大模型系统和应用——自然语言处理&大模型基础
引言
最近在公众号中了解到了刘知远团队退出的视频课程《大模型交叉研讨课》,看了目录觉得不错,因此拜读一下。
观看地址: https://www.bilibili.com/video/BV1UG411p7zv
目录:
- 自然语言处理&大模型基础
- 神经网络基础
- Transformer&PLM
- Prompt Tuning & Delta Tuning
- 高效训练&模型压缩
- 基于大模型的文本理解与生成
- 大模型与生物医学
- 大模型与法律智能
- 大模型与脑科学
基础与应用
自然语言处理的目的是让计算机理解人类所说的语言。在人工智能的最开始阶段,图灵提出了图灵测试,是判断机器智能的一个重要手段。
简单来说,就是让人类与机器对话,让人类判断对面是否为机器人。而机器只有非常好地理解人类语言并能生成合理地回应之后,才能让人类无法判断出对面是机器人还是人类。
Advances in Natural Language Processing是一个非常好的自然语言处理综述介绍,是2015年发布的。
下面我们来看一下自然语言处理的基本任务和应用。
基本任务和应用
包括词性标注(Part of speech)、命名识别识别(Named entity recognition)、共指消解(Co-reference)和依存关系(Basic dependencies):
还有一些和语言相关的任务,比如中文里面的中文分词。
如果完成了上面的这些任务后,那么可以应用到非常多不同的任务中。
自然语言处理与结构化知识有密切的关系,如何从文本中抽取结构化知识来更好地支持我们获取相关信息,常用的技术是知识图谱。
知识图谱需要自动地从大规模的文本中挖掘,这里就涉及到另一个非常重要的技术,机器阅读理解。
自然语言处理还可以实现智能助理,比较有名的是钢铁侠电影中的贾维斯,尽管我们现在还无法实现这么智能。商业化的产品像小度、Siri有着非常广泛的应用。
此外还有一个经典的任务,机器翻译,现在比较厉害的应用Google翻译,几乎离不开它。
有时我们想知道一句话的情感,也可以应用自然语言处理的技术,情感分析。
还可以利用自然语言来分析人类的心理状态。
我们看到了很多的应用,下面我们简单了解一下自然语言处理的基本问题,即词的表示问题。
词表示
词表示(Word representation):把自然语言中最基本的语言单位——词,转换成机器能理解的表示的过程。即让机器理解单词的意思。
那如何做到这件事呢?我们要想清楚有了词表示后,那么计算机可以做什么。
- 计算单词相似度
- 知道单词语义关系
- 比如北京和中国是首都和国家的关系
同义词和上位词
在过去如何去表示一个词的词义呢,有一个非常简单的做法,用一组相关词(比如同义词)来表示当前词。

比如用"Good"有关的近义词和反义词来表示它的词义;或者说用"NLP"相关的上位词来表示它的词义。
这是非常直观的一种表示方案,但是这样做有一些问题:
- 丢失细微差别
- 比如"proficient"与"good"只在某些情况下是同义词
- 丢失单词的新意
- 比如"Apple"除了有苹果的意思,还是一家公司
- 主观性问题
- 数据稀疏问题
- 需要大量人工构建维护词典
One-hot表示
实际上对于计算机来说,最常用的还是将词表示成独立的符号,比如独热表示。

即任何一个词都可以用词表一样大小维度的向量来表示,只有一个维度为1,其他都是0。
这种表示方式,比较适用于计算文档之间的相似度,因为两篇文档理论上相同的单词越多,证明越相似。
但是在表示词的时候就会存在问题,因为它假设词之前的向量都是正交的。
上下文表示
为了解决one-hot的问题,上下文分布表示被提出来,这里有一句名言"ou shall know a word by the company it keeps."。即我们可以利用词的上下文词来知道这个词的意思,或来表示这个词。

比如上面的例子,为了表示词"stars",我们可以选取经常出现的上下文词"shining"、"cold"和"bright"等来表示这个词。

利用这种方式我们就可以用一个向量,它的长度也和词典长度一样,但里面的每一维度表示该词的上下文它出现了多少次。这样任何一个词,都可以用它上下文出现的频度来进行表示,从而得到每个词的稠密向量。
然后可以利用该稠密向量计算两个词的相似度。
这样的方法很好,但还是有问题,它有什么问题呢?
- 存储需求随着词表大小增长
- 需要大量存储空间
- 对于频率特别少的词,存在稀疏问题
- 导致该词的表示效果不好
词嵌入
针对上面的问题,深度学习或大模型所做的工作就是词嵌入(Word Embedding)。
词嵌入是一种分布式表示
- 从大规模文本中建立一个低维稠密向量空间
- 学习方法:比如Word2Vec
语言模型
自然语言处理的另外一个知识点是语言模型(Language Model)。
语言模型的任务就是根据前文来预测下一个单词。

