作者 Jeroen Borgers译者 韩锴 发布于 2008年10月29日 上午2时54分
在本文的第一部分中, 我们通过一个单一线程的基准,比较了同步的StringBuffer和非同步的StringBuilder之间的性能。从最初的基准测试结果来看,偏向锁 提供了最佳的性能,比其他的优化方式更有效。测试的结果似乎表明获取锁是一项昂贵的操作。但是在得出最终的结论之前,我决定先对结果进行检验:我请我的同 事们在他们的机器上运行了这个测试。尽管大多数结果都证实了我的测试结果,但是有一些结果却完全不同。在本文的第二部分中,我们将更深入地看一看用于检验 测试结果的技术。最后我们将回答现实中的问题:为什么在不同的处理器上的锁开销差异如此巨大?
相关厂商内容
InfoQ中文站电子杂志《架构师》试刊号发布
Java 6中的线程优化真的有效么?(第二部分)
中国软件安全峰会((11月5日·6日)后报名
沙龙:OpenSolaris前世今生/Groovy&Grails应用二三事(11.8西安)
IDC:《软件商成长路线图》白皮书免费下载
相关赞助商
InfoQ中文站Java社区,关注企业Java社区的变化与创新,通过新闻、文章、视频访谈和演讲以及迷你书等为中国Java技术社区提供一流资讯。
基准测试中的陷阱
通过一个基准测试,尤其是一个“小规模基准测试”(microbenchmark),来回答这个问题是非常困难的。多半情况下,基准测试会出现一些 与你期望测量的完全不同的情景。即使当你要测量影响这个问题的因素时,结果也会被其他的因素所影响。有一点在这个实验开始之初就已经很明确了,即这个基准 测试需要由其他人全面地进行审查,这样我才能避免落入报告无效基准测试数据的陷阱中。除了其他人的检查以外,我还使用了一些工具和技术来校验结果,这些我 会在下面的几节中谈到。
结果的统计处理
大多数计算机所执行的操作都会在某一固定的时间内完成。就我的经验而言,我发现即使是那些不确定性的操作,在大多数条件下基本上也能在固定的时间内 完成。正是根据计算的这种特性,我们可以使用一种工具,它通过测量让我们了解事情何时开始变得不正常了。这样的工具是基于统计的,其测量结果会有些出入。 这就是说,即使看到了一些超过正常水平的报告值,我也不会做过多过的解释的。原因是这样的,如果我提供了指令数固定的CPU,而它并没有在相对固定的时间 内完成的话,就说明我的测量受到了一些外部因素的影响。如果测试结果出现了很大的异常,则意味着我必须找到这个外部的影响进而解决它。
尽管这些异常效果会在小规模基准测试中被放大,但它不至于会影响大规模的基准测试。对于大规模的基准测试来说,被测量的目标应用程序的各个方面会彼 此产生干扰,这会带来一些异常。但是异常仍然能够提供一些很有益的信息,可以帮助我们对干扰级别作出判断。在稳定的负荷下,我并不会对个别异常情况感到意 外;当然,异常情况不能过多。对于那些比通常结果大一些或小一些的结果,我会观察测试的运行情况,并将它视为一种信号:我的基准测试尚未恰当地隔离或者设 置好。这样对相同的测试进行不同的处理,恰恰说明了全面的基准测试与小规模基准测试之间的不同。
最后一点,到此为止仍然不能说明你所测试的就是你所想的。这至多只能说明,对于最终的问题,这个测试是最有可能是正确的。
预热方法的缓存
