注解---
@DS注解,动态数据源,事务:
首先,引入jar包:
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot-starter</artifactId>
<version>2.5.4</version>
</dependency>
然后,在Springboot的application.yml中进行配置:
spring:
datasource:
url: jdbc:mysql://localhost:3306/test2?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
dynamic:
primary: master
datasource:
master:
url: jdbc:mysql://localhost:3306/test2?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
sub:
url: jdbc:mysql://localhost:3306/test2?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8
driver-class-name: com.mysql.cj.jdbc.Driver
username: root1
password: root1
其中配置了两个数据源,master与sub,其中选择master作为默认数据源(对应primary配置);
若想使用sub作为部分代码的数据源,可在ServiceImpl做如下配置:
@DS("sub")
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {}
在使用@DS注解时,有如下注意事项:
- 不能使用事务,否则数据源不会切换,使用的还是第一次加载的数据源;
- 第一次加载数据源之后,第二次、第三次…操作其它数据源,如果数据源不存在,使用的还是第一次加载的数据源;
- 数据源名称不要包含下划线,否则不能切换。
@Scheduled:
1、SpringBoot定时任务@Scheduled
要使用@Scheduled注解,首先需要在启动类添加@EnableScheduling,启用Spring的计划任务执行功能,这样可以在容器中的任何Spring管理的bean上检测@Scheduled注解,执行计划任务
2、参数说明
cron 任务执行的cron表达式
zone cron表达时解析使用的时区,默认为服务器的本地时区,使用java.util.TimeZone#getTimeZone(String)方法解析
fixedDelay 上一次任务执行结束到下一次执行开始的间隔时间,单位为ms
fixedDelayString 上一次任务执行结束到下一次执行开始的间隔时间,使用java.time.Duration#parse解析
fixedRate 以固定间隔执行任务,即上一次任务执行开始到下一次执行开始的间隔时间,单位为ms,若在调度任务执行时,上一次任务还未执行完毕,会加入worker队列,等待上一次执行完成后立即执行下一次任务
fixedRateString 与fixedRate逻辑一致,只是使用java.time.Duration#parse解析
initialDelay 首次任务执行的延迟时间
initialDelayString 首次任务执行的延迟时间,使用java.time.Duration#parse解析
3、定时任务同步/异步执行
定时任务执行默认是单线程模式,会创建一个本地线程池,线程池大小为1。当项目中有多个定时任务时,任务之间会相互等待,同步执行
默认情况下,三个任务串行执行,都使用pool-1-thread-1同一个线程池,并且线程只有一个
可以通过实现SchedulingConfigurer接口,手动创建线程池,配置期望的线程数量
示例代码:
@Configuration
public class ScheduledConfig implements SchedulingConfigurer {
/**
* 任务执行线程池大小
*/
private static final int TASK_POOL_SIZE = 50;
/**
* 线程名
*/
private static final String TASK_THREAD_PREFIX = "test-task-";
@Override
public void configureTasks(ScheduledTaskRegistrar scheduledTaskRegistrar) {
ThreadPoolTaskScheduler taskPool = new ThreadPoolTaskScheduler();
taskPool.setPoolSize(TASK_POOL_SIZE);
taskPool.setThreadNamePrefix(TASK_THREAD_PREFIX);
taskPool.initialize();
scheduledTaskRegistrar.setTaskScheduler(taskPool);