该任务是让计算机去掌握语言能力的非常重要的一个任务。一旦计算机掌握了这种预测能力,那么它就掌握了如何更好地理解一句话、如何根据某句话生成后面的回复等工作。
语言模型主要完成两个工作,一是计算一个单词序列称为一个合理语句的(联合)概率:
P ( W ) = P ( w 1 , w 2 , ⋯ , w n ) P(W) = P(w_1,w_2,\cdots,w_n) P(W)=P(w1,w2,⋯,wn)
另一个是根据前面的话来预测下一个词的(条件)概率:
P ( w n ∣ w 1 , w 2 , ⋯ , w n − 1 ) P(w_n|w_1,w_2,\cdots,w_{n-1}) P(wn∣w1,w2,⋯,wn−1)
那么如何完成这两个工作呢?
这里有一个语言模型的基本假设——未来的词只受到前面词的影响。这样我们就可以把句子的联合概率,拆解成条件概率的乘积:
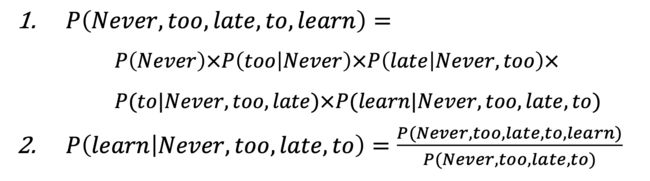
所以语言模型可以写成:
P ( w 1 , w 2 , ⋯ , w n ) = ∏ i P ( w i ∣ w 1 , w 2 , ⋯ , w i − 1 ) P(w_1,w_2,\cdots,w_n) = \prod_i P(w_i|w_1,w_2,\cdots,w_{i-1}) P(w1,w2,⋯,wn)=i∏P(wi∣w1,w2,⋯,wi−1)
一个句子的联合概率等于句子中每个词基于它前面已经出现的词的条件概率之积。
那现在的问题是如何构建语言模型呢?
N-Gram
在过去,一个非常典型的做法叫N-Gram语言模型。它统计前面出现几个词之后,后面出现的那个词的频率是怎样的,比如以4-gram为例:
P ( w j ∣ too late to ) = count ( too late to w j ) count ( too late to ) P(w_j|\text{too late to}) = \frac{\text{ count} ( \text{too late to} \, w_j )}{\text{ count} ( \text{too late to})} P(wj∣too late to)= count(too late to) count(too late towj)
N-Gram遵循了马尔科夫假设,即一个句子出现的联合概率,只考虑单词前面几个有限的词:
P ( w 1 , w 2 , ⋯ , w n ) ≈ ∏ i P ( w i ∣ w i − k , ⋯ , w i − 1 ) P(w_1,w_2,\cdots,w_n) \approx \prod_i P(w_i|w_{i-k},\cdots,w_{i-1}) P(w1,w2,⋯,wn)≈i∏P(wi∣wi−k,⋯,wi−1)
上面的公式表示只考虑前面 k k k个词。
因此根据前面 i − 1 i-1 i−1个词来预测第 i i i个词出现的概率,可以通过前面 k k k个词来简化:
P ( w i ∣ w 1 , w 2 , ⋯ , w i − 1 ) ≈ P ( w i ∣ w i − k , ⋯ , w i − 1 ) P(w_i|w_1,w_2,\cdots,w_{i-1}) \approx P(w_i|w_{i-k},\cdots,w_{i-1}) P(wi∣w1,w2,⋯,wi−1)≈P(wi∣wi−k,⋯,wi−1)
但N-Gram的问题是
- 需要存储所有可能的n-gram,所以一般应用较多的是bi-gram或tri-gram
- 没有捕获到词之间的相似性
神经语言模型
在深度学习出现之后,就产生出了神经语言模型,即基于神经网络取学习词的分布式表示,可以
- 将词与分布式向量关联起来
- 基于特征向量计算词序列的联合概率
- 优化词特征向量(嵌入矩阵 E E E)和损失函数的参数(映射矩阵 W W W)
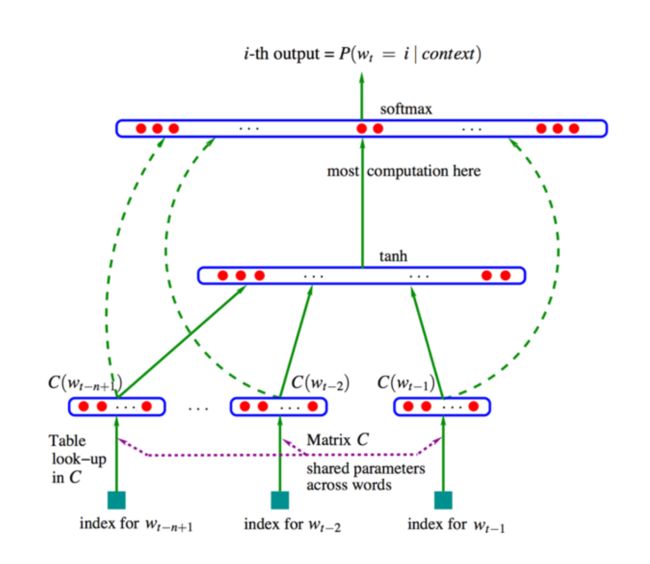
基本思路是,要预测词 w t w_t wt,需要考虑前文。这里前文就是固定大小窗口内的词。假设窗口大小为3,那么就考虑该词前面的三个词。具体地,根据这三个词的索引根据嵌入矩阵得到它们的特征向量,即分布式表示。然后拼接这几个向量,形成一个维度更大的上下文向量。然后经过非线性转换(tanh),之后通过Softmax函数来计算概率出概率最大的下一个词。
因为所有的预测工作,都是基于对上下文的表示来完成的,可以想象由于每个词的向量,和整个匹配的预测过程,都是基于神经网络可学习的参数来完成,所以我们就可以利用大规模的数据来自动地学习这些词向量,自动地去更新神经网络的权重(嵌入矩阵)。
大模型之旅