JIT会编译你的代码,这也是众多影响基准测试的行为之一。Hotspot会频繁地检查你的程序,寻找可以应用某些优化的机会。当找到机会后,它会 要求 JIT编译器重新编译问题中的某段代码。此时它会应用一项技术,即当前栈替换(On Stack Replacement,OSR),从而切换到新代码的执行上。执行OSR时会对测试产生各种连锁影响,包括要暂停线程的执行。当然,所有这样的活动都会 干扰到我们的基准测试。这类干扰会使测试出现偏差。我们手头上有两款工具,可以帮助我们标明代码何时受到JIT的影响了。第一个当然是测试中出现的差异, 第二个是-XX:-PrintCompilation标记。幸运的是,如果不是所有的代码在测试的早期就进行JIT化处理,那么我们可以将它视为另外一种 启动时的异常现象。我们需要做的就是在开始测量前,先不断地运行基准测试,直到所有代码都已经完成了JIT化。这个预热的阶段通常被称为“预热方法的缓存 ”。
大多数JVM会同时运行在解释的与本机的模式中。这就是所谓的混合模式执行。随着时间的流逝,Hotspot和JIT会根据收集 的信息将解释型代码转化为本机代码。Hotspot为了决定应该使用哪种优化方案,它会抽样一些调用和分支。一旦某个方法达到了特定的阈值后,它会通知 JIT生成本机代码。这个阈值可以通过-XX:CompileThreshold标记来设定。例如,设定 -XX:CompileThreshold=10000,Hotspot会在代码被执行10,000次后将它编译为本机代码。
堆管理
下一个需要考虑的是垃圾收集,或者更广为人知的名字—堆管理。在任何应用程序执行的过程中,都会定期地发生很多种内存管理活动。它们包括:重新划分 栈空间大小、回收不再被使用的内存、将数据从一处移到另一处等等。所有这些行为都导致JVM影响你的应用程序。我们面对的问题是:基准测试中是否需要将内 存维护或者垃圾回收的时间包括进来?问题的答案取决于你要解决的问题的种类。在本例中,我只对获取锁的开销感兴趣,也就是说,我必须确保测试中不能包含垃 圾回收的时间。这一次,我们又能够通过异常的现象来发现影响测试的因素,一旦出现这种问题,垃圾回收都是一个可能的怀疑对象。明确问题的最佳方式是使用 -verbose:gc标志,开启GC的日志功能。
在这个基准测试中,我做了大量的String、StringBuffer和StringBuilder操作。在每次运行的过程中大概会创建4千万个 对象。对于这样一种数量级的对象群来说,垃圾回收毫无疑问会成为一个问题。我使用两项技术来避免。第一,提高堆空间的大小,防止在一个迭代中出现垃圾回 收。为此,我利用了如下的命令行:
>java -server -XX:+EliminateLocks -XX:+UseBiasedLocking -verbose:gc -XX:NewSize=1500m -XX:SurvivorRatio=200000 LockTest然后,加入清单1的代码,它为下一次迭代准备好堆空间。
System.gc();
Thread.sleep(1000);清单1. 运行GC,然后进行短暂的休眠。
休眠的目的在于给垃圾回收器充分的时间,在释放其他线程之后完成工作。有一点需要注意:如果没有CPU任何活动,某些处理器会降低时钟频率。因此, 尽管CPU时钟会自旋等待,但引入睡眠的同时也会引入延迟。如果你的处理器支持这种特性,你可能必须要深入到硬件并且关闭掉“节能”功能才行。
前面使用的标签并不能阻止GC的运行。它只表示在每一次测试用例中只运行一次GC。这一次的暂停非常小,它产生的开销对最终结果的影响微乎其微。对于我们这个测试来说,这已经足够好了。
偏向锁延迟
还有另外一种因素会对测试结果产生重要的影响。尽管大多数优化都会在测试的早期发生,但是由于某些未知的原因,偏向锁只发生在测试开始后的三到四秒 之后。我们又要重述一遍,异常行为再一次成为判断是否存在问题的重要标准了。-XX:+TraceBiasedLocking标志可以帮助我们追踪这个问 题。还可以延长预热时间来克服偏向锁导致的延迟。
Hotspot提供的其他优化
