自监督表征预训练之掩码图像建模:CAE 及其与 MAE、BEiT 的联系
来源:https://zhuanlan.zhihu.com/p/531243540
自监督表征预训练 (Self-supervised representation pretraining),主要有两大类方法。一类是,对比学习 (Contrastive self-supervised representation pretraining),另外一类是,掩码图像建模 (Masked image modeling,MIM)。我先主要讲讲后一种方法。主要讲讲我们的工作 Context Autoencoder (CAE) ,和MAE、BEiT的一些联系,以及和对比学习的比较。
Readpaper link:https://readpaper.com/paper/4588984690984099841
arXiv link: https://arxiv.org/abs/2202.03026
Official code: https://github.com/PaddlePaddle/VIMER/tree/main/CAE
Collection of official and third-party implementations: https://github.com/Atten4Vis
一、定义和目标
掩码图像建模 (MIM) 是指:将图像中一些图像块掩码掉,用其他剩下的可见的图像块 (Visible patches) 来预测被掩码掉的图像块 (Masked patches)。自监督表征预训练,把MIM这个任务当成预训练任务,来训练图像编码器 (Encoder) ,期望编码器编码的表征 (Representation) 包含丰富的语义信息。
二、设计原则
如何设计预训练网络结构呢?有这么几点需要考虑。
首先,如前面所讲,这个结构得显式的包含需要学习的表征编码器。
其次,设计解决掩码图像建模任务的结构模块,掩码图像建模任务,与其他任务 (如检测、分割等) 一样,只是一个视觉任务,所以类似检测,需要一个相应的任务结构模块。
再次,希望预训练得到编码器的表征能力尽量强,为此,希望预训练过程中,编码器只负责表征学习的任务,而且表征学习只由编码器负责。为此,编码器只处理可见图像块,而解决 MIM 任务的时候,不再修改可见图像块的表征,期望分离编码和 MIM 任务。
最后,既然我们的目的是通过预训练学习编码器,以得到语义信息丰富的表征,我们是不是可以对表征做些特别的处理?为此,我们把掩码图像建模任务变成掩码表征建模 (Masked representation modeling) 任务,在编码表征空间里,用可见图像块的表征来预测掩码图像块的表征。
三、Context Autoencoder (CAE) 结构
基于以上考虑,我们设计了Context Autoencoder,如下:

(a) 把可见图像块输入到编码器中,抽取可见图像块的表征。(b) 在编码表征空间中做预测,使得掩码图像块的表征和从可见图像块预测得到表征一致。(c) 将掩码图像块的表征输入到解码器中,预测掩码图像块。
通过这样的设计,我们希望编码模块 (a) 和任务解决部分 (b,c) 分离;把掩码图像建模任务转成掩码表征建模任务 (b) ,在编码表征空间中,完成预测任务。
直观解释
这三步跟人类完成MIM任务是类似的。步骤 (a):从可见的图像块来识别图像的语义内容,如dog,用表征来表示;步骤 (b):猜测掩码图像块是什么,比如是dog还是grass,仍然用表征来表示;步骤 (c):猜想出掩码图像块的具体内容。

四、掩码表征建模的重要性
从两个角度分析,一是实验结果 (ViT base,300 epochs) ,Alignment 起了就很大的作用。其中没有 Alignment 的结果比 BEiT 和 MAE 的结果高,说明了分离的重要性。有了Alignment,结果更高,说明了在编码表征空间做预测的重要性。
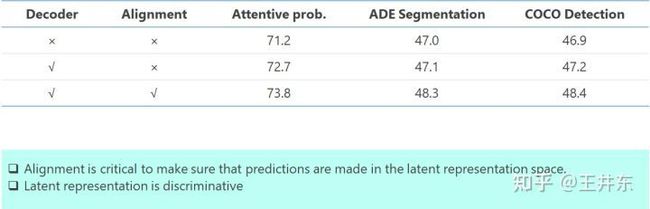
二是去掉了Alignment,也就是不能确保掩码图像块的表征和从可见图像块预测得到表征一致。我们的是通过重建来验证:把图像的所有图像块输入到编码器,然后直接把编码表征输入解码器里重建图像。结果显示了 Alignment 的重要性。