可以看到,从2013年之后,随着深度学习技术的发展,整个自然语言处理的发展也受到了很大地影响。从13年的Word2Vec,到14年的RNN,到18年的ELMo,以及同年出现的BERT,之后预训练模型就被大量使用。
为什么大模型非常重要

首先在应用了大模型之后,它整个的表现有了突飞猛进的提升。以GLUE为例,该指标的结果有了非常显著的提升。
除了自然语言理解中,在自然语言生成里面,比如对话系统,也取得了非常好的结果。

所以,自18年之后,大家的目光都集中于如何得到一个更好的预训练语言模型,以及如何把预训练语言模型用在更多的任务上。
总地来说,预训练语言模型的发展有三个趋势:
- 不断地增大它的参数
- 不断地增大数据量
- 不断地增大计算量
最后大家发现对预训练语言模型来说很重要的一个趋势就是,增加参数量和数据量之后,训练模型会变得更加有效,并且能显著提升各种任务的表现。
围绕这一点,可以发现,从18年之后,模型参数的增长速度是非常快的。
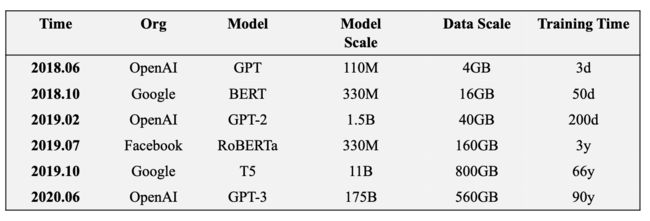
基本以每年十倍的速度往上增长,伴随着模型参数量增大的同时,它们使用的数据规模也在不断地增大,相应地所需要的计算量也不断变大。这就是大模型发展的整体趋势。
然后其实模型大到一定程度之后,我们会从中发现模型掌握了大量知识。比如从GPT-3中,我们会发现它具有一定程度地对世界的认知、常识以及逻辑推理。
 如果我们把它应用到各种各样的NLP任务上,那势必就会产生很好的效果。
如果我们把它应用到各种各样的NLP任务上,那势必就会产生很好的效果。
大模型的另外一方面,或者说一种能力,它具有很强的零样本或少次学习(zero/few-shot learning)的能力。