}
}

此时任务的执行已经异步化,从自定义线程池中分配线程执行任务,在实际应用中需要考虑实际任务数量,创建相应大小的线程池
@KeySequence:
Oracle实体类配置主键 Sequence @KeySequence(value=”序列名”,clazz=xxx.class 主键属性类型)
@KeySequence(value = "SEQ_SYS_USER_ID", clazz = String.class)
1、支持父类定义@KeySequence子类继承使用
@TableId:
@TableName 注解用来将指定的数据库表和 JavaBean 进行映射。
使用**@TableId(value=“user_id”,type = IdType.AUTO)**注解
“value”:设置数据库字段值
“type”:设置主键类型、如果数据库主键设置了自增建议使用“AUTO”
type有六种类型类型,最下面三个只有插入主键为空时,才会自动填充:
@TableId(type = IdType.AUTO):id的自增长,
AUTO 数据库自增ID
NONE 数据库未设置主键类型(将会跟随全局)
INPUT 用户输入ID(该类型可以通过自己注册自动填充插件进行填充)
ID_WORKER 全局唯一ID (idWorker)
UUID 全局唯一ID(UUID)
ID_WORKER_STR 字符串全局唯一ID(idWorker 的字符串表示)
注:当添加上@TableId(type = IdType.AUTO)该注解后,你会发现添加完数据后,依然是mybatis-plus自动生成的id,并没有实现id的自增长,要解决该问题,其中有一种方法就是,备份表数据,删除表数据,重新创建该表,就可以实现自增长了。
如果还是不行,表中取消自增,保存;选中自增,保存。
@TableField:
@TableField(select = false) //查询时,则不返回该字段的值
@TableField(value = "email") //通过tableField进行字段不一致的映射
@TableField(exist = false) //设置该字段在数据库表中不存在
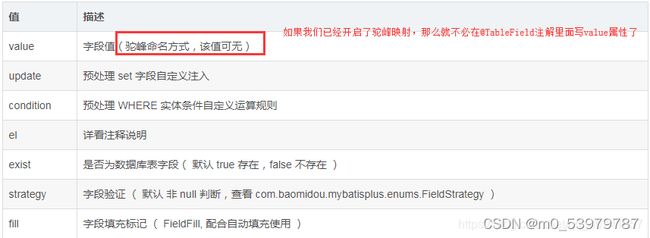
- TableField 注解新增属性 update 预处理 set 字段自定义注入
(讲解:比如我们使用mybatisplus自带的insert()方法向数据库插入数据时,假设我们给age字段赋值为1,但是我们在age字段上的@TableField注解里面加了update="%s+1",那么真真插入到数据库的值就是age=2,而不是age+1了)
例如:@TableField(.. , update="%s+1") 其中 %s 会填充为字段
输出 SQL 为:update 表 set 字段=字段+1 where ...
- 如果给某个字段上@TableField注解里面写update=“now()”,那么最后我们使用mybatisplus自带的insert()方法向数据库插入数据时,这个字段插入到数据库中的值就为当前时间,看下面代码的sql语句即可明白
例如:@TableField(.. , update="now()") 使用数据库时间
输出 SQL 为:update 表 set 字段=now() where ...
- TableField 注解新增属性 condition 预处理 WHERE 实体条件自定义运算规则,下面会有代码讲解
@TableField(condition = SqlCondition.LIKE)
private String name;
输出 SQL 为:select 表 where name LIKE CONCAT('%',值,'%')
@NotBlank:
@NotNull:不能为null,但可以为empty
@NotEmpty:不能为null,而且长度必须大于0
@NotBlank:只能作用在String上,不能为null,而且调用trim()后,长度必须大于0
注:在使用@NotBlank等注解时,一定要和@valid一起使用,不然@NotBlank不起作用
@PathVaribale 获取url中的数据
看一个例子,如果我们需要获取Url=localhost:8080/hello/id中的id值,实现代码如下:
@RestController
public class HelloController {
@RequestMapping(value="/hello/{id}/{name}",method= RequestMethod.GET)
public String sayHello(@PathVariable("id") Integer id,@PathVariable("name") String name){
return "id:"+id+" name:"+name;
}
}
以上,通过@PathVariable注解来获取URL中的参数时的前提条件是我们知道url的格式时怎么样的。
只有知道url的格式,我们才能在指定的方法上通过相同的格式获取相应位置的参数值。