Hotspot不会在完成一次优化后就停止对代码的改动。相反,它会不断地寻找更多的机会,提供进一步的优化。对于锁来说,由于很多优化行为违反了 Java存储模型中描述的规范,所以它们是被禁止的。然而,如果锁已经被JIT化了,那么这些限制很快就会消失。在这个单线程化的基准测试 中,Hotspot可以非常安全地将锁省略掉。这样就会为其他的优化行为打开大门;比如方法内联、提取循环不变式以及死代码的清除。
如果仔细思考下面的代码,可以发现A和B都是不变的,我们应该把它抽取出来放到循环外面,并引入第三个变量,这样可以避免重复的 计算,正如清单3中所示的那样。通常,这都是程序员的事情。但是Hotspot 可以识别出循环不变式并把它们抽取到循环体外面。因此,我们可以把代码写得像清单2那样,但是它执行时其实更类似于清单3的样子。int A = 1;
int B = 2;
int sum = 0;
for (int i = 0; i < someThing; i++) sum += A + B;清单2 循环中包含不变式
int A = 1;
int B = 2;
int sum = 0;
int invariant = A + B;
for (int i = 0; i < someThing; i++) sum += invariant;清单3 不变式已抽取到循环之外
这些优化真的应该允许么?还是我们应该做一些事情防止它的发生?这个有待商榷。但至少,我们应该知道是否应用了这些优化。我们绝对要避免“死代码消 除”这种优化的出现,否则它会彻底扰乱我们的测试!Hotspot能够识别出我们没有使用concatBuffer和concatBuilder操作的结 果。或者可以说,这些操作没有边界效应。因此没有任何理由执行这些代码。一旦代码被标识为已“死亡”,JIT就会除去它。好在我的基准测试迷惑了 Hotspot,因此它并没有识别出这种优化,至少目前还没有。
如果由于锁的存在而抑制了内联,反之没有锁就可能出现内联,那么我们要确保在测试结果中没有包含额外的方法调用。现在可以用到的一种技术是引入一个接口(清单4)来迷惑Hotspot。
String concatBuffer(String s1, String s2, String s3);
String concatBuilder(String s1, String s2, String s3);
Concat {
...}清单4 使用接口防止方法内联
防止内联的另一种方法是使用命令行选项-XX:-Inline。我已经验证,方法内联并没有给基准测试的报告带来任何不同。
执行栈输出
最后,请看下面的输出结果,它使用了下面的命令行标识。
>java -server -XX:+DoEscapeAnalysis -XX:+PrintCompilation -XX:+EliminateLocks -XX:+UseBiasedLocking -XX:+TraceBiasedLocking LockTest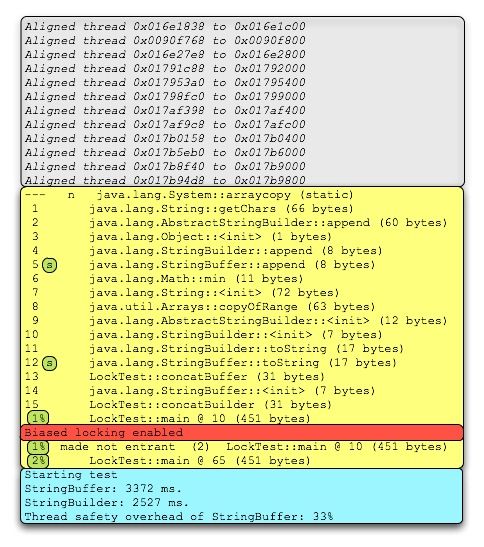
图1 基准测试的执行栈输出
JVM默认会启动12个线程,包括:主线程、对象引用处理器、Finalize、Attach监听器等等。上图中第一个灰色段显示的是这些线程的对 齐,它们可以使用偏向锁(注意所有地址都以00结尾)。你尽管忽略可以忽略它们。接下来的黄色段包含了已编译方法的信息。我们看一下第5行和12行,能够 发现它们都标记了一个额外的“s”。表1的信息告诉我们这些方法都是同步的。包含了“%”的各行已经使用了OSR。红色的行是偏向锁被激活的地方。最底下 的蓝绿色框是基准测试开始计时的地方。从记录基准测试开始时间的输出中可以看到,所有编译都已经发生了。这说明前期的预热阶段足够长了。如果你想了解日志 输出规范的更多细节,可以参考这个页面和这篇文章。