我们知道深度学习需要大量的标注数据去支撑的,但是GPT-3让我们看到了另外一面,即可以在大规模无标注数据上进行模型学习,学完后让模型具备很多知识。然后在解决具体任务时,就不需要很多的样本,只需要少量的样本去告诉模型要做什么任务,同时引导模型把它与任务相关的知识摘取出来,去解决这个问题。
比如说上图框出来的机器翻译,以往我们需要大量的平行语料。但是对于GPT-3,在无标签数据训练后,哪怕只给出一些少量的翻译样本,该模型也能做出比较好的机器翻译效果。
还有,在GPT-3中,很多复杂的任务,比如编程或下国际象棋,也能转换为基于预训练语言模型的动作序列生成任务。
同时从预训练模型出来后,对于语言模型的关注度也在突然上涨。
大模型背后的范式
- 在预训练阶段,预训练语言模型会从大规模无标注的数据中捕获丰富的知识
- 接着,通过引入任务相关的数据进行微调来调整预训练模型

即预训练-微调范式。这种范式可以溯源到迁移学习。
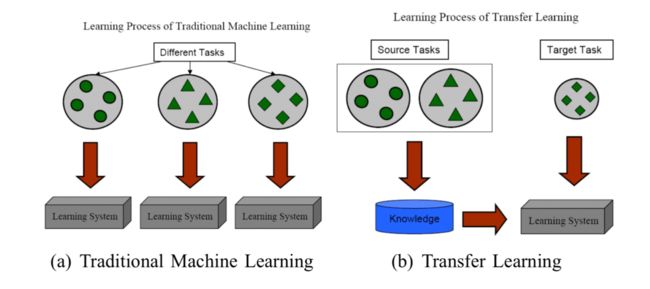
迁移学习使用一个“预训练然后微调”的框架来完成“知识获取然后知识迁移”的工作。
特征表示迁移和参数迁移都被用于后续预训练模型的工作。
词嵌入(Word Embeddings)可以看成是简单的预训练语言模型,比如CBOW和Skip-Gram。
词嵌入从无标签数据中通过自监督学习的范式学习,然后可以当成下游任务的输入。

这是特征表示迁移。
但这种词嵌入技术有两个主要问题:
- 无法处理多义词
- I go to bank(银行) for money deposit
- I go to bank(河岸) for fishing
- 无法处理反义词
- I love this movie. The movie is so bad
- I don’t love this movie. The movie is so good
后来带有上下文信息的词嵌入被提了出来。
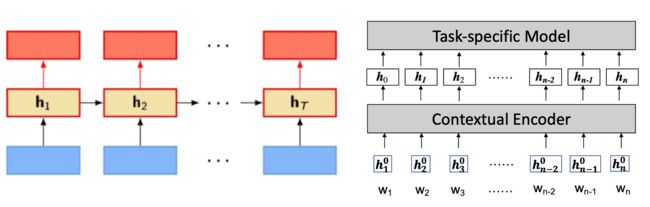
比较有代表性的就是ELMo模型
- 利用RNN在大规模无标签数据上进行语言建模
- 使用该预训练的RNN取生成任务特征的带上下文的词嵌入
说到这种技术,不得不提的一个是Transformer,可以说是一个划时代的技术。

基于Transformer,一系列深度预训练模型被开发出来:
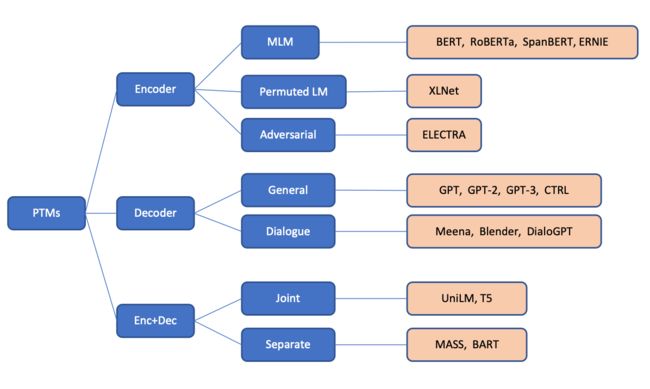
大模型的典型案例
首先是GPT,把语言建模看成一个预训练任务。
L 1 ( C ) = − ∑ i log P ( w i ∣ w 1 w 2 ⋯ w i − 1 ) L_1(C) = -\sum_i \log P(w_i|w_1w_2\cdots w_{i-1}) L1(C)=−i∑logP(wi∣w1w2⋯wi−1)

既可以用在下游生成任务(作为解码器),也可以用在下游语言理解任务(作为编码器)。
另外一个是BERT,它基于两个任务学习。
掩码语言模型(Masked language model, MLM):

下一句预测(Next sentence prediction,NSP)
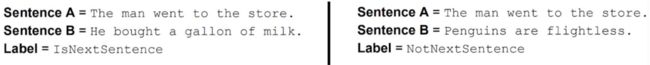
实际上这是一个分类任务。
BERT在微调不同的下游任务时会增加不同的特殊符号:
