论文地址:原始音频的带宽扩展通过生成对抗网络
博客作者:凌逆战
博客地址:https://www.cnblogs.com/LXP-Never/p/10661950.html
摘要
基于神经网络的方法最近在图像合成和超分辨率任务方面展示了最先进的结果,特别是通过使用具有监督特征损失的生成对抗网络(GANs)的变体。然而,以前的特征损失公式依赖于大型辅助分类器网络的可用性,以及能够训练此类分类器的标记数据集。此外,对于基于GAN的方法在图像和视频以外的领域的适用性的研究相对较少。在本研究中,我们探讨了一种基于GAN的音频处理方法,并开发了一个卷积神经网络结构来执行音频超分辨率。除了用于音频处理的几个新的体系结构构之外,我们方法的一个关键组成部分是使用基于自动编码器的丢失,它支持在GAN框架中进行训练,其特征损失来自未标记的数据。我们探索了我们的建筑选择的影响,并在客观和感性的质量方面展示了与之前的作品相比的重大改进。
1 引言
深度卷积神经网络(CNNs)已成为现代图像和音频分析解决方案的基石。这类网络在监督识别任务方面表现出色,例如在ImageNet[5,36]上,图像分类器网络是在大量标记数据的基础上训练的。近年来,CNNs已成功地应用于生成对抗网络(GANs)[12]环境下的数据合成问题。在GAN框架中,神经网络用于从建模的分布中综合新的实例,或解决给定有损观测的缺失细节。在后一种情况下,与导致过度平滑输出的独立样本空间损失相比,GAN已经被证明可以大大改善图像精细纹理细节的重建[8,14,24]。然而,GAN是出了名的难以训练,使用传统的样本空间目标与对抗性损失结合,要么使训练失去稳定性,要么导致输出具有值的注意的artifacts(人工产品)(图1)。
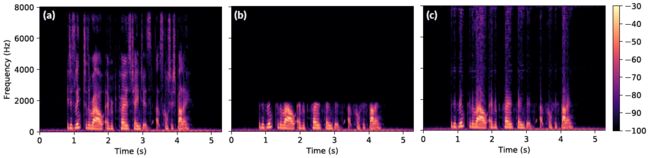
图1:对GAN进行简单的音频处理训练,往往会导致输出带有明显的伪影。上面的语谱图显示(a)高分辨率,(b)低分辨率,(c)简单处理后的超分辨率音频。超分辨谱图对应于由受过对抗性损失和常规$L2$损失训练的GAN产生的音频。
为了解决上述平滑性问题,以往的工作通常用特征损失(也称为感知损失)来增加或替代传统的样本空间损失[8,18,10,24]。这种特征损失不是原始样本空间中的距离,而是用辅助神经网络的特征映射反映距离。虽然基于分类器的特征丢失是有效的,但是它们需要一个适用于问题域的预先训练的神经网络(例如,合成猫的图像),或者一个易于训练相关分类器的标记数据集。训练新的分类器以用于特征丢失是非常重要的,原因有很多。除了难以训练通常用于特征丢失的大型分类器,例如VGG[36],创建足够大且多样的标记数据集通常是不可行的。
在这项工作中,我们通过开发一种无监督的特征损失来克服辅助分类器训练的困难。特别地,我们关注一个称为超分辨率的音频建模任务,其目标是生成高质量的音频,提供低采样、低分辨率的输入。受之前在音频和图像超分辨率方面的工作启发,我们开发了一个端到端超分辨率的神经网络架构,该架构可以对原始音频进行操作。除了为音频建模提供新的算法外,我们的工作还提出了在其他领域改进基于GAN的方法的新技术
比如图像和视频。具体来说,我们的贡献如下:
1. 我们提出了一种新的、通用的、完全无监督的特征丢失方法,它可以避免使用基于分类器的有问题模型。
2. 我们成功地将对抗性框架应用于音频处理,并展示了如何将非监督特性丢失合并到训练中,从而稳定训练,并提高结果质量。
3. 我们展示了我们的方法在一个端到端架构的音频超分辨率,与最先进的结果在语音和音乐任务。
4. 我们提供了我们的方法的详细分析,包括客观的质量评估,感性的用户研究,金融分析。
2 背景以及相关工作
Audio super-resolution 音频超分辨率
音频超分辨率是由包含原始样本的一小部分的低分辨率信号构建高分辨率音频信号的任务。具体来说,给定一个低分辨率序列的音频样本$x_l=(x_{\frac{1}{R_h}},...,x_{\frac{R_hT}{R_h}})$,我们希望合成一个高分辨率的音频信号$x_h=(x_{\frac{1}{R_h}},...,x_{\frac{R_hT}{R_h}})$,其中$R_l$和$R_h$分别为低分辨率和高分辨率信号的采样率。我们将$R=R_h=R_l$表示为upsampling ratio(上采样比率),本工作中上采样比为$2\sim 6$。因此,音频超分辨率问题等价于重构$R_l=2$和$R_h=2$之间缺失的频率内容。
在人工带宽扩展[23]术语下,在信号和音频处理社区中已有大量关于音频超分辨率的前期工作。该领域基于神经网络的方法通常将DNN作为复杂带宽扩展系统的一部分应用于手工制作的特性之上[26,1]。高斯混合模型和隐马尔可夫模型也被使用[40,3],但是这些方法通常比神经网络[1]表现得更差。与上述工作相比,我们的方法不依赖于手工制作的特征(如变换或倒谱系数),也不针对语音建模中的问题。
Audio modeling with neural networks 音频建模与神经网络
