}
}这里第一个 for 里面的长度求的是 array1.length,因为它本身就是一个特殊一维数组,这样求出的就是它的行,第二个for array1[i].length,自然求得就是每一行一维数组长度了
for-each 循环打印:
public class TestDemo {
public static void main(String[] args) {
int[][] array1 = { {1,2,3}, {4,5,6} }; //两行三列的二维数组
for (int[] arr : array1) { //二维数组的每个元素是一维数组,所以每个元素的类型是int[]
for (int a : arr) { //arr是一维数组,每个数组的元素的int
System.out.print(a + " ");
}
System.out.println();
}
}
}Arrays 工具类有个方法也可以打印二维数组,是Arrays.deepToString,这个方法也是打印二维数组的但只能在一行显示,感兴趣的可以下来自己实验下。
3.4 不规则的二维数组
在Java中,二维数组的列可以省略,也就是把二维数组看成一个特殊的一维数组的每个元素指向的一维数组是可以元素个数不同的,如何理解这句话呢?我们还是一样通过一小段并且以画图的形式给大家讲解:
int[][] array = new int[2][];
array[0] = new int[3];
array[1] = new int[2]; 当然,他的遍历方法是跟普通二维数组一样的, 这里我就不多说,自己摸索,实在不懂可以问下博主。
当然,他的遍历方法是跟普通二维数组一样的, 这里我就不多说,自己摸索,实在不懂可以问下博主。

下期预告:【Java SE】类和对象