@RequestParam 获取请求参数的值
一般情况下,url的格式为:localhost:8080/hello?id=98,使用@RequestParam获取其id值。
但是,当我们在浏览器中输入地址:localhost:8080/hello?id ,即不输入id的具体值,此时返回的结果为null。
localhost:8080/hello ,即不输入id参数,则会报错:
@RequestParam注解给我们提供了这种解决方案,即允许用户不输入id时,使用默认值,
使用RequestParam,那么则需要前端的Content-Type要设置成application/x-www-form-urlencoded类型。
@RestController
public class HelloController {
@RequestMapping(value="/hello",method= RequestMethod.GET)
//required=false 表示url中可以不传入id参数,此时就使用默认参数
public String sayHello(@RequestParam(value="id",required = false,defaultValue = "1") Integer id){
return "id:"+id;
}
}
@RequestBody
@requestBody注解常用来处理application/json或者是application/xml等。一般情况下来说常用其来处理application/json类型。@RequestBody接受的是一个json格式的字符串,一定是一个字符串。
@GetMapping 组合注解
@GetMapping是一个组合注解,是@RequestMapping(method = RequestMethod.GET)的缩写。该注解将HTTP Get 映射到 特定的处理方法上。处理get请求
@PutMapping和@PostMapping的区别
如果执行添加操作, 后面的添加请求不会覆盖前面的请求, 所以使用@Postmapping
如果执行修改操作, 后面的修改请求会把前面的请求给覆盖掉, 所以使用@PutMapping
@Slf4j:
@Slf4j是用作日志输出的,一般会在项目每个类的开头加入该注解。
如果不想每次都写private final Logger logger = LoggerFactory.getLogger(当前类名.class); 并且想用log,可以用注解@Slf4j;这样就省去这行代码。
@Component注解和@Bean注解的作用,以及两者的区别:
@Component:(把普通pojo实例化到spring容器中,相当于配置文件中的 )
泛指组件,可标注任意类为 Spring 的组件。如果一个类 不知道属于哪个层,可以使用 @Component 注解标注。
@Bean注解告诉Spring这个方法将会返回一个对象,这个对象要注册为Spring应用上下文中的bean。通常方法体中包含了最终产生bean实例的逻辑。
两者的目的是一样的,都是自动注入bean到Spring容器中。
@Component 作用于类,@Bean作用于方法。
Tips: 使用@Component,@Repository,@Service,@Controller注解的类,表示把这些类纳入到spring容器中进行管理,同时也是表明把该类标记为Spring容器中的一个Bean。
@Component :通用的注解,可标注任意类为 Spring 的组件。如果一个 Bean 不知道属于哪个层,可以使用 @Component 注解标注。
@Repository :对应持久层即 Dao 层,主要用于数据访问。
@Service :对应服务层,主要设计一些复杂的逻辑,需要用到 Dao 层。
@Controller :对应 Spring MVC 控制层,主要用来接受用户请求并调用 Service 层返回数据给前端页面。
@Configuration :声明该类为一个配置类,可以在此类中声明一个或多个 @Bean 方法,Spring容器可以使用这些方法来注入Bean。
@Autowire 和 @Resource 的区别:
- @Autowire 和 @Resource都可以用来装配bean,都可以用于字段或setter方法。
- @Autowire 默认按类型装配,默认情况下必须要求依赖对象必须存在,如果要允许 null 值,可以设置它的 required 属性为 false。
- @Resource 默认按名称装配,当找不到与名称匹配的 bean 时才按照类型进行装配。名称可以通过 name 属性指定,如果没有指定 name 属性,当注解写在字段上时,默认取字段名,当注解写在 setter 方法上时,默认取属性名进行装配。
- @Autowire和@Qualifier配合使用效果和@Resource一样:
@Autowired(required = false) @Qualifier("example")
private Example example;
@Resource(name = "example")