基于学习的音频方法在很大程度上也在表示学习、生成建模和文本传输技术(TTS)系统的上下文中得到了探索。研究表明,无监督的方法,如卷积深信网络[25]和瓶颈CNN[2]已被证明可以从音频中学习有用的表示,如音素和声音纹理。叠加自动编码器[43]和变分自动编码器[21,37]已用于去噪、图像生成和音乐合成[34]。与以前的DNN和基于样条的[22]方法相比,瓶颈式的CNNs在监督设置下的音频超分辨率也有了显著的改进。[7]是最早用甘斯开发原始音频合成方法的作品之一。值得注意的是,文献[7]的作者指出,为了生成多样且可信的音频输出,需要对gan架构进行非平凡的修改。我们在上述工作的基础上,开发了一个带有改进瓶颈样式生成器的音频超分辨率GAN框架,并表明利用从无监督培训中学习到的表示对超分辨率任务有很大帮助。自回归概率模型最近已经证明了音乐生成[9]、通用音频[41,28]和参数化TTS系统[38]的先进成果。有几项研究利用模型蒸馏[42]来降低自回归方法的开销,使其适用于实时音频生成。一般来说,我们的工作可以用来增强现有的语音合成系统,包括那些使用自回归方法的系统。例如,我们工作中提出的无监督特征丢失可以作为在[42]中使用的基于分类器的特征丢失的替代品。虽然我们没有意识到任何探索音频超分辨率自回归建模的努力,但我们相信这可能是一个有前途的未来方向。
Generative adversarial networks for images 为图像生成对抗性网络
生成方法在图像生成和超分辨率方面得到了广泛的研究。GANs在[12]的基础上不断改进,生成可信的高保真图像[32,6,4,19]。以类标签或对象草图为条件的GAN变体在绘画和风格转换等任务中也显示出了良好的效果[30,14]。
3 方法
生成对抗网络的超分辨率
与[12]的原始公式相比,针对超分辨率任务开发的GANs具有几个重要的不同之处。当从数据分布$p_{data}$生成新实例时,由$\theta _G$参数化的生成器(G)学习到数据空间的映射为$G(z;\theta _G)$,其中$z$是一个潜在的noise prior(噪声先验)。然后由$\theta _D$参数化的鉴别器(D)估计 $G(z;\theta _G)$的概率,$G(z;\theta _G)$是从$p_{data}$而不是从生成器分布$p_g$中得来的的概率。相反,对于超分辨率,G不再受到噪声的制约,学习映射到高分辨率数据空间的$p_h$值作为$G(x_l;\theta _G)$,其中$x_l$是从低分辨率数据分布$p_l$中提取出来的。D的任务是分别从高分辨率和超分辨率(生成器)分布的$p_h$和$p_g$中区分样本。由于低分辨率数据$x_l$在训练过程中直接对应于一个高采样版本的$x_h$,所以我们希望$G(x_l;\theta _G)\approx x_h$。G和D是根据两个玩家的极大极小问题进行优化的:
$$\min_{\theta _G}\min_{\theta _D}E_{x_h\sim p_h(x_h)}[\log D(x_h;\theta_D)]+E_{x_l\sim p_l(x_l)}[\log (1-D(G(x_l;\theta _G)))]$$
该框架实现了两个神经网络的联合优化——G生成以欺骗D为目标的超分辨率数据,并训练D区分真实数据和超分辨率数据。因此,GAN方法鼓励G学习到 难以与真实高分辨率数据区分 的解决方案。
框架总述
MU-GAN (Multiscale U-net GAN)由三个模型组成,它们都在原始音频上运行——生成器(G)、鉴别器(D)和卷积自编码器(A)(图2)。生成器的任务是学习分别对应于$x_l$和$x_h$信号的低分辨率和高分辨率数据空间之间的映射。鉴别器的任务是对呈现的数据实例是真实的,还是由生成器生成的进行分类。除了G和D,自动编码器还从真实和超分辨率数据中extracts(提取)perceptually-relevant(感知相关)的features(特征),用于feature-space(特征空间)损失函数。在GAN框架中使用A是至关重要的,因为仅针对L2或其他样本空间损失进行训练的生成器会受到训练instability(不稳定性)或输出artifacts(伪影)[24]的影响。
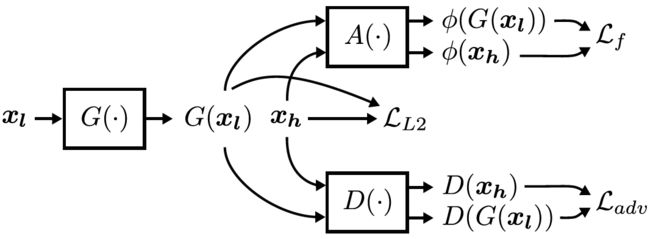
图二: 模型体系结构概述及相应的损失项
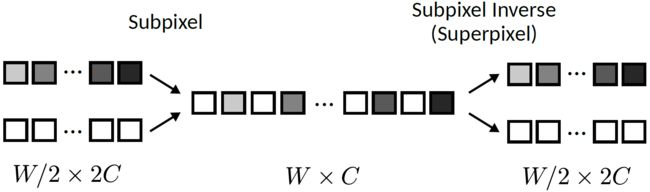
图3:分别用于提高和降低空间分辨率的Subpixel(子像素)层和superpixel(超像素)层
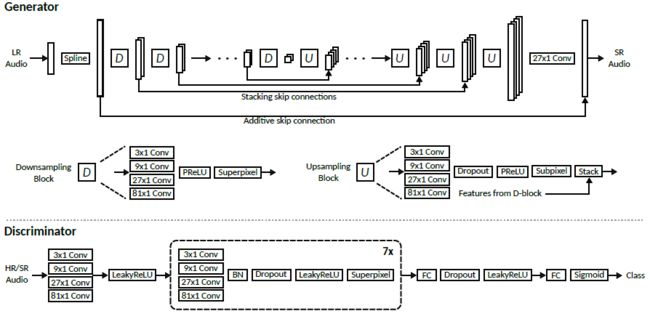
图4:生成器和鉴别器模型
Multiscale convolutional layers 多尺度卷积层
与图像相比,当采样time-scales(时间尺度)在10秒到100秒之间时音频信号具有周期性。因此,需要具有非常大的receptive fields(接受域)的过滤器来创建高质量的原始音频[41,7]。以前对分类器模型的研究也表明,在网络中改变filter(滤波器)的size(大小)有助于捕获multiple scales(多尺度)[39]下的信息。利用这些观察结果,我们使用由3x1、9x1、27x1和81x1级联滤波器组成的multiscale(多尺度)卷积构建block(块)。在实践中,对于给定的层,在固定参数数量的情况下,我们发现大于81x1的滤波器没有提供额外的好处,而如果忽略较大的滤波器尺寸会导致音频质量显著下降。我们认为小滤波器性能差是其频率选择性byproduct(相关);从信号处理理论可知,FIR滤波器的频率响应分辨率与滤波器的长度成正比。