表1 编译示例码
单核系统下的结果
尽管我的多数同事都在使用Intel Core 2 Duo处理器,但还是有一小部分人使用陈旧的单核机器。在这些陈旧的机器上,StringBuffer基准测试的结果和StringBuilder实现的 结果几乎相同。由于产生这种不同可能是多种因素使然,因此我需要另外一个测试,尝试忽略尽可能多的可能性。最好的选择是,在BIOS中关闭Core 2 Duo中的一个核,然后重新运行基准测试。运行的结果如图2所示。
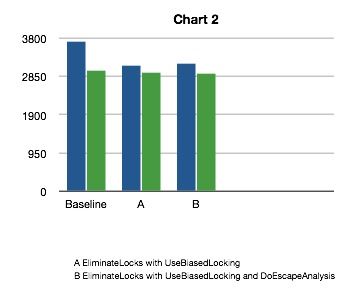
图2 单核系统的性能
在多核环境下运行的时候,关闭了三种优化行为后获得了一个基准值。这次,StringBuilder又保持了平稳的吞吐量。更有趣的是,尽管 StringBuffer比StringBuilder要稍慢,但是在多核平台下,StringBuffer的性能更接近于StringBuilder。 从这个测试开始我们将一步步勾勒出基准测试的真实面目。
在多核的世界中,线程间共享数据的现实呈现出一种全新的面貌。所有现代的CPU必须使用本地存储的缓存,将获取指令和数据的延迟降到最低。当我们使 用锁的时候,会导致一次存储关卡(Barrier)被插入到执行路径中。存储关卡像一个信号,它通知CPU此时必须和其他所有的CPU进行协调,以此获得 最新的数值。为了完成这个任务,CPU之间将要彼此通讯,从而导致每个处理器暂定当前正在运行的应用程序线程。这个过程要花多少时间已经成了CPU存储模 型的指标之一。越是保守的存储模型,越是线程安全的,但是它们在协调各个处理器核的时候也要花费更多的时间。在Core 2 Duo上,第二个核将固定的运行基准从3731ms提高到了6574ms,或者说增加了176%。很明显,Hotspot所提供的任何帮助都能明显改进我 们的应用程序的总体性能。
逸出分析真的起作用了么?
现在,还有一种优化很明显会起作用,但是我们还没有考虑,它就是锁省略。锁省略是最近才实现的技术,而且它依赖于逸出分析,后者是一种 Profiling 技术,其自身也是刚刚才实现的。为了稳妥一些,各公司和组织都宣称这些技术只有在有限的几种情况下才起作用。比如,在一个简单的循环里,对一个局部变量执 行递增,且该操作被包含在一个同步块内,由一个局部的锁保护着。这种情况下逸出分析是起作用的[http://blog.nirav.name/2007_02_01_archive.html]。同时它在Mont Carlo的Scimark2基准测试中可以工作(参见[http://math.nist.gov/scimark2/index.html])。
将逸出分析包含在测试中
那么,为什么逸出分析可以用于上述的情况中,却不能用于我们的基准测试中?我曾经尝试过将StringBuffer和 StringBuilder的部分方法进行内联。我也修改过代码,希望可以强制逸出分析运行。我想看到锁最终被忽略,而性能可以获得大幅提升。老实说,处 理这个基准测试的过程既困惑,又让人倍感挫折。我必须无数次地在编辑器中使用ctrl-z,以便恢复到前面一个我认为逸出分析应该起作用的版本,但是却不 知由于什么原因,逸出分析却突然不起作用了。有时,锁省略却又会莫名其妙地出现。
最后,我认识到激活锁省略似乎和被锁对象的数据大小有关系。你运行清单2的代码就会看到这一点。正如你所看到的,无论运行多少次,结果都毫无区别,这说明DoEscapeAnalysi没有产生影响。
>java -server -XX:-DoEscapeAnalysis EATest
thread unsafe: 941 ms.
thread safe: 1960 ms.