private Example example;
@PostConstruct和@PreConstruct :
1、方法初始化和销毁
从Java EE5规范开始,Servlet增加了两个影响Servlet生命周期的注解: @PostConstruct和@PreConstruct ,这两个注解被用来修饰一个非静态的void()方法,而且这个方法不能有抛出异常声明,标注方法的初始化和销毁,当你需要在系统启动时提前设置一下变量或者设置值操作时,可以使用@PostConstruct注解进行项目启动时设置来完成,当你需要处理关闭资源或者发送通知相关操作时可以使用@PreConstruct 完成。
2、 @PostConstruct注解
被@PostConstruct修饰的方法会在服务器加载Servlet的时候运行,并且只会被服务器调用一次,类似于Servlet的inti()方法。被@PostConstruct修饰的方法会在构造函数之后,init()方法之前运行。
3、 @PreDestroy注解
被@PreDestroy修饰的方法会在服务器卸载Servlet的时候运行,并且只会被服务器调用一次,类似于Servlet的destroy()方法。被@PreDestroy修饰的方法会在destroy()方法之后运行,在Servlet被彻底卸载之前。
4、加载顺序如图:
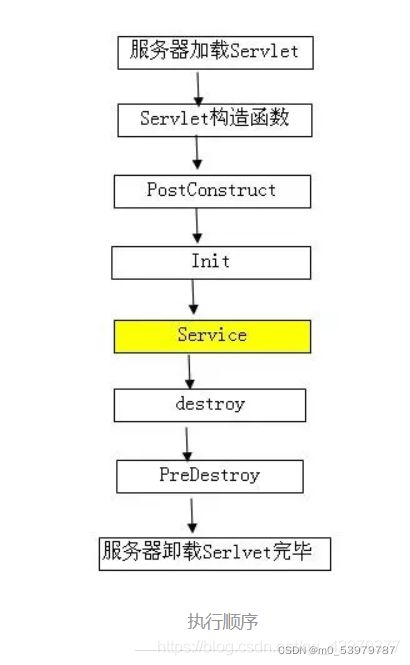
5、在Spring中可以使用以下方式指定初始化方法和销毁方法(方法名任意):
//对象创建并赋值之后调用
@PostConstruct
public void init() {
System.out.println("对象创建并赋值之后调用...");
}
//容器移除对象之前
@PreDestroy
public void detory(){
System.out.println("容器移除对象之前执行...");
}
@Deprecated:
@Deprecated 表示此方法已废弃、暂时可用,但以后此类或方法都不会再更新、后期可能会删除,建议后来人不要调用此方法。
since: 指定已注解的API元素已被弃用的版本。
forRemoval: 表示在将来的既定版本中会被删除,应该迁移 API。
如:
@Deprecated(since = "1.2", forRemoval = true)
@Override:
注解@Override用在方法上,当我们想重写一个方法时,在方法上加@Override,当我们方法的名字出错时,编译器就会报错
@EnableAutoConfiguration:
@EnableAutoConfiguration 这个注解是用来开启自动配置的,这样就不需要配置任何的xml配置文件
@Mapper、@MapperScan:
1、@Mapper注解:
作用:在编译之后会生成相应的接口实现类
添加位置:接口类上面
2、@MapperScan(“类路径”)
作用:指定要变成实现类的接口所在的包,然后包下面的所有接口在编译之后都会生成相应的实现类
添加位置:是在Springboot启动类上面添加,等等
@Transactional回滚问题(try catch、嵌套):
结论
结论一:对于@Transactional可以保证RuntimeException错误的回滚,如果想保证非RuntimeException错误的回滚,需要加上rollbackFor = Exception.class 参数。
@GetMapping("/saveNormal0")
@Transactional
public void saveNormal0() throws Exception {
method1();
throw new RuntimeException();
}
回滚
@GetMapping("/saveNormal0")
@Transactional( rollbackFor = Exception.class)
public void saveNormal0() throws Exception {
method2();
throw new Exception();
}
回滚
结论二:try catch只是对异常是否可以被@Transactional 感知 到有影响。如果错误抛到切面可以感知到的地步,那就可以起作用。
@GetMapping("/saveTryCatch")
@Transactional( rollbackFor = Exception.class)
public void saveTryCatch() throws Exception{
try{
method1();
throw new Exception();
}catch (Exception e){
}
}
不回滚:catch中的错误不继续往上抛,切面无法感知到错误,无法进行处理,那么事务就无法回滚
结论三:由于REQUIRED属性,“两个事务”其实是一个事务,处理能力看报错时刻,是否添加了处理非RuntimeException的能力。
@GetMapping("/out")
@Transactional
public void out() throws Exception{