Superpixel layers Superpixel层
空间分辨率的处理方法是图像和音频合成模型的关键组成部分。最近,有研究表明pooling(池化)和卷积strided(步长)往往会导致周期性的"checkerboard(棋盘)"artifacts(伪影)[31,7]。虽然亚像素层[35]已被证明不太容易出现"checkerboard(棋盘)"artifacts(伪影),但还没有研究评估 inverse operation(反向运算)decreasing(降低)spatial(空间)分辨率方面的性能。具体地说,inverse subpixel operator(逆亚像素运算)将样本从时间维度交叉到信道维度,从而将空间分辨率降低了一个integer factor(整数因子)。我们将这个简单的逆操作称为superpixel(超像素)层(图3),并用它来代替strided (跨步)卷积和池层。
Generator network 生成器网络
生成器网络的高级体系结构(图4)受到autoencoder-like U-net模型的启发[33、14、22]。在U-net-style模型中,网络的前半部分由B个下采样块(D-blocks)组成,它们在多个尺度和分辨率下执行特征提取。(注意,为了$G$的输入和输出处具有匹配的分辨率,$LR$信号首先用三次样条曲线向上采样。)模型的后半部分由B上采样块(U-blocks)组成,U-blocks依次增加信号的空间分辨率。我们利用multi-scale(多尺度)卷积层的throughput(吞吐量)对生成网络进行处理,并用superpixel(超像素)层代替所有的strided(跨步)卷积。
Discriminator network 鉴别器网络
在训练过程中,鉴别器(图4)被用来区分真实的、高分辨率的音频和由发生器产生的超分辨率信号。我们的设计松散地基于[32]的recommendations(推荐)和[24]的图像鉴别器。所有鉴别器的激活函数都是leakyReLU[27],其值为0:2。与生成器一样,我们使用多尺度卷积,并且上面描述的超像素层代替strided(步幅)卷积,以最小化损失梯度[31]中的伪影。
Autoencoder network 自编码网络
自动编码器$A$用于从低分辨率信号中提取相关的感知特征。A提取的特征被合并到生成器的特征损失$L_f$中,后面的部分将更详细地描述。对于$A$的特定实现,我们使用生成器模型的修改版本,该版本排除了所有additive(加法)和stacking skip connections(叠加跳过连接)。因此,$A$的模型是一个卷积自编码器,增加了多尺度卷积层和super/subpixel(超/亚像素)层用于down/up-sampling.(上/下采样)。
Loss functions 损失函数
MU-GAN包含了几个用于训练生成器和鉴别器的损失项。生成器损失的第一项是sample-space(采样空间)L2损耗,由2给出(我们用一个隐式平均值来表示单个样本的损失)
$$L_{L2}=\frac{1}{W}\sum _{i=1}^W||x_{h,i}-G(x_l)_i||_2^2$$
我们发现,仅使用sample-space(采样空间)和adversarial losses(对抗损失),要么比非GAN模型几乎没有改善,要么引入了持续性的听觉artifacts(伪影)(例如高频音调,图1)。如第2节所述,将特征损失与GAN训练结合使用,会鼓励生成器学习包含感知相关texture(本质)细节的解决方案。给定自编码器$A$,我们将自编码器bottleneck(瓶颈)处的输出特征张量表示为A,然后将特征丢失$L_F$表示为
$$L_f=\frac{1}{C_FW_f}\sum _{c=1}^{C_f}\sum _{i=1}^{W_f}||\phi (x_h)_{i,c}-\phi (G(x_l))_{i,c}||_2^2$$
其中$W_f$和$C_f$分别表示自编码瓶颈feature maps(特征映射)的width(宽度)和channel dimensions(通道维度)。对抗性损失$L_{adv}$是由鉴别器识别生成数据真伪的能力决定的。我们使用的梯度友好的公式最初提出在[12],由
$$L_{abv}=-\log D(G(x_l))$$
然后生成器的综合损失$L_G$由上述损耗之和给出,鉴别器损失$L_D$直接由式(1)中的GAN优化目标得到,即
$$L_G=L_{L2}+\lambda _fL_f+\lambda _{adv}L_{adv}$$
$$L_D=-[\log D(x_h)+\log (1-D(G(x_l)))]$$
其中$\lambda _f$和$\lambda _{adv}$是常数scaling factors(缩放因子)。
4 实验
Datasets 数据集