Thread safety overhead: 208%
>java -server -XX:+DoEscapeAnalysis EATest
thread unsafe: 941 ms.
thread safe: 1966 ms.
Thread safety overhead: 208%在下面的两次运行中,我移除了ThreadSafeObject类中一个没有被用过的域。如你所见,当开启了逸出分析,所有性能有了很大的提高。
>java -server -XX:-DoEscapeAnalysis EATest
thread unsafe: 934 ms.
thread safe: 1962 ms.
Thread safety overhead: 210%
>java -server -XX:+DoEscapeAnalysis EATest
thread unsafe: 933 ms.
thread safe: 1119 ms.
Thread safety overhead: 119%逸出分析的数目在Windows和Linux上都能看到。然而在Mac OS X上,即使有额外未被使用的变量也不会有任何影响,任何版本的基准测试的结果都是120%。这让我不由地相信在Mac OS X上有效性的范围比其他系统更广泛。我猜测这是由于它的实现比较保守,根据不同条件(比如锁对象数据大小和其他OS特定的特性)及早地关掉了它。
结论
当我刚开始这个实验,解释应用各种锁优化的Hotspot的有效性的时候,我估计它将花费我几个小时的时间,最终这会丰富我的blog的内容。但是 就像其他的基准测试一样,对结果进行验证和解释的过程最终耗费了几周的时间。同样,我也与很多专家进行合作,他们分别花费了大量时间检查结果,并发表他们 的见解。即使在这些工作完成以后,仍然很难说哪些优化起作用了,而哪些没有起作用。尽管这篇文章引述了一组测试结果,但它们是特定我的硬件和系统的。大家 可以考虑是否能在自己的系统上看到相同类型的测试结果。另外,我最初认为这不过是个小规模基准测试,但是后来它逐渐既要满足我,也要满足所有审核代码的 人,而且去掉了Hotspot不必要的优化。总之,这个实验的复杂度远远地超出了我的预期。
如果你需要在多核机器上运行多线程的应用程序,并且关心性能,那么很明显,你需要不断地更新所使用的JDK到最新版本。很多(但不是全部)前面的版 本的优化都可以在最新的版本中获得兼容。你必须保证所有的线程优化都是激活的。在JDK 6.0中,它们默认是激活的。但是在JDK 5.0中,你需要在命令行中显式地设置它们。如果你在多核机器上运行单线程的应用程序,就要禁用除第一个核以外所有核的优化,这样会使应用程序运行得更 快。
在更低级的层面上,单核系统上锁的开销远远低于双核处理器。不同核之间的协调,比如存储关卡语义,通过关掉一个核运行的测试结果看,很明显会带来系 统开销。我们的确需要线程优化,以此降低这一开销。幸运的是,锁粗化和(尤其是)偏向锁对于基准测试的性能确实有明显的影响。我也希望逸出分析与锁省略一 起更能够做到更好,产生更多的影响。这项技术会起作用,可只是在很少的情况下。客观地说,逸出分析仍然还处于它的初级阶段,还需要大量的时间才能变得成 熟。
最后的结论是,最权威的基准测试是让你的应用程序运行在自己的系统上。当你的多线程应用的性能没有符合你的期望的时候,这篇文章能够为你提供了一些思考问题的启示。而这就是此文最大的价值所在。
关于Jeroen Borgers
Jeroen Borger是Xebia 的资深咨询师。Xebia是 一家国际IT咨询与项目组织公司,专注于企业级Java和敏捷开发。Jeroen帮助他的客户攻克企业级Java系统的性能问题,他同时还是Java性能 调试课程的讲师。他在从1996年开始就可以在不同的Java项目中工作,担任过开发者、架构师、团队lead、质量负责人、顾问、审核员、性能测试和调 试员。他从2005年开始专注于性能问题。
鸣谢
没有其他人的鼎力相助,是不会有这篇文章的。特别感谢下面的朋友:
Dr. Cliff Click,原Sun公司的Server VM主要架构师,现工作在Azul System;他帮我分析,并提供了很多宝贵的资源。
Kirk Pepperdine,性能问题的权威,帮助我编辑文章。
David Dagastine,Sun JVM性能组的lead,他为我解释了很多问题,并把我引领到正确的方向。
我的很多Xebia的同事帮我进行了基准测试。
资源
Java concurrency in practice, Brian Goetz et all.