method1();
}
@Transactional( rollbackFor = Exception.class)
public void inner() throws Exception{
method2();
throw new Exception();
}
回滚:当外面报错的时候,此时查看事务,没有增加rollbackFor = Exception.class参数,即没有处理非RuntimeException能力,所以代码走完,貌似“两个事务”,都回滚失败了。当里面报错的时候,事务已经添加上了处理非RuntimeException能力,所以,代码走完就回滚成功了。
@EqualsAndHashCode:
@EqualsAndHashCode(callSuper = false)
自动的给model bean实现equals方法和hashcode方法。false 不调用父类的属性
@JsonFormat:
@JsonFormat 用来表示json序列化的一种格式或者类型,shap表示序列化后的一种类型
@JsonFormat(shape = JsonFormat.Shape.STRING):解决long类型精度丢失问题;
@JsonFormat(shape = JsonFormat.Shape.STRING , pattern = “yyyy-MM-dd HH:mm:ss”, , timezone = “Asia/Shanghai”):处理时间数据类型和json之前互相转换问题,节省时间提高效率
@DateTimeFormat(pattern = "yyyy-MM-dd")
@JsonFormat(timezone = "GMT+8",pattern = "yyyy-MM-dd")
private Date ytfzrsj;
@JsonAlias和@JsonProperty json 和 bean 之间字段转换 :
@JsonAlias
这个注解是在JackSon 2.9版本中才有的。
作用是在反序列化的时候可以让Bean的属性接收多个json字段的名称。可以加在字段上或者getter和setter方法上。
public class User {
@JsonAlias({"name","user"})
private String username;
private String password;
private Integer age;
}
即json字段是nam
e时也成功对应到了Bean的username属性
如果不加上面那个注解肯定会报json解析异常错误。
注意:序列化的时候仍然是原始的属性名称,只是在反序列化的时候可以接收多个json字段,如果多个json字段对应了Bean里面的同一个属性,依然会报Json解析异常错误的。
@JsonProperty
这个注解是更改Bean字段的属性名用的。
Access.WRITE_ONLY:只在序列化时使用修改后的字段
Access.READ_ONLY:只在反序列化时使用,类似于@JsonAlias注解
Access.READ_WRITE:在序列化和反序列化都使用修改后字段
Access.AUTO:自动确定,一般是和第三个一样,啥情况不一样我也不清楚,如果不写access,默认就是这个。
value是逻辑属性的名称,如果只有value则省略
@JsonProperty(value = "name", access = JsonProperty.Access.WRITE_ONLY)
private String username;
access是更改逻辑属性序列化和反序列化的可见性,
@TableLogic:
@TableLogic注解表示逻辑删除
效果:在字段上加上这个注解再执行BaseMapper的删除方法时,删除方法会变成修改方法
@TableLogic
private Integer dataStatus;
调用BaseMapper的deleteById(id)或者调用IService的removeById(id)
效果:
没有@TableLogic注解调用deleteById/removeById,直接删除数据。
SQL: delete from table where id = 1
有注解走Update方法
SQL:Update table set isDelete = 1 where id = 1
@TableLogic注解参数
value = “” 未删除的值,默认值为0
delval = “” 删除后的值,默认值为1
@TableLogic(value="原值",delval="改值")
当使用了@TableLogic注解,调用update方法是并不会将该字段放入修改字段中,而是在条件字段中。即使你给dataStatus赋值也不会修改。
sql:
Update table set 字段1 = 值1,字段2 = 值2 where id = 1 and data_status = 0
@SuppressWarnings:
J2SE 提供的最后一个批注是 @SuppressWarnings。该批注的作用是给编译器一条指令,告诉它忽略指定的警告。