我们评估了从VCTK语料库[44]和来自[28]的non-vocal music dataset(非声乐数据集)导出的三个超分辨率任务的方法。对于来自VCTK的语音,我们组成一个来自单个说话人(Speaker1任务)的语音组成 数据集,再组成一个来自多说话人的语音 数据集(Speaker99任务)。Speaker1由VCTK speaker 225的前223段录音组成,用于训练,最后8段音频用于测试。Speaker99使用前99位VCTK说话人的所有语音进行训练,并使用后10位说话人的语音进行测试。Piano(钢琴)采用标准的88%-6%-6%的训练/验证/测试分割。对于所有任务,首先采用anti-aliasing lowpass filter(抗混叠低通滤波器)创建数据集,然后从产生的音频中随机采样fixed length(固定长度)的patches(小块)。注意,对于直接比较,上面的数据集与[22]中使用的数据集相同。
Training methodology 训练方法
对于Speaker1,我们instantiate(实例化)了MU-GAN的variants(变体),并训练了400个epochs周期。对于更大的数据集Speaker99和Piano,模型被训练了150个epochs周期。epochs周期数是根据观察到的收敛性和验证集上的性能saturation(饱和) 经验选择的。对于所有模型,我们使用ADAM优化器[20],学习率为1e-4, B1 = 0:9,$\beta _1=0.9$,$\beta _2=0.999$,batch size(批次大小)为32。对于自动编码器特性损失,我们用$L=4$实例化一个模型,并在与其associated(关联)的GAN模型相同的数据集上训练400个epoch。loss scaling(损失比例)factors(因子)$\lambda _f$和$\lambda _{adv}$分别固定在1.0和0.001。
Performance metrics 性能度量
我们使用三个指标来评估超分辨音频的质量:
(1)signal-to-noise ratio信噪比(SNR)
(2)log-spectral distance对数光谱距离(LSD)
(3)mean opinion score平均意见评分(MOS)
信噪比是信号处理领域的一个标准度量,定义为
$$SNR(x,x_{ref})=10\log _{10}\frac{||x_{refe}||_2^2}{||x-x_{ref}||_2^2}$$
其中$x$是参考信号$x_{ref}$的近似值。LSD[13]测量信号频率之间的差异,与信噪比相比,LSD与感知质量的相关性更好[17,22]。给定短时离散傅里叶变换$X$和$X_{ref}$, LSD由
$$LSD(X,X_{ref})=\frac{1}{W}\sum _{w=1}^W\sqrt{\frac{1}{K}\sum _{k=1}^N(\log _{10}\frac{|X(w,k)|^2}{|X_{ref}(w,k)|^2})^2}$$
其中w和k分别是窗口和频率bin指标(我们使用长度为2048的non-overlapping(非重叠)傅里叶变换窗口)。语音质量感知评价(PESQ)[16]是一种评价语音通信系统的行业标准方法。在给定参考和degraded(降级)音频信号的情况下,PESQ对一组听众的平均意见得分(MOS)进行建模。具体来说,我们使用PESQ来产生MOS-LQO(听力质量目标)评分[15],范围从1到5。
Impact of superpixel layers 超像素层的影响
我们发现,使用超像素层可以使整个模型尺寸的培训时间提高约14%,而在目标质量指标方面没有显著差异。在非正式的自盲听力测试中,两种方法产生的音频差异也不明显。这表明超像素层可以很好地替代传统的strided(步幅)卷积,同时在不影响性能的前提下提高训练时间。
Objective performance evaluation 客观性能评估
表1给出了$MU-GAN$相对于其他近期公作的定量表现。我们将MU-GAN8表示为深度参数$L = 8$的$MU-GAN¥实例,即,有8个下采样模块和8个上采样模块。从[22]得到$U-net4$是$L = 4$的模型。为了消除性能比较中的深度因素,我们重新实现了一个$L=8$更深的$U-net$体系结构,表示为U-net8。
表1显示,与基线模型相比,MU-GAN8的信噪比通常较差,但LSD较低,而MOS-LQO较高。这表明,虽然MU-GAN8产生的重构音频具有较低的信噪比,但偏离sample-wise distance(采样方向的距离)导致合成更多的perceptually-relevant(感知相关)的频率内容。钢琴任务是个例外,在信噪比方面,$MU-GAN8$比U-net基线表现好几个数量级。总的来说,我们还发现,$U-net8$和$MU-GAN8$在语音任务上的性能通常在R = 2时达到饱和。非正式的听力测试证实,在$R = 2$的差异最小,这表明更困难的上采样率(即, R = 4、6)更适合作进一步比较。
表1:与基线超分辨率网络的客观比较(U-net4的Metrics(度量)直接取自[22];那些$U-net8$是我们重新实现的)
| Up. Ratio R = 2 | Up. Ratio R = 4 | Up. Ratio R = 6 | ||||||||
| U-net4 | U-net8 | MU-GAN8 | U-net4 | U-net8 | MU-GAN8 | U-net4 | U-net8 | MU-GAN8 | ||