Java theory and practice: Synchronization optimizations in Mustang,
Did escape analysis escape from Java 6
Dave Dice's Weblog
Java SE 6 Performance White Paper
清单1.
public class LockTest {
private static final int MAX = 20000000; // 20 million
public static void main(String[] args) throws InterruptedException {
// warm up the method cache
for (int i = 0; i < MAX; i++) {
concatBuffer("Josh", "James", "Duke");
concatBuilder("Josh", "James", "Duke");
}
System.gc();
Thread.sleep(1000);
long start = System.currentTimeMillis();
for (int i = 0; i < MAX; i++) {
concatBuffer("Josh", "James", "Duke");
}
long bufferCost = System.currentTimeMillis() - start;
System.out.println("StringBuffer: " + bufferCost + " ms.");
System.gc();
Thread.sleep(1000);
start = System.currentTimeMillis();
for (int i = 0; i < MAX; i++) {
concatBuilder("Josh", "James", "Duke");
}
System.out.println("StringBuilder: " + builderCost + " ms.");
System.out.println("Thread safety overhead of StringBuffer: "
}
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}
StringBuilder sb = new StringBuilder();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}
清单2.
public class EATest {
private static final int MAX = 200000000; // 200 million
public static final void main(String[] args) throws InterruptedException {
// warm up the method cache
sumThreadUnsafe();
sumThreadSafe();
sumThreadUnsafe();
sumThreadSafe();
System.out.println("Starting test");
long start;
start = System.currentTimeMillis();
sumThreadUnsafe();
long unsafeCost = System.currentTimeMillis() - start;
System.out.println(" thread unsafe: " + unsafeCost + " ms.");
start = System.currentTimeMillis();
sumThreadSafe();
long safeCost = System.currentTimeMillis() - start;
System.out.println(" thread safe: " + safeCost + " ms.");
System.out.println("Thread safety overhead: "
+ ((safeCost * 10000 / (unsafeCost * 100)) - 100) + "%/n");
}
public static int sumThreadSafe() {
String[] names = new String[] { "Josh", "James", "Duke", "B" };
ThreadSafeObject ts = new ThreadSafeObject();
int sum = 0;
for (int i = 0; i < MAX; i++) {
sum += ts.test(names[i % 4]);
}
return sum;
}
public static int sumThreadUnsafe() {
String[] names = new String[] { "Josh", "James", "Duke", "B" };
ThreadUnsafeObject tus = new ThreadUnsafeObject();
int sum = 0;
for (int i = 0; i < MAX; i++) {
sum += tus.test(names[i % 4]);
}
return sum;
}
}
final class ThreadUnsafeObject {
// private int index = 0;
private int count = 0;
private char[] value = new char[1];
public int test(String str) {
value[0] = str.charAt(0);
count = str.length();
return count;
}
}
final class ThreadSafeObject {
private int index = 0; // remove this line, or just the '= 0' and it will go faster!!!
private int count = 0;
private char[] value = new char[1];
public synchronized int test(String str) {
value[0] = str.charAt(0);
count = str.length();
return count;
}
}
查看英文原文:Do Java 6 threading optimizations actually work? - Part II。
转自:http://www.infoq.com/cn/articles/java-threading-optimizations-p2
原文链接: http://blog.csdn.net/vanessa219/article/details/3221537