@SuppressWarnings 批注允许您选择性地取消特定代码段(即,类或方法)中的警告。其中的想法是当您看到警告时,您将调查它,如果您确定它不是问题,
您就可以添加一个 @SuppressWarnings 批注,以使您不会再看到警告。虽然它听起来似乎会屏蔽潜在的错误,但实际上它将提高代码安全性,因为它将防止
您对警告无动于衷 — 您看到的每一个警告都将值得注意。
作用:用于抑制编译器产生警告信息。
使用:
@SuppressWarnings(“”)
@SuppressWarnings({})
@SuppressWarnings(value={"A","B"})
注解目标:
通过 @SuppressWarnings 的源码可知,其注解目标为类、字段、函数、函数入参、构造函数和函数的局部变量。
关键字:
all (抑制所有警告)
boxing (抑制装箱、拆箱操作时候的警告)
cast (抑制映射相关的警告)
dep-ann (抑制启用注释的警告)
deprecation (抑制过期方法警告)
fallthrough (抑制确在switch中缺失breaks的警告)
finally (抑制finally模块没有返回的警告)
hiding
incomplete-switch (忽略没有完整的switch语句)
nls (忽略非nls格式的字符)
null (忽略对null的操作)
rawtypes (使用generics时忽略没有指定相应的类型)
restriction
serial (忽略在serializable类中没有声明serialVersionUID变量)
static-access (抑制不正确的静态访问方式警告)
synthetic-access (抑制子类没有按最优方法访问内部类的警告)
unchecked (抑制没有进行类型检查操作的警告)
unqualified-field-access (抑制没有权限访问的域的警告)
unused (抑制没被使用过的代码的警告)
@Lazy:
Spring IOC (ApplicationContext) 容器一般都会在启动的时候实例化所有单实例 bean 。如果我们想要 Spring 在启动的时候延迟加载 bean,即在调用某个 bean 的时候再去初始化,那么就可以使用 @Lazy 注解。
属性
value 取值有 true 和 false 两个 默认值为 true
true 表示使用 延迟加载, false 表示不使用,false 纯属多余,如果不使用,不标注该注解就可以了。
@Lazy注解注解的作用主要是减少springIOC容器启动的加载时间
当出现循环依赖时,也可以添加@Lazy
@JsonIgnore:
作用:在json序列化时将pojo中的一些属性忽略掉,标记在属性或者方法上,返回的json数据即不包含该属性。
@FeignClient:
常用属性
- value, name:value和name的作用一样,如果没有配置url那么配置的值将作为服务名称,用于服务发现。反之只是一个名称。
- url: url一般用于调试,可以手动指定@FeignClient调用的地址
- decode404:当发生http 404错误时,如果该字段位true,会调用decoder进行解码,否则抛出FeignException
- configuration: Feign配置类,可以自定义Feign的Encoder、Decoder、LogLevel、Contract
- fallback: 定义容错的处理类,当调用远程接口失败或超时时,会调用对应接口的容错逻辑,fallback指定的类必须实现@FeignClient标记的接口
- fallbackFactory: 工厂类,用于生成fallback类示例,通过这个属性我们可以实现每个接口通用的容错逻辑,减少重复的代码
- path: 定义当前FeignClient的统一前缀
@ControllerAdvice:
@ControllerAdvice:全局异常处理器;默认情况下,@ControllerAdvice 中的方法应用于全局所有的 Controller
我们最常使用的是结合 @ExceptionHandler 用于全局异常的处理。捕获自定义的异常进行处理,并且可以自定义状态码返回:
@Builder:
关于Builder较为复杂一些,Builder的作用之一是省去写很多构造函数的麻烦,进行快速开发
@Builder:用构造者模式生成对象,并且可以为对象链式赋值
@Data @Builder:混合使用,对应的场景为在生成对象的时候通过构造者模式生成对象,然后将生成的对象作为 JavaBean 使用
@Data
@Builder
public class Student {
String name;
int age;
}
使用:
Student student = Student.builder().name("18").age(19).build();
- 但是通过对反编译的代码进行简单的分析后,很明显的会发现会有两个问题:
一、在整个过程中会多创建个中间类StudentBuilder实现解耦合,多占用了内存。
二、由于bulider()方法是类方法,所以在进行创建过第一次后,不能对创建后的对象继续进行动态赋值。