| Speaker1 | SNR | 21.1 | 21.94 | 21.40 | 17.1 | 18.68 | 17.72 | 14.4 | 14.85 | 13.98 |
| LSD | 3.2 | 2..24 | 1.63 | 3.6 | 2.34 | 1.92 | 3.4 | 2.92 | 1.95 | |
| MOS-LQO | - | 4.54 | 4.54 | - | 3.81 | 3.79 | - | 2.97 | 3.21 | |
| Speaker99 | SNR | 20.7 | 20.05 | 20.01 | 16.1 | 14.30 | 14.03 | 10.0 | 11.11 | 10.92 |
| LSD | 3.1 | 2.22 | 2.14 | 3.5 | 2.92 | 2.72 | 3.7 | 3.23 | 2.97 | |
| MOS-LQO | - | 3.68 | 3.75 | - | 2.68 | 2.93 | - | 2.44 | 2.69 | |
| Piano | SNR | 30.1 | 44.98 | 52.03 | 23.5 | 31.71 | 32.28 | 16.1 | 22.53 | 24.71 |
| LSD | 3.4 | 1.12 | 0.90 | 3.6 | 1.35 | 1.30 | 4.4 | 1.53 | 1.41 | |
Subjective quality analysis 主观质量分析
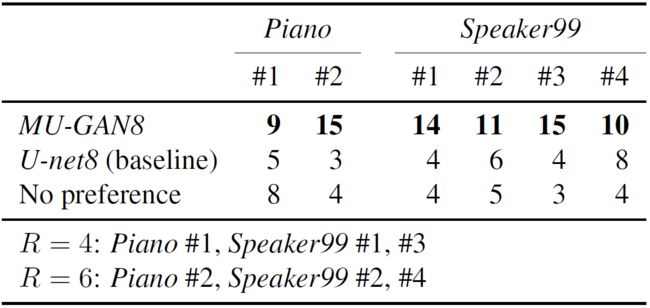
为了在真实的听众中评估MU-GAN的性能,我们对22名参与者进行了随机、single-blinded(单盲)的用户研究(表2)。我们展示了两个来自钢琴的片段,和四个音色各异的来自Speaker99的片段。表2显示,在所有情况下,与基线方法相比,侦听者更喜欢$MU-GAN8$生成的音频。
表2:A/B test user study scores
一般来说,我们观察到$MU-GAN$产生的音频比基线网络产生的音频更清晰。音质差异最明显的是辅音,与典型元音相比,辅音的高频成分较多。例如,在phrase(短语)Ask her to bring these things from the store(图5,底部一行)中,Ask、things和store中的辅音发音明显更好。相比之下,来自最佳基线$U-net8$的音频则明显比较沉闷和底沉。
Comparison with classifier-based feature loss 与基于分类器的特征丢失进行比较
我们将提出的无监督特征损失与[11]中的基于分类器的特征损失进行了比较([11]作者的预训练分类器模型来自https://github.com/francoisgermain/speechnoinsingwithdeepfeaturelosses)。[11]的方法使用基于$VGG$[36]的网络作为语音去噪的特征损失,并对该丢失网络进行DCASE 2016[29]中分类和音频标记任务的训练。表3显示了从一个用$L_{adv}$训练的$MU-GAN8$实例中获得的客观指标,或者是无监督损失$L_f$,或者是基于分类器的损失$L_{f_SV}$。在所有上采样ratios(比)中,与基于分类器的损失相比,所提出的无监督方法的性能与标准相当(在某些情况下稍好一些)。因此,我们的结果表明,使用基于领域特定分类器的损失可能不会在性能方面提供任何优势。考虑到与训练一般音频分类器模型相关的问题(第1节),我们的方法可能是一个不影响音频质量的有吸引力的解决方案。
表3:使用基于语音分类器的损失和proposed损失$(L_{f,SV},L_f)$训练$MU-GAN8$的$Speaker1$客观指标

Ablation Analysis 烧蚀分析
表4显示了带有简化模型参数的$MU-GAN$体系结构的$MOS-LQO$度量。而几乎所有的变化在$R = 2$时都表现得很好,但增加深度(即从l=4到l=8)和额外的损失项可以提高更好采样率的性能。此外,增加对抗性损失和无监督特征损失项单调地改善了$MOS-LQO$。对于$MU-GAN8$,我们看到增加额外损失项会减少收益;与$MU-GAN4$相比,许多改进似乎来自额外的深度。另一方面,将$L_f$和$L_{adv}$的损失添加到$MU-GAN4$变体上可以获得显著的好处,因此其性能可以与MU-GAN8相媲美。这表明,该特性和对抗性损失可能特别有助于减轻拟合不足,或降低模型尺寸的等性能。
表4:speaker1任务中烧蚀模型的$MOS-LQO$

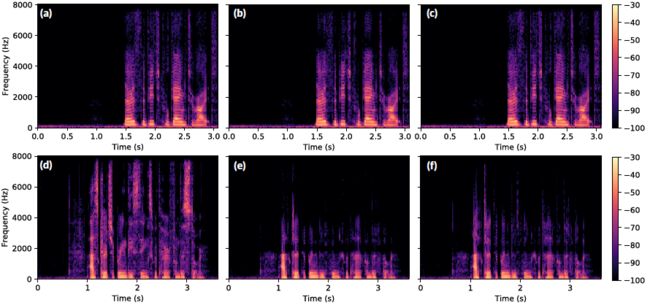
图5:在$R=2$时来自Speaker1任务的语谱图(顶部一行,Speaker 225),以及$R = 4$时Speaker99任务的语谱图(底部一行,Speaker 360)。(a-d)高分辨率,(b-e) U-net8超分辨率,(c-f) MU-GAN8超分辨率。在不同的上采样比率下,由$MU-GAN8$合成高频含量的增加变得更加明显。
5 结论
