在Linux下链表使用介绍二:list_add/list_add_tail、list_for_each/list_for_each_safe等
在上一篇我们介绍了list_head;并定义了结构体节点,如何把该类型的结构体节点串成一个链表呢?
1、必须专门定义一个专有链表头,并初始化:
struct list_head ListHead;
INIT_LIST_HEAD(&ListHead);其中INIT_LIST_HEAD的定义为
#define INIT_LIST_HEAD(ptr) do { \
(ptr)->next = (ptr); \
(ptr)->prev = (ptr); \
} while (0)2、用list_add/list_add_tail 来添加链表节点
list_add(&entry, &ListHead);其中list_add,list_add_tail定义为
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
static inline void __list_add( struct list_head *new, struct list_head *prev, struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
void list_add_tail(struct list_head *new, struct list_head *head);
static __inline__ void list_add_tail(struct list_head *_new, struct list_head *head)
{
__list_add(_new, head->prev, head);
}
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static __inline__ void __list_add(struct list_head * _new,
struct list_head * prev,
struct list_head * next)
{
next->prev = _new;
_new->next = next;
_new->prev = prev;
prev->next = _new;
}
3、遍历链表list_for_each/list_for_each_safe
我们知道list_for_each_entry会用到list_entry,而list_entry用到container_of,而container_of中有offsetof,所以从offsetof讲起。
offsetof(TYPE, MEMBER) ((size_t)&((TYPE *)0)->MEMBER) 接下来讲讲container_of
/*
* container_of - cast a member of a structure out to the containing structure
* @ptr: the pointer to the member.
* @type: the type of the container struct this is embedded in.
* @member: the name of the member within the struct.
*
*/
#define container_of(ptr, type, member) ({ /
const typeof( ((type *)0)->member ) *__mptr = (ptr); /
(type *)( (char *)__mptr - offsetof(type,member) );}) 首先可以看出container_of被预定义成一个函数,函数的第一句话,通过((type *)0)->member定义一个MEMBER型的指针__mptr,这个指针指向ptr,所以第一句话获取到了我们要求的结构体,它的成员member的地址,接下来我们用这个地址减去成员member在结构体中的相对偏移量,就可以获取到所求结构体的地址, (char *)__mptr - offsetof(type,member)就实现了这个过程,最后再把这个地址强制转换成type型指针, 就获取到了所求结构体指针, define预定义返回最后一句话的值, 将所求结构体指针返回。
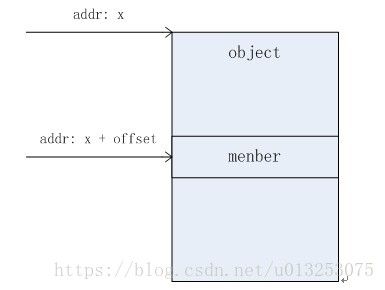
所以整个container_of的功能 就是通过指向结构体成员member的指针ptr获取指向整个结构体的指针 。container_of清楚了,那list_entry就更是一目了然了。
/*list_entry /**
* list_entry - get the struct for this entry
* @ptr: the &;struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_struct within the struct.
*/
#define list_entry(ptr, type, member) /
container_of/(ptr,type,member) /**
* list_for_each_entry - iterate over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry(pos, head, member) /
for (pos = list_entry((head)->next, typeof(*pos), member); /
&pos->member != (head); /
pos = list_entry(pos->member.next, typeof(*pos), member))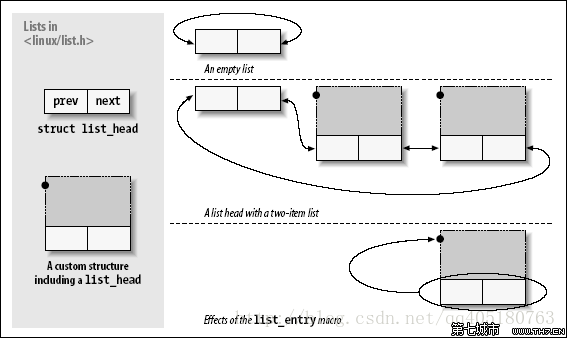
链表头和链表的关系清楚了,我们才能完全理解list_for_each_entry。list_for_each_entry被预定义成一个for循环语句,for循环的第一句话获取(head)->next指向的member成员的数据结构指针,也就是将pos初始化为除链表头之外的第一个实体链表成员,for的第三句话通过pos->member.next指针遍历整个实体链表,当pos->member.next再次指向我们的链表头的时候跳出for循环。整个过程没有对链表头进行遍历(不需要被遍历),所以使用list_for_each_entry遍历链表必须从链表头开始。 因此可以看出, list_for_each_entry的功能就是遍历以head为链表头的实体链表,对实体链表中的数据结构进行处理 。
接下来看看list_for_each_entry_safe
/**
* list_for_each_entry_safe - iterate over list of given type safe against removal of list entry
* @pos: the type * to use as a loop cursor.
* @n: another type * to use as temporary storage
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry_safe(pos, n, head, member) /
for (pos = list_entry((head)->next, typeof(*pos), member), /
n = list_entry(pos->member.next, typeof(*pos), member); /
&pos->member != (head); /
pos = n, n = list_entry(n->member.next, typeof(*n), member)) end!!