所以推荐使用@Accessors
lombok部分注解:
@Cleanup:关闭流
@Synchronized:对象同步
@SneakyThrows:抛出异常
@Accessors:
1、@Accessors(fluent = true)
使用fluent属性,getter和setter方法的方法名都是属性名,且setter方法返回当前对象
@Data
@Accessors(fluent = true)
class User {
private Integer id;
private String name;
// 生成的getter和setter方法如下,方法体略
public Integer id(){}
public User id(Integer id){}
public String name(){}
public User name(String name){}
}
2、@Accessors(chain = true)
使用chain属性,setter方法返回当前对象,即链式赋值
@Data
@Accessors(chain = true)
class User {
private Integer id;
private String name;
// 生成的setter方法如下,方法体略
public User setId(Integer id){}
public User setName(String name){}
}
3、@Accessors(prefix = “f”)
使用prefix属性,getter和setter方法会忽视属性名的指定前缀(遵守驼峰命名)
@Data
@Accessors(prefix = "f")
class User {
private Integer fId;
private String fName;
// 生成的getter和setter方法如下,方法体略
public Integer id(){}
public void id(Integer id){}
public String name(){}
public void name(String name){}
}
@Value:
@Value三种情况的用法。
1、$是去找外部配置文件中对应的属性值
假如我有一个sys.properties文件 里面规定了一组值: web.view.prefix =/WEB-INF/views/
@Value("${web.view.prefix}")
private String prefix;
2、#是SpEL表达式,获取bean的属性,或者调用bean的某个方法。当然还有可以表示常量
3、直接写字符串就是将字符串的值注入进去
@Synchronized:
synchronized是线程安全中一个重要的关键字,它是一种同步锁,主要用来保证在同一个时刻,只有一个线程可以执行某个方法或者某段代码块。一般使用synchronized去锁住代码块,而不是方法,因为锁住代码块效率更高。
SpringCloud:
@ConditionalOnClass:
1、@ConditionalOnClass通常与@Configuration 结合使用,意思是当classpath中存在xxx类时满足条件,实例化一个Bean
@ConditionalOnClass(xxx.class)
2、当报错“找不到类路径时”,用类的 所在包路径 + 类名 当参数即可
@ConditionalOnClass(name = "org.springframework.kafka.core.KafkaTemplate")
@ConditionalOnBean(仅仅在当前上下文中存在某个对象时,才会实例化一个Bean)
@ConditionalOnClass(某个class位于类路径上,才会实例化一个Bean)
@ConditionalOnExpression(当表达式为true的时候,才会实例化一个Bean)
@ConditionalOnMissingBean(仅仅在当前上下文中不存在某个对象时,才会实例化一个Bean)
@ConditionalOnMissingClass(某个class类路径上不存在的时候,才会实例化一个Bean)
@ConditionalOnNotWebApplication(不是web应用)
java中元注解有四个: @Retention @Target @Document @Inherited:
@Retention:注解的保留位置
注解按生命周期来划分可分为3类:
1、RetentionPolicy.SOURCE:注解只保留在源文件,当Java文件编译成class文件的时候,注解被遗弃;
2、RetentionPolicy.CLASS:注解被保留到class文件,但jvm加载class文件时候被遗弃,这是默认的生命周期;
3、RetentionPolicy.RUNTIME:注解不仅被保存到class文件中,jvm加载class文件之后,仍然存在;
这3个生命周期分别对应于:Java源文件(.java文件) —> .class文件 —> 内存中的字节码。
那怎么来选择合适的注解生命周期呢?