在这项工作中,我们开发了方法,使应用的GAN音频处理,特别是与classifier-free(无分类器)特征损失。除了几个新的模型构建模块外,我们还证明了卷积自编码器可以在音频超分辨率环境下实现高性能的特征损失。通过对几个语音和音乐超分辨率任务的演示,我们展示了我们的架构在客观和主观指标上都实现了最先进的性能。我们对我们的模型进行了详细的分析,包括阐述模型尺寸和损失组件影响的烧蚀。最后,我们的工作为设计和分析除音频处理外的重要问题领域中基于神经网络的综合方法提供了新的可能性。
参考文献
[1] Johannes Abel and Tim Fingscheidt. Artificial speech bandwidth extension using deep neural networks for wideband spectral envelope estimation. In IEEE/ACM Transactions on Audio,Speech, and Language Processing, 2018.[2] Yusuf Aytar, Carl Vondrick, and Antonio Torralba. Soundnet: Learning sound representations from unlabeled video. In NIPS, 2016.[3] Pramod Bachhav, Massimiliano Todisco, Moctar Mossi, Christophe Beaugeant, and Nicholas Evans. Artificial bandwidth extension using the constant q transform. In ICASSP, 2017.[4] David Berthelot, Tom Schumm, and Luke Metz. BEGAN: boundary equilibrium generative adversarial networks. arxiv:1703.10717, 2017.[5] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A Large-Scale Hierarchical Image Database. In CVPR, 2009.[6] Emily L. Denton, Soumith Chintala, Arthur Szlam, and Rob Fergus. Deep generative image models using a laplacian pyramid of adversarial networks. In NIPS. 2015.[7] Chris Donahue, Julian McAuley, and Miller Puckette. Synthesizing audio with generative adversarial networks. arxiv:1802.04208, 2018.[8] Alexey Dosovitskiy and Thomas Brox. Generating images with perceptual similarity metrics based on deep networks. In NIPS. 2016.[9] Jesse Engel, Cinjon Resnick, Adam Roberts, Sander Dieleman, Douglas Eck, Karen Simonyan,and Mohammad Norouzi. Neural audio synthesis of musical notes with wavenet autoencoders.arxiv:1704.01279, 2017.[10] Leon Gatys, Alexander Ecker, and Matthias Bethge. Image style transfer using convolutional neural networks. In CVPR, 2016.[11] Francois G. Germain, Qifeng Chen, and Vladlen Koltun. Speech denoising with deep feature losses. arxiv:1806.10522, 2018.[12] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In NIPS. 2014.[13] Augustine Gray and John Markel. Distance measures for speech processing. In IEEE/ACM Transactions on Audio, Speech, and Language Processing, 1976.[14] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. In CVPR, 2017.[15] ITU. Mapping function for transforming p.862 raw result scores to MOS-LQO. In ITU-T Rec.P.862.1.