五、与MAE和BEiT的联系
可能有些 subtle,欢迎讨论。
先看看 BEiT (Bidirectional Encoder representation from Image Transformers)。BEiT把可见图像块的颜色信息和掩码图像块掩码 token (不包含掩码图像块的颜色信息) ,输入到ViT中,然后ViT输出通过一个线性层来做预测。尽管可以把 ViT 称为编码器,不过,ViT 负责了两项任务:表征编码,以及预测掩码图像块的任务,没有把这两个任务分离。换句话中,ViT也在不停的解决任务 (也就是预测任务)。正因为如此,BEiT 预训练得到 ViT 语义表征能力一般,从其 linear probing 可以看到。

下面看看 MAE (Masked AutoEncoder)。MAE 只把可见图像块输入到编码器中,然后编码器的输出的可见图像块的表征和掩码图像块的掩码 token,输入到由 self-attention 组成的解码器中去。这样的结构比 BEiT 有了进步,但是解码器中可见图像块的表征可能会进一步更新,所以表征学习的任务没有由编码器完全负责,所以 MAE 得到的编码器能力也不足够好。

相比较,CAE尽量做到编码和MIM任务分离。除此,CAE在编码表征空间中做预测。比较总结如下:

预训练得到编码器,在ImageNet-1K上的 probing 比较验证了以上分析

六、与对比自监督表征预训练比较
这里不做详细介绍对比学习的方法,一个典型的结构如下。重要特点是,比较随机裁剪的图像块。

考虑到随机裁剪的性质,发现原图中间部分的像素有更大概率落到裁剪的图像块中 (如下图) ,为了使得同一图像裁剪的图像块抽取的表征尽量相似,我们猜测:对比方法主要学到了图像中间物体的信息。比如在 ImageNet-1K 上,主要学到 1000 类的信息。

相比较,CAE 和 MIM 可以学到图像的所有图像块的信息。通过可视化,也验证了分析。这是MIM比对比方法好的原因之一吧。

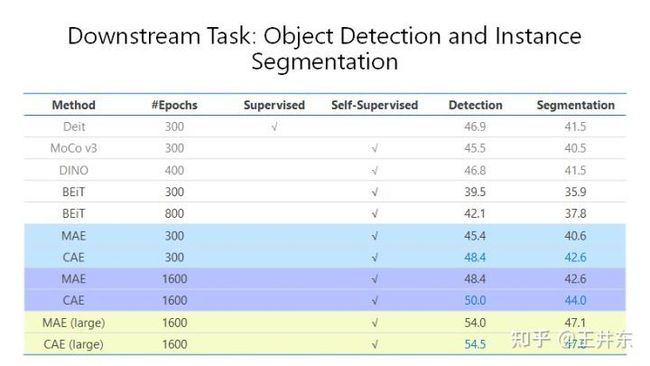
七、下游任务比较
ADE 上分割以及 COCO 物体检测实例分割,在 ViT (base) 和 ViT (large) 上的结果,验证了我们的分析,CAE 高于 MAE 和 BEiT,也高于对比学习。

八、后记
最近看到了火热的 Geoffrey Hinton 最新访谈的文章

有几个点跟 CAE 的设计原则很有关联。
第一点,在编码表征空间做预测,就是把掩码图像建模转成掩码表征建模。CAE结构中 (b) 部分。

第二点,BEiT 中 ViT 是在不停的预测掩码图像块的信息,MAE 的 decoder 部分同时做表征学习和解决 MIM 任务。

第三点,Hinton 在访谈中,谈到了关于他和 Suzanna Becker 的对比学习的文章,说不 work 的原因有点 subtle,没有展开讲。或许原因跟我们的分析类似。
【技术交流】
已建立深度学习公众号——FightingCV,关注于最新论文解读、基础知识巩固、学术科研交流,欢迎大家关注!!!
推荐加入FightingCV交流群,每日会发送论文解析、算法和代码的干货分享,进行学术交流,加群请添加小助手wx:FightngCV666,备注:地区-学校(公司)-名称
面向小白的顶会论文核心代码库:https://github.com/xmu-xiaoma666/External-Attention-pytorch
面向科研小白的YOLO目标检测库:https://github.com/iscyy/yoloair
面向小白的顶刊顶会的论文解析:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading

【赠书活动】
为感谢各位老粉和新粉的支持,FightingCV公众号将在9月10日包邮送出4本《深度学习与目标检测:工具、原理与算法》来帮助大家学习,赠书对象为当日阅读榜和分享榜前两名。想要参与赠书活动的朋友,请添加小助手微信FightngCV666(备注“城市-方向-ID”),方便联系获得邮寄地址。

本文由mdnice多平台发布