首先要明确生命周期长度 SOURCE < CLASS < RUNTIME ,所以前者能作用的地方后者一定也能作用。一般如果需要在运行时去动态获取注解信息,那只能用 RUNTIME 注解;如果要在编译时进行一些预处理操作,比如生成一些辅助代码(如 ButterKnife),就用 CLASS注解;如果只是做一些检查性的操作,比如 @Override 和 @SuppressWarnings,则可选用 SOURCE 注解。
@Target:注解的作用目标
@Target(ElementType.TYPE) //接口、类、枚举、注解
@Target(ElementType.FIELD) //字段、枚举的常量
@Target(ElementType.METHOD) //方法
@Target(ElementType.PARAMETER) //方法参数
@Target(ElementType.CONSTRUCTOR) //构造函数
@Target(ElementType.LOCAL_VARIABLE)//局部变量
@Target(ElementType.ANNOTATION_TYPE)//注解
@Target(ElementType.PACKAGE) ///包
Swagger,Knife4j:
@API:
@API使用在类上,表明是swagger资源,@API拥有两个属性:value、tags
生成的api文档会根据tags分类,直白的说就是这个controller中的所有接口生成的接口文档都会在tags这个list下;tags如果有多个值,会生成多个list,每个list都显示所有接口
value的作用类似tags,但是不能有多个值
@ApiOperation:
使用于在方法上,表示一个http请求的操作
源码中属性太多,记几个比较常用
value用于方法描述
notes用于提示内容
tags可以重新分组(视情况而用)
@ApiModel():
使用在类上,表示对类进行说明,用于参数用实体类接收
value–表示对象名
description–描述
@ApiModelProperty():
使用在字段上,表示对model属性的说明或者数据操作更改
value–字段说明
name–重写属性名字
dataType–重写属性类型
required–是否必填
example–举例说明
hidden–隐藏
@ApiParam:
使用在方法上或者参数上,字段说明;表示对参数的添加元数据(说明或是否必填等)
name–参数名
value–参数说明
required–是否必填
@ApiIgnore:
@ApiIgnore 可以用在类、方法上,方法参数中,用来屏蔽某些接口或参数,使其不在页面上显示。忽略的意思就是 swagger-ui.html 上不会显示对应的接口信息。
1、隐藏某个类还可以用@Api注解自带的hidden属性:
@Api(value = "xxx", tags = "xxx",hidden = true)
2、隐藏某个方法还可以用@APIOperation注解自带的hidden属性:
@ApiOperation(value = "xxx", httpMethod = "GET", notes = "xxx",hidden = true)
3、作用在参数上时,单个具体的参数会被忽略
public String abc(@ApiIgnore String a, String b, String c){
return "a" + "b" + "c";
}
补充:
4、 在实体类中忽略不需要字段的方式:
(1)用@ApiModelProperty注解自带的hidden属性:
@ApiModelProperty(value = "xxxid", required = true,hidden = true)
private Long id;
(2)使用@JsonIgnore注解:
@ApiModelProperty(value = "xxxid", required = true)
@JsonIgnore
private Long id;
# 学习目标:
提示:这里可以添加学习目标
例如:一周掌握 Java 入门知识
学习内容:
提示:这里可以添加要学的内容
例如:
1、 搭建 Java 开发环境
2、 掌握 Java 基本语法
3、 掌握条件语句
4、 掌握循环语句
学习时间:
提示:这里可以添加计划学习的时间
例如:
1、 周一至周五晚上 7 点—晚上9点
2、 周六上午 9 点-上午 11 点
3、 周日下午 3 点-下午 6 点
学习产出:
提示:这里统计学习计划的总量
例如:
1、 技术笔记 2 遍
2、CSDN 技术博客 3 篇
3、 学习的 vlog 视频 1 个