[16] ITU. Perceptual evaluation of speech quality, an objective method for end-to-end speech quality assessment of narrowband telephone networks and speech codecs. In ITU-T Rec. P.862.[17] Zhang Jie, Xiaoqun Zhao, Jingyun Xu, and Zhang Yang. Suitability of speech quality evaluation measures in speech enhancement. In International Conference on Audio, Language and Image Processing, 2014.[18] Justin Johnson, Alexandre Alahi, and Fei-Fei Li. Perceptual losses for real-time style transfer and super-resolution. arxiv:1603.08155, 2016.[19] Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of gans for improved quality, stability, and variation. In ICLR, 2018.[20] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR,2015.[21] Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. In ICLR, 2014.[22] Volodymyr Kuleshov, S. Zayd Enam, and Stefano Ermon. Audio super resolution using neural networks. In ICLR, 2017.[23] Erik R. Larsen and Ronald M. Aarts. Audio Bandwidth Extension: Application of Psychoacoustics,Signal Processing and Loudspeaker Design. John Wiley & Sons, Inc., 2004.[24] Christian Ledig, Lucas Theis, Ferenc Huszar, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew P. Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, and Wenzhe Shi.Photo-realistic single image super-resolution using a generative adversarial network. In CVPR,2017.[25] Honglak Lee, Peter Pham, Yan Largman, and Andrew Y. Ng. Unsupervised feature learning for audio classification using convolutional deep belief networks. In NIPS. 2009.[26] Bin Liu, Jianhua Tao, Zhengqi Wen, Ya Li, and Danish Bukhari. A novel method of artificial bandwidth extension using deep architecture. In INTERSPEECH, 2015.[27] Andrew L. Maas, Awni Y. Hannun, and Andrew Y. Ng. Rectifier nonlinearities improve neural network acoustic models. In ICML, 2013.[28] Soroush Mehri, Kundan Kumar, Ishaan Gulrajani, Rithesh Kumar, Shubham Jain, Jose Sotelo,Aaron C. Courville, and Yoshua Bengio. Samplernn: An unconditional end-to-end neural audio generation model. In ICLR, 2017.[29] Annamaria Mesaros, Toni Heittola, Emmanouil Benetos, Peter Foster, Mathieu Lagrange, Tuomos Virtanen, and Mark D. Plumbley. Detection and classification of acoustic scenes and events: Outcome of the dcase 2016 challenge. In IEEE/ACM Transactions on Audio, Speech,and Language Processing, 2018.[30] Mehdi Mirza and Simon Osindero. Conditional generative adversarial nets. arXiv:1411.1784,2014.[31] Augustus Odena, Vincent Dumoulin, and Chris Olah. Deconvolution and checkerboard artifacts.In Distill, 2016.[32] Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. In ICLR, 2015.[33] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention,2015.[34] Andy M. Sarroff and Michael A. Casey. Musical audio synthesis using autoencoding neural nets. In International Computer Music Conference, 2014.[35] Wenzhe Shi, Jose Caballero, Ferenc Husz´ar, Johannes Totz, Andrew P. Aitken, Rob Bishop,Daniel Rueckert, and Zehan Wang. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In CVPR, 2016.[36] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556, 2014.[37] Casper Kaae Sonderby, Tapani Raiko, Lars Maaloe, Soren Kaae Sonderby, and Ole Winther.Ladder variational autoencoders. In NIPS. 2016.[38] Jose Sotelo, Soroush Mehri, Kundan Kumar, Joo F. Santos, Kyle Kastner, Aaron Courville,and Yoshua Bengio. Char2Wav: End-to-end speech synthesis. In ICLR, 2017.[39] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov,Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions.In CVPR, 2015.[40] Keiichi Tokuda, Yoshihiko Nankaku, Tomoki Toda, Heiga Zen, Junichi Yamagishi, and Keiichiro Oura. Speech synthesis based on hidden markov models. In Proceedings of the IEEE,2013.[41] A¨aron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew W. Senior, and Koray Kavukcuoglu. Wavenet: A generative model for raw audio. arxiv:1609.03499, 2016.[42] Aaron van den Oord, Yazhe Li, Igor Babuschkin, Karen Simonyan, Oriol Vinyals, Koray Kavukcuoglu, George van den Driessche, Edward Lockhart, Luis Cobo, Florian Stimberg,Norman Casagrande, Dominik Grewe, Seb Noury, Sander Dieleman, Erich Elsen, Nal Kalchbrenner,Heiga Zen, Alex Graves, Helen King, Tom Walters, Dan Belov, and Demis Hassabis.Parallel WaveNet: Fast high-fidelity speech synthesis. In ICML, 2018.[43] Pascal Vincent, Hugo Larochelle, Isabelle Lajoie, Yoshua Bengio, and Pierre-Antoine Manzagol.Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. In JMLR, 2010.[44] Junichi Yamagishi. CSTR VCTK corpus.http://homepages.inf.ed.ac.uk/jyamagis/page3/page58